 夜雨聆风
夜雨聆风Claude Code × Codex × CoPaper.AI × VS Code 统一工作台
一、培训概述
1.1 培训背景
2026 年,AI 编程工具已从"锦上添花"变成"研究基础设施"。耶鲁大学 Paul Goldsmith-Pinkham 教授开设了面向应用经济学家的 Claude Code 系列课程;GitHub 上的 awesome-ai-for-economists 项目已整理出超过 100 个经济学 AI 工具和资源;CoPaper.AI 等平台让"从数据到论文"的全流程 AI 辅助成为可能。
但国内高校的经济学师生,面临三个核心痛点:
- 工具门槛高
:Claude Code、Codex 等工具需要终端操作,对习惯 Stata GUI 的研究者来说有陡峭的学习曲线 - 网络环境特殊
:部分 AI 工具需要海外账号或特殊网络配置 - 缺乏学科适配
:现有 AI 培训多面向程序员,经济学实证研究的特殊需求(计量模型、面板数据、因果推断)缺少针对性教学
本培训方案旨在弥补这一缺口。
1.2 培训目标
培训结束后,学员应能够:
在 VS Code 中配置并使用 Claude Code 扩展和 Codex CLI 用自然语言指令让 AI 生成 Stata / Python 代码,完成数据清洗、变量构建、计量回归 使用 CoPaper.AI 完成从研究设计到论文初稿的全流程协作 理解 AI 辅助研究的学术伦理边界,合理使用而非滥用 通过 MCP 服务器直接在编辑器内查询 FRED、世界银行等经济数据
1.3 适用对象
1.4 培训规模与时长
- 时长
:2 天,共 12 学时(每天 6 学时,含实操练习) - 规模
:每期 20-50 人(需配备电脑和网络) - 形式
:讲授 30% + 演示 30% + 动手实操 40% 
图 1:培训课程四大模块总览
二、工具介绍与对比
2.1 Claude Code
定位:Anthropic 出品的全能型 AI 编程 Agent,可以读写本地文件、运行代码、管理 Git。
核心能力:
理解整个项目的代码结构,自主规划执行步骤 支持 CLI(终端命令行)和 VS Code 扩展两种使用方式 VS Code 扩展提供 inline diff 预览、@-提及文件、计划审查等图形化功能 可通过 CLAUDE.md 文件定制项目级别的 AI 行为规范 支持 MCP(Model Context Protocol)接入外部数据源
经济学应用场景:
自然语言描述 → 生成 Stata do 文件 / Python 脚本 从 FRED、World Bank 等数据库自动下载和清洗数据 辅助 LaTeX 论文撰写和格式排版 解读回归结果、建议稳健性检验方案
费用:Anthropic Pro 订阅 $20/月
2.2 OpenAI Codex CLI
定位:OpenAI 出品的轻量级终端 AI 编程助手,擅长快速生成代码片段。
核心能力:
纯终端操作,一条命令即可获得代码 沙盒隔离执行,安全性高 在 VS Code 中可通过 GitHub Copilot 的模型选择器切换到 Codex 模型 VS Code 的 Agent Sessions 面板支持 Copilot / Claude / Codex 三个 Agent 并行运行
经济学应用场景:
快速生成一次性的数据处理脚本 批量处理文件格式转换 生成简单的统计图表代码
费用:ChatGPT Plus $20/月 或 OpenAI API
2.3 CoPaper.AI
定位:面向学术研究的端到端论文协作平台,不是"帮你写论文",而是"人机协作研究"。
核心能力:
上传数据后,填写 15 模块、53 字段的研究信息表(从研究问题到计量方法) 按 P1(引言)→ P2(数据与方法)→ P3(结果)→ P4(结论)逐章生成 每章 AI 草拟后必须经人类审核确认才进入下一步 内置代码执行环境,回归表和统计图表基于真实数据生成 支持中英双语界面和论文输出
经济学应用场景:
完整的实证论文从构思到初稿的全流程 特别适合 DID、IV、面板固定效应等标准计量方法 生成后可导出 LaTeX,在 VS Code 中进一步精修
费用:按项目付费
2.4 VS Code:统一工作台
为什么选择 VS Code 作为核心平台?
