 夜雨聆风
夜雨聆风点击下方卡片关注AI病理视界。这里持续追踪病理AI前沿论文、深度行业观察与工具方法更新。我们不只关注模型做了什么,也关注它离真实场景还有多远。
推 文 概 览
今天解读的是一项发表于Nature Cancer的最新研究,题为“PRET is a few-shot system for pan-cancer recognition without example training”。研究团队提出了一个名为PRET(泛癌免示例训练识别系统)的框架,旨在解决当前病理AI模型对海量标注数据和任务特定训练的依赖。
核心亮点是:PRET无需任何模型微调,仅凭几张(1-8张)标注示例WSI,即可在23个基准测试集的20个任务上超越现有方法,甚至在CAMELYON16淋巴结转移检测任务上,仅用8张示例就超越了11位病理学家的平均水平。
在性能光环之下,更应关注其方法学的本质创新及真正的应用边界。PRET的最大价值或许不在于挑战已被充分研究的“红海”任务,而在于为资源匮乏的“蓝海”场景(如罕见病、长尾肿瘤亚型)提供了一种切实可行的病理AI实施路径。
如果你希望围绕相关项目、技术方向进一步沟通,欢迎扫码联系。

一、最值得关注的地方
在深入细节前,先抛出我觉得最值得深思的一点:PRET的范式创新点在于其“免训练”的极低部署成本,但这在CAMELYON16这类已有大量公开标注数据、强监督模型性能趋于饱和的任务上,并不能完全体现其颠覆性价值。它的真正用武之地,也许在于那些因病例稀少而无法进行传统监督学习的“长尾”临床问题。
因此,阅读本文时,应带着两个层次的问题:
1.方法学层面:PRET如何实现“免训练”且“高性能”的few-shot学习?它解决了哪些旧范式的痛点?
2.应用价值层面:论文的实验设计是否充分论证了其最不可替代的应用场景?如何客观看待它在不同任务中的性能表现?
二、研究背景与问题定义
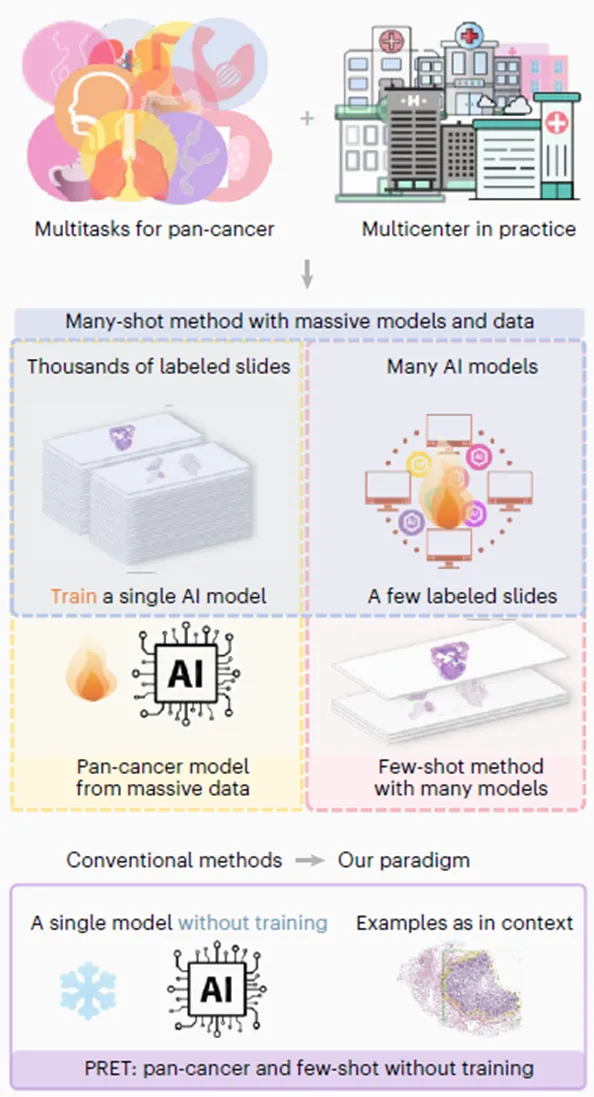
传统病理AI的开发遵循“一任务一模型”的范式。然而,像OncoTree数据库收录了近900种肿瘤类型,为每一种肿瘤都收集海量数据并训练特定任务模型,在实践中几乎是不可能的,尤其是在医疗资源匮乏的地区。
近年来,病理基础大模型的兴起为解决此问题带来曙光。但它们在各个下游任务中的应用,依然普遍依赖微调或多个弱监督模型训练,这需要可观的标注数据、计算资源和AI专家。而现有的免训练方法(如基于KNN聚类的方法),又往往将WSI聚合为单一的全局特征向量,丢失了关键的局部信息,导致性能不佳。
PRET正是针对这一痛点而设计:如何在完全无需训练的前提下,充分利用病理基础模型的表征能力和WSI的局部信息,仅凭极少示例就实现灵活、高性能的泛癌识别?
