 夜雨聆风
夜雨聆风

上一期,智在碧得向大家展示了碧桂园服务是如何通过工程记忆三层架构破解AI编程长周期断层难题,实现AI编程效率翻倍的。本期,碧桂园服务数能中心新业务团队进一步聚焦Claude Code落地实操,深挖其长效记忆底层机制。
在实际高频的开发场景中,Claude似乎经常 “失忆”,“我的对话怎么找不到了?”,“我的历史对话是否可以恢复?”——这是不少团队成员的共同困惑。同时,在多任务并行、同一项目并发开发时,还频繁出现上下文污染、记忆冲突等问题。面对 “失忆” 断层与并发冲突双重痛点,若每次重开会话、或多开实例,都会面临重复提供背景信息的Token浪费、开发逻辑错乱、代码风险上升等问题。
为系统性解决这一系列问题,团队深度剖析Claude Code背后的运行逻辑,全面梳理Claude的会话存储与项目绑定关系、记忆管理与并发隔离底层机制,通过吃透核心机制提升团队对复杂长任务、多任务并行开发的处理灵活性,并确立标准化AI并发开发规范。
核心成果:梳理总结Claude的 “会话存储与项目绑定”核心机制,解决了团队复杂长任务历史对话丢失重开、同一项目多实例并发冲突导致的Token浪费、时间损耗与代码异常问题,提高了对复杂长任务处理的灵活性与并发开发安全性。
在处理复杂任务时,对比之前重新开启新会话提供背景信息,至少提升研发效率40%,Token有效利用率提升65%;同时推广Git Worktree + Claude Code的协同工作流,确立AI并发开发规范。
*以下内容来自碧桂园服务新业务研发团队

在AI编程工具日益普及的今天,Claude Code极大地提升了开发效率,但也暴露了会话管理上的短板。团队在实际开发中,高频遭遇以下两类痛点:
|1.1 长周期任务的记忆断层
复杂任务被耽搁几天后,历史对话往往难以找回,只能被迫重开新会话。而每次重开都需要重复提供项目背景信息,不仅造成Token浪费,也耗费大量开发时间。
传统模式下,每次开启新会话,AI都需要重新理解整个项目。工作流程是:开发者打开新会话→粘贴相关代码→AI花费大量Token理解结构→完成一小部分任务→Token耗尽→下次会话重复以上步骤。
损失量化:每次新会话重新理解项目消耗5-15分钟+ 2000-8000 tokens。假设一个项目需要100次会话迭代,仅“重新理解”就浪费8-25小时+20万-80万tokens。
这种“失忆”现象不仅打断了开发思路,还迫使开发者必须重新、重复提供项目背景信息,造成了极大的Token浪费与时间损耗。
|1.2 同一项目多实例并发引发会话冲突与开发异常
在快速响应需求迭代与Bug紧急修复时,部分工程师为提升效率,尝试在同一项目目录下开启多个Claude Code实例,试图同时处理新功能开发、线上Bug修复等并行任务,结果出现开发上下文污染、Checkpoint冲突、Auto Memory数据丢失等问题,特别是造成冲突之后,需要花费更多的Token与时间去解决,进一步加剧了复杂任务的开发风险与时间成本。

这个痛点促使团队跳出简单的“问答工具”思维,深入探究Claude Code背后的运行逻辑。团队从实际的痛点切入,深度剖析Claude会话存储与项目绑定机制。
举个简单例子:如与Claude发起简单对话,同时,双击CTRL+C即可退出对话。
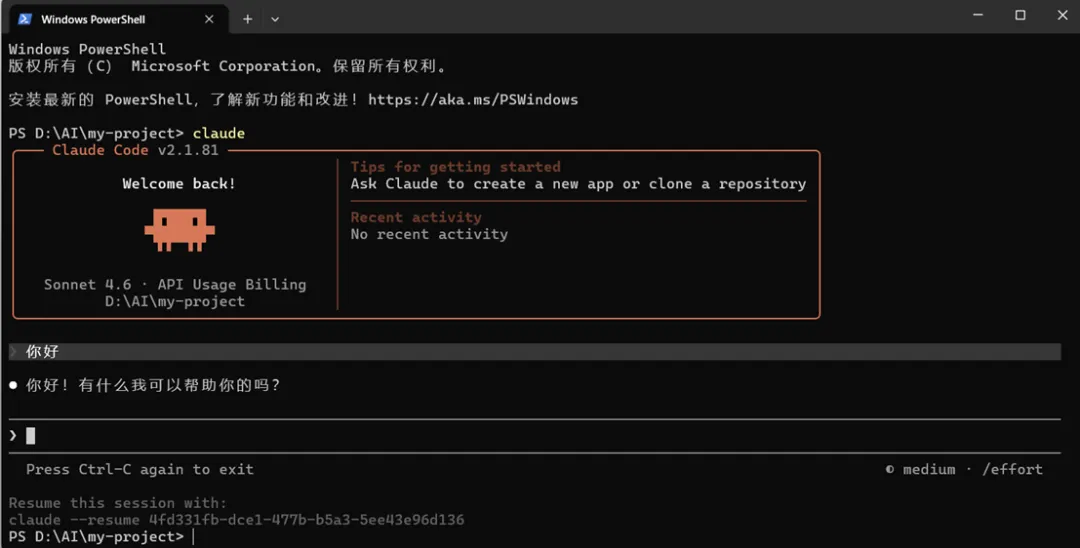
退出对话时能看到当前对话ID。而下次再次进入会话的话,需要在同一文件夹内输入resume命令:
claude--resume 4fd331fb-dce1-477b-b5a3-5ee43e96d136
或者直接输入claude -c就能直接恢复上一次停止的会话。
上面的-c和--resume操作看似简单,背后却隐藏着Claude Code最核心的设计哲学之一:会话与项目目录的绑定关系。理解这一机制,既能解决文章开头的困惑(“我的对话怎么找不到了?我的历史对话是否可以恢复?”),更能帮助建立正确的Claude Code工作心智模型。
|2.1 操作层面:为什么必须在同一文件夹内恢复对话?
尝试一个实验:在~/project-A目录下与Claude Code进行了一次深入的代码重构对话,然后退出。接着cd~/project-B,再执行claude-c—你会发现,刚才的对话完全消失了,-c恢复的是project-B目录下的上一次会话(如果有的话),而不是你刚才在project-A中的那次。
这不是Bug,而是刻意为之。Claude Code本质上是一个项目级的开发助手,而非全局聊天工具。它的每一次对话都深度嵌入当前项目的上下文,读取了哪些文件、修改了哪些代码、创建了哪些Checkpoint、遵循了哪些CLAUDE.md规范。如果允许在project-B中恢复project-A的会话,Claude可能会按照A项目的规范去修改B项目的代码,后果不堪设想。
核心认知:Claude Code不是“通用对话工具碰巧能写代码”,而是“项目级Agent碰巧通过对话交互”。每个项目目录就是一个独立的工作空间,会话、记忆、配置三者在目录维度上完全隔离。
|2.2 底层机制:会话如何存储在本地?
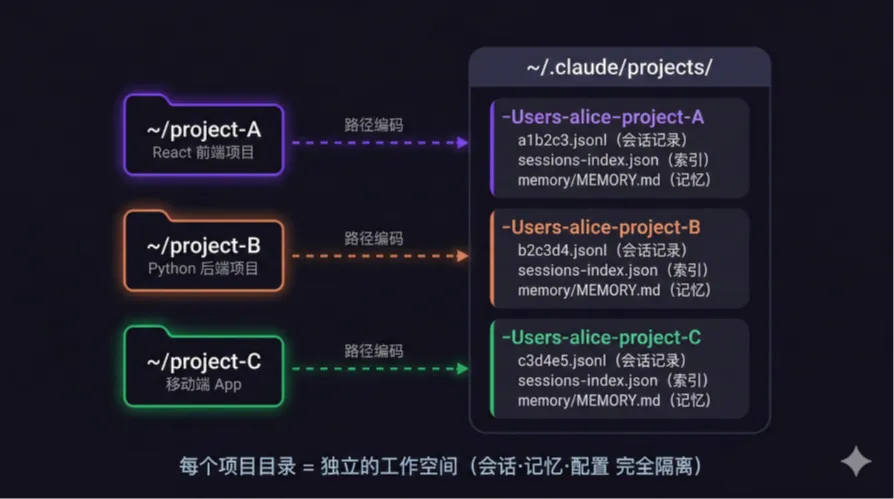
打开~/.claude/projects/目录,可以看到Claude Code会话存储的全貌。每个项目目录的绝对路径会被编码为一个文件夹名,路径分隔符替换为连字符:

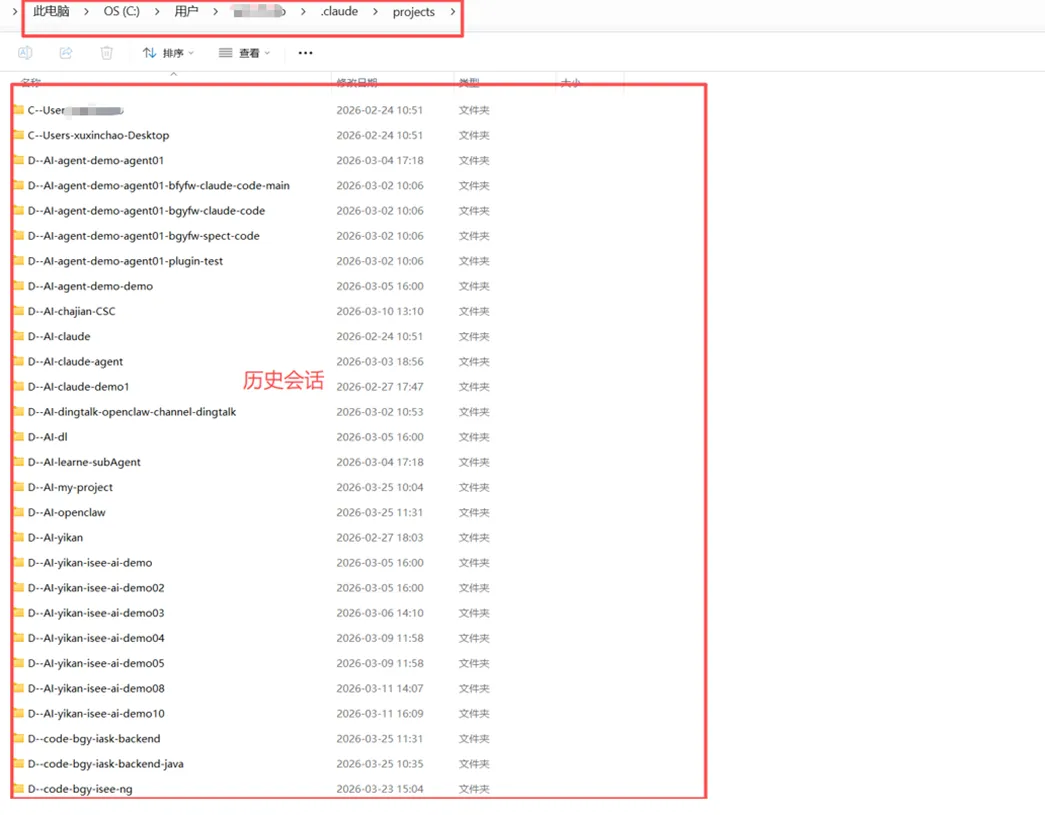
每个编码后的项目文件夹内部结构如下:

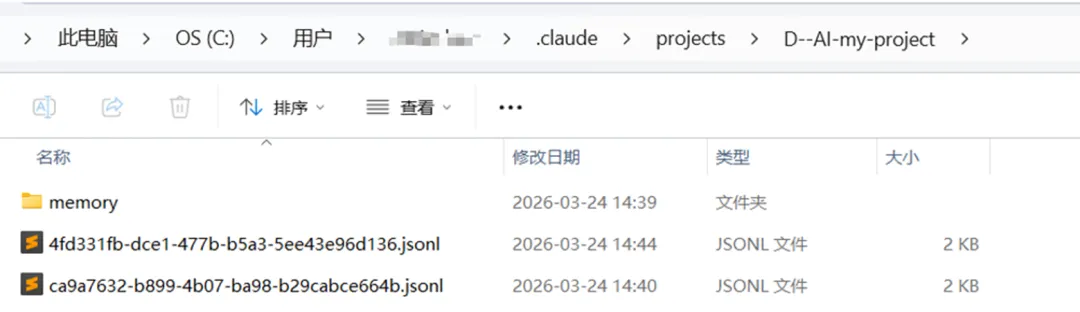
其中,.jsonl文件是会话的完整记录,每一行是一个JSON对象,记录了每一轮对话的消息内容、时间戳、Token用量、工具调用结果、当前Git分支等信息。Claude Code采用追加写入(append-only)模式,每产生一条消息就立即写入磁盘,即使进程崩溃也不会丢失已完成的对话内容。
以获取Token用量为例,打开一个JSONL文件,每一行是一条消息记录。找到type=“assistant”的行,里面有关键的usage字段,详细记录了某次对话的Token用量:
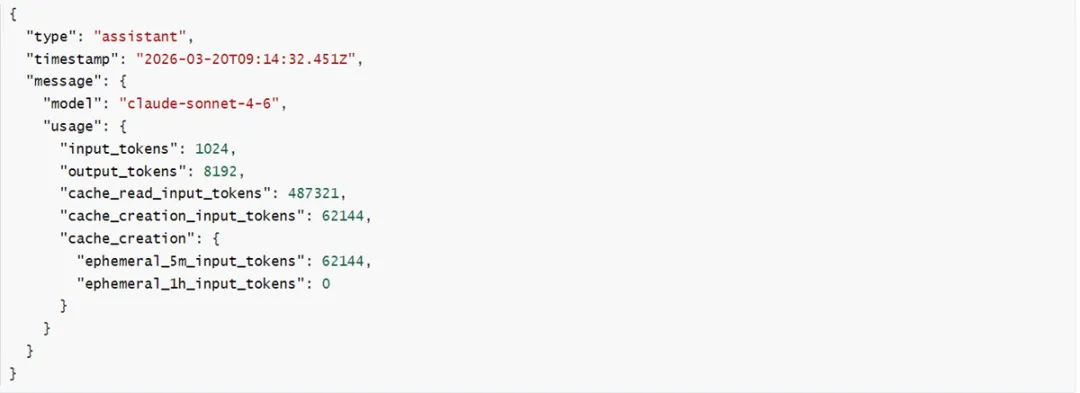
sessions-index.json则是一个轻量级索引文件,记录每个会话的元数据(首条提示词、摘要、消息数量、创建/修改时间、Git分支等),供claude --resume的交互式选择器快速检索,无需逐一解析完整的JSONL文件。
注意,最新版sessions-index.json内容已经合并到历史对话记录json字段中。
理解了这套存储结构,几个常见问题就迎刃而解了:

理解上述机制后,便也知晓了怎么恢复Claude历史会话,比如用opencalw --resume 2f154559-a46b-44e5-a673-a2385a8ca5f7,恢复了一个一周前的对话历史,可以继续基于此话历史继续进行交互开发,从而避免了重开会话,重复提供项目背景信息,造成的Token浪费与时间损耗。
|2.3 延伸:Claude Code 能否“多开”?
理解了“会话绑定项目目录”的机制后,一个自然的问题浮现:能不能同时开多个Claude Code实例,并行处理不同任务?
答案需要分两种情况讨论:
不同项目目录,完全可以多开。可以在一个终端窗口中用Claude Code开发前端项目~/frontend,同时在另一个窗口中开发后端项目~/backend。两个实例的会话、记忆、Checkpoint各自独立,互不干扰。这正是“项目级隔离”设计的优势,每个项目目录映射到 ~/.claude/projects/下不同的文件夹,数据天然隔离。
同一项目目录,强烈不建议多开。虽然技术上Claude Code不会阻止你在同一个目录下启动第二个实例,但这样做会引发一系列问题:

Claude Code之所以没有实现目录级的进程锁,是因为它信任开发者的使用习惯,就像你不会同时用两个编辑器打开同一个文件并同时保存一样。如果确实需要在同一个代码仓库中并行开发两个独立功能,正确的做法是使用Git Worktree:

每个Worktree是一个独立的目录路径,因此在~/.claude/projects/下会自动产生独立的会话空间,既保留了Git历史的统一性,又实现了Claude Code层面的完全隔离。

|3.1 成果总结
通过吃透并全员普及Claude的“会话存储与项目绑定机制”,在处理复杂长任务时,碧服数能中心新业务团队实现了显著的效能提升,消除了上下文丢失的痛点,并确立AI并发开发规范:
消除上下文丢失损耗:依托会话恢复能力,无需反复重开新会话、重复提供项目背景,大幅减少Token消耗与时间浪费,复杂任务研发效率提升40%,Token有效利用率提升65%。
规范AI并发开发流程:推广Git Worktree + Claude Code协同工作流,实现同一仓库多任务并行开发的完全隔离,从根源避免会话串台、上下文污染、Checkpoint冲突、记忆丢失等问题。
建立正确使用心智:将Claude Code 从“临时问答工具” 转变为项目级驻场开发助手,让团队具备长任务续接、多任务安全并行的标准化操作能力,支撑复杂业务系统高效迭代。
|3.2 未来方向
从这次团队技术深挖中得出一个重要经验:应当把 Claude Code当作一个有独立记忆的“驻场开发工程师”,而不是一个随用随丢的聊天框。 在未来,理解Claude的项目隔离与绑定机制,可在中心内部的不同业务线分别沉淀高度定制化的CLAUDE.md与能力矩阵(Skills)。通过在不同项目目录中预置专属的“项目级Agent”,将进一步推动中心从“人力编码”向“人机结对代理开发”的智能化研发转型。
本文作者
徐新超 碧桂园服务JAVA开发工程师
指导人
毛卓 碧桂园服务技术总监
王志坚 碧桂园服务JAVA开发专家





