 夜雨聆风
夜雨聆风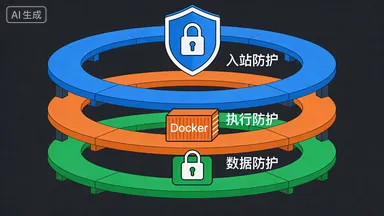
当一个 AI Agent 可以读写文件、执行命令、操控浏览器、访问你的聊天账号时,安全就不再是"可选项"——它是生存条件。OpenClaw 的安全模型不是事后补丁,而是从架构层面设计的三层纵深防御体系。
三层防护架构
OpenClaw 的安全跨越三个边界:入站、执行、数据。
第一层:入站防护
入站防护解决的问题是:谁可以与 Agent 对话?
| DM 配对验证 | security.dm_pairing: true | |
| 显式白名单 | security.whitelist: [user_id_1, user_id_2] | |
| 群组提及门控 | security.require_mention: true | |
| 速率限制 | security.rate_limit: 10/min |
这些机制确保了 Agent 不会被陌生人滥用,也不会在群组中被无关消息触发。
第二层:执行防护
执行防护解决的问题是:Agent 可以做什么?
| Docker 沙箱 | |
| 8 层工具策略 | |
| 提升模式 | |
| 命令审批 | rm -rf、sudo)需要人工确认 |
| 超时控制 |
第三层:数据防护
数据防护解决的问题是:数据存储在哪里?谁可以访问?
| 本地存储 | |
| 记忆作用域 | |
| 凭证独立管理 | ~/.openclaw/credentials/,与会话数据分离 |
| 网络回环隔离 | 127.0.0.1:18789,外部无法直接访问 |
| 会话加密 |
三个权限级别
OpenClaw 定义了三个递进式的权限级别:
non-main | ||||
main | ||||
elevated |
权限切换是显式的——Agent 不能自己提升权限,必须由用户主动切换。这防止了 Agent 被提示注入攻击后自动获取高权限。
Docker 沙箱:隔离的艺术
Docker 沙箱是 OpenClaw 执行防护的核心。当 Agent 在非主会话中执行命令时:
沙箱架构
用户消息 → Agent 决定执行命令 → 检查会话类型 ├── 主会话 → 直接在宿主机执行(受工具策略限制) └── 非主会话 → 创建 Docker 容器 → 挂载工作区(只读或读写,取决于策略) → 在容器内执行命令 → 返回结果 → 销毁容器(可配置保留)沙箱限制
| 文件系统 | |
| 网络 | |
| 资源 | |
| 时间 | |
| 权限 |
沙箱的实际效果
假设一个恶意提示试图让 Agent 执行 rm -rf /:
入站防护:如果发送者不在白名单中,消息被拒绝 工具策略:如果当前会话的策略禁止 exec,命令被拒绝命令审批:如果启用了审批工作流,命令需要人工确认 Docker 沙箱:即使命令执行,也只影响容器内的文件系统 超时控制:命令超时后自动终止
五层防护,任何一层都足以阻止攻击。
安全审计与监控
OpenClaw 提供了完整的安全审计能力:
| 操作日志 | |
| ACP Provenance | |
| 异常检测 | |
| 会话回放 |
已知安全问题与社区响应
OpenClaw 的安全模型并非完美。社区和安全研究者发现了一些值得关注的问题:
localhost 信任问题
正如 Adaptavist Group 的分析指出:OpenClaw 自动批准来自 localhost 的连接,因此任何部署在标准反向代理后面的实例,看起来都会默认认证所有流量。
社区响应:后续版本增加了基于 token 的认证,即使是 localhost 连接也需要提供有效 token。
技能供应链安全
OpenClaw 的技能生态系统面临供应链攻击风险:
恶意技能可能窃取凭证 技能更新可能引入后门 缺乏技能签名验证
社区响应:建议将每个技能视为不受信任的代码,实施严格的扫描、版本锁定和持续监控。
提示注入防护
AI Agent 面临的独特威胁——提示注入攻击:
恶意网页内容可能包含隐藏指令 群组消息中可能包含针对 Agent 的攻击 工具返回的结果可能被篡改
OpenClaw 的防护:
群组会话默认 non-main权限,限制可用工具工具结果经过清理,移除潜在的注入内容 敏感操作需要 elevated权限,需用户显式确认
最佳实践
社区总结的安全最佳实践:
| 渐进式信任 | |
| 最小权限 | |
| 定期审计 | |
| 版本锁定 | |
| 网络隔离 | |
| 备份 |
与其他框架的安全对比
| 权限级别 | ||||
| 沙箱 | ||||
| 工具策略 | ||||
| 入站防护 | ||||
| 数据隔离 | ||||
| 审计日志 |
总结
OpenClaw 的安全模型是目前开源 AI Agent 框架中最全面的设计之一。三层纵深防御(入站/执行/数据)、三个权限级别、8 层工具策略、Docker 沙箱——这些机制共同构成了一个可以在生产环境中安全运行的 AI Agent 系统。
安全不是功能的对立面,而是功能的基础。OpenClaw 证明了:一个强大的 AI Agent 可以同时是一个安全的 AI Agent。
参考链接
Penligent - Hardening the OpenClaw AI Frontier Penligent - OpenClaw Security Audit The Agent Stack - Security Boundaries, Tool Risk, and Authorization Adaptavist - OpenClaw's Three-Layer AI Security Failure Traefik - OpenClaw, NemoClaw, and Application-Layer Security lzw.me - OpenClaw Security Guide NextGenTechInsider - OpenClaw Skill Ecosystem Security Flaws
