 夜雨聆风
夜雨聆风
关键洞察
公众对AI能力的认知存在偏差,核心原因在于AI技术存在代际层级差异。“基础对话模型”与具备自主决策能力的“前沿智能体”,在任务处理逻辑上有着本质不同。
AI能力演进在各领域呈现非对称性,其迭代速度主要由“任务可验证性”决定。在逻辑推导明确、具备“自动反馈闭环”的领域,模型可通过“强化学习”持续提升性能。
衡量AI模型性能的关键指标,已从“单次指令响应效果”转变为“长周期任务的自主执行时长”。数据显示,前沿模型独立处理复杂任务的时长呈固定增长周期,正从“瞬时交互”向“多阶段自主执行”过渡。
AI对职业结构的影响具有选择性,其应用主要集中于“数字资产处理”与“逻辑分析类岗位”;而在依赖物理操作、法律合规或高敏感度决策的领域,AI渗透率则相对较低。
软件工程及相关数字化生产领域的开发模式正在重构,生产流程已从人工编写具体指令,转向对“多智能体系统”的“任务拆解”“协同定义”及“全生命周期编排”。
[正文内容]
AI的“感知鸿沟”:两种平行的技术现实

2026年4月9日,Andrej Karpathy(@karpathy)在X平台发布帖文,直指当前社会对AI能力的认知正出现日益扩大的“感知鸿沟”(Perception Gap)。他观察到,大量用户仍基于旧版模型或免费版ChatGPT的残存体验对AI持保留态度,常以幻觉问题为由否定其价值——例如OpenAI Advanced Voice模式在处理“开车还是步行去洗车店”这类基础查询时的失误。然而,这些过时模型显然无法代表今年OpenAI Codex与Claude Code等前沿智能体模型的真实量级。
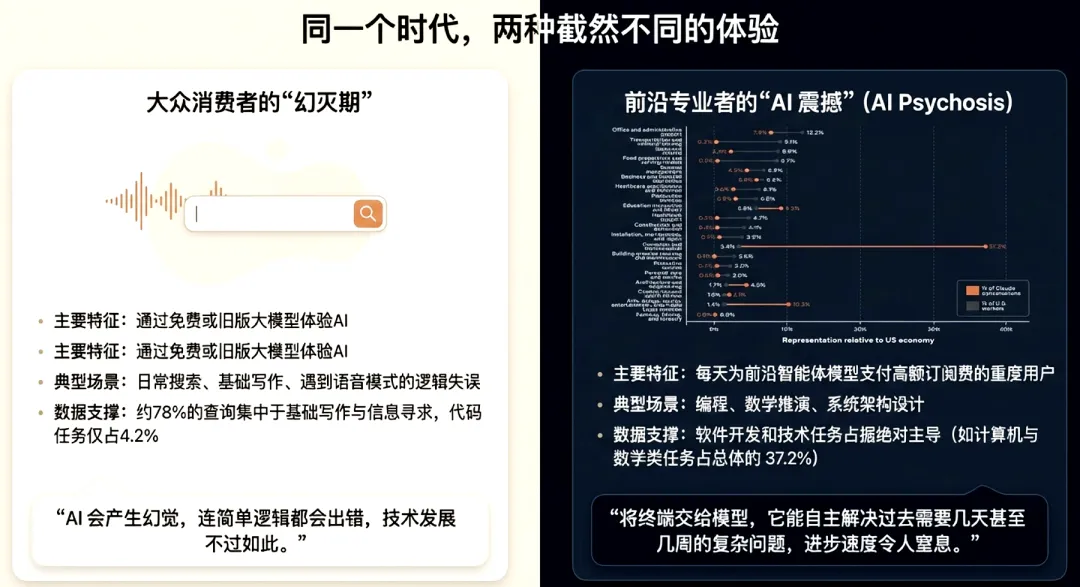