VS Code 在 2026 年已经不只是代码编辑器——它是 AI 编程指挥中心:
同时运行 Claude Code、Codex、GitHub Copilot 三个 AI Agent 内置终端可以直接运行 Stata、Python、R 命令 丰富的扩展生态:LaTeX Workshop、Stata Enhanced、Python 等 免费、跨平台(Windows/macOS/Linux)、中文界面支持

图 2:三大工具定位与能力对比
三、培训详细日程
Day 1 上午 · 模块一:环境搭建与基础认知(3 学时)
第 1 节(60 分钟):AI 编程工具认知与 VS Code 环境搭建
讲授内容:
AI 辅助研究的现状与趋势
耶鲁大学 Claude Code for Applied Economists 系列课程简介 AI 工具在经济学研究中的角色:执行工具而非替代思考 学术伦理红线:AI 不能替代研究者的学术判断 VS Code 安装与配置
扩展名称 用途 安装命令 Chinese Language Pack 中文界面 扩展市场搜索安装 Claude Code AI Agent code --install-extension anthropic.claude-codeGitHub Copilot AI 补全 扩展市场搜索安装 Python Python 支持 扩展市场搜索安装 Stata Enhanced Stata 语法高亮 扩展市场搜索安装 LaTeX Workshop 论文排版 扩展市场搜索安装 下载安装:code.visualstudio.com 中文语言包安装 必装扩展清单: 终端基础知识(面向零基础学员)
VS Code 内置终端的打开方式( Ctrl+`)基本命令: cd(切换目录)、ls(查看文件)、mkdir(创建文件夹)Windows 用户注意事项:PowerShell vs CMD
动手实操:
安装 VS Code 并配置中文界面 在终端中练习基本命令 创建一个名为 econ-research的项目文件夹
第 2 节(60 分钟):Claude Code 安装与首次使用
讲授内容:
Claude Code 安装(双路径)
路径 A:VS Code 扩展(推荐初学者)
VS Code → 扩展市场 → 搜索 "Claude Code" → 安装安装后侧边栏出现 Claude Code 图标路径 B:终端 CLI 安装
# macOS / Linuxcurl -fsSL https://claude.ai/install.sh | bash# Windows PowerShellirm https://claude.ai/install.ps1 | iex账号与登录
需要 Anthropic 账号(Pro $20/月) VS Code 扩展:点击侧边栏 Claude 图标 → 自动引导登录 CLI:运行 claude→ 浏览器自动打开登录页面基本交互方式
操作 VS Code 扩展 终端 CLI 启动 点击侧边栏图标 claude提问 在聊天面板输入 直接输入文字 引用文件 @文件名 自动读取项目文件 查看代码变更 inline diff 预览 终端显示 diff 接受修改 点击"接受" 输入 y 第一个任务:让 Claude 分析项目
这个文件夹里有什么数据文件?帮我做一个基本的描述性统计
动手实操:
安装 Claude Code(扩展或 CLI 二选一,推荐扩展) 完成登录 在 econ-research目录下创建一个示例 CSV 文件,让 Claude 分析
第 3 节(60 分钟):Codex CLI 与 CoPaper.AI 配置
讲授内容:
Codex CLI 安装
# 检查 Node.js 版本(需要 >= 22)node -v# 安装 Codex CLInpm i -g @openai/codex# 国内镜像加速npm i -g @openai/codex --registry=https://registry.npmmirror.comVS Code 内使用 Codex
安装 GitHub Copilot 扩展 → 模型选择器 → 选择 Codex 模型 Agent Sessions 面板:可同时运行 Copilot / Claude / Codex CoPaper.AI 注册与界面导览
访问 copaper.ai → 注册账号 创建新研究项目 了解研究信息表的 15 个模块结构 演示:上传示例数据集
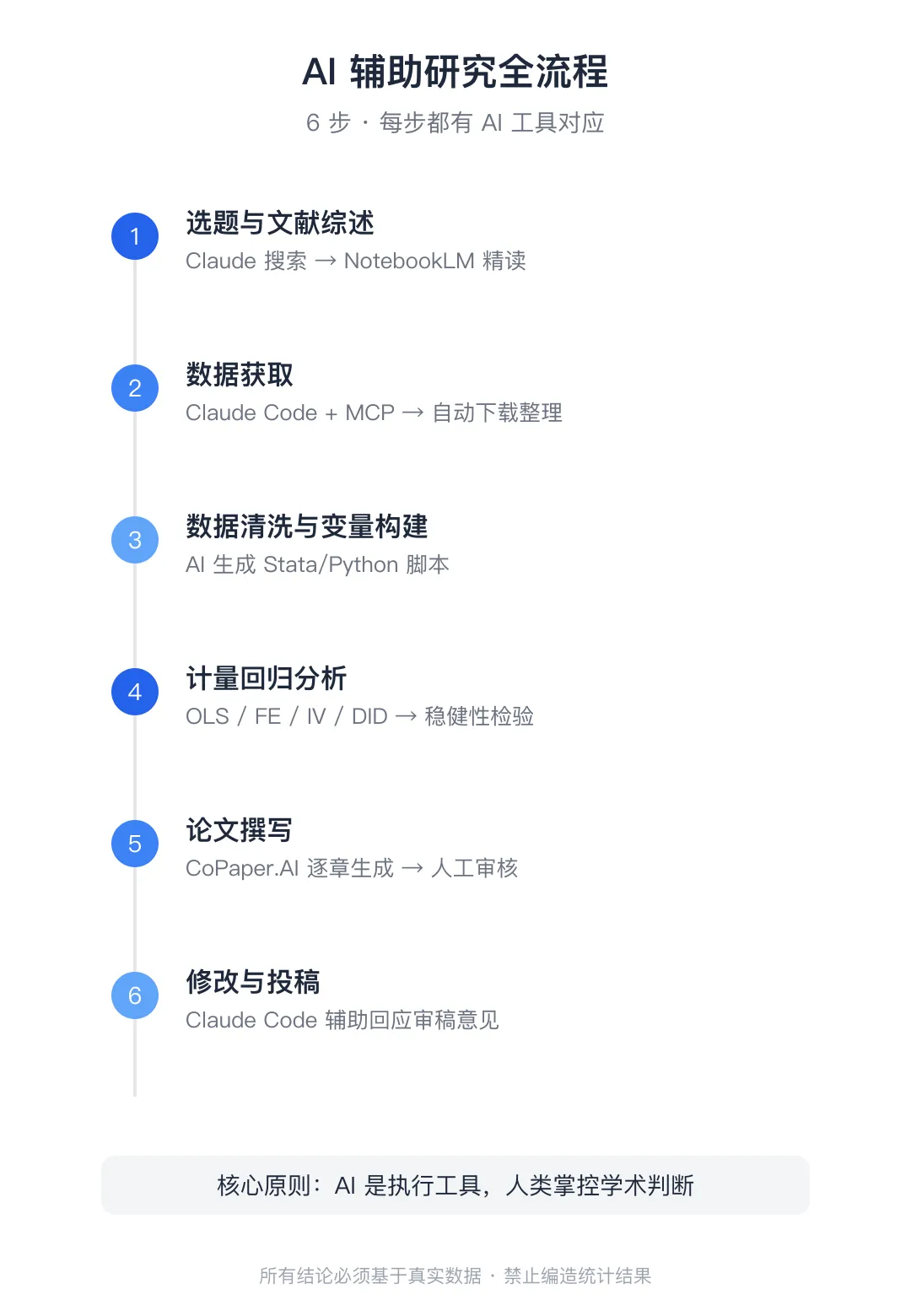
图 3:三大工具安装路径速查(CLI + VS Code)
动手实操:
安装 Codex CLI 或配置 Copilot 中的 Codex 模型 注册 CoPaper.AI 并创建一个测试项目 在 VS Code 中同时打开 Claude Code 和终端,体验多面板工作流
Day 1 下午 · 模块二:数据获取与清洗(3 学时)
第 4 节(60 分钟):AI 辅助数据获取
讲授内容:
经济学常用数据源
数据库 数据类型 获取方式 FRED(美联储) 宏观经济时间序列 API / MCP World Bank Open Data 跨国发展指标 API / MCP CSMAR(国泰安) 中国上市公司数据 手动下载 CNKI / Wind 中国经济统计 手动下载或API Penn World Table 跨国GDP和生产率 直接下载 CHIP / CFPS 中国家庭面板调查 申请获取 用 Claude Code 获取公开数据
在 VS Code 的 Claude Code 面板中输入:
帮我从 FRED 下载美国 1990-2024 年的季度 GDP 增长率和失业率数据,保存为 CSV 文件,列名用英文Claude Code 会自动:
生成 Python 脚本(使用 fredapi 库) 下载数据并清洗格式 保存到项目目录 MCP 服务器:直接在 VS Code 中查询数据
- FRED MCP
:80 万+ 时间序列 - World Bank MCP
:发展指标 - BLS MCP
:美国劳动统计(CPI、失业率、工资) - OpenEcon
