 夜雨聆风
夜雨聆风最近这段时间,我一直在折腾一件事情:怎么把运行在腾讯云服务器上的 OpenClaw,和我自己平时真正使用的 Obsidian 知识库打通。(暂时还不想在自己的主力机部署,准备新电脑搞)
用腾讯云 COS 给 Obsidian 做多端同步,一次配置全设备通用(后面的前提,先把这里配置好)
表面上看,这像是一个“AI 接知识库”的技术问题,但我真正想解决的,其实不是“让 AI 能读文件”这么简单,而是另外几个更现实的问题。
我希望 AI 不只是偶尔帮我写点东西,而是真的能进入我的工作流,能够基于已有内容持续工作;我希望它有一定的“记忆”,而不是每次都从零开始;我也希望它的操作是可控的,而不是直接对我的知识库乱写乱改。更重要的是,我的 Obsidian 并不是只在一台机器上使用,我平时是电脑和手机都在用,并且会同步到腾讯云 COS 存储桶,所以这件事一旦处理不好,很容易出现冲突、覆盖、误删这些问题。
一开始,我也想过最直接的方案,比如让 AI 直接操作 Obsidian 仓库,或者让它像 Claude Code 一样直接读写笔记文件。但越往后做,我越觉得,真正可持续的方案不是“让 AI 直接动我的知识库”,而是给 AI 设计一个受控的工作区,让它读得到、写得出,但不能越界。
最后,我把这套方案落成了一个相对稳定的架构。今天把整个过程整理出来,既是做一个阶段性记录,也希望给同样想把 AI 接进个人知识系统的人一个可参考的思路。
一、我真正想搭建的,不是“AI 会写笔记”,而是一套可控的知识协作系统
先说最后成型的架构。
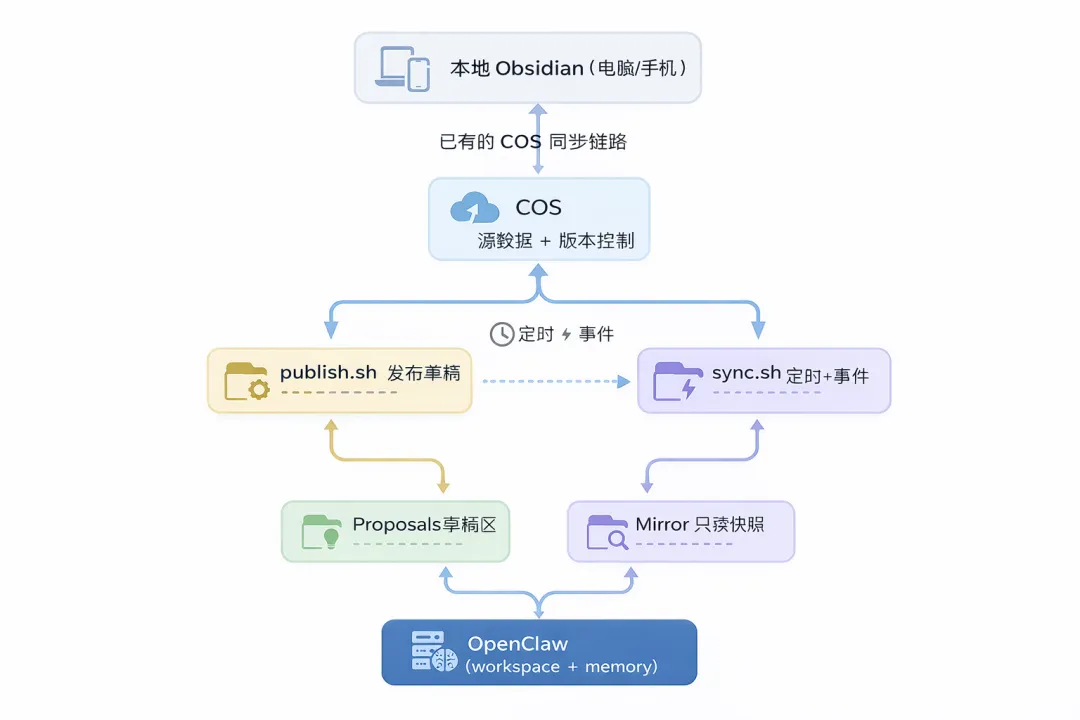
我的本地 Obsidian 仍然是我平时真正使用的知识库,手机和电脑都会同步到腾讯云 COS;云服务器上运行 OpenClaw,它不会直接碰我的本地 Vault,而是通过 COS 去读取一份镜像,并把自己的输出写到一个待确认区域;我确认之后,再由脚本把内容发布到 COS 的指定路径,最终同步回 Obsidian。
整个结构可以理解成这样:
本地 Obsidian(电脑/手机)↑(已有 COS 同步链路)↓COS(源数据 + 版本控制)↑ ↓publish.sh sync.sh(定时 + 事件)↑ ↓proposals/ mirror/(只读快照)↑OpenClaw(workspace + memory)
这套架构的核心原则只有五条,但每一条都很重要。
第一,AI 只读 mirror/,不直接读写我的正式知识库。 第二,AI 只写 proposals/,也就是所有产出都先进入草稿区。 第三,真正入库必须经过人工确认,然后再通过 publish.sh 发布到 COS 的指定路径。
第四,每次发布之后立即触发一次同步,确保 mirror 尽快刷新。 第五,COS 开启版本控制,这样即使真的发生误操作,也还能回滚。
换句话说,这套系统从一开始追求的就不是“自动化到完全无人接管”,而是“AI 能持续工作,但关键动作必须可控”。
二、为什么我没有让 OpenClaw 直接操作整个 Obsidian 仓库
