 夜雨聆风
夜雨聆风谷歌的Gemma4开源,让我们的龙虾本地化自由
谷歌的Gemma4模型本地化部署
先看看你的电脑有多少内存,基础版本只需要8GB运行内存就能流畅跑起来,即便是普通办公本也能hold住,不用专门升级昂贵的高端显卡,对普通玩家太友好。
第一步 先安装Ollama
不管你是用Mac、Windows还是Linux系统,直接去Ollama官网下载对应安装包,点几下下一步就能完成安装,全程都是图形化操作,完全不用折腾复杂的命令行。
第二步 打开电脑的终端工具
只需要在终端输入一行命令:ollama run gemma:4b
剩下的工作Ollama会自动完成,从拉取模型到配置环境全都是自动处理,你只需要喝杯茶等个几分钟就行。
安装完成直接就能在终端里对话。
第三步 再下个OpenClaw接入
所有调用都在本地完成,
不用把数据传到第三方服务器
不用担心隐私泄露,关键是真的一分钱都不用花。
原本调用大模型接口每万token就要收几毛钱,跑几个项目下来 token 成本就是一笔不小的开销。
现在把Gemma 4装在本地
不管你是做个人开发测试,还是给小项目搭智能助手
token 直接用多少都不花钱。
养龙虾这事儿真就能零成本实现了。关键是安全安全,数据安全了。
而且这次Gemma 4用的是Apache 2.0协议,不光个人用免费,就算是商用开发、自己改模型结构、重新分发版本全都是合规的,搭配Apple Silicon芯片用MLX框架推理,响应速度比之前旧模型快了一倍,打字刚结束回答就出来,用着和线上云模型一样顺滑。
手机、笔记本都能用
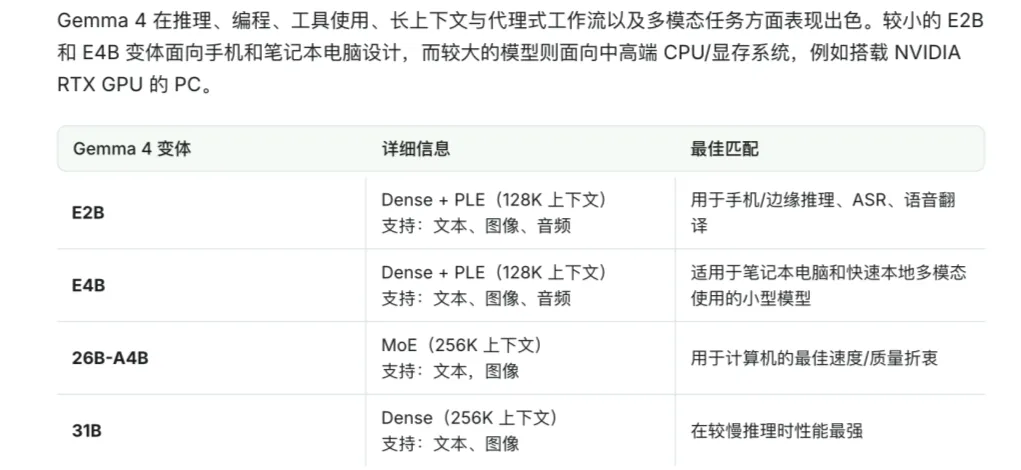
谷歌最新推出的Gemma 4系列
四个不同定位的版本几乎覆盖了从入门到发烧友的全场景需求,哪怕是以4-bit量化后的部署门槛来看,对普通用户也相当友好。
最小的Gemma 4 E2B参数只有23亿,量化后只需要大概4GB内存就能运行,不光支持图片、音频多模态输入,还能hold住128K的长上下文。
别说普通的轻薄本,就算是智能手机或者单板的树莓派都能顺畅跑起来,出门在外也能随时拉起自己的本地AI。
往上一档的E4B总参数45亿,4-bit量化后占用约5.5GB内存,同样保留了图文音多模态能力和128K上下文,性能刚好适配日常闲聊、信息查询这类普通需求,普通的家用笔记本就能轻松装下,日常用起来基本不会有滞涩感。
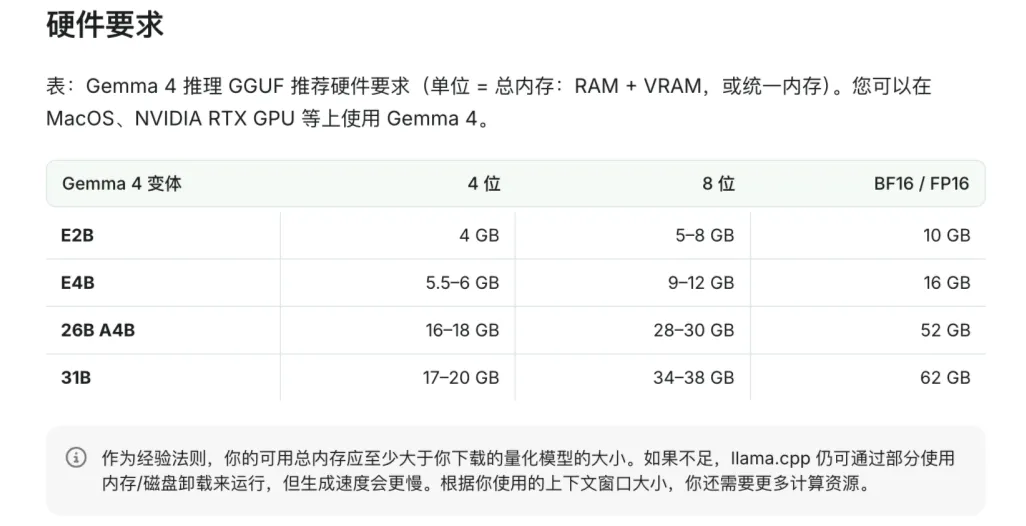
如果你想要更强的推理能力,又不想付出太高的硬件成本,26B这个混合专家架构版本绝对是性价比首选。它采用MoE架构,总参数虽然达到了252亿,但每次推理只会激活38亿参数,4-bit量化后只占用16到18GB的内存,支持256K的超长上下文,还能处理图片输入,只是暂不支持音频,推理速度接近小参数模型,输出质量却直逼满血版,只要你的Mac设备内存达到24GB,或者独立显卡有24GB显存就能流畅带动,大部分中端游戏本都能满足这个要求。追求极限性能的发烧友可以选择满血版31B,它的307亿参数全程全激活,4-bit量化后占用17到20GB内存,同样支持256K长上下文,在Arena AI开源模型排行榜上高居第三名,AIME 2026数学推理准确率达到89.2%,编程测评LiveCodeBench也拿到了80.0%的好成绩,是四个版本里跑分成绩最猛的。这个版本就算用24GB内存/显存的设备也能跑,但运行时会比较吃紧,如果你的设备有32GB的内存或者显存,用起来会流畅舒服很多。
本地模型安装
不少想在本地玩大语言模型的朋友总是发愁不知道怎么选配置,其实照着这个标准选就基本不会踩坑:4GB显存就能跑E2B模型,6GB显存可以流畅跑E4B,18GB显存就能拿下26B参数的模型,要是你的显存能到20GB以上,跑31B参数的大模型也完全没问题。
如果你是Mac用户,上手本地大模型其实特别简单,先直接去ollama.com下载安装Ollama就可以,习惯用Homebrew的朋友也可以直接输一行命令安装,就是brew install --cask ollama-app。
Ollama算得上是目前普通用户跑本地大模型最简单的工具之一了,从模型下载到推理引擎配置,再到API服务部署,一个App就能全部搞定,不需要你折腾复杂的环境配置,对新手特别友好,装完就能直接上手用。
如果有任何技术问题请留言
欢迎咨询「李老雷喊你一起玩AI」