Karpathy指出,另一群支付高额费用、深度使用前沿智能体模型进行编程、数学及前沿研究的专业用户,正经历着“效率爆炸”与“AI Psychosis”(AI精神错觉)。在获得计算机终端访问权限后,模型得以在1小时内自主重构完整代码库,或精准识别并利用系统漏洞。这种感知分化不仅源于模型版本的代差,更在于AI能力的提升在技术密集型领域呈现显著的“尖峰化”(Peaky)特征:传统的搜索、协作与建议类查询并非进步最快的主战场,真正的突破发生在具备强化学习可验证奖励函数(如单元测试)的领域及B2B高价值商业场景。
相关讨论进一步深化了这一观点:Jiayuan (JY) Zhang(@jiayuan_jy)强调,在专业群体内部,效能瓶颈已从模型智力转向“上下文供给与判断框架”;0xSero分享了Codex/Claude操控3D打印机及构建Home RAG的实战案例,指出AI已能覆盖日常任务的50%以上;M则引用OpenAI与Harvard NBER数据提醒,编码类查询仅占ChatGPT消息总量的约4%,非工作查询占比超过73%。这些信息勾勒出不同群体在认知维度上“擦肩而过”的现实。
这一“感知鸿沟”并非主观偏见,而是AI从“通用对话工具”向“自主决策实体”转型的真实信号。通过构建高质量上下文,专业用户已见证AI在数分钟内交付人类半数日常工作成果的巨大潜力。
1.被低估的“感知鸿沟”:幻觉与爆炸的分野
当前社会对人工智能能力的认知正处于严重的极化状态。这种鸿沟首先根源于使用层级与模型版本的代差:大量普通用户仍滞留于旧版模型,其处理基础逻辑查询时的频发失误与幻觉,使公众对AI的认知仍固化在“不成熟的对话助手”阶段。
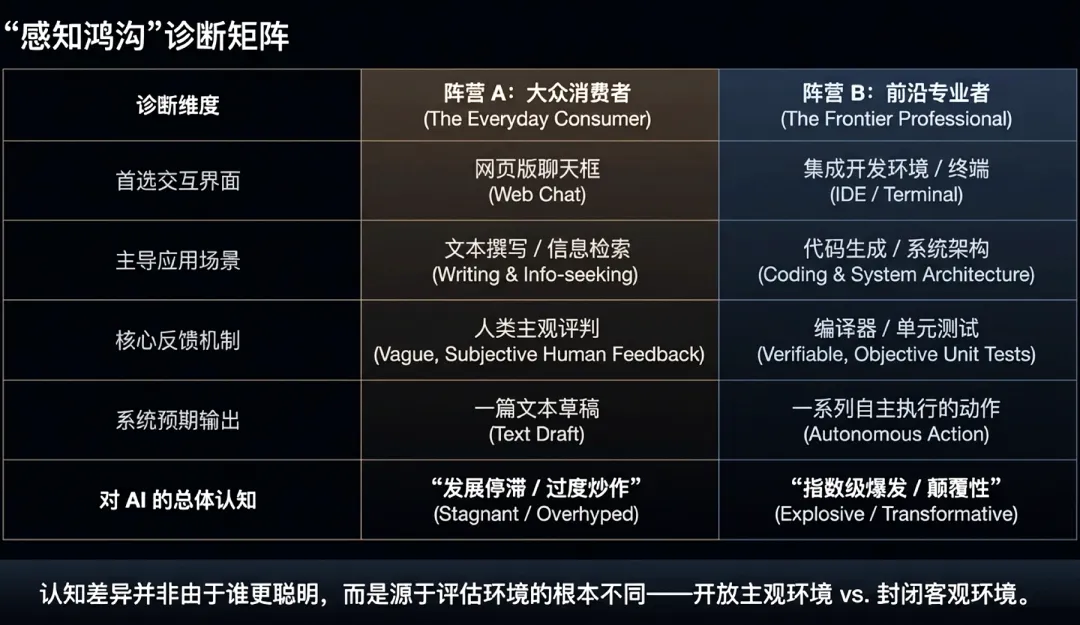
