夜雨聆风
夜雨聆风OpenClaw 多 Agent,为什么总是跑不通?
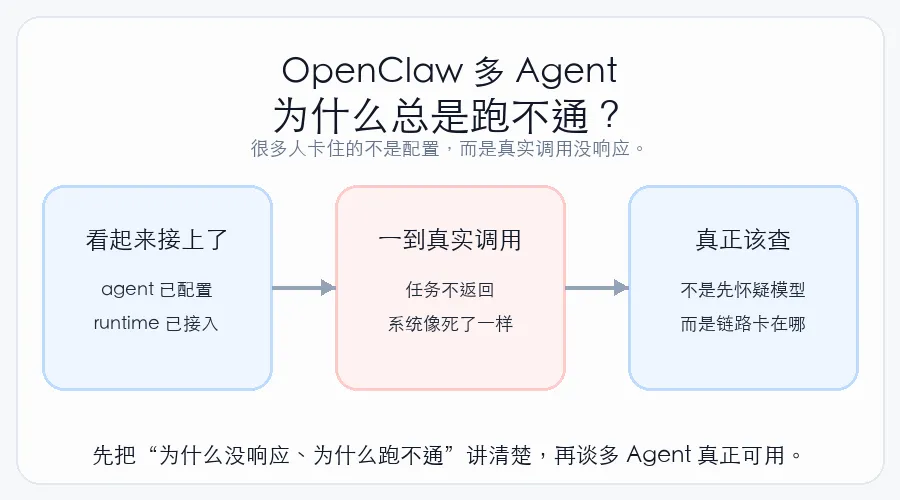
你做多 Agent 开发,最怕的不是模型写错。最怕的是:
调用没响应。任务跑不通。系统像死了一样。
这就是过去很多人对 OpenClaw 的真实体验。
不是不会配。是配好了,还是跑不起来。
所以这次我重新做的,不是一次普通试用。
而是一次彻底的问题定位:
OpenClaw 做智能化多 Agent 开发,到底为什么没响应、为什么跑不通、现在又到底修到了哪一步?
结论先说:
过去那些“超时”“不返回”“像死掉一样”的问题,很多并不是模型本身不行。
而是运行链路卡住了。
卡在一个永远不会到来的输入上。
Obsidian CLI 当时直接报错:Unable to connect to main process
这句话很重要。
它说明过去很多问题,不是“接不进去”,而是“某一段已经卡死了”。
所以现在真正该问的,不再是“能不能接入”。
而是:链路到底稳不稳定。
先看这张对比图。很多人把链路问题误判成模型问题,结果越查越偏:

这次验证,最重要的是三件事
第一,Claude 和 Codex 已经能通过 OpenClaw ACP runtime 正常接收单轮任务并返回结果。
这不是“能聊几句”。
这是 one-shot 调度闭环已经打通。
第二,它们已经通过了真实文件写入验证。
能回复,不等于能干活。
能写文件,才说明它开始进入执行环节。
第三,连续多轮上下文也开始可用,但路径要选对。
Telegram 入口下,ACP 的 thread session 仍有限制。
但 direct acpx named session,已经可以承接至少两轮上下文。
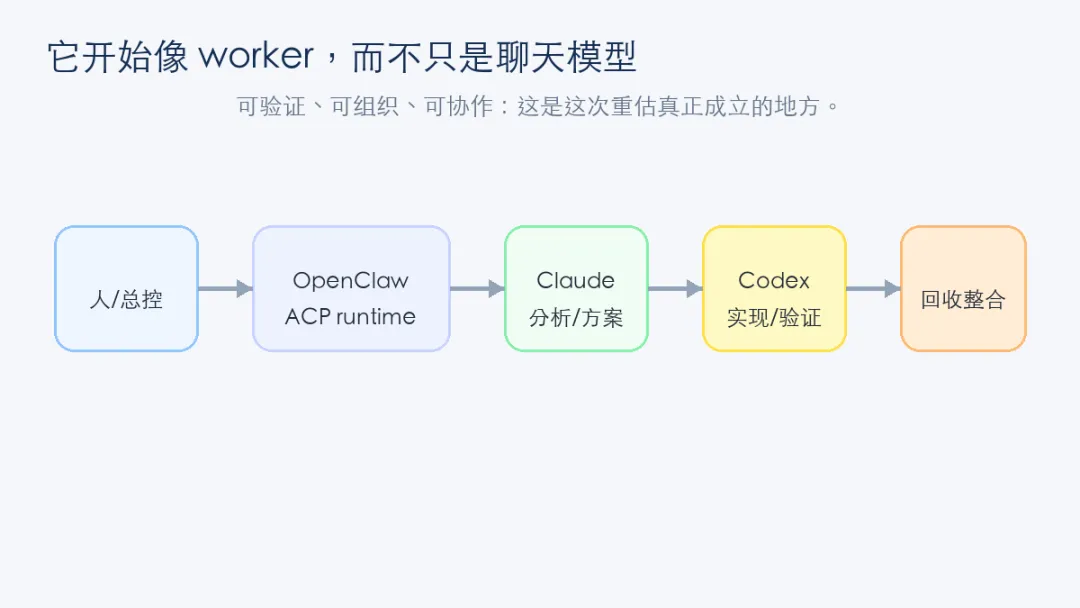
我这次实际跑过一条协同闭环:一个做分析/方案,一个做实现/验证,再由总控回收整合。
下面这张图,就是两条路径的区别:

为什么说这不是一次普通更新?
因为判断坐标变了。
以前大家争论的是:
Claude / Codex 到底能不能接进 OpenClaw。
现在更实际的问题变成了:
接进来之后,哪条链路能稳定跑,哪条链路还有限制。
这才是真正的进步。
从架构上看,任务分发链路是:
总控 → OpenClaw ACP runtime → acpx → Claude/Codex adapter → harness process
这意味着 Claude 和 Codex 不再只是“回答问题的模型”。
它们开始变成能被调度进流程的 worker。
能接任务。
能分工。
能协作。
真正能用,取决于你知不知道边界
这次更新并不意味着所有场景都已经丝滑稳定。
但它已经足够回答一个关键问题:
OpenClaw 调 Claude / Codex 做多 Agent 开发,不再只是概念可行,而是开始进入“可验证、可组织、可协作”的阶段。
当前最现实的用法也很清楚:
单轮任务 → 走 OpenClaw ACP runtime 连续多轮任务 → 走 direct acpx named session
这不是完美状态。
但已经不是 demo 状态了。
这意味着,如果你之前因为“没响应、跑不通”就把它判死刑,现在确实该重新评估一次。