 夜雨聆风
夜雨聆风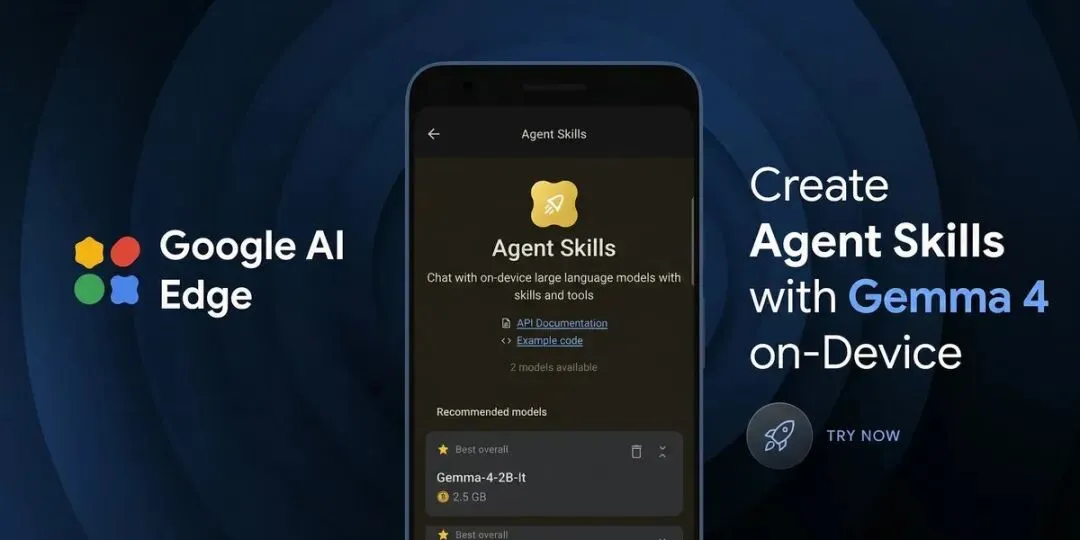
过去两周,AI Agent 领域最值得关注的动作来自 Google。不是又发了个大模型跑分,而是把完整的 Agent 能力塞进了端侧设备。同时 OpenAI 在安全合规方向继续布局,Veo 3.1 Lite 则让视频生成的成本门槛再降一半。逐个拆解。
Gemma 4:端侧 Agent 这件事,终于有人认真做了
Google DeepMind 4 月 2 日发布的 Gemma 4,表面上是又一个开源模型家族更新,但如果你只关注参数量和 benchmark,就错过了这次发布真正的信号:Google 正在用 Gemma 4 定义「端侧 Agent」的工程范式。
几个关键点:
多步规划和自主行动,不需要微调就能跑。 这不是"端侧能跑个聊天机器人"的程度。Gemma 4 直接支持 multi-step planning 和 autonomous action,也就是说你可以在手机上跑一个能分解任务、调用工具、自主决策的 Agent,而不只是一个问答框。Apache 2.0 协议,商用无压力。
Agent Skills 这个概念值得重点关注。 Google AI Edge Gallery 里新上线的 Agent Skills,是我见过的第一个把「端侧 Agent 工作流」做成可体验产品的尝试。它能做什么?举个例子:你可以给 Agent 挂一个 Wikipedia 查询的 skill,让它在完全离线的情况下,先规划查询策略,再调用技能获取信息,最后组织回答。整个过程全部在设备上完成,不经过云端。
这对实际开发意味着什么?
第一,隐私敏感场景终于有了靠谱的 Agent 方案。 医疗、金融、企业内网——这些场景对数据出端有严格限制,之前要做 Agent 基本只能自己量化部署,踩坑无数。Gemma 4 配合 LiteRT-LM 这个推理库,把这条路铺平了不少。LiteRT-LM 号称提供"简化 API"实现低延迟推理,实测下来确实比之前自己搞 GGML 转换要省心。
第二,离线 Agent 的可用性大幅提升。 代码生成、文档处理、多语言翻译(支持 140+ 语言)——这些能力在断网环境下也能工作。对于做工业巡检、户外作业、边缘计算场景的团队来说,这是实打实的能力补全。
第三,Android AICore 的开发者预览版同步开放了内置 Gemma 4 模型的访问。 这意味着如果你做 Android 应用,可以直接调用系统级的 Agent 能力,不用自己打包模型。对 APK 体积和用户体验都是好事。
我的判断:端侧 Agent 在 2026 年会成为一个独立赛道。 不是说它会替代云端 Agent,而是两者会分化出完全不同的应用场景和技术栈。如果你现在的项目涉及设备端智能,建议尽早拿 Gemma 4 跑几个 POC,熟悉 LiteRT-LM 的开发流程。先发优势在这个领域很值钱,因为端侧部署的工程经验很难靠读文档补齐。
Gemini + MediaPipe:Vibe Coding 进入体感交互时代
这条消息在 AI Agent 圈子里讨论度不高,但我觉得它代表了一个有意思的方向:用大模型生成交互式应用的完整代码,而且是带物理世界感知能力的那种。
Google 在 AI Studio 里新增了一个 showcase gallery,展示用 Gemini + MediaPipe 做体感交互游戏和应用的工作流。具体怎么玩?
你在 AI Studio 里用自然语言描述你想要的应用,比如"做一个体感控制的 Chrome 恐龙跑酷游戏,用 MediaPipe Pose Landmarker 检测玩家跳跃动作",Gemini 3.1 Pro 几分钟内就能生成一个完整可运行的 Web 应用。包括游戏逻辑、姿态检测、调试面板,全部一步到位。
这里面有几个对 Agent 开发者有启发的点:
MediaPipe 提供的是标准化的感知能力接口。 人脸追踪、手势识别、姿态检测、图像分割——这些能力都是跨平台的,而且针对实时性做过优化。如果你在做需要感知物理世界的 Agent,MediaPipe 是目前最成熟的中间层。 不需要自己训练视觉模型,直接调用就行。
Gemini Canvas 作为原型工具的效率非常高。 传统做法是先写需求文档,再找人开发,再调试。现在的流程是:描述想法 → 生成原型 → 在 AI Studio 里迭代优化 → 导出。对于需要快速验证 Agent 交互方式的场景,这个工作流能省掉大量前期开发时间。
建议关注的场景: 零售门店的客流分析 Agent、工厂产线的质检 Agent、康复训练的动作评估 Agent——这些都是 MediaPipe 感知能力 + Agent 决策能力的天然结合点。之前这类项目的门槛在视觉模型的部署和调优上,现在这个门槛几乎被抹平了。
OpenAI 发布面向青少年的安全策略框架
OpenAI 3 月 24 日发布了 `gpt-oss-safeguard`,一套基于 prompt 的青少年安全策略,供开发者在自己的应用中集成。
这件事的意义不在技术本身,而在于它释放的信号:平台方正在把安全责任向开发者端下沉。
之前的模式是:OpenAI 在模型层面做内容过滤,开发者只管调 API。现在 OpenAI 明确告诉你,针对特定人群(比如未成年人)的安全保护,需要开发者在应用层自己实现。`gpt-oss-safeguard` 提供的是策略模板和最佳实践,但最终的落地执行在你这边。
对 Agent 开发者的实际影响:
- 如果你的 Agent 产品面向 C 端用户,青少年安全合规现在是必选项,不是加分项。 尤其是教育类、社交类、创意内容类 Agent,不做年龄分级和内容审核,迟早会出问题。
- Prompt-based safety 的思路值得借鉴。 与其在 Agent 外面套一层过滤器,不如在 system prompt 层面就把安全策略写进去。这样做的好处是安全逻辑和业务逻辑耦合度低,维护成本也低。
- 建议把 `gpt-oss-safeguard` 的策略文档通读一遍,不管你用不用 OpenAI 的模型。 里面关于年龄特定风险的分类方式和缓解策略,对接入任何大模型的 Agent 应用都有参考价值。
Veo 3.1 Lite:视频生成成本再降 50%
Google 3 月底发布了 Veo 3.1 Lite,定位是"最具性价比的视频生成模型"。核心数据:成本不到 Veo 3.1 Fast 的一半,速度相同。 支持文生视频和图生视频,支持横屏竖屏,720p/1080p 分辨率,4/6/8 秒时长可选。
同时 Google 宣布 4 月 7 日会进一步降低 Veo 3.1 Fast 的价格。
这对 Agent 开发者意味着什么?视频生成终于可以作为 Agent 的常规工具调用了。
之前视频生成的成本太高,只能用在少数高价值场景。现在成本降到这个水平,很多之前想都不敢想的 Agent 应用可以跑起来了:
- 营销 Agent 自动生成短视频素材,按不同平台比例批量产出,成本可控
- 客服 Agent 生成操作演示视频,替代纯文字说明
- 教育 Agent 根据学习内容动态生成解释视频
本周值得注意的趋势
回看这几条消息,有一个共同的方向越来越清晰:Agent 的基础设施层正在快速成熟。
端侧推理有了 Gemma 4 + LiteRT-LM,感知能力有了 MediaPipe,视频生成有了 Veo 3.1 Lite,安全合规有了 gpt-oss-safeguard。这些都是 Agent 开发中的关键拼图,而且都在朝着"降低门槛、标准化接口"的方向演进。
对个人开发者和小团队来说,现在做 Agent 产品的技术门槛已经降到历史最低点。 瓶颈不再是"能不能做",而是"做什么场景"和"怎么做到好用"。
下周继续跟进 Veo 3.1 Fast 降价后的实际成本对比,以及 Gemma 4 在端侧部署的实测体验。如果你已经在用这些工具,欢迎留言交流踩坑经验。