与之形成鲜明对比的是,重度渗透前沿智能体(如OpenAI Codex或Claude Code)的专业群体正见证一场“效率爆炸”。在编程、数学及深度科研领域,AI的表现已跨越文本生成范畴。实测显示,当代前沿模型在拥有系统终端权限时,能在一小时内自主完成代码库重构或漏洞挖掘。这种能力的指数级跨越,使得专业用户感知到的技术演进斜率远比大众视野中的更为陡峭。
这种认知分歧标志着技术瓶颈的结构性转移。资深从业者认为,AI竞争的核心已从单纯的“智能能级”转向“上下文供给与判断框架”。在同等模型基准下,产出质量的巨大差异核心不在于模型本身,而在于输入端背景信息的深度,以及引导智能体执行任务时的逻辑严密性。
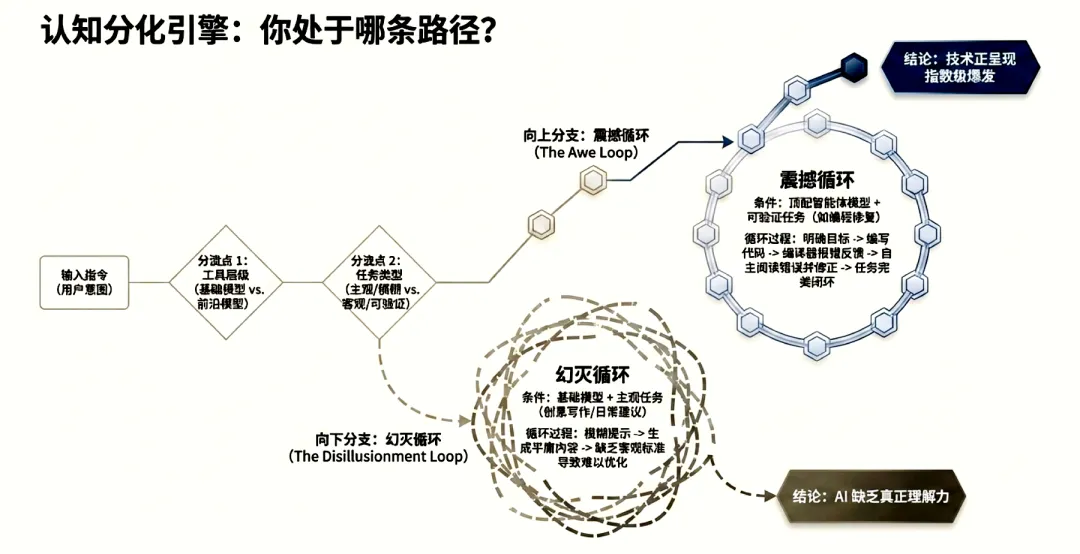
这种分化预示着AI正加速从“通用对话工具”向“自主决策实体”演进。对于能够提供高质量判断框架的专业用户,AI已具备处理人类日常工作中50%以上任务的能力。感知鸿沟的本质,是技术应用深度与任务可验证性共同作用的结果:在具备明确奖励函数(如单元测试)的技术领域,AI正通过强化学习实现能力的指数级跃升;而在缺乏客观评价标准的软性任务中,这种进步感则相对微弱。
2.技术演进的指数法则:每7个月能力翻倍
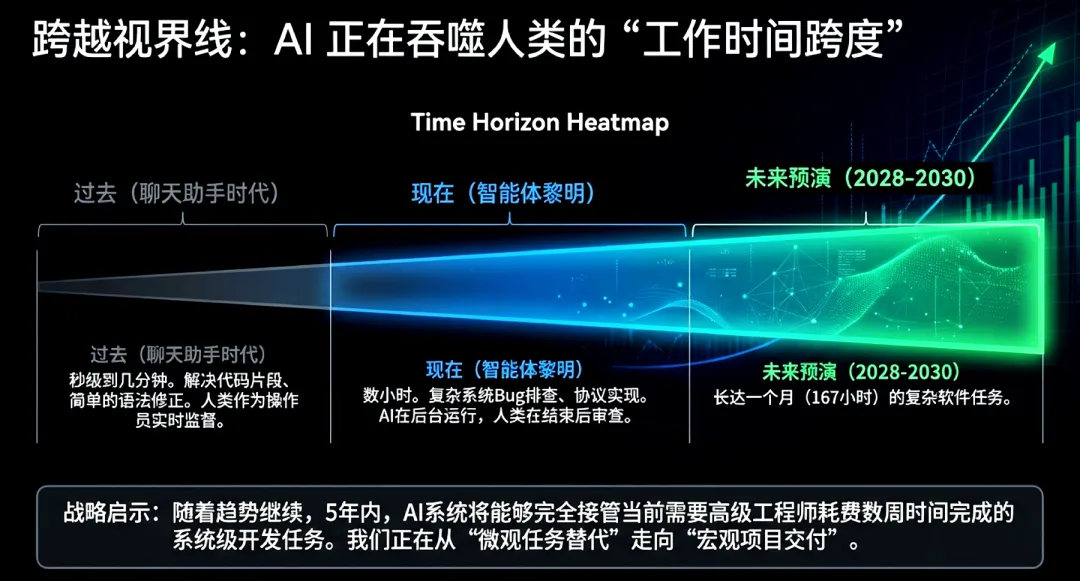
AI能力的演进遵循着严密的量化规律,其核心标志在于处理复杂任务的时间跨度。模型评估与威胁研究中心(METR)提出的“50%任务完成时间跨度(Time Horizon)”指标显示:自2019年以来,前沿模型处理同等难度任务并达到50%成功率的能力指标,大约每7个月翻倍(参考METR 2026年3月3日更新数据)。
