 夜雨聆风
夜雨聆风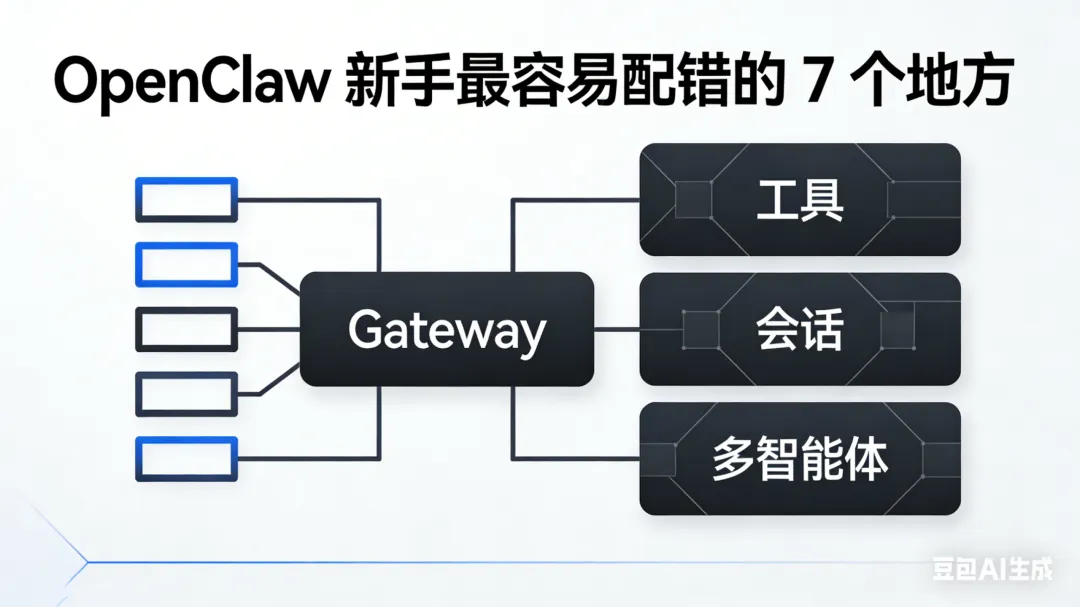
OpenClaw 新手最容易配错的 7 个地方
不是不会用,而是一开始就理解错了。
这两天连续折腾 OpenClaw,我越来越强烈地感觉到一件事:
很多人不是败在“不会配”,而是败在“一上来就把它理解错了”。
你看它的时候,会觉得它像 Bot,像自动化平台,像能调工具的大模型外壳,甚至像一个“接上消息平台就能跑”的 AI 助手。
但真开始动手之后,你很快就会发现:
OpenClaw 不是那种“功能很多”的工具,而是一套“结构没想清楚,功能越多越容易出事”的系统。
它能做的事情确实很多:接渠道、调工具、多智能体、接节点、做自动化、跑会话协作。也正因为它能做的太多,新手最容易犯的错误,不是某个命令写错了,而是起手思路就偏了。
这篇不讲炫技,不讲 fancy 工作流,就讲一个更实际的问题:
OpenClaw 新手最容易配错的 7 个地方。
1. 把 OpenClaw 当成“聊天机器人”来理解
这是第一个,也是最常见的误区。
很多人第一次接触 OpenClaw,脑子里会自动给它找参照物:
Telegram Bot Discord 机器人 企业微信助手 一个能调用工具的大模型 Bot
这么理解不能说完全错,但会很快把后面的思路带偏。
因为 OpenClaw 的核心,不是“某个平台上的一个机器人”,而是 Gateway 这层控制平面。
聊天平台只是入口。真正决定系统怎么运作的,是后面这些东西:
会话怎么管理 请求怎么路由 工具怎么调用 节点怎么接进来 agent 怎么隔离 自动化怎么编排
所以,如果你一开始只盯着“怎么把机器人拉进群”,很容易忽略一个更底层的问题:
这套系统,准备怎么组织。
这件事不想清楚,后面很容易出现一种状态:账号混了、会话混了、权限混了、角色也混了。
2. 以为多智能体就是“多套人设”
这是第二个特别容易让人兴奋、也特别容易走偏的坑。
很多人一看到 multi-agent,第一反应就是:
一个负责写作 一个负责技术 一个负责运营 一个负责自动化 一个负责吐槽和整活
听起来很合理,但问题是:
如果你只是给不同 agent 写不同 prompt、不同语气、不同人设,这其实不叫多智能体,最多只能叫——多人设切换。
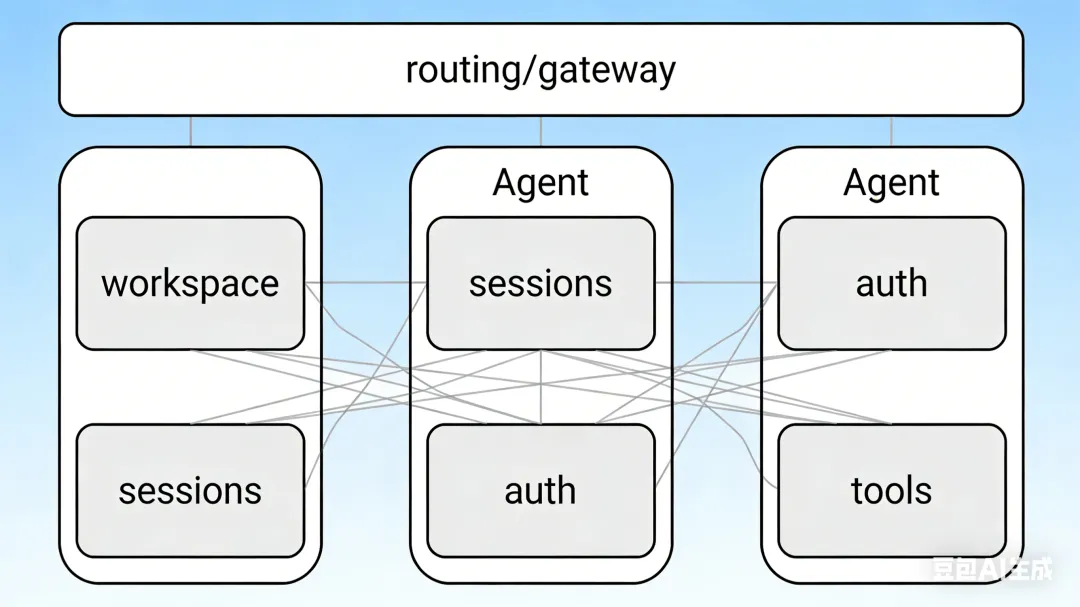
OpenClaw 里的多智能体,重点根本不是“像不像不同的人”,而是 隔离。
一个 agent 真正重要的,不是它说话风格,而是它有没有自己的:
workspace sessions auth profile tools scope routing boundary
换句话说:
一个 agent 不是一个口吻,而是一块独立作用域。
如果这一点没想清楚,你最后得到的很可能不是“多智能体”,而只是几个名字不一样、实质上还在共享上下文的假分身。
3. 先设计人格,后设计路由
这个坑很多人都会踩,而且往往踩得很认真。
因为人格设计这件事,真的很容易上头。你会想写:
SOUL.md USER.md AGENTS.md 一整套风格约束 一整套“它应该怎么说话”
这些东西当然有价值。 但如果你把大量精力先花在“它要怎么表达”上,而不是“消息到底进谁”,那后面非常容易陷入一种局面:
人格写得很丰满,系统行为却很混乱。
因为在 OpenClaw 里,很多时候真正决定结果的,不是人格,而是 路由。
比如:
哪个渠道进哪个 agent 哪个账号归哪个 agent 哪个群要不要特殊处理 哪个私聊需不需要独立隔离 匹配优先级怎么定
这些东西,才是系统会不会跑偏的基础。
说得再直接一点:
人格是表层,路由是地基。
地基没打好,人设越复杂,后面越容易补锅。
4. 以为 workspace 就是安全沙箱
这个坑很隐蔽,因为它特别容易制造一种“我已经隔离了”的错觉。
很多人看到 workspace,下意识就会理解成:
每个 agent 一个目录 所有东西都在各自目录里 那就等于安全了
但实际不是这么回事。
workspace 更准确的含义是:默认工作目录。 它更像默认 cwd,而不是天然的硬隔离边界。
这意味着:
相对路径通常会从 workspace 出发 但绝对路径不一定受这个边界限制 外部命令和工具调用也不一定自动被“目录”拦住
所以如果你把 workspace 当成强安全边界,问题往往不会立刻暴露,但一旦你开始:
接外部脚本 调系统工具 做自动化链路 处理多人场景
这个误解就会开始反噬。
更稳妥的理解应该是:
workspace 是组织方式,不是完整沙箱。
真想做强隔离,还是得靠 sandbox、权限控制和调用边界一起配。
5. 一上来就追求“全自动工作流”
这是最容易让人热血上头的一种坑。
因为 OpenClaw 太容易让人联想到一条非常诱人的链路:
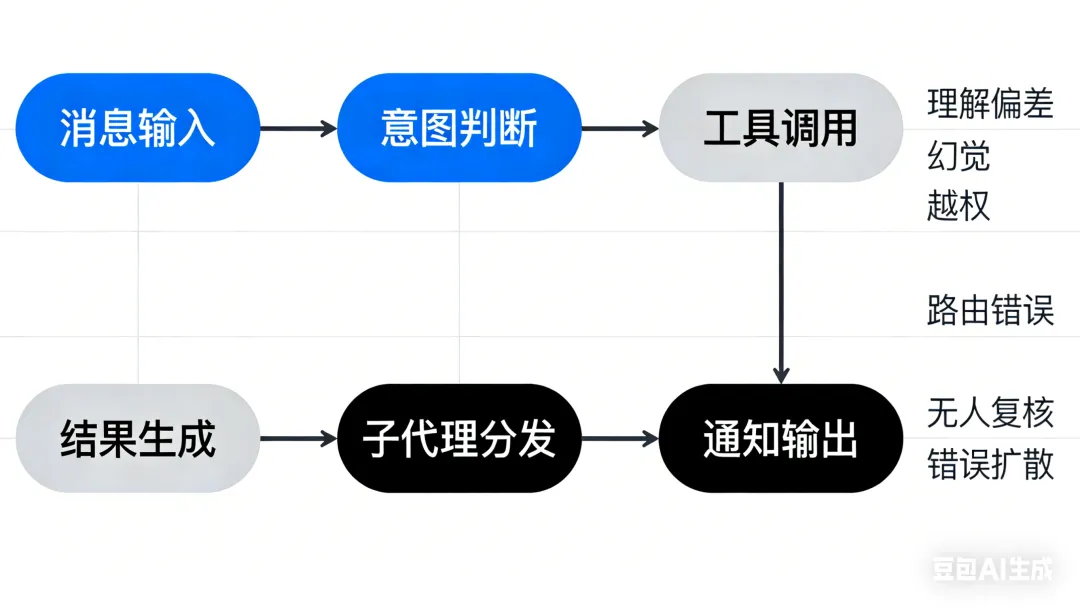
收到消息 自动判断意图 自动调工具 自动生成结果 自动分发任务 自动调用子代理 自动通知别人 自动闭环
看起来很美,演示起来也确实很爽。
但问题是,一条链路越长,失控点就越多。
你很快会开始面对这些现实问题:
哪一步理解错了? 哪一步幻觉了? 哪一步越权了? 哪一步路由错了? 哪一步结果没人复核?
所以自动化真正的坑,不是“能不能做”,而是:
你是不是太早做长链路了。
我现在越来越认同一个顺序。
先做短链路闭环
比如:
收到消息 调一个工具 返回结果