:统一接口,33 万+ 指标 MCP = Model Context Protocol,让 AI Agent 直接连接外部数据源 常用经济数据 MCP 服务器:
动手实操:
用 Claude Code 下载一组 FRED 数据 用 Codex 一行命令生成 Python 数据下载脚本 检查并验证下载的数据完整性
第 5 节(60 分钟):AI 辅助数据清洗
讲授内容:
经济学数据清洗的常见任务
任务 Stata 命令示例 AI 提示词示例 缺失值处理 drop if missing(gdp)"删除 GDP 缺失的观测" 异常值处理 winsor2 gdp, cuts(1 99)"对 GDP 变量做 1%/99% Winsorize" 变量生成 gen ln_gdp = ln(gdp)"生成 GDP 的自然对数" 滞后变量 gen L1_gdp = L.gdp"生成 GDP 的一阶滞后" 面板设置 xtset id year"设置面板数据,个体 ID 为 id,时间为 year" 合并数据 merge 1:1 id year using ..."按 id 和 year 合并这两个数据集" 在 VS Code 中用 Claude Code 生成 Stata do 文件
我有一个面板数据集 firm_data.csv,包含以下变量:- firm_id: 企业ID- year: 年份 (2010-2022)- revenue: 营业收入(万元)- employees: 员工数- rd_expense: 研发支出(万元)- province: 省份请帮我写一个 Stata do 文件,完成以下清洗步骤:1. 导入 CSV 数据2. 设置面板结构3. 对 revenue 和 rd_expense 做 1%/99% 的 Winsorize4. 生成 ln_revenue = ln(revenue), rd_intensity = rd_expense/revenue5. 生成描述性统计表6. 输出到 results/ 文件夹Python 数据清洗(替代方案)
对于没有 Stata 的学员,用 Python + pandas:
帮我用 Python 对 firm_data.csv 做以下处理:- 用 pandas 读取- 删除缺失值超过 50% 的变量- 对连续变量做描述性统计- 画出各变量的分布直方图- 保存清洗后的数据为 firm_data_clean.csv
动手实操:
使用提供的示例数据集,在 VS Code 中用 Claude Code 完成数据清洗 生成 Stata do 文件或 Python 脚本 运行脚本并检查清洗结果
第 6 节(60 分钟):描述性统计与可视化
讲授内容:
AI 生成描述性统计表
帮我生成一个标准的描述性统计表(Table 1),包含:- 变量名、观测数、均值、标准差、最小值、中位数、最大值- 输出为 LaTeX 格式,可以直接粘贴到论文中- 风格参考 AER(American Economic Review)的排版AI 生成可视化图表
帮我画以下图表,保存为 PDF 和 PNG 格式:1. 各省份平均 revenue 的柱状图2. ln_revenue 和 rd_intensity 的散点图3. revenue 按年份的趋势线图使用 matplotlib,风格要学术论文级别在 VS Code 中实时预览
Python 生成的图表可以在 VS Code 中直接预览 LaTeX 表格可以通过 LaTeX Workshop 扩展预览
动手实操:
生成描述性统计表 生成 2-3 个数据可视化图表 将结果组织到 results/文件夹中
Day 2 上午 · 模块三:计量分析与论文撰写(3 学时)
第 7 节(60 分钟):AI 辅助计量回归分析
讲授内容:
常用计量方法的 AI 提示词模板
OLS 回归:
请用 Stata 对 firm_data_clean.dta 做以下回归:- 因变量:ln_revenue- 自变量:rd_intensity, ln_employees- 控制变量:year dummies, province dummies- 聚类标准误到企业层面- 输出回归表到 reg_table1.tex面板固定效应:
请用 Stata 做面板固定效应回归:- 因变量:ln_revenue- 核心解释变量:rd_intensity- 固定效应:企业固定效应 + 年份固定效应- 标准误聚类到企业层面- 用 estout 输出发表级别的回归表工具变量(IV):
请用 Stata 做 IV 回归:- 因变量:ln_revenue- 内生变量:rd_intensity- 工具变量:同行业其他企业的平均研发强度- 做第一阶段 F 统计量检验- 做过度识别检验(如果有多个 IV)双重差分(DID):
请用 Stata 做 DID 分析:- 处理组:2015 年后获得政策补贴的企业- 控制组:未获得补贴的企业- 处理时间:2015 年- 因变量:ln_revenue- 做平行趋势检验并画图- 做安慰剂检验AI 辅助结果解读
我得到了以下回归结果:[粘贴回归输出]请帮我:1. 解释每个系数的经济含义2. 评估统计显著性3. 建议可能的稳健性检验4. 用中文写一段适合放在论文中的结果描述稳健性检验清单
检验类型 目的 AI 提示词关键词 替换因变量 测量敏感性 "换一个因变量的代理变量重新跑" 替换自变量 测量稳健性 "用替代指标替换核心解释变量" 缩样本 样本选择 "删除极端值/特定年份后重新回归" 安慰剂检验 因果验证 "做安慰剂检验,用假的处理时间" PSM-DID 样本匹配 "做倾向得分匹配后再做 DID" 更换聚类层面 标准误稳健 "换到行业层面聚类"
动手实操:
选择一个计量方法,用 Claude Code 生成完整的 Stata do 文件 运行回归并获取结果 让 AI 解读回归结果并生成论文段落
第 8 节(60 分钟):CoPaper.AI 全流程论文写作
讲授内容:
CoPaper.AI 工作流程
Step 1:创建项目并上传数据
Step 2:填写研究信息表
Step 3:逐章生成与审核
每章生成后必须人工确认才能继续——这是 CoPaper.AI 保证学术诚信的核心机制。
Step 4:导出与精修
