 夜雨聆风
夜雨聆风
AI即人工智能(Artificial Intelligence)。很多人提到人工智能,第一反应都是“这是最近十年才冒出来的黑科技”,是ChatGPT带火的新鲜事物。但如果你翻开AI的发展史就会发现,人类对“造一个会思考的机器”的梦想,早在两千多年前就埋下了种子,这一路经历了七十多年的起落,才走到今天的全民共享AI时代。


早在公元前100年的古希腊,人类就造出了第一台能自动计算的机器——安提凯希拉装置。这台被考古学家称为“世界上第一台模拟计算机”的青铜机器,由30多个精密的青铜齿轮组成,只要你转动手柄输入日期,它就能自动算出太阳、月亮的位置,甚至能提前几十年预测日食月食。
根据美国机械工程师协会(ASME)的公开研究,这台机器的精密程度,直到17世纪的欧洲才重新造出类似的结构——也就是说,两千多年前的古希腊人,就已经用齿轮,把“用机器代替人计算”的梦想,变成了实实在在的金属造物。

而在遥远的东方,中国人发明的算盘,其实也是早期的计算工具:它用珠子的位置代表数字,通过手动拨动完成加减乘除,本质上就是一台手动的“计算设备”,帮助古人解决了大量的计算难题。
从那之后,人类对“自动计算”的探索就没停过:13世纪的学者罗杰·培根就提出,能不能造出机器,代替人完成繁重的计算;17世纪的帕斯卡造出了加法机,能自动做加减法;19世纪的巴贝奇设计了差分机,已经有了现代计算机的雏形——这些,都是AI诞生前的铺垫。


真正的现代AI,要从20世纪的理论奠基开始。1936年,24岁的艾伦・图灵发表了论文《论可计算数及其在判定问题上的应用》,提出了“图灵机”这个思想实验:一个无限长的纸带,加上一个读写头,就能完成任何可计算的任务。这篇论文,直接定义了现代计算机的理论基础,也为“机器能不能思考”这个问题,打下了理论的地基。
14年后,也就是1950年,图灵又发表了那篇大名鼎鼎的《计算机器与智能》,提出了著名的“图灵测试”:如果一台机器,能和人聊天,而人分辨不出它是机器,那它就可以被认为是智能的。这篇论文,直接给人工智能定下了终极的评价标准,直到今天,我们还在用这个框架,来衡量机器的智能程度。
到了1956年的夏天,一切都迎来了转折点。约翰・麦卡锡、马文・明斯基、克劳德・香农这些后来的AI大牛,在达特茅斯学院开了一个夏季研讨会,会上,麦卡锡第一次提出了“人工智能(Artificial Intelligence)”这个术语,正式把AI变成了一个独立的学科。

根据达特茅斯会议的公开提案,这些科学家当时甚至乐观地认为:“我们认为,只要让一群科学家一起研究一个夏天,就能解决机器智能的大部分问题。”
谁也没想到,这个梦想,一走就是七十多年。