再做半自动
比如:
先给建议 人确认 再执行外部动作
最后再做全自动
但前提是你已经有:
日志 追踪 边界 回滚 人工兜底
真正成熟的自动化,不是链路越长越高级,而是:
越可审计,越高级。
6. 以为 agent 之间会自动协作得很优雅
很多人对多智能体系统有一种天然想象:
既然都是 agent,那多个 agent 在一起,应该会自动分工、自动接力、自动配合吧?
现实通常没这么浪漫。
OpenClaw 的设计,反而比较克制。它没有鼓励那种“大家自己心有灵犀”的协作幻想,而是提供了明确的会话工具,比如:
sessions_listsessions_historysessions_sendsessions_spawn
这套思路其实很成熟:
协作可以有,但最好是显式的。
因为只要多个 agent 开始随便共享上下文、随便互相调用、随便递归派生,系统复杂度很快就会失控。
所以这里真正该调整的,不是参数,而是预期。
不要期待它们“自动默契”,而要设计它们“明确协作”。
7. 不做自己的本地知识整理,学了也等于白学
OpenClaw 文档并不少,概念也不轻。很多内容不是看一遍就真懂了,而是要在实际配置里反复碰几次,才会开始真正形成自己的理解。
如果每次遇到问题都回去重新翻 README、翻 docs、翻 issue,短期可能还能忍,时间一长就很累。
更关键的是,真正有用的那部分认知,往往不是“文档原文”,而是你自己在实践里长出来的那层理解。
所以我现在越来越觉得,学 OpenClaw 最值得做的一件事,不只是“会配”,而是:
把它整理成自己的本地知识库。
哪怕只是最简单的结构都很有用:
官方资料本地副本 自己的学习笔记 主题索引 常见坑记录 推荐阅读路径
这样以后再遇到问题时,你不是重新开始搜答案,而是回到自己的知识资产里快速定位:
多智能体问题看哪里 架构问题看哪里 路由问题看哪里 session 协作看哪里 workspace 边界看哪里
这才是复利。
说到底:
别把文档当一次性消费品,要把它变成你自己的知识资产。
最后一句
我现在对 OpenClaw 最大的感受,不是“它功能真多”,而是:
它特别考验你有没有系统思维。
如果你只是把它当成一个 bot,你很快就会被它的复杂度反噬。
但如果你把它理解成一个 个人 AI 控制平面,很多东西反而会越配越顺。
所以新手最容易配错的,从来不只是某个命令、某个参数、某个配置项。
真正最容易配错的,是这个顺序:
先追求效果 后考虑结构 先堆功能 后补边界 先想智能 后想控制
而更稳的顺序应该是:
先理解架构 再理解路由 再划清 agent 边界 再接工具和自动化 最后再追求复杂能力
顺序对了,系统会越来越稳。 顺序错了,功能越多,坑也越多。