导出 LaTeX 格式 在 VS Code 中用 LaTeX Workshop + Claude Code 进一步修改 P1 引言:研究动机、文献贡献、论文结构 P2 数据与方法:数据来源、变量说明、模型设定 P3 实证结果:回归表、图表、结果解释 P4 结论:主要发现、政策建议、局限性 核心研究问题 文献背景与理论框架 变量定义(因变量、自变量、控制变量、工具变量) 计量方法选择(OLS、FE、IV、DID 等) 异质性分析方案 稳健性检验方案 支持 CSV、DTA 格式 系统自动识别变量类型 学术伦理重点提醒
CoPaper.AI 生成的是初稿,不是成品 所有学术判断(研究问题选择、因果识别策略、结果解释)必须由研究者做出 投稿时应按期刊要求披露 AI 工具的使用
动手实操:
在 CoPaper.AI 中完成一个迷你研究项目的 P1-P2 部分 体验逐步确认机制 将生成的内容导出到 VS Code 中查看
第 9 节(60 分钟):回归表与论文图表制作
讲授内容:
发表级别回归表
帮我用 Stata 的 esttab 命令,把以下三个回归结果做成一个三列的回归表:- 模型1:OLS 基准回归- 模型2:加入控制变量- 模型3:面板固定效应表格风格参考 AER,保留 3 位小数,标注 */**/*** 显著性水平输出 LaTeX 格式AI 辅助论文图表
帮我用 Python matplotlib 画以下图表,学术风格:1. 平行趋势检验图(处理组 vs 控制组,标注处理时间垂直线)2. 系数图(coefficient plot),展示核心变量在不同子样本中的效果3. 事件研究图(event study),展示处理效应的动态变化所有图表用灰度配色,适合黑白打印在 VS Code 中管理论文项目
项目文件结构建议:econ-research/├── data/│ ├── raw/ # 原始数据│ └── clean/ # 清洗后数据├── code/│ ├── 01_clean.do # 数据清洗│ ├── 02_analysis.do # 回归分析│ └── 03_figures.py # 图表生成├── results/│ ├── tables/ # 回归表│ └── figures/ # 图表├── paper/│ └── main.tex # 论文主文件└── CLAUDE.md # AI 配置文件
动手实操:
生成一个标准的三列回归表 生成一个平行趋势检验图 在 VS Code 中组织项目文件结构
Day 2 下午 · 模块四:进阶技巧与实战项目(3 学时)
第 10 节(60 分钟):进阶配置与定制化
讲授内容:
CLAUDE.md:项目级 AI 配置文件
在项目根目录创建
CLAUDE.md:# 项目:中国企业研发与绩效研究## 研究背景本项目分析中国上市公司的研发投入对企业绩效的影响。使用 CSMAR 数据库 2010-2022 年的面板数据。## 编码规范- 统计软件:Stata 17 / Python 3.11- Stata do 文件:使用 estout/esttab 输出回归表- Python:使用 pandas, matplotlib, statsmodels- 所有变量名使用小写英文加下划线- 回归表保留 3 位小数## 变量字典- firm_id: 企业股票代码- year: 年份- revenue: 营业收入(万元)- rd_expense: 研发支出(万元)- rd_intensity: 研发强度 = rd_expense / revenue- ln_revenue: 营收对数- employees: 员工数- province: 省份## 注意事项- 标准误始终聚类到企业层面- 所有回归包含年份固定效应- 连续变量做 1%/99% Winsorize配置好后,Claude Code 在这个项目中会自动遵循上述规范。
Skills:经济学专属技能包
从 awesome-econ-ai-stuff 社区安装:
/r-econometrics:R 语言 IV、DID、RDD 分析 /stata-regression:Stata 发表级别回归输出 /python-panel:Python 面板数据分析 /latex-paper:LaTeX 学术论文撰写 /econ-data-fetch:FRED/World Bank 数据获取 Agent Sessions:多 Agent 并行工作
在 VS Code 的 Agent Sessions 面板中:
用 Claude Code 做复杂的数据分析和代码重构 用 Copilot 做实时代码补全 用 Codex 执行独立的批处理任务
动手实操:
为自己的研究项目创建 CLAUDE.md 体验 Skills 的安装和使用 在 Agent Sessions 中同时使用两个 Agent
第 11 节(30 分钟):学术伦理与最佳实践
讲授内容:
AI 辅助研究的伦理边界
可以做 不应做 AI 生成代码,人工审查逻辑 不审查直接使用 AI 生成的回归结果 AI 辅助写作初稿,人工修改 AI 生成整篇论文直接投稿 AI 建议稳健性检验方案 让 AI 选择"好看的"结果 AI 辅助翻译和润色 隐瞒 AI 工具的使用 用 AI 理解复杂代码 盲目信任 AI 的统计解读 关键原则
- 人类主导
:研究问题、因果识别策略、结果解释必须由研究者决定 - 可重现性
:保留所有 AI 交互记录和生成的代码 - 透明披露
:按期刊要求说明 AI 工具的使用方式 - 数据真实
:所有统计结果必须基于真实数据运行,绝不编造 主要经济学期刊的 AI 政策
AER、QJE 等顶刊已制定 AI 使用披露要求 国内期刊(如《经济研究》《管理世界》)也在跟进 建议:在论文致谢或方法部分明确说明使用了哪些 AI 工具
第 12 节(90 分钟):分组实战项目
项目说明:
学员分为 4-5 人一组,在 90 分钟内完成以下任务:
选题(任选一个):
要求:
在 VS Code 中使用 Claude Code 完成数据清洗(20 分钟) 完成基准回归和至少一个稳健性检验(30 分钟) 生成描述性统计表和回归表(20 分钟) 用 CoPaper.AI 生成论文 P1(引言)初稿(15 分钟) 小组展示(每组 5 分钟):讲解研究思路、展示结果、反思 AI 使用体验