很多人不知道,AI其实经历过三次热潮,两次寒冬,才走到今天。
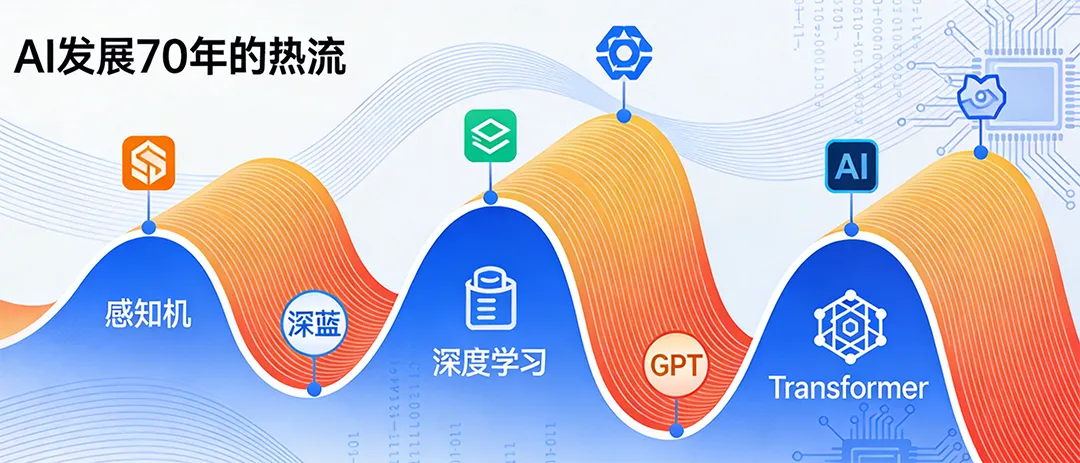
第一次热潮与寒冬(1956-1974)
达特茅斯会议之后,AI迎来了第一次爆发:科学家们造出了感知机,也就是最早的人工神经元,能做简单的分类;专家系统能帮医生看病、帮工程师解数学题;当时的IBM甚至预言,十年之内,计算机就能成为世界象棋冠军。
但很快,现实就给了所有人当头一棒:当时的计算机算力太差了,一个简单的任务,就要花掉几个小时的计算时间;而且当时的AI只能解决非常简单的问题,稍微复杂一点的常识推理,就完全搞不定。
到了70年代,政府和资本发现,AI根本达不到之前吹的牛皮,钱烧完了,却没什么实际的成果,于是第一次AI寒冬来了:大量的研究项目被砍,科学家们转行了,AI变成了没人敢碰的“骗子行业”。
第二次热潮与寒冬(1980-1993)
到了80年代,AI又活过来了:反向传播算法被重新发现,解决了神经网络的训练难题;IBM的深蓝,在1997年击败了国际象棋世界冠军卡斯帕罗夫,震惊了全世界。
但这一次,热潮又很快退去:专家系统太贵了,一个企业要花几百万美元才能部署,根本用不起;神经网络还是解决不了复杂的问题,比如语音识别,准确率一直上不去。到了90年代,资本又一次撤资,第二次AI寒冬来了。
第三次浪潮:深度学习的爆发(2006-至今)
这一次,终于不一样了。2006年,杰弗里・辛顿发表了论文,提出了深度信念网络,解决了深度学习的梯度消失问题,深度学习正式兴起。2012年,辛顿的团队用深度学习,在ImageNet图像识别比赛中,把错误率直接降了一半,震惊了整个行业。2017年,谷歌发表了Transformer的论文,提出了注意力机制——简单来说,就是让AI读文字的时候,能记住上下文的关系,不会读了后面忘了前面,这直接给大模型打下了基础。然后,就是我们熟悉的:2020年GPT-3发布,2022年ChatGPT上线,2023年GPT-4、Sora陆续推出,AI终于走进了普通人的生活。
这一次的爆发,不是突然的:它是算力的进步——GPU的出现,让计算速度提升了上万倍;是数据的爆发——互联网的普及,给AI提供了海量的训练数据;是算法的迭代——七十多年的积累,终于在这一次,厚积薄发。