这一趋势在模型迭代中表现得尤为惊人。早期GPT-2的时间跨度仅为2秒,而2025年发布的o3模型已提升至110分钟。这意味着当前的AI系统已能自主处理原本需人类专家投入近两小时的复杂多步工程任务。根据现有斜率推演,AI系统有望在2028至2031年间达到处理人类单月工作量(约167工时)的技术水平。
为精准定义这种从“助手”向“自主实体”的跃迁,OECD在2026年2月的报告中明晰了概念边界。“AI智能体(AI Agents)”被定义为具备环境感知与交互能力、拥有自主性且能调用工具达成特定目标的系统。而“智能体AI系统(Agentic AI)”则代表更高阶的系统范式,强调多智能体间的协同、任务拆解与职能委派。
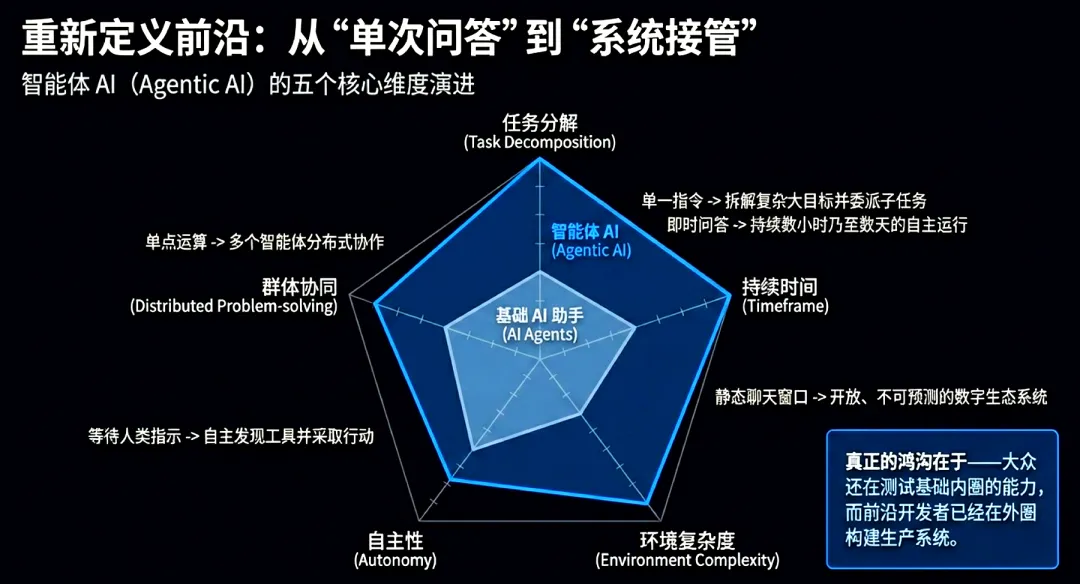
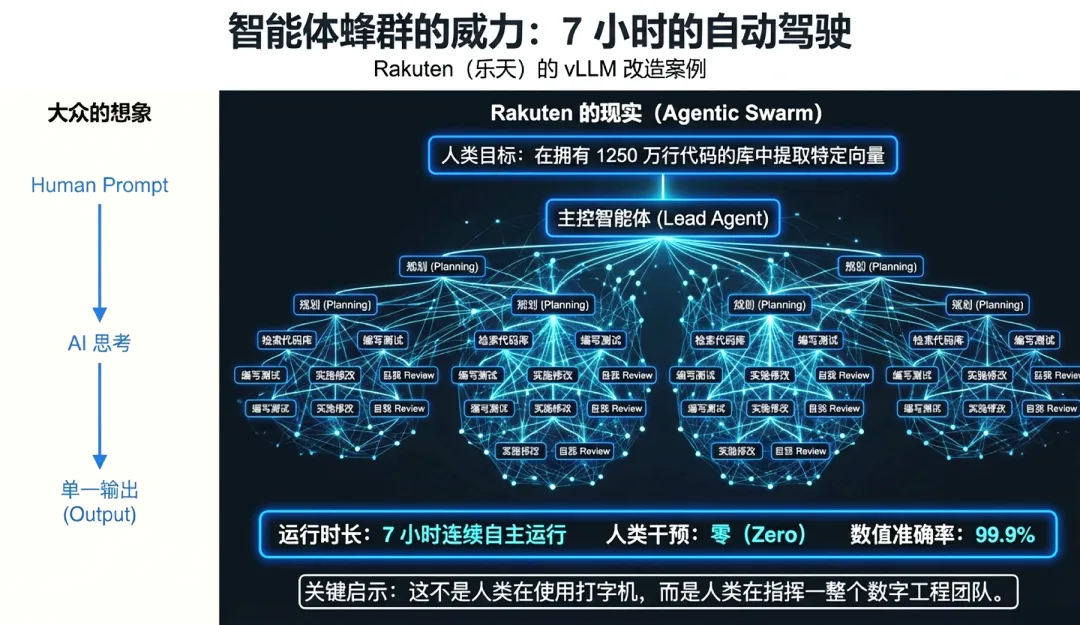
Agentic AI的本质差异在于其系统化的目标处理能力。不同于单点决策,该系统能将复杂目标自动解析为可管理的子任务并分发协作。此类系统具备在开放式物理或虚拟环境中持续运作的能力,能在长周期任务中实现极低的人工干预。这种范式迁移标志着AI正从执行单一指令的工具,演进为能够自主编排、自我反馈并集成底层Fabric架构能力的系统化实体。
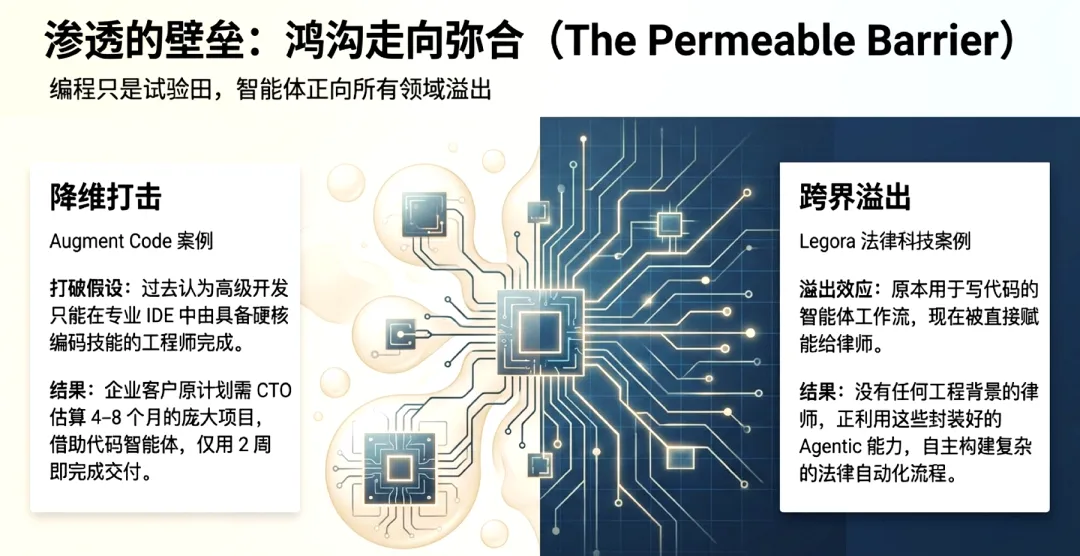
3.经济图谱的分化:谁在真正驱动AI价值?
大众对AI的认知常被社交舆论或情感互动所左右,但真实的经济活动数据揭示了截然不同的应用格局。Anthropic在2025年3月的实证研究显示,基于400万条Claude.ai对话数据,AI应用高度向专业技术领域集聚。“计算机与数学”相关任务占据了总量的37.2%。