评分维度:
研究设计的合理性(40%) AI 工具使用的熟练度(30%) 结果的可解释性(20%) 学术伦理意识(10%)

图 4:AI 辅助经济学实证研究全流程
四、培训前准备清单
4.1 硬件与网络要求
4.2 软件预装清单
- VS Code
:code.visualstudio.com 下载最新版 - Node.js >= 22
:nodejs.org 下载 LTS 版本 - Python 3.10+
:python.org 或 Anaconda - Stata
(如有):版本 15 及以上 - Git
:git-scm.com(Windows 用户必装)
4.3 账号准备
4.4 培训师准备
[ ] 准备示例数据集(4 个选题各一个) [ ] 准备每个工具的备用演示视频(防止网络问题) [ ] 准备国内模型替代方案(DeepSeek / GLM),应对海外服务不可用的情况 [ ] 测试培训教室的网络环境 [ ] 为每位学员准备一份安装速查卡(单页打印)
五、培训后跟进
5.1 学习资源
视频课程:
Paul Goldsmith-Pinkham 的 Claude Code for Applied Economists(7 集) DeepLearning.AI 的 Claude Code 短课程
GitHub 资源:
awesome-ai-for-economists:100+ 经济学 AI 工具 awesome-econ-ai-stuff:18+ Claude Code 经济学技能包 Stata-MCP:在 VS Code 中直接运行 Stata
推荐阅读:
《Generative AI for Economic Research》(AEA 2025 更新版) 各工具官方文档(Claude Code Docs / OpenAI Codex Docs)
5.2 进阶学习路径
入门阶段(培训后 1-2 周) → 在自己的真实研究项目中使用 Claude Code 做数据清洗中级阶段(1-2 个月) → 配置 CLAUDE.md 和 Skills → 尝试 MCP 服务器连接数据源 → 使用 CoPaper.AI 完成一篇完整论文初稿高级阶段(3-6 个月) → 自定义 Skills 适配研究需求 → 使用 Agent Teams 功能实现多 Agent 并行分析 → 在课题组内推广 AI 辅助研究工作流5.3 常见问题 FAQ
Q:国内网络环境下这些工具能正常使用吗? A:Claude Code 和 Codex CLI 需要海外网络环境。替代方案包括:使用 cc-switch 工具切换到国内模型(DeepSeek、GLM);或使用学校提供的国际网络。CoPaper.AI 网页端在国内可以直接访问。
Q:没有 Stata 怎么办? A:Python + statsmodels / linearmodels 可以替代 Stata 完成绝大多数计量分析。Claude Code 和 Codex 都能生成 Python 代码。
Q:AI 生成的代码可靠吗? A:AI 生成的代码需要人工审查。建议流程:AI 生成 → 人工检查逻辑 → 运行测试 → 核对结果。不要盲目信任 AI 输出的统计结果。
Q:使用 AI 工具写论文算学术不端吗? A:关键在于如何使用。AI 作为编码和写作辅助工具是可以接受的,但研究设计、因果识别、结果解释必须由研究者独立完成。请按期刊要求披露 AI 使用情况。
Q:费用谁来承担? A:建议学院或课题组统一采购。Claude Pro 和 ChatGPT Plus 各 $20/月,是性价比很高的科研投入。部分工具(GitHub Copilot)对学生免费。
六、技术细节补充
6.1 Stata MCP 扩展:VS Code 中直接运行 Stata 的完整配置
Stata MCP 是目前最成熟的 Stata + AI 集成方案,能让 Claude Code、GitHub Copilot 等 AI 直接在 VS Code 中执行 Stata 命令并获取实时输出。
安装步骤:
# 方式 1:VS Code 扩展市场# 搜索 "Stata MCP" → 安装# 方式 2:命令行安装code --install-extension DeepEcon.stata-mcp系统要求:
Stata 17 或更高版本 UV 包管理器(扩展首次启动时自动安装,约需 2 分钟)
核心快捷键:
Ctrl+Shift+Enter | Cmd+Shift+Enter | |
Ctrl+Shift+D | Cmd+Shift+D | |
Ctrl+Shift+C | Cmd+Shift+C |
关键配置项(settings.json):
{"stata-vscode.stataPath":"/Applications/Stata/StataMP.app/Contents/MacOS/stata-mp","stata-vscode.stataEdition":"mp","stata-vscode.mcpServerHost":"localhost","stata-vscode.mcpServerPort":4000,"stata-vscode.resultDisplayMode":"compact","stata-vscode.workingDirectory":"relative"}与 AI 工具集成:
Claude Code 接入 Stata MCP:
claude mcp add --transport sse stata-mcp http://localhost:4000/mcpGitHub Copilot 接入(.vscode/mcp.json):
{"servers":{"stata-mcp":{"type":"sse","url":"http://localhost:4000/mcp"}}}接入后,AI 可以直接执行 Stata 代码并读取回归结果,无需在 Stata GUI 和编辑器之间来回切换。
6.2 CLAUDE.md 进阶配置:经济学研究项目模板
根据社区最佳实践(建议控制在 300 行以内),以下是经济学实证研究的完整 CLAUDE.md 模板:
# 项目:[研究标题]## 研究概述- 研究问题:[一句话描述]- 方法:[OLS / FE / IV / DID / RDD]- 数据来源:[CSMAR / FRED / CFPS / 自采]- 数据时间跨度:[2010-2022]## 编码规范- 主力软件:Stata 17(do 文件)+ Python 3.11(数据获取和可视化)- Stata 回归输出:使用 esttab/estout,保留 3 位小数- Python 可视化:matplotlib 学术风格,灰度配色适配黑白打印- 变量命名:小写英文 + 下划线(如 ln_revenue, rd_intensity)- 所有路径使用相对路径,禁止硬编码绝对路径## 变量字典| 变量名 | 含义 | 类型 | 来源 ||--------|------|------|------|| firm_id | 企业标识 | ID | CSMAR || year | 年份 | 时间 | - || revenue | 营业收入(万元) | 连续 | CSMAR || ... | ... | ... | ... |## 统计规范- 标准误聚类层面:企业层面- 固定效应:企业 FE + 年份 FE- 连续变量 Winsorize:1% / 99%- 显著性标注:* p<0.1, ** p<0.05, *** p<0.01## 文件结构- data/raw/ → 原始数据(不可修改)- data/clean/ → 清洗后数据- code/ → 按编号排序的脚本- results/tables/ → 回归表(LaTeX 格式)- results/figures/ → 图表(PDF + PNG)## 禁止事项- IMPORTANT: 不要编造或伪造任何统计结果- IMPORTANT: 不要在未经确认的情况下删除观测值- 不要修改 data/raw/ 目录中的任何文件进阶技巧:
模块化管理:大型项目可用
@import引用子文件@import code/variable_dictionary.md@import code/regression_specs.md团队协作:将 CLAUDE.md 提交到 Git,团队成员共享同一套规范
自我优化:当 Claude 犯错时直接说"把这条规则添加到 CLAUDE.md",让纠正沉淀下来
个人配置:在
CLAUDE.local.md(加入 .gitignore)中存放个人偏好
6.3 75 个 Stata AI 提示词精选(按研究阶段分类)
以下提示词可直接在 Claude Code 或 Codex 中使用:
数据清洗阶段:
1. "读取 firm_data.csv,检查所有变量的缺失值比例,生成缺失值报告"2. "对所有连续变量做 1%/99% 的 Winsorize 处理,使用 winsor2 命令"3. "检测 revenue 变量的异常值(超过均值±3个标准差),列出这些观测"4. "将 province 变量从中文转换为省份代码,生成 province_code"5. "按 firm_id 和 year 去重,保留每组最后一条记录"6. "生成以下滞后变量:L1_revenue, L2_revenue, L1_rd_expense"7. "将年度数据与月度数据按 year 和 firm_id 合并,使用 1:m merge"8. "检查面板数据的平衡性,报告每个企业的观测年份数量分布"描述性统计阶段:
9. "生成发表级别的描述性统计表(Table 1),包含 N、Mean、SD、Min、P25、P50、P75、Max"10. "生成相关系数矩阵,标注显著性水平,输出 LaTeX 格式"11. "按处理组和控制组分别生成描述性统计,做均值差异 t 检验"12. "画出 ln_revenue 的核密度图,按处理前后分组叠加显示"13. "生成各年份样本量的时间序列图,检查是否有样本断层"回归分析阶段:
14. "运行基准 OLS 回归:ln_revenue = β₀ + β₁×rd_intensity + Controls + ε"15. "运行面板固定效应回归,包含企业 FE 和年份 FE,聚类到企业层面"16. "做 Hausman 检验,判断应该使用固定效应还是随机效应"17. "运行 IV 回归:内生变量 rd_intensity,工具变量为同行业平均研发强度"18. "报告第一阶段 F 统计量,检验工具变量是否足够强"19. "运行 DID 回归:treat × post 交互项,控制企业和年份固定效应"20. "做事件研究分析(event study),画出动态效应图,标注 95% 置信区间"稳健性检验阶段:
21. "替换因变量为 ROA,重新运行基准回归"22. "删除直辖市样本后重新回归,检验结果是否稳健"23. "做安慰剂检验:将处理时间提前 2 年,检验是否有显著效果"24. "做 PSM-DID:先用 Logit 模型估计倾向得分,然后最近邻匹配后做 DID"25. "做 Bootstrap 标准误检验,重复 1000 次"26. "将聚类层面从企业层面换到行业-年份层面,重新估计标准误"27. "做排除限制检验(overidentification test),使用 Hansen J 统计量"输出与可视化阶段:
28. "用 esttab 生成三列回归表,列标题为 OLS、FE、IV,输出 LaTeX"29. "画系数图(coefficient plot),展示核心变量在不同子样本中的效果"30. "画平行趋势检验图,处理组和控制组分别用实线和虚线"6.4 国内网络环境适配方案
方案 A:使用国内模型替代(零海外依赖)
通过 cc-switch 工具或环境变量切换后端模型:
# 使用 DeepSeek 替代 Claudeexport ANTHROPIC_BASE_URL="https://api.deepseek.com/v1"export ANTHROPIC_API_KEY="your-deepseek-key"# 使用智谱 GLM 替代export ANTHROPIC_BASE_URL="https://open.bigmodel.cn/api/paas/v4"export ANTHROPIC_API_KEY="your-glm-key"推荐国内模型:
- DeepSeek V3