误区一:AI是最近十年才突然出现的黑科技?
人工智能并非突然在21世纪20年代出现的技术。“人工智能”这一术语由约翰·麦卡锡于1956年在达特茅斯会议上首次提出,此后六十年间,该领域经历了多次发展浪潮。早期研究者通过符号逻辑和专家系统探索AI可能性,如20世纪70年代的MYCIN医疗诊断系统。当前AI的爆发式增长主要源于三方面技术突破:1) 21世纪10年代深度学习算法的成熟,2) 21世纪20年代算力的指数级提升(如GPU并行计算),3) 大规模结构化数据的可用性。AI技术的今天是数十年研究积累与近期技术突破共同作用的结果,而非单纯的“十年黑科技”。这一误解源于公众对早期AI研究的忽视,以及对“深度学习”等近期技术的过度聚焦。
误区二:AI已经有自我意识了?
目前的人工智能系统,包括最先进的大型语言模型,都不具备自我意识、情感或主观体验。AI的工作原理是通过分析海量训练数据,识别统计模式并生成概率上最可能的响应序列。当AI回答“我理解你的感受”时,它只是在模仿人类在类似情境下的高概率回应模式,而非真正产生情感共鸣。神经科学和哲学领域至今仍未对“意识”形成科学共识,更不用说在AI系统中实现。即使是最复杂的神经网络,其行为也完全由其架构设计和训练数据决定,没有自主意识或意图形成机制。2025年《科学》杂志发表的综述文章指出:当前AI与意识的差距“如同将石器时代与信息时代并置”,需要根本性的理论突破而非单纯的技术优化。
误区三:AI会取代所有人类的工作?
AI确实会改变就业结构,但全面取代人类工作的可能性极低。历史表明,技术革命通常会重塑而非消除工作岗位。AI擅长处理规则明确、重复性强的任务,如数据整理和基础文本生成,但在需要复杂判断、情感互动和创造性思维的工作中表现有限。2025年麦肯锡全球研究院报告显示:AI自动化可能仅取代全球约5%的工作岗位,而创造的新岗位数量将超过被取代的岗位。医生不仅需要分析影像数据,还需考虑患者情绪、病史和生活情境;作家不只是生成文字,更要构思故事和表达情感。AI的真正价值在于辅助人类,解放我们从事重复性工作的时间,让我们更专注于战略决策、创造性表达和人际互动等高价值活动。
误区四:AI的答案都是对的,它什么都知道?
AI并非全知全能的“真理机”,它会犯错误,甚至有时会以非常自信的方式编造错误信息。这种现象被称为“幻觉”或“胡说八道”,源于AI的生成机制:它基于概率预测生成响应,而非验证事实真伪。例如,AI可能会编造不存在的学术论文引用、提供错误的法律条款或生成有漏洞的代码。2024年OpenAI的研究表明:即使是最先进的大语言模型,在事实性问题上的错误率也高达10%—20%。AI的回答需要经过领域专家的严格核查,不能盲目采信。这一误解源于公众对AI生成能力的过度崇拜,忽视了其本质仍是基于统计规律的模式识别系统,而非具备常识判断和事实验证能力的智能实体。
误区五:ChatGPT是第一个通用AI?
ChatGPT是第一个引起广泛关注的通用型AI模型,但它远非第一个通用AI。早在2017年,Google的Transformer架构就展示了处理多任务的能力;2018年,BERT模型在自然语言理解方面取得了突破;2020年,GPT-3已经具备了相当程度的通用性。ChatGPT的创新主要在于其更优的对话生成能力和OpenAI的营销策略,而非技术上的首创性。通用AI的定义是指能在多种任务上表现出接近人类水平的性能,而当前所有AI系统,包括最先进模型,都只能在特定范围内完成任务,无法像人类一样灵活应对各种未知场景。这一误解源于公众对“通用AI”概念的模糊理解,以及对AI技术发展速度的过高估计。