三、方法学拆解
在深入PRET的具体设计之前,有必要先了解一个关键概念:In-Context Learning(上下文学习,ICL)。
ICL最早在大语言模型(如GPT-3)中被发现并引起广泛关注。它的核心现象是:模型无需更新任何参数,仅凭在输入中给出的几个示例(即上下文),就能理解并完成一个新的任务。
ICL的本质,是将学习从训练阶段转移到了推理阶段,模型不是从海量数据中归纳规则,而是从当前给出的极少示例中临时领悟任务模式。
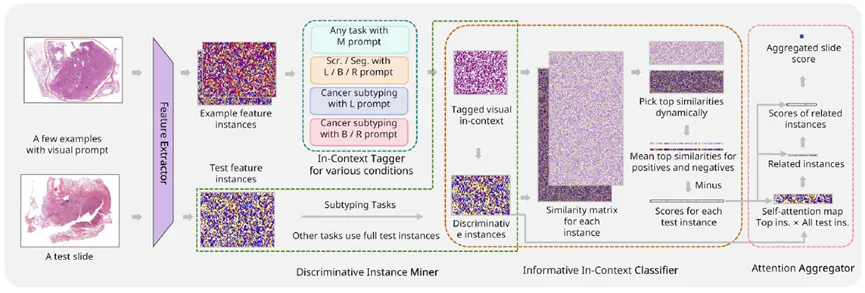
PRET的核心创新,正是将这一思想首次系统性地迁移到了计算病理学领域。它的完整工作流由六个模块构成:特征提取器、上下文标记器、判别性实例挖掘器、信息性上下文分类器、注意力聚合器、后处理器。针对不同任务(筛查、分型、分割),可灵活组合这些模块。
1
特征提取器:冻结的基石
PRET首先用一个完全冻结的病理基础模型(基于DINO自监督方法在TCGA上预训练的ViT-S/8模型)将所有WSI切分成256×256的patch,并提取为特征向量。论文也系统测试了与CHIEF、Virchow、UNI、Prov-GigaPath、TITAN等主流病理基础大模型的兼容性,结果显示,基础模型越强,PRET的性能水涨船高,证明它是一个“放大器”而非“替代者”。
2
上下文标记器:弱标注的智能翻译官
这是PRET区别于所有现有方法的第一道分水岭。它支持四种视觉提示:切片标签(L)、边界框(B)、粗略掩膜(R)、精细肿瘤掩膜(M)。这些提示的标注成本差异巨大:切片标签平均15.4秒,而精细掩膜需537.2秒。
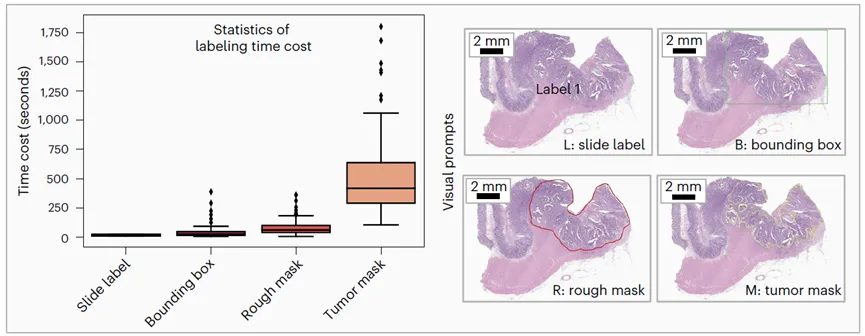
对于L、B、R这类弱提示,标记器的任务是将它们转化为实例级的正负样本标签。其核心算法通过计算patch与已知正/负样本的余弦相似度,并利用OTSU二值化动态划分正、负和不确定实例。
例如,当仅有切片标签时,标记器会先用已知良性切片的特征作为“负样本参照”,从癌症切片中筛选出与参照最不像的patch作为“正样本”,最像的作为“负样本”,中间地带作为“不确定样本”。
这意味着什么?病理医生只需花几十秒画一个框,PRET就能自动“脑补”出成千上万个精确的patch级标签,极大降低了高质量上下文信息的获取门槛。
3
信息性上下文分类器:拒绝“平均主义”
这是PRET性能碾压基线方法(如MI-SimpleShot、原型网络)的关键。所有传统few-shot方法都有一个共同缺陷:将示例的所有特征压缩成一个“原型向量”,丢失了局部细节。
PRET的做法截然不同:保留示例中所有patch的局部特征,不做任何池化或平均。
在推理时,对于测试WSI中的每一个patch,分类器计算它与所有示例正样本patch的余弦相似度,取top-k个最高值的均值;同时计算与所有示例负样本patch的top-k相似度均值;两者相减即为该测试patch的预测分数。
这种方法的核心优势有三:
动态匹配:每个测试patch都能从示例库中找到与自己最相似的“参照物”,而非被迫与一个平均化的“大众脸”比对。
信息保真:完整保留了示例中的局部形态异质性,对于识别微小病灶(如淋巴结中的单个肿瘤细胞巢)至关重要。
免于过拟合:没有可训练参数,天然避免了小样本下的过拟合风险。
4