相比之下,舆论热衷讨论的社交与情感应用在实际流量中占比极低:涉及人际关系与个人反思的对话仅占1.9%。这一趋势有力证明,AI的核心经济价值并非情感代偿,而是作为处理结构化逻辑与数字资产的高阶生产力工具。
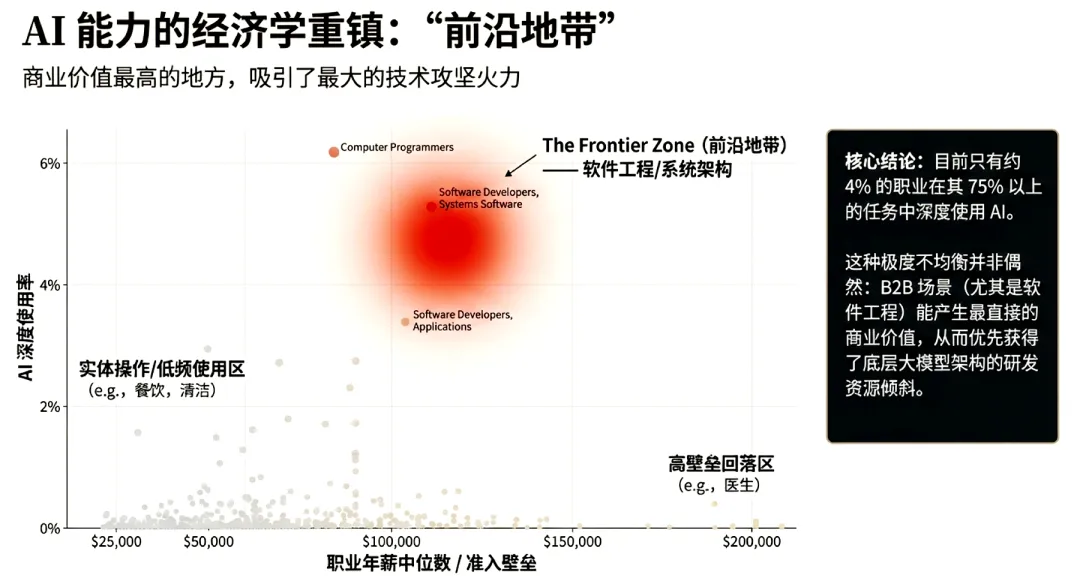
AI在职业结构中的渗透呈现显著的非线性特征。通过U.S. ONET数据库分析发现,AI使用率在Job Zone 4(需要高度专业准备)的职业中达到峰值,代表性比率高达1.50。这意味着此类岗位对AI的渗透程度比劳动力市场基准高出50%。
然而,在薪资光谱的两端,AI渗透率显著下降:高薪端的麻醉师、产科医生等岗位(Job Zone 5),因高度依赖物理操作、法律合规或敏感信息限制,AI使用率较低;低薪端的体力劳动岗位,AI渗透率同样处于极低水平。这种分布态势也解释了为什么不同职业背景的人对AI进化的感知存在巨大温差。
4.深层分化逻辑:可验证奖励函数与商业激励
AI在不同领域的演进速度并不对等,这种失衡受底层技术逻辑与商业资源分配的双重驱动。
强化学习中的可验证奖励函数
编程与数学之所以成为演进先导,核心在于其任务具备“可验证奖励函数”。代码执行结果可通过单元测试或逻辑推导进行即时、明确的验证。这种闭合反馈机制极大提升了强化学习的训练效率,使模型能通过大规模试错自主优化路径。
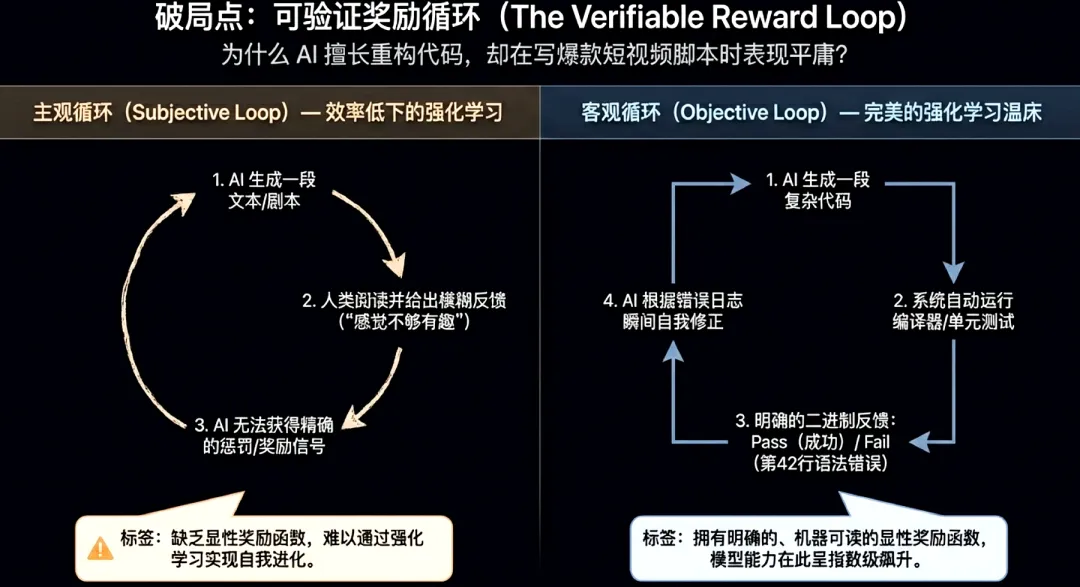
相比之下,写作等“软任务”因缺乏统一客观的评判标准,难以构建自动化的反馈闭环。由于无法通过即时运行结果判定优劣,这些领域的模型进步在用户端显得相对迟滞。
商业优先级与B2B高价值场景
商业激励进一步加剧了能力鸿沟。AI厂商在资源配置上优先向经济价值最高的领域倾斜。在B2B场景中,自动重构复杂软件系统或解决高难度科研课题具备极高的变现潜力。对于企业而言,将OpEx(运营性支出)转化为高效的智能体自动化流程,或通过一次性CapEx(资本性支出)投入算力集群与Fabric高速互连,已成为核心竞争策略。
尽管市场数据显示70%的ChatGPT消费级查询与工作无关,但这些任务由于容错率高且缺乏明确的经济闭环,并未成为Agentic Capabilities的核心优化目标。这种资源偏斜导致了能力的“峰值化”特征:AI在特定硬技术领域(如编程和数学)已经能够交付人类数周的工作量,而在通用搜索、写作等领域进步则相对平缓。
5.结语
感知鸿沟对未来预判的塑造
当前的“感知鸿沟”正深远影响着不同群体对技术斜率的预判。接触旧版模型的普通用户判断趋于保守;而在技术前沿使用智能体工具的专业群体,则持更激进的预期。这种认知分化意味着,社会对AI潜力的共识正随任务应用深度而发生断裂。
软件开发生命周期(SDLC)的系统性重塑
随智能体能力的指数级增长,SDLC正经历范式转移。由智能体驱动的自动化执行、测试与文档生成,已将开发周期从数周压缩至数小时。这不仅降低了工程师接入代码库的时间,也使企业能实现动态的“激增式”人才配置,彻底改写了软件工程的经济模型。
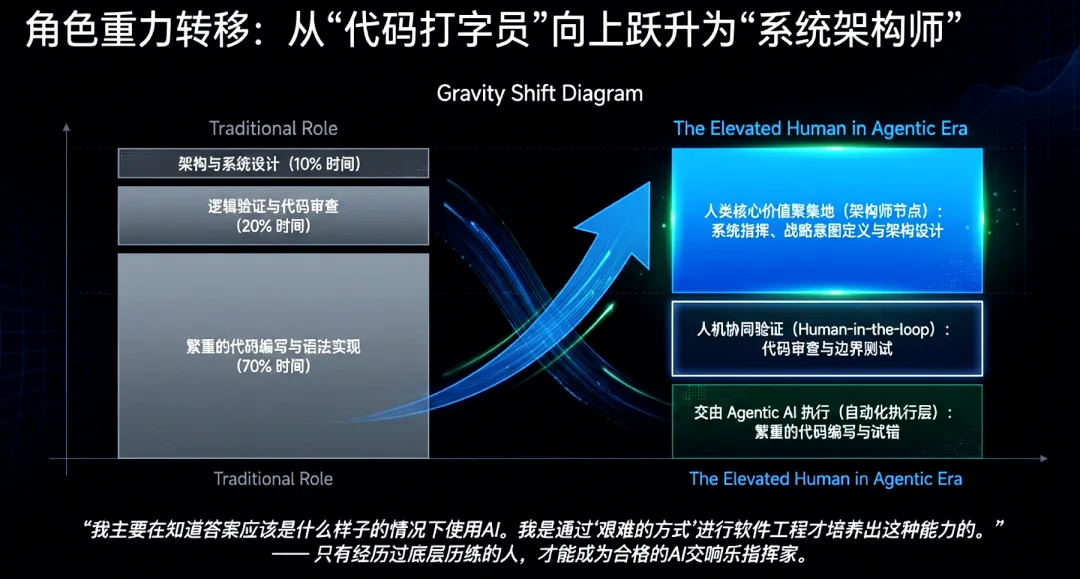
从“代码编写者”向“智能体编排者”的角色转型
工程师的核心价值正从战术性编写转向系统架构设计、智能体编排与质量审校。开发者的主要职责是编排能够自主协作的智能体集群,提供战略方向并确保问题解决。这要求开发者具备更强的“全栈”视角,在掌握高性能互连技术的同时,精通任务拆解、智能体专业化分配及协议制定。
智能体协作与人类判断力的融合
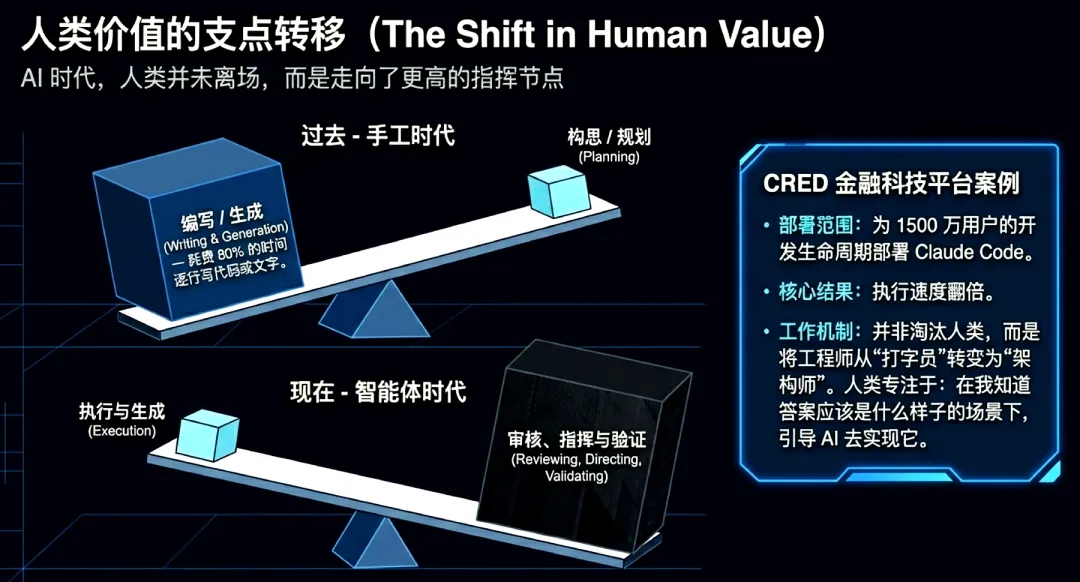
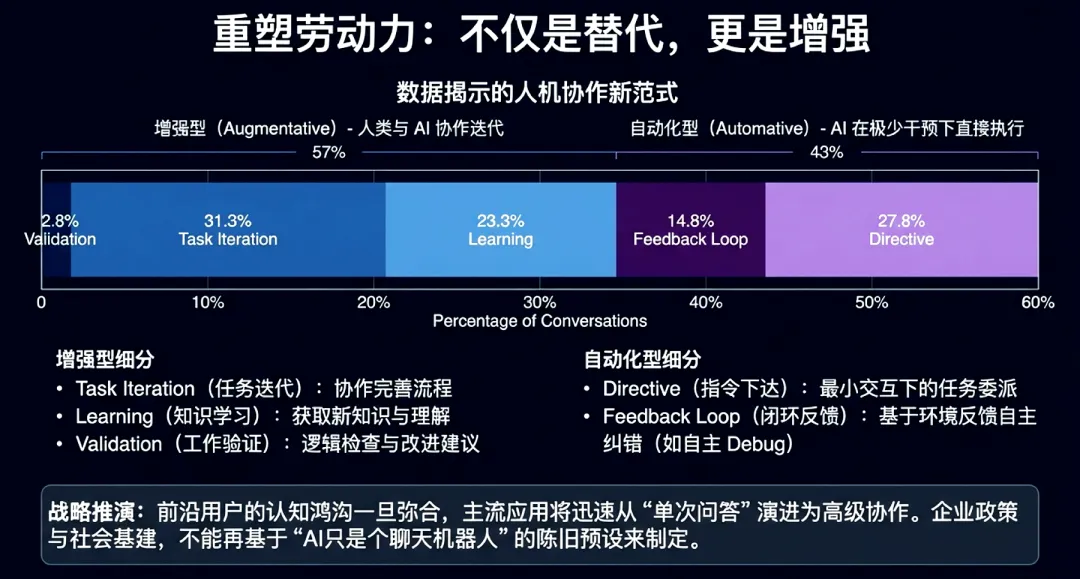
未来的竞争重心不再是单纯的人机对话,而是大规模系统设计中的智能协作。单智能体工作流正被多智能体协同系统取代,通过并行推理与专业化分工处理复杂任务。在此模式下,人类的角色依然不可替代:有效的协作需要人类在关键节点提供战略监督、验证输出质量,并基于组织背景行使最终判断。随智能体编排模式的趋于成熟,人类判断力将与AI执行力在复杂社会系统中达成深度融合。
References
Handa, K., Tamkin, A., McCain, M., et al. (2025). Which Economic Tasks are Performed with AI? Evidence from Millions of Claude Conversations. Anthropic Research. Available at: https://huggingface.co/datasets/Anthropic/EconomicIndex/
Chatterji, A., Cunningham, T., Deming, D., et al. (2025). How People Use ChatGPT. OpenAI & National Bureau of Economic Research (NBER).
Kwa, T., West, B., Becker, J., et al. (2025). Measuring AI Ability to Complete Long Software Tasks. Model Evaluation & Threat Research (METR).
OECD (2026). The Agentic AI Landscape and Its Conceptual Foundations. OECD Artificial Intelligence Papers, No. 56. OECD Publishing, Paris.
Anthropic (2026). 2026 Agentic Coding Trends Report: How coding agents are reshaping software development.
METR (2026). Task-Completion Time Horizons of Frontier AI Models. Model Evaluation & Threat Research. Updated March 3, 2026. Available at: https://metr.org/time-horizons/
Karpathy, A. (2025). On the AI Perception Gap. Social Media Post (X).
AI Digest (2026). A New Moore's Law for AI Agents: Tracking the exponential growth of autonomous task completion. Data source: METR Time Horizon 1.1.
更多交流,可加本人微信
(请附中文姓名/公司/关注领域)