:代码能力强,中文优秀,API 价格低 - GLM-4.7
:中文优化最好,适合论文写作辅助 - Kimi K2
:超长上下文(128K+),适合处理大数据集
方案 B:学校统一网络方案
联系学校网络中心,确认是否提供科研用国际网络 部分高校图书馆已采购 AI 工具统一账号
方案 C:API 中转服务
使用第三方 API 聚合服务(如 OfoxAI),支持微信/支付宝支付,无需海外信用卡。
6.5 高校 AI 使用政策速览(2026 年最新)
根据多所高校已发布的规定,培训中需要向学员强调以下政策要点:
复旦大学(国内首个 AI 禁令):
禁止直接生成论文正文文本 禁止在研究方案设计、创新方法、算法框架等关键环节使用 AI 必须披露 AI 工具名称、版本、使用时间和具体用途
青岛科技大学/江苏大学:
AI 使用遵循"辅助性、透明性、可控性"三原则 禁止 AI 用于核心观点、研究方法、研究结论的生成 允许 AI 用于文献检索、数据处理、引文整理等辅助工作
北京邮电大学:
开发"文察"AI 检测系统,可识别 AI 生成内容(准确率超 90%) AI 仅限辅助工作:文献调研、数据处理、引文整理
共同原则:
学生和导师对提交内容承担全部责任 AI 工具"辅助"而非"替代"原创学术思考 各学院应开展 AI 使用专项教育培训
6.6 Claude Code for Applied Economists 课程笔记
耶鲁大学 Paul Goldsmith-Pinkham 教授的 7 集系列课程是目前最权威的经济学 AI 工具教程:
Episode 1 · Getting Started:
Claude Code 是终端 AI 编程助手,可读写本地文件、运行代码 关键原则:管理上下文窗口(200K token),避免信息过载 推荐搭配工具:Ghostty 终端、Zellij 多窗口管理、Oh My Zsh
Episode 2 · Data Analysis:
演示从 Census 获取美国住房所有权数据 Claude 自动处理数据抓取、清洗、脚本生成全流程 核心理念:"缩小从模糊想法到初步结果的距离"
Episode 3 · Web Scraping:
从 SEC EDGAR 抓取企业 10-K 报告中的风险披露 构建 DuckDB 数据库追踪关税相关风险提及频率 展示"计划→迭代→精化"将非结构化数据转为研究数据集
实操案例(Staggered DID 讲座生成):
输入一条指令:"创建交叠 DID 方法讲座" Claude 自动生成: 3 份 Beamer 幻灯片(共 120 页) 3 个 Stata 脚本(偏误模拟、方法示例、稳健性检验) 使用指南 + 参考文献库 + 统一 LaTeX 格式
6.7 经济学 MCP 数据源完整清单
以下 MCP 服务器可在 Claude Code 中通过一行命令接入:
接入示例:
# 在 Claude Code 中接入 FRED MCPclaude mcp add fred-mcp# 接入后即可直接查询# 提示词:"从 FRED 下载 2000-2024 年美国 CPI 月度数据"6.8 经济学 Claude Code Skills 技能包
从 awesome-econ-ai-stuff 社区可安装以下经济学专属技能包:
# 安装经济学技能包市场/plugin marketplace add anthropics/skills可用 Skills 列表:
/python-panel | ||
/r-econometrics | ||
/stata-regression | ||
/stata-cleaning | ||
/econ-data-fetch | ||
/latex-paper | ||
/beamer-slides | ||
/ggplot-viz |
技能包的工作原理:
Skills 本质上是包含 SKILL.md 文件的文件夹,存放在 ~/.claude/skills/ 目录。Claude 根据任务需求自动判断并激活对应技能——无需手动触发。例如,当你说"帮我做一个 DID 分析"时,Claude 会自动加载 /r-econometrics 或 /stata-regression 技能。
自定义经济学 Skill 示例:
在 ~/.claude/skills/econ-regression/SKILL.md 中:
---name: 经济学回归分析description: 生成标准经济学回归代码,包含固定效应、聚类标准误和发表格式输出---# 执行规范- 所有回归默认包含企业固定效应和年份固定效应- 标准误聚类到企业层面(除非用户另行指定)- 使用 esttab 输出 LaTeX 格式表格- 连续变量默认做 1%/99% Winsorize- 显著性标注:* p<0.1, ** p<0.05, *** p<0.01- 每个回归模型报告 N、R²、F 统计量七、进阶技术细节补充(第二批)
7.1 Claude Code Plan Mode(规划模式)详解
Plan Mode 是 Claude Code 最核心的工作模式,Anthropic 创始人 90% 的时间都在使用此模式。
启用方式:
快捷键 Shift + Tab连按两次Windows: Alt + M命令输入框输入 /plan
工作流程:
接收任务 → 分析项目 → 探索代码库 → 设计方案 → 用户确认 → 执行实现 ↑ ↓ ← 不同意则调整方案 ←经济学研究中的应用:
Plan Mode 特别适合复杂的实证研究项目。例如:
我需要做一个 DID 分析,数据是 2010-2022 年中国上市企业面板数据。处理组是 2015 年获得研发补贴的企业。请先制定分析计划,包括:数据清洗步骤、基准回归设定、平行趋势检验方案、稳健性检验清单。不要直接写代码。Claude 会生成一个详细的多步骤计划,包括每步的具体操作和预期输出,等你确认后才开始写代码。这避免了 AI 直接生成一堆代码但逻辑不对的问题。
什么时候该用 Plan Mode?
修改涉及多个文件的复杂分析 你对方法不确定,需要先讨论方案 你不熟悉被修改的代码 需要在编码前产出可选方案和权衡点
什么时候不用?