判别性实例挖掘器与注意力聚合器
对于肿瘤亚型分类任务,仅靠标记器还不够,因为不同亚型的正常组织背景是相似的。此时需要“判别性实例挖掘器”介入,它利用已知负样本从测试WSI中筛选出最不像正常组织的区域(即肿瘤区域),仅对这些区域进行分类,避免了背景噪声干扰。
最后,一个无参数的“注意力聚合器”将所有patch级分数融合为切片级预测。它通过计算测试patch之间的自注意力权重,对高分patch进行加权求和,确保模型聚焦于最相关的区域。
总体而言,PRET的方法学创新不在于提出新的网络架构,而在于重构了few-shot学习的推理流程。它将推理过程从一个“全局特征比对”问题,转变为一个“局部特征检索与动态匹配”问题,并通过“上下文标记器”和“拒绝平均化”的实例级分类器,将极少示例中的信息榨取到了极致。
四、结果与验证表现
PRET在23个数据集、4484张WSI(约1.24亿个patch)上进行了系统验证。
1
全面超越基线方法
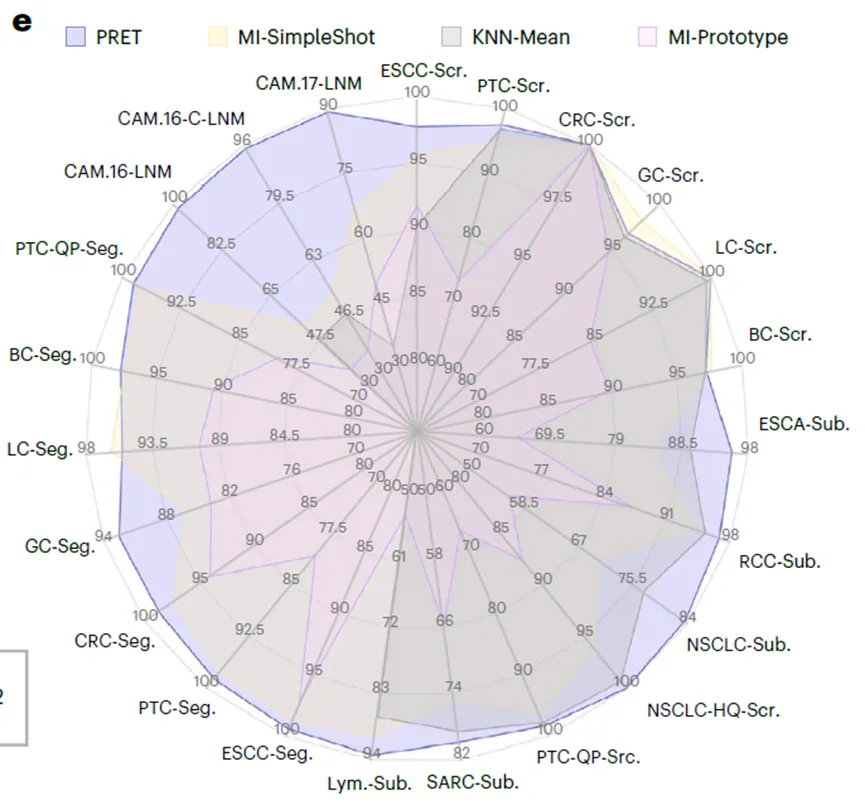
vs免训练方法:在20/23个任务上超越MI-SimpleShot、KNN-Mean等基线。例如在CAMELYON16上,AUC从62.40%提升至95.27%,绝对提升32.87%。
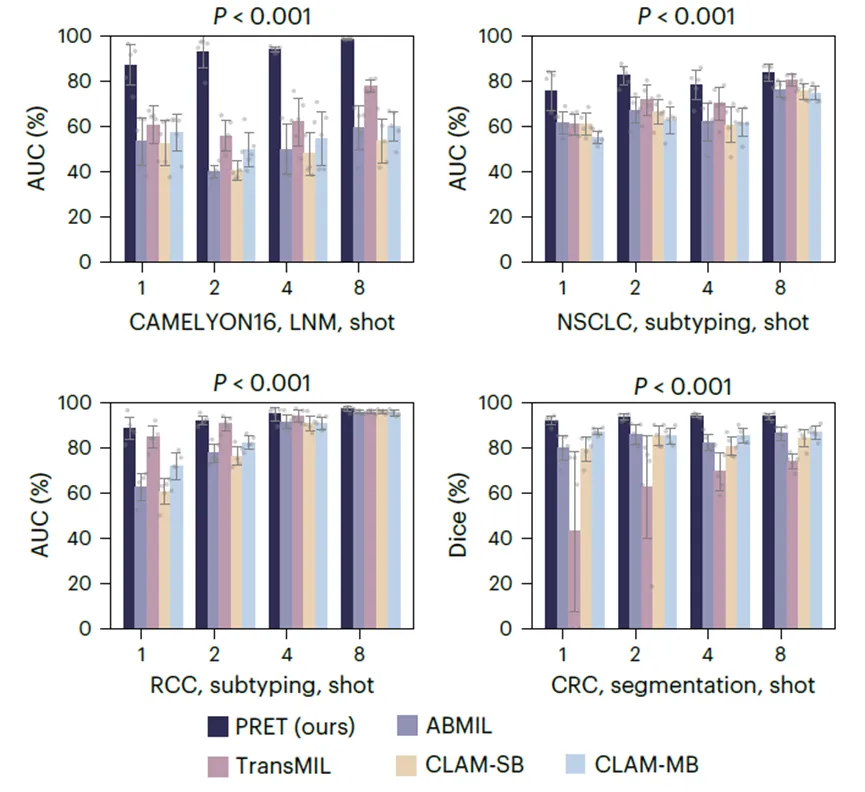
vs需微调的弱监督方法:在少样本设置下,PRET(82.58% AUC)远超TransMIL(71.64% AUC)等需要训练的方法。
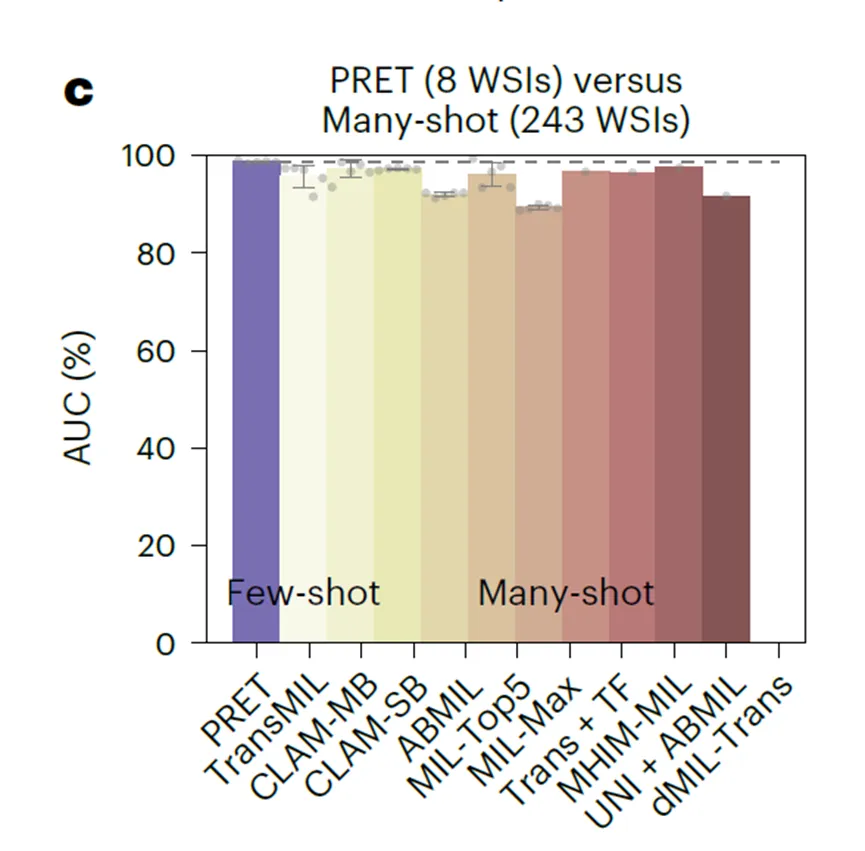
vs全量数据训练的方法:在CAMELYON16上,PRET仅用8张示例(AUC 98.71%),就超越了使用243张WSI训练的TransMIL、CLAM等方法。
2
各类提示方式性能对比
提示方式与肿瘤大小的关系:对于肿瘤较小的癌症(如PTC、ESCC),精细掩膜(M)效果最佳;对于肿瘤较大且易定位的癌症(如CRC、NSCLC),切片标签(L)已足够好。
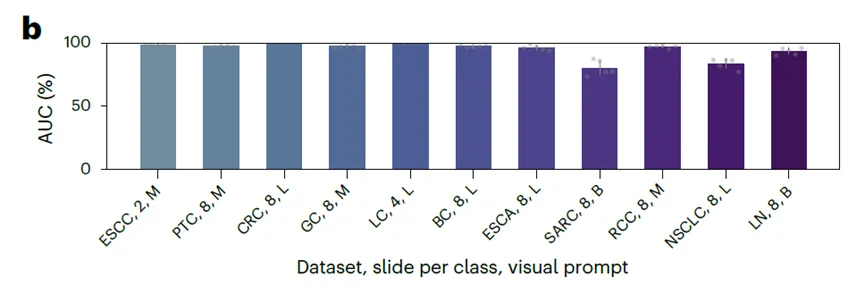
弱提示可以逼近强提示:在分割任务中,使用B或R弱提示的PRET性能与使用M强提示的差距通常<5%,而基线方法的差距可达10%-20%。

具体案例:在PTC筛查任务中,1-shot下PRET使用切片标签的AUC已达93.3%,而对比的方法仅63.6%。
3
泛化能力:免训练的结构性优势
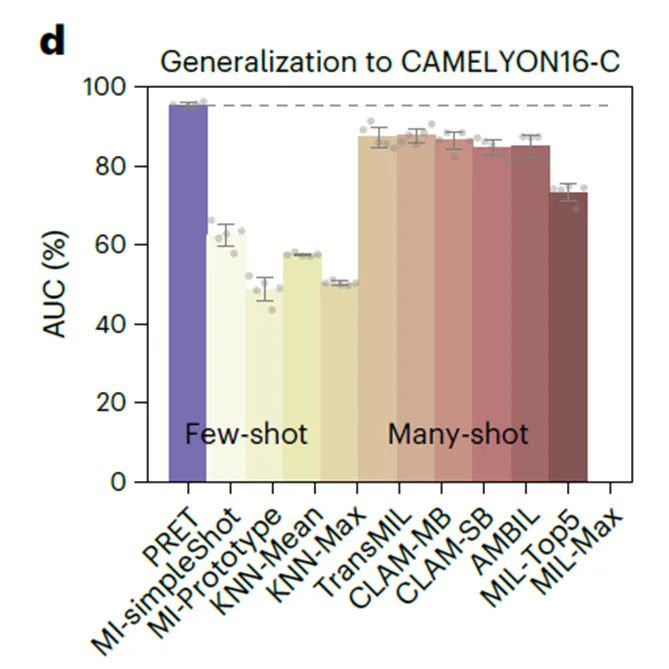
PRET在跨中心、跨扫描仪、跨种族测试中展现出卓越的鲁棒性。
扫描伪影:在CAMELYON16-C(模拟染色不均、失焦等伪影)上,PRET的AUC仅下降3.44%,而最佳基线下降7.55%。
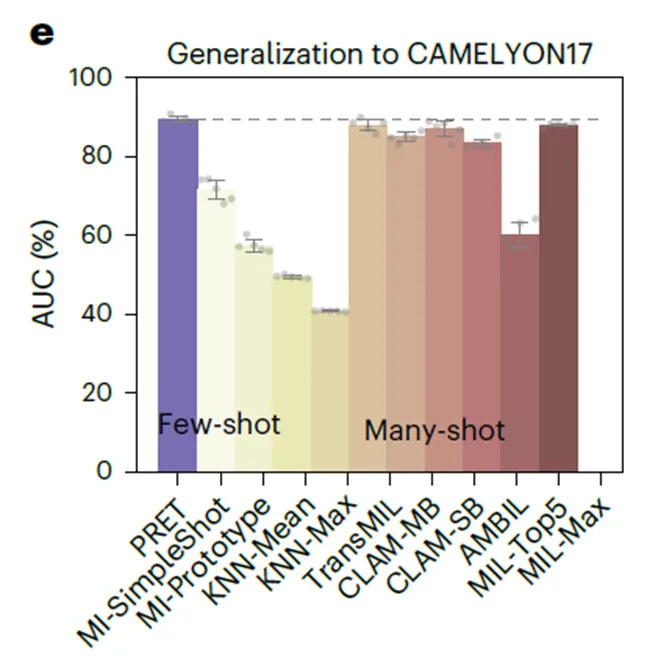
跨中心验证:用CAMELYON16的示例直接测试CAMELYON17(五个外部中心),PRET的AUC保持在94%以上。
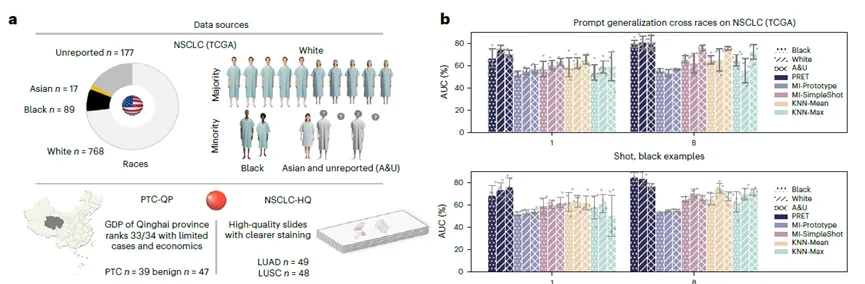
跨种族公平性:在TCGA-NSCLC数据上,用白人样本作示例测试黑人/亚裔群体,PRET的AUC差异仅1.32%,远低于其他方法。
4
消融实验:每个模块都不可或缺
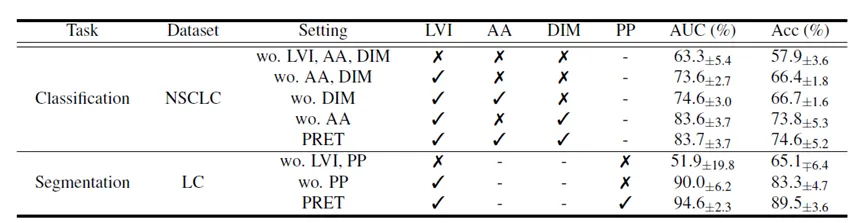
消融实验清晰地表明:关闭上下文标记器(LVI),直接使用全部patch:AUC从92.2%降至73.8%(淋巴瘤8-shot)。关闭注意力聚合器(AA),改用最大池化:AUC从92.2%降至82.6%。对于分型任务,关闭判别性实例挖掘器(DIM):AUC从78.6%降至64.1%。
五、讨论与总结:PRET的方法学意义、现实考量与未尽之路
1
PRET推动的是“更晚压缩信息”的建模思路
如果要用一句话概括PRET的方法学贡献,我觉得是:这篇文章真正推进的,不是病理基础模型本身,而是基础模型之上任务适配的方式。 过去许多工作虽已使用病理基础模型,但下游范式并无本质变化——依然是全局池化、MIL聚合、线性探测或参数微调。PRET证明,在完全冻结表征的前提下,存在另一条路线:尽量保留局部信息,尽量延后压缩,把分类决策推迟到支持集与测试集发生动态交互之后。
这一思路对病理图像尤为重要。WSI并非一个“全局均值表征”能完整描述的模态——一个直径仅200微米的转移灶,在全局池化后可能被完全淹没。PRET通过保留patch级特征、使用基于top-k相似度的实例级分类器,确保了小病灶的局部信号不被“平均掉”。这正是其在CAMELYON16上超越病理学家、在微小肿瘤数据集上表现优异的原因。
2
它的最大价值,可能不在性能极限,而在监督设计和资源组织
PRET最值得重视的,是它给出了一种更现实的资源配置思路:Backbone不必每个任务重训,标注不必每个任务都做到最细,新任务不必重新走完整训练流水线,少量示例即可形成可用的推理上下文。
PRET更像是在重新定义一个问题:什么样的监督足够让一个病理基础模型开始工作? 它的回答是:极少的、粗粒度的、低成本的监督,配合精巧的上下文利用机制,就足以解锁强大的临床能力。
3
真正适合PRET的任务
这是理解PRET应用边界的关键。论文将CAMELYON16作为临床级性能的标杆,用8-shot超越了11位病理学家,这无疑证明了PRET在数据效率上的惊人能力。
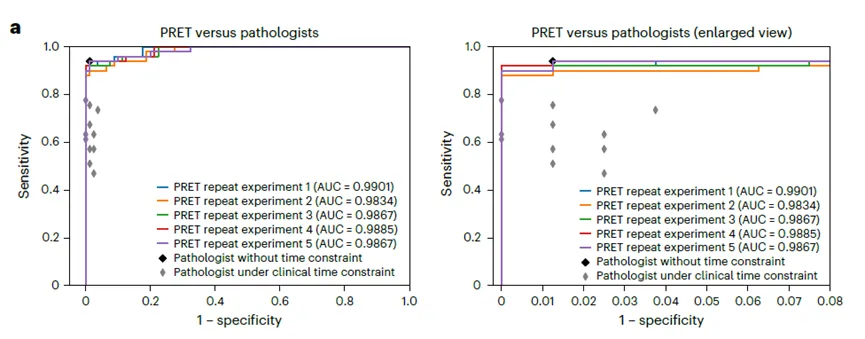
但需要清醒认识到,CAMELYON16本身是一个有像素级详尽标注的公开数据集,全监督模型性能已非常成熟。 PRET在此的胜利,更多是证明了方法的可行性,而非找到了其最不可替代的应用场景。
从应用逻辑看,PRET最值得期待的未来场景,或许是另一类问题:数据很少,很难标注。 例如,某些肿瘤存在大量稀有亚型、罕见形态变体、特殊免疫表型;某些中心会不断遇到低频但临床重要的新问题;某些科研任务只需快速验证一个小样本假设,根本不值得为它单独训练一个完整模型。对这些长尾问题,PRET的价值不仅是省训练,更是让病理AI第一次拥有了低门槛进入的能力。
因此,CAMELYON这类任务适合证明PRET有实力,但长尾任务才更可能证明PRET有必要。
4
它还没有彻底回答“开放类别病理识别”这件事
PRET离真正意义上的开放类别识别——例如“这张切片里有什么异常形态?”——还有明显距离。此外,PRET并非“零监督”,它只是将监督从精细标签转成了少量示例和视觉提示。对于真正罕见且边界模糊的病理类别,示例如何选、提示如何给、支持集是否代表目标类别,都会成为新的瓶颈。
5
现实考量:推理速度与示例选择策略
推理速度是PRET走向实用必须面对的问题。论文报告的7.41秒/张WSI(CAMELYON16,8-shot)有一个重要前提:所有示例和测试WSI的patch特征均已预先提取。 在实际即时预测中,测试WSI需先完成特征提取(通常数分钟),之后才是约7秒的推理计算——总耗时在临床场景中仍可接受,但并非“秒级响应”。
更关键的是示例选择策略:若每次更换示例都需重新提取其特征,PRET“即插即用”的灵活性将大打折扣。这意味着在实际部署中,需要一个预提取好特征的示例特征库作为基础设施,才能真正实现低延迟的任务切换。论文未展开讨论这一点,但这是从方法学原型走向实用系统的关键一步。
6
总 结
PRET最重要的贡献,在于提出了一套在不再训练的前提下,如何把冻结病理表征转化为多任务识别系统的方法框架。它将弱提示处理、局部上下文保留、判别实例筛选和非参数推理组织成一个完整闭环。
对那些数据充足、标签成熟、任务定义稳定的问题,全监督训练模型仍然会长期存在,甚至在很多场景下依然是更优解。可对那些长尾、稀有、中心特异、不断变化的问题,PRET代表的路线可能更值得重视。
AI病理视界团队在病理AI竞赛、研究发表与项目案例方面有丰富积累,覆盖病理AI模型开发、数据分析、研究方案设计与技术支持等多个环节。
如果你来自病理科、科研团队、药企/CRO或相关企业,正在推进病理AI任务设计、模型研发或转化项目,欢迎进一步交流。
如果你具备病理AI、基础模型或工具链相关背景,也欢迎围绕兼职、实习或技术合作与我们联系。

· 往期推荐
AI病理文摘|封闭任务的“技术守恒”:从Lancet Digital Health最新PanCAM模型看淋巴结转移检测的十年演进