误区六:AI能完全替代人类创造力?
AI能够在艺术、写作等领域生成高质量内容,但这并不意味着它能完全替代人类创造力。AI生成的内容本质上是对训练数据中模式的重组和模仿,缺乏真正的情感表达和价值判断。2025年7月,美国版权局首次批准一幅AI生成图片的著作权登记,但明确指出:只有当人类对AI生成的元素进行了选择、调整和原创性添加时,作品才具备法律认可的“创造力”。例如,《A Single Piece of Cheese》这一作品通过扩大画布、添加第三只眼等人类干预,才获得了版权保护。AI是创造力的放大器而非替代者,它降低了技术门槛,使更多人能够将想法转化为可行方案,但真正的创作灵魂始终来自人类的情感、经验和价值判断。
误区七:AI决策过程完全不可解释?
虽然许多AI模型(尤其是深度神经网络)内部结构复杂,被称为“黑箱”,但AI决策过程并非完全不可解释。近年来,可解释AI(XAI)领域取得了显著进展,开发了多种解释方法,如特征重要性分析、注意力可视化和反事实解释等。这些技术能帮助用户理解AI的决策依据,提高透明度和信任度。然而,XAI也存在局限性:对于复杂模型(如大型语言模型),解释成本高;不同模型类型的解释方法差异大;且解释的准确性和易懂性之间存在权衡。2025年国家自然科学基金委员会发布的《可解释、可通用的下一代人工智能方法重大研究计划》进一步证明,AI可解释性是当前研究的重点,而非不可逾越的障碍。通过适当的工具和方法,AI决策过程可以在一定程度上被理解和解释。
误区八:AI无需人类监督即可安全运行?
尽管AI系统能够自主运行,但完全脱离人类监督的AI应用并不可行也不安全。2025年4月,上海辟谣平台澄清了“AI误诊肺炎致患者险丧命”的谣言,但指出其背后反映了真实问题:AI模型训练数据多来自轻症病例,易漏诊危重患者;现行法规未明确AI误诊追责主体;部分机构为降成本削减人工复核环节。这些情况在医疗、金融等关键领域尤为突出。即使是最先进的无监督学习算法,也需要人类设计学习框架和评估标准。AI的安全运行依赖于持续的人类监督、数据质量控制和责任机制。AI系统本质上是工具,其行为和决策仍需在人类价值观和伦理框架下进行评估和调整。
误区九:AI技术已成熟,无需持续迭代?
虽然AI技术取得了巨大进步,但当前AI技术远未成熟,仍需持续迭代优化。2025年Gartner技术成熟度曲线显示,生成式AI等关键技术仍处于“泡沫破裂低谷期”,表明其潜力已被高估,实际应用价值仍需验证。同时,国家自然科学基金委员会2026年度项目指南将“可解释、可通用的下一代人工智能方法”列为重点支持方向,这直接证明了现有技术的不完善。AI系统面临诸多挑战,包括数据漂移、模型过拟合、“逆转诅咒”(如GPT-4在反向逻辑问题中的正确率从79%骤降至33%)等。此外,AI基础设施和算法仍存在许多理论缺陷,如对计算资源的依赖性强、对噪声和对抗样本敏感等。AI技术的发展是一个长期过程,需要持续投入和优化。
误区十:AI可完全保护用户隐私?
AI系统在处理用户数据时确实采用了各种隐私保护技术,如差分隐私和同态加密,但AI无法完全保护用户隐私。2025年11月,ProfileTree安全研究团队揭示了模型逆向攻击的风险:攻击者可以通过分析模型输出,系统性地重构训练数据中的敏感信息,甚至包括人脸特征。研究表明,即使采用先进的隐私保护技术,如VaultGemma的差分隐私框架,也存在性能与隐私的权衡问题。此外,训练数据本身可能包含历史敏感信息,如果数据集构建不当,AI系统可能无意中泄露这些信息。2026年初,Kratika详细分析了模型逆向攻击的技术路径,包括从人脸识别模型中提取个人信息等场景。AI隐私保护是一个持续挑战,而非已经解决的问题,需要不断开发和改进隐私保护技术,同时建立严格的数据使用规范和监管机制。


从两千多年前的青铜齿轮,到今天的千亿参数大模型,人类用了两千多年的时间,才把“造一个会思考的机器”这个梦想,一点点变成了现实。
我们有过乐观的幻想,有过失望的寒冬,有过突然的爆发,也有过对未来的焦虑。但说到底,AI从来不是什么突然冒出来的黑科技,它是人类几千年的智慧,一点点堆出来的成果。

今天的AI,还只是一个开始,它还没有意识,还会犯错,还只是一个辅助人类的工具。但未来,它会走向哪里?没人知道,但我们知道的是,这一路的探索,从来没有停过,而这,才是人类最了不起的地方。