能用一句话描述的简单任务,直接跳过计划
7.2 Sub Agent(子代理)并行研究
Sub Agent 是 Claude Code 的"专业化分身",每个子代理在独立的 200K token 上下文窗口中运行。
核心优势:
- 上下文隔离
:探索工作与主对话分离,不污染主线 - 并行执行
:多个子代理同时处理不同任务 - 专业化
:每个子代理可以有定制的系统提示和工具权限 - 成本控制
:可将简单任务路由到更便宜的模型(如 Haiku)
经济学研究中的并行场景:
场景:同时处理多个稳健性检验├── Sub Agent 1(后台):替换因变量为 ROA,重新回归├── Sub Agent 2(后台):删除直辖市样本,重新回归├── Sub Agent 3(后台):做安慰剂检验└── 主 Agent:继续写论文的引言部分创建自定义子代理:
运行 /agents 命令 → 选择 "Create new agent" → 配置:
名称:如 "经济学数据分析员" 系统提示:专注于 Stata 代码生成和数据清洗 工具权限:仅允许 Read、Bash(运行代码)
后台模式: 按 Ctrl+B 将子代理发送到后台运行,你可以继续在主对话中工作。
7.3 Git Worktree:多任务并行的安全沙盒
Git Worktree 让你从一个仓库"克隆"出多个独立工作目录,每个有自己的文件和分支,但共享 Git 历史。
在 Claude Code 中使用:
# 创建隔离的 worktreeclaude --worktree feature-robustness# 或者在 Desktop 版本中:# 点击侧边栏 "+ New session" → 自动创建独立 Worktree经济学研究的典型用法:
主分支:基准回归分析(稳定版本)├── worktree-1:尝试新的工具变量(实验性)├── worktree-2:加入异质性分析(新功能)└── worktree-3:处理审稿人意见(修改版)每个 worktree 是完全隔离的沙盒——万一 AI 搞坏了也不影响主分支。
自动清理: 如果 worktree 没有未提交的修改,Claude Code 会自动删除目录和分支。
7.4 Hooks(钩子):自动化工作流
Hooks 是在 Claude Code 生命周期特定节点自动执行的 shell 命令。
可用的 Hook 事件:
PreToolUse | ||
PostToolUse | ||
Stop | ||
Notification | ||
UserPromptSubmit | ||
SessionStart |
经济学研究中的实用 Hook 示例:
在 ~/.claude/settings.json 中配置:
{"hooks":{"PostToolUse":[{"matcher":"Write","command":"if [[ \"$CLAUDE_FILE\" == *.do ]]; then echo '提醒:请检查 do 文件中的路径是否使用了相对路径'; fi"}],"Stop":[{"command":"echo '任务完成。请人工审查所有统计结果的准确性。'"}]}}7.5 Winsorize 缩尾处理技术细节
缩尾处理是经济学实证研究中处理离群值的标准方法。
原理: 将小于 P1 分位数的值替换为 P1 值,将大于 P99 分位数的值替换为 P99 值。
Stata 实现(winsor2 命令):
* 安装ssc install winsor2, replace* 基本用法:对单个变量 1%/99% 缩尾winsor2 revenue, replace cuts(1 99)* 同时处理多个变量winsor2 revenue rd_expense employees, replace cuts(1 99)* 按年份分组缩尾(面板数据推荐)winsor2 revenue, replace cuts(1 99) by(year)* 生成新变量而非替换winsor2 revenue, cuts(1 99) suffix(_w)* 生成 revenue_wPython 实现:
import numpy as npdefwinsorize(series, lower=0.01, upper=0.99): q_low = series.quantile(lower) q_high = series.quantile(upper)return series.clip(lower=q_low, upper=q_high)# 对面板数据按年份分组缩尾df['revenue_w'] = df.groupby('year')['revenue'].transform(lambda x: winsorize(x, 0.01, 0.99))AI 提示词:
对 firm_data.dta 中的 revenue、rd_expense、employees 三个变量做 1%/99% 的缩尾处理,按年份分组。用 winsor2 命令,生成后缀为 _w 的新变量。处理前后各输出一次描述性统计做对比。7.6 Python linearmodels 面板回归完整示例
对于没有 Stata 的学员,Python 的 linearmodels 库可以完成相同的面板数据分析。
安装:
pip install linearmodels pandas完整面板固定效应回归代码:
import pandas as pdfrom linearmodels.panel import PanelOLS# 读取数据df = pd.read_csv('firm_data_clean.csv')# 设置面板索引(个体 + 时间)df = df.set_index(['firm_id', 'year'])# 方式 1:公式接口(推荐)formula = 'ln_revenue ~ rd_intensity + ln_employees + EntityEffects + TimeEffects'mod = PanelOLS.from_formula(formula, df)res = mod.fit(cov_type='clustered', cluster_entity=True)print(res.summary)# 方式 2:直接传参mod2 = PanelOLS( dependent=df['ln_revenue'], exog=df[['rd_intensity', 'ln_employees']], entity_effects=True, time_effects=True)res2 = mod2.fit(cov_type='clustered', cluster_entity=True)# 导出结果from linearmodels.panel import comparecomparison = compare({'OLS': res_ols, 'FE': res, 'RE': res_re})print(comparison.summary)Hausman 检验(固定效应 vs 随机效应):
from linearmodels.panel import PanelOLS, RandomEffects# 分别估计 FE 和 RE,然后比较系数差异7.7 esttab/estout LaTeX 回归表完整配置
Stata 发表级回归表标准流程:
* 安装ssc install estout, replace* 运行回归并存储eststo cleareststo: reg ln_revenue rd_intensity, robusteststo: xtreg ln_revenue rd_intensity i.year, fe cluster(firm_id)eststo: ivregress 2sls ln_revenue (rd_intensity = iv_rd) i.year, cluