 夜雨聆风
夜雨聆风Claude Code 技能包已开源: 这套方法论已打包为可直接调用的 Claude Code Skill,让 Claude 自动审计你的 AI 系统并给出改进方案。→ GitHub 获取[1]
我最近在做一个东西:让 AI 自动生成企业应用。
输入一段需求描述,AI 自动规划工作表结构、设计字段、造数据、创建视图、生成图表——一套完整的业务应用,几分钟出来。我叫它 HAP Auto Maker。
在把这个系统搭起来、调通、踩坑、重构的过程中,我把每一个调试经验、每一个设计决策写成了一份内部方法论。这篇文章就是把这份方法论整理出来,分享给所有在做类似事情的人。
这11条原则,不只适用于 AI 工程。任何有复杂流程、多步骤、调用外部 API 的系统,都用得上。
1. 分步拆解(Decomposition)
原则:把一个大任务拆成多个独立小步骤,每步职责单一。
大任务给 AI,AI 的上下文会被稀释,输出质量会下降。更致命的是,出了问题你不知道问题在哪。
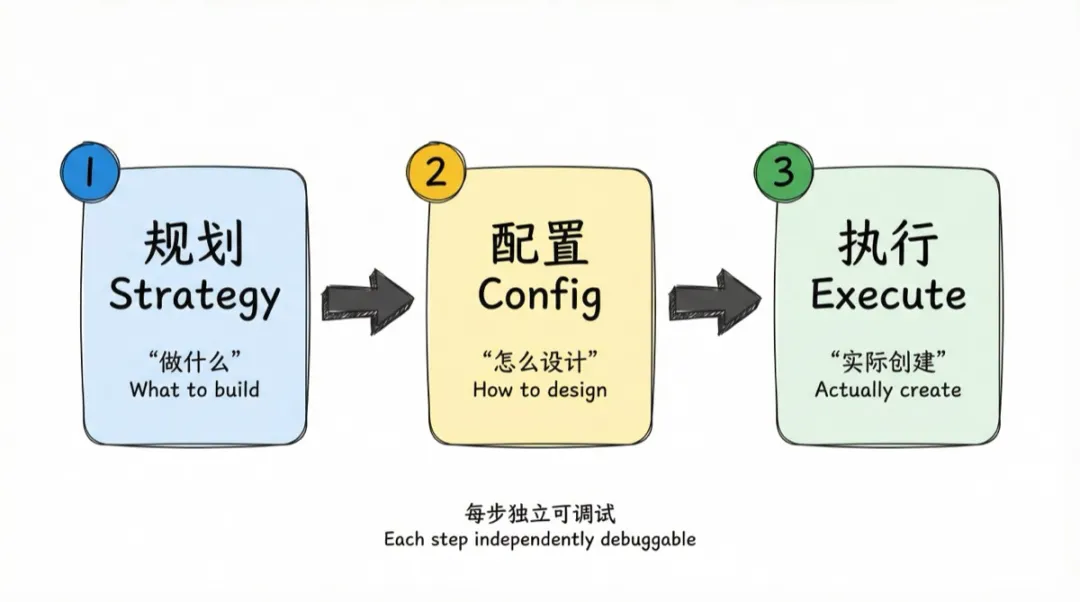
我的 pipeline 分成了"规划→配置→执行"三个阶段:先让 AI 规划有哪些工作表,再逐表细化字段,最后执行创建。三个阶段,三个独立脚本,每步可以单独调试、单独重跑。
判断标准: 一步里如果有两件不相关的事,就该拆。"决定做什么"和"怎么配置参数"就是两件事。
2. 硬约束前置过滤(Hard Constraint Gating)
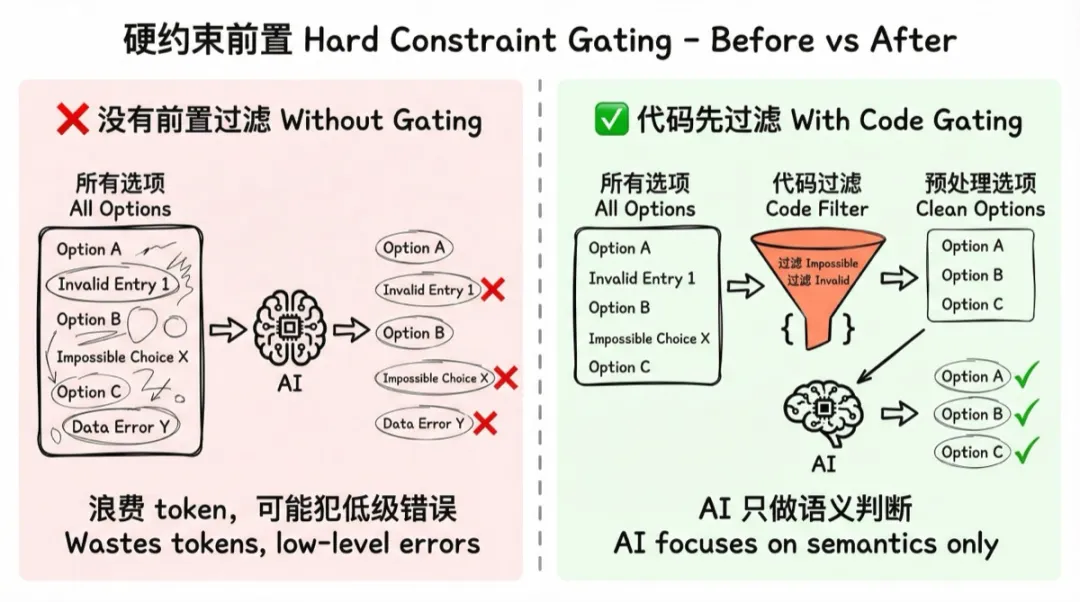
原则:在调用 AI 之前,先用代码把不可能的选项过滤掉。
AI 的能力在于语义理解和创意输出,但它不应该浪费 token 去判断一些纯粹靠规则就能确定的事。
视图推荐是最典型的例子。日历视图需要日期字段,地图视图需要定位字段,分组视图需要单选字段。在把工作表丢给 AI 之前,代码先扫一遍字段,没有日期字段就把日历视图从候选池里移出去。AI 只在"可行的选项"里做语义判断,不会推荐出一个根本无法创建的视图类型。
图表也是一样。没有日期字段,就把折线图从候选里移除;没有数值字段,就移除数值图和仪表盘。这些判断,两行代码就能做,没必要靠 prompt 去约束 AI。
好处是双重的: 减少 AI 犯低级错误的概率,同时减少 token 消耗。
3. 步间校验(Inter-step Validation)
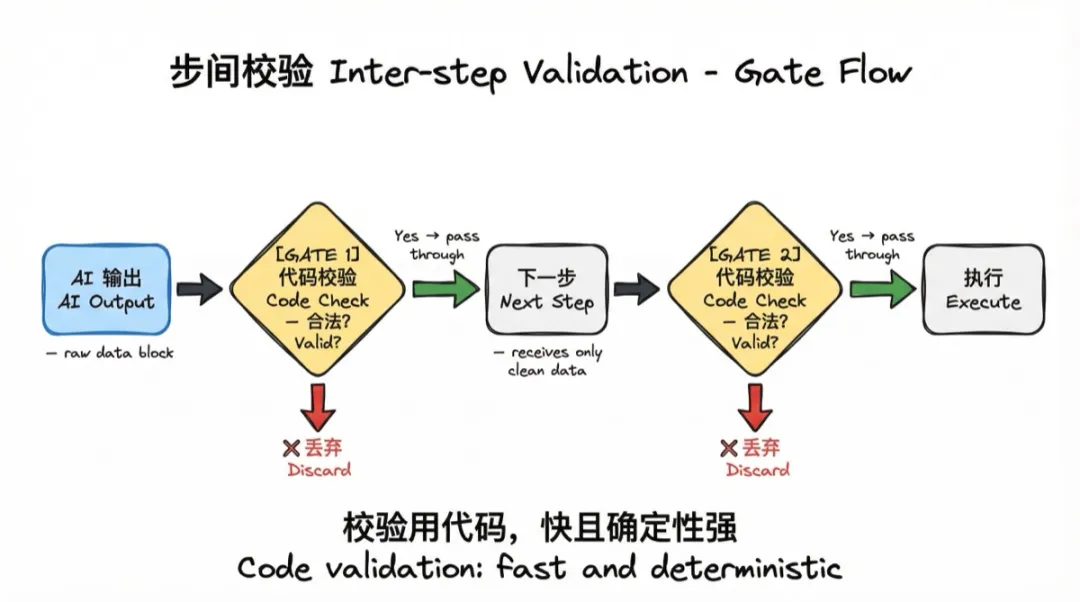
原则:每步 AI 输出之后、传给下一步之前,插入代码校验。不让脏数据往下走。
AI 输出的 JSON 可能缺字段、类型错误、关联引用不存在。不校验直接用,错误会在最不该出现的地方爆发,而且很难定位。
在工作表规划阶段,AI 输出骨架后,代码会校验:
• 每个工作表有没有名称 • 关联字段引用的目标表是否存在于同一规划中 • creation_order 是否满足拓扑顺序(被依赖的表先创建) • 单选/多选字段有没有填 option_values
不通过就修正或丢弃,不传给下一步。这套校验用代码做,快、确定性强。用 AI 做校验是大材小用,也不可靠。
4. 隔离性(Isolation)
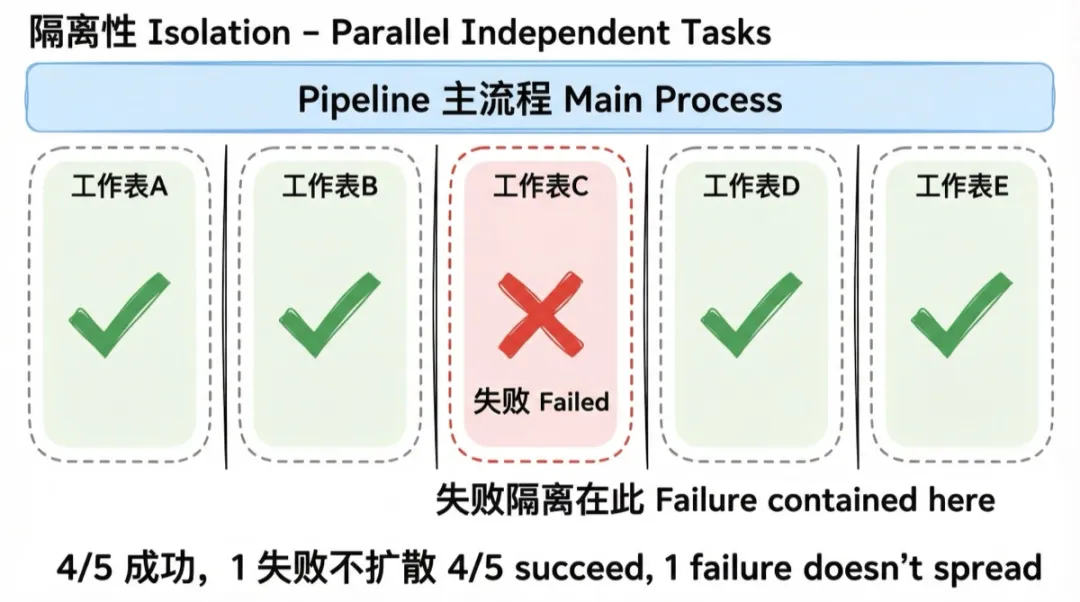
原则:单个子任务失败,不影响其他子任务。
这个原则看起来显而易见,但真正做到需要刻意设计。
最常见的反模式:一个循环里处理多个工作表,一张表出错直接 raise,后面所有表全部跳过。
正确做法:每个子任务用独立的 try/catch 包裹,失败记录到日志,继续执行下一个。单个工作表的字段配置出错,该表跳过,其他表不受影响;单个图表规划失败,该图表丢弃,其他图表继续创建。
我的 pipeline 里,10 个工作表并行规划,任何一个失败都只影响自己,其余 9 个照常完成。这一点对用户体验的影响非常大——原本需要整体重跑的,现在顶多局部重试。
5. 降级优先(Graceful Degradation)
原则:遇到错误时,优先降级,不要整体失败。
这是隔离性的延伸,但粒度更细。