一开始很多人直觉上会觉得,既然目标是让 AI 使用 Obsidian,那最直接的办法不就是把整个仓库挂给它吗?
但真正做的时候,我很快发现这件事风险很大。
第一,我的 Obsidian 是多端使用的,电脑(工作+个人)和手机都在同步,背后还有 COS 作为中间层,如果让云端 AI 再直接对同一个 Vault 动手,就等于往本来就有同步关系的结构里又加了一层写入源,冲突概率会明显上升。
第二,Obsidian 本质上还是一个文件系统层面的知识库,Markdown、附件、配置、目录结构都很敏感,AI 直接改文件当然不是不行,但一旦路径错了、文件名错了、内容覆盖了,后果会比“写错一段文本”严重得多。
第三,我后来慢慢想清楚了一件事:我真正需要的不是“AI 直接拥有我的知识库”,而是“AI 能在一个规则明确的环境里,辅助我整理、生成、建议和归档”。
所以最后,我选择把 AI 的工作空间和我的正式知识空间分开。AI 可以参考我的知识,但不能直接替我做最终决定。
三、这套系统里,OpenClaw、mirror、proposal、Obsidian 各自负责什么
一开始我也没太想清楚,脑海里预演了很多想法,最后和我的几个AI助理们一起商讨,选择了一套开始动起来,在做的过程中不断修正思考。
1. OpenClaw 的 workspace 和 memory,是 AI 自己的工作记忆层
这一层不是 Obsidian 的替代品,而是 OpenClaw 自己的运行上下文。它记录的是规则、偏好、当前任务状态,以及一些不需要进入正式知识库的工作性信息。比如我会在 SKILL.md 里明确写清楚:
mirror 是只读的 proposals 是唯一允许写入的目录 不允许删除或修改正式知识内容 输出必须是 markdown 新内容和修改建议应该进入不同目标路径
这一层更像是给 AI 立规矩,而不是给我自己存知识。
2. mirror,是 AI 的输入层
mirror 不是真正的知识库,它只是从 COS 拉下来的只读快照,用来给 OpenClaw 提供“可参考的内容”。
最开始我全量拉了整个仓库,后来很快发现这不是最优方案,因为 AI 一开始并不需要理解我所有的项目、领域、资源,它只需要先处理和 AI 协作直接相关的部分。所以后来我把同步范围缩小到了专门的 AI 工作区,而不是整个 Vault。
3. proposals,是 AI 的输出层
这是我很满意的一个设计。所有 AI 产出的内容,不管是新写的文档,还是对已有内容的修改建议,都必须先进入 proposals/。也就是说,AI 的职责不是“直接写进知识库”,而是“提交一个待审草稿”。
我需要检查一下他写的内容再进入我的知识库,而不是让AI生产一堆假大空的文章,埋在里面不见天日。
4. Obsidian,是最终的长期知识层
Obsidian 依然是我真正认可的知识沉淀空间,凡是进入这里的内容,默认都是经过我确认过的。它是长期存储、查阅和组织的地方,而不是 AI 的临时工作内存。
四、我最后给 Obsidian 单独划了一个 AI 工作区
为了不让 AI 的产出直接混进我原有的知识目录,我在 Vault 里单独建了一个工作区:
Vault/├── 06AI_workspace/│ ├── 00AI_Inbox/│ ├── 01AI_Drafts/│ └── 02System/│ ├── AI_RULES.md│ └── TEMPLATE.md├── (其他正常知识目录)
这套结构其实非常直观。
00AI_Inbox 用来放 AI 新生成的内容,也就是“新东西先放这里,之后再决定要不要整理进正式知识结构里”;01AI_Drafts 用来放 AI 对已有内容的修改建议,也就是它不直接去改原文,而是先给出一个修订版本或者修订提案;02System 用来放规则、模板和说明文档,相当于这个协作系统的制度层。
这个设计有一个很大的好处,就是边界特别清楚。以后无论是我自己还是 AI,都知道哪些内容是“工作中的”、哪些内容是“正式沉淀的”。
五、踩坑最多的一步,不是脚本,而是环境安装
真正开始动手的时候,我遇到的第一个大坑其实不是同步逻辑,而是环境问题。
因为我的服务器是 Ubuntu / Debian 系,系统 Python 开了 PEP 668 的 externally managed environment 保护,所以直接执行 pip install coscmd 会报错。这一步如果以前没遇到过,很容易以为是自己装错了,但其实不是。
正确的做法,是单独给 coscmd 建一个虚拟环境。也就是先安装 python3-venv,然后:
source ~/venvs/coscmd/bin/activatepip install -U pippip install -U coscmd
后面为了避免每次还要手动激活环境,我在脚本里都直接写了绝对路径:
COSCMD="$HOME/venvs/coscmd/bin/coscmd"这样无论是 sync.sh 还是 publish.sh,都不会依赖当前 shell 是否已经激活虚拟环境。
六、sync.sh:让 OpenClaw 只读知识,不直接碰仓库
我认为:AI 不是读得越多越聪明,而是读得越相关越稳定。
一开始我的 sync.sh 是全量拉整个 Vault,后来发现这样太重,而且不符合“最小必要输入”的原则,所以最后改成了只同步 AI 工作区里的必要目录。
最终思路是:
00AI_Inbox、01AI_Drafts、02System分别单独拉mirror 只作为只读快照使用 发布后会触发一次主动刷新 平时再用低频 cron 做兜底
精简之后,这个同步脚本的意义就很明确了:它不是把整个知识库搬到服务器,而是给 OpenClaw 提供一份“刚好够用”的输入环境。
七、publish.sh:把 AI 的草稿,安全地发布回知识系统
这套系统真正闭环的关键,不是 sync,而是 publish。
因为只有 publish 打通了,AI 才不只是“能读”,而是“能真正参与知识协作”。
我的做法是,publish.sh 不写本地 Vault,也不碰 mirror,而是把我确认过的 proposal 上传到 COS 中 06AI_workspace 对应的路径。
逻辑很简单:
如果 proposal 的 frontmatter 里写的是 target: AI Inbox,就发布到00AI_Inbox否则发布到 01AI_Drafts上传成功后,把 proposal 从 proposals/移到published/最后自动触发一次 sync.sh,刷新 mirror
这样,整个过程就变成了:
OpenClaw 生成草稿→ proposals/→ 我确认→ publish.sh 上传到 COS→ 本地 Obsidian 同步回来→ mirror 自动刷新
这一步做完之后,我第一次真正有了那种“AI 已经接进知识系统里了”的感觉。
八、验证闭环之后,我才意识到这套系统真正解决了什么问题
当测试文件成功从服务器上传到 COS,再同步回本地 Obsidian 的那一刻,我突然意识到,我搭出来的其实不是一个“自动写笔记脚本”,而是一套有边界、有状态、有发布机制的知识协作系统。
它解决的不是单一功能,而是几个更根本的问题。
它解决了 AI 没有记忆的问题,因为 OpenClaw 有自己的 workspace 和 memory; 它解决了 AI 乱改知识库的问题,因为 AI 永远只能写 proposal; 它解决了多端知识同步的风险,因为正式入库走的是 COS 的既有链路,而不是服务器直接碰本地 Vault; 它解决了可回溯性的问题,因为 COS 开了版本控制,proposal、published、rejected 也保留了状态。
说到底,我需要的从来不是“一个会写字的 AI”,而是“一个能在规则内持续协作的系统”。
九、现在这套系统怎么用,已经变得非常清楚了
当它真正跑通之后,如何让Openclaw使用就是很简单的事情了,我选择让他根据我的思路写了一个SKILL。
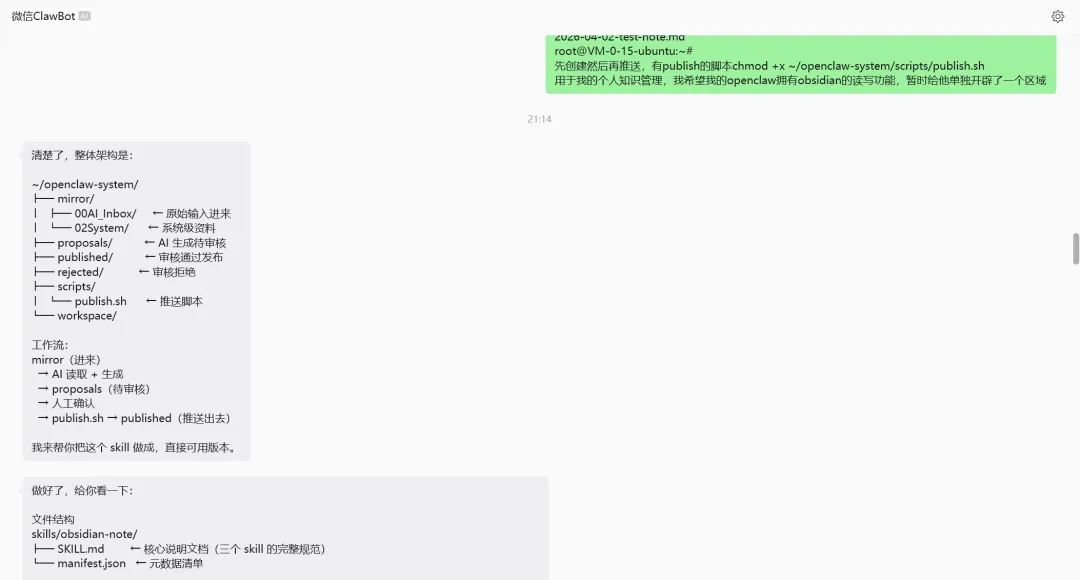
如果我要问问题,就让 OpenClaw 读 mirror;如果我要让它写内容,就让它输出到 proposals;如果我认可了某一篇草稿,就执行:
bash ~/openclaw-system/scripts/publish.sh 文件名.md
然后系统会自己完成上传、刷新、同步这几个动作。
也就是说,AI 在这里不是一个“随时会对我的系统乱动手”的自动代理,而是一个带有明确权限边界的协作助手。
十、接下来,我真正想做的不是继续折腾基础设施,而是把“使用方式”固化下来
现在基础链路已经打通了,后面最有价值的工作,其实不是继续优化脚本,而是把使用方式标准化。
比如,我已经越来越明确地感觉到,“基建”配置我已经搞定了,剩下我的OpenClaw根据我的对话就可以执行了,那么后续我可能想要继续优化我的很粗糙的skill,实现我的All in One。
十一、最后总结一下这套方案的本质
如果要用一句话概括我这次整个实践,我会这样说:
AI 提建议,系统做隔离,人做最终决策。
它不是一个“AI 自动帮我管理知识库”的激进方案,而是一套更稳、更适合长期使用的知识协作架构。它让 AI 有能力参与,但不让它越过边界;它让知识流动起来,但不牺牲可控性;它让自动化真正服务于日常使用,而不是制造新的混乱。
对我来说,这套系统到这里还不是终点。后面我还会继续做 skill、优化工作流,甚至可能继续探索我的整个知识管理体系的方向。