创建视图时,某个高级配置(advancedSetting)某个 key 格式不对,不要因为这个让整个视图创建失败。移除那个 key,用默认值继续创建。视图创建出来了,配置不完整,但用户至少有一个可用的视图。
这比"全部重来"的代价小得多。在 AI 生成的内容里,局部错误是常态,不是异常——你的系统要有能力吸收这些局部错误,而不是被它们击垮。
判断边界: 核心结构错误(工作表名称缺失、关联目标不存在)应该拒绝并记录;细节配置错误(颜色格式错、描述字段超长)应该修正后继续。
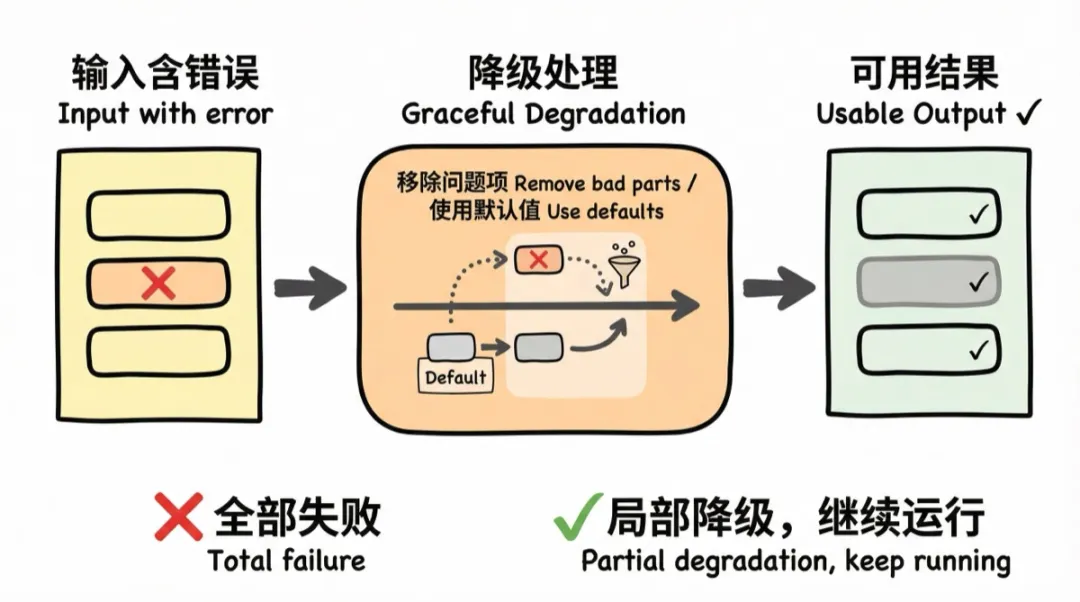
6. 幂等性(Idempotency)
原则:重复执行同一步,不产生重复数据。
这是调试体验的关键。
系统跑到一半失败了,你重跑,结果之前已经创建成功的部分又创建了一遍——10 张工作表变成了 20 张。这种情况会让你不敢重跑,每次都得先手动清理。
做法:创建之前先检查是否已存在。工作表——先查应用里有没有同名工作表,有就跳过;角色——--skip-existing 参数,已存在的角色不重复创建。
幂等性让你可以放心重跑整个 pipeline,不用担心产生垃圾数据。
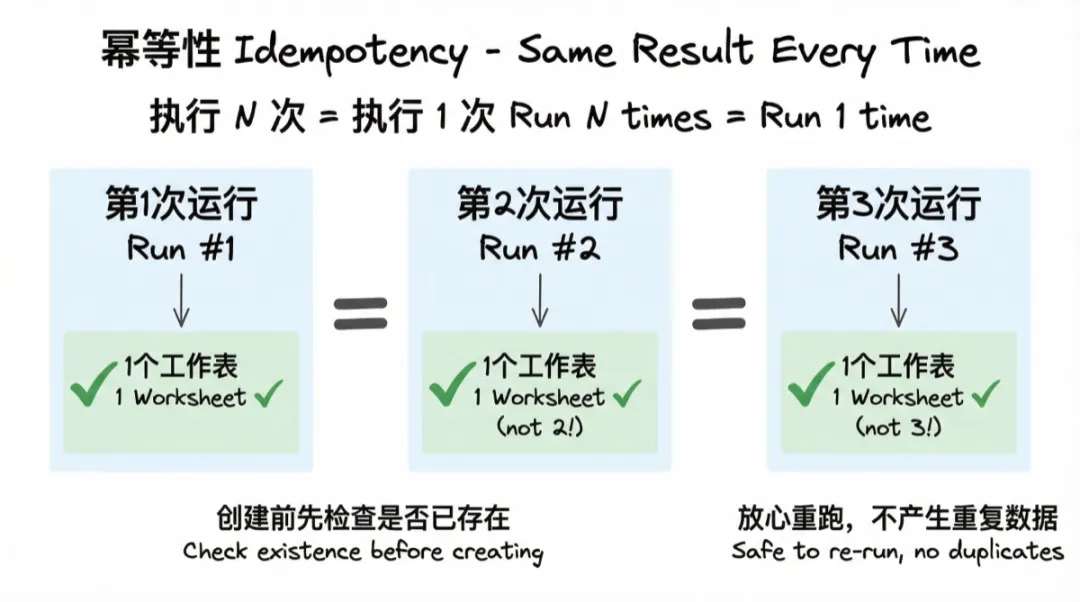
7. 断点续跑(Resume / Checkpoint)
原则:每步输出都持久化。重跑时检测中间产物是否已存在,存在则跳过。
这是幂等性的升级版。幂等性解决的是"不产生重复数据",断点续跑解决的是"不重复做已经做过的事"。
工作表规划需要调 3 次 AI(骨架 + 逐表细化),花费大量 token 和时间。如果规划已经完成但后续步骤失败,重跑时应该直接用已有的规划结果,跳过 AI 调用,从创建阶段开始。
实现方式:每步开始前检查输出文件是否存在且内容合法,存在则加载并跳过。文件名要用确定性命名(基于 app_id),而不是带时间戳的随机名——带时间戳的文件每次都生成新文件,找不到上次的结果。
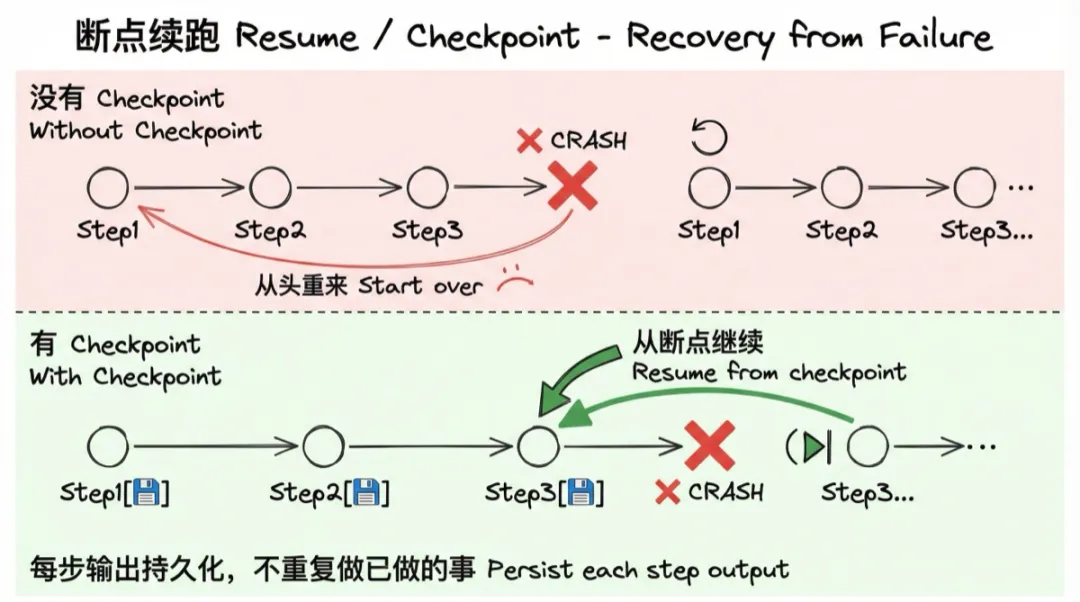
8. 干跑(Dry Run)
原则:每一步都支持只输出计划、不实际执行。
调 prompt 的时候,你不想每次都真的创建一堆工作表;验证流程逻辑的时候,你不想操作真实数据。
--dry-run 模式让整个 pipeline 正常运转,但所有实际 API 调用都被跳过,只打印出"会做什么"。你能看到完整的执行计划,验证逻辑正确,再正式跑。
这个功能的价值在调试阶段被放大了 10 倍。从 "跑一次就创建了一堆垃圾数据,然后手动删" 变成 "随便跑,没有副作用"。
9. 可观测性(Observability)
原则:每步记录耗时、token 消耗、重试次数、丢弃原因。Pipeline 结束后输出可读 summary。
不可观测的系统是黑盒,出了问题只能凭感觉猜。
一个好的 summary 应该让你一眼看到:
工作表「订单」: 规划 2.1s → 字段细化 3×1.8s → 创建 3×0.5s | 3/3 成功工作表「客户」: 规划 1.9s → 字段细化 2×1.5s → 创建 2/2 成功工作表「物流」: 规划失败(重试 2 次)| 跳过总计: 5/5 工作表创建成功, 1 表跳过, AI tokens: 12,340, 总耗时: 8.2stoken 消耗数据特别重要:知道每步花了多少 token,才能有针对性地优化 prompt、评估成本。如果每次跑都是黑盒,你永远不知道优化是否有效。

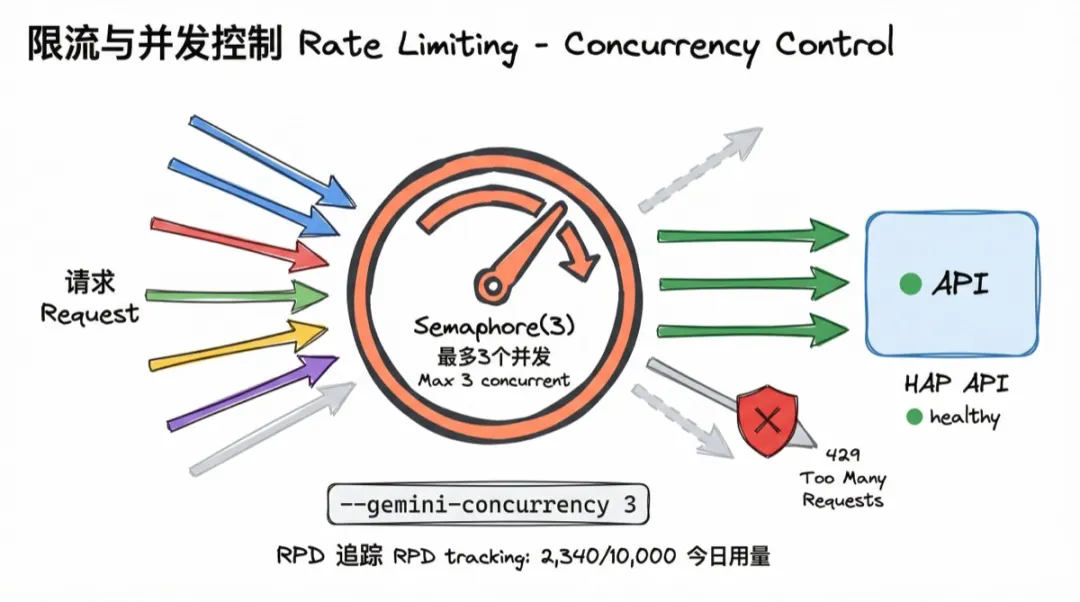
10. 限流与并发控制(Rate Limiting)
原则:用参数控制并行度,不要让并发冲垮外部服务。
并行执行能大幅缩短耗时,但并行度太高会触发 API 限流(429 错误),反而变慢,严重时会被封。
我用信号量(Semaphore)控制同时调用 AI API 的数量,--gemini-concurrency 参数可以调整。同时按天追踪 RPD(Requests Per Day)用量,快到上限时提前预警。
对外部 API 的每一次并发调用,都要问自己:对方的 rate limit 是多少?我当前的并发设置会不会超?有没有重试逻辑?
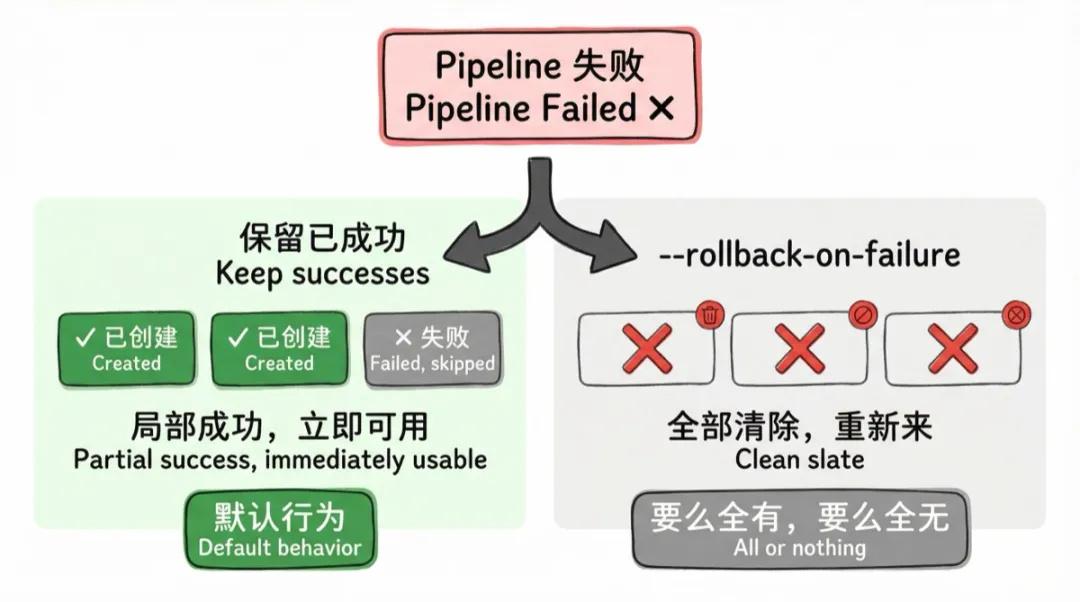
11. 回滚(Rollback)
原则:失败时可选择清理已创建的数据。
这是成本和一致性的权衡。
默认策略是保留已成功的——跑了一半,成功的工作表留着,失败的不管。这在大多数场景下是合理的:局部成功总比全部没有要好。
但有时候你需要"要么全成功、要么全没有"——比如给客户演示用的应用,半成品不能给人看。这时候需要 --rollback-on-failure,失败时把整个应用删掉,重新来。
这个功能必须是可选的、显式触发的,不能是默认行为。保留部分成果是更安全的默认策略。
这11条的优先级
如果你现在要从零开始用这套方法,按这个顺序来:
1. 分步拆解 — 基础,其他所有方法都建立在此之上 2. 硬约束前置 — 能用代码解决的事不要交给 AI 3. 步间校验 — 脏数据止步于每步边界 4. 隔离性 — 局部失败不扩散 5. 降级优先 — 能用就用 6. 幂等性 — 放心重跑 7. 断点续跑 — 不从头来 8. 可观测性 — 知道发生了什么、花了多少 9. 干跑 — 安全调试 10. 限流 — 保护外部服务 11. 回滚 — 按需要
前五条是正确性,后六条是工程体验。正确性优先,体验其次。
最后说一句
这份方法论是从真实项目里蒸馏出来的。每一条背后都有具体的 bug、具体的调试记录、具体的"当时如果这样做就好了"。
AI 让写代码变快了,但它没有让软件工程变简单。恰恰相反——AI 系统的不确定性更高,更需要这些工程原则来保证稳定性和可维护性。
AI 给你的是速度,工程原则给你的是可靠性。两个都要。
用 Claude Code 自动审计你的系统
这套方法论已打包为 Claude Code Skill,可以让 Claude 自动扫描你的代码库、对照这 11 条原则逐一打分、输出优先级排序的改进计划。
安装:
claude plugin install https://github.com/andyleimc-source/ai-engineering-principles-skill使用:
在 Claude Code 中输入 /engineering-principles,Claude 会读你的 pipeline 代码,输出一份审计报告——哪些原则已经实现,哪些有缺口,该从哪里开始补。
→ GitHub 仓库[1]
老雷(Andy),明道云 & Nocoly CMO,SaaS 行业从业十余年。骨子里是个产品人和技术迷,乔布斯的信徒,相信好的产品能改变世界。深度关注 AI、商业与科技趋势,目前在深度使用和实践 Claude Code,专注探索 AI 如何重塑产品形态和商业逻辑。不聊概念,只聊真实发生的事。
引用链接
[1] GitHub 获取: https://github.com/andyleimc-source/ai-engineering-principles-skill
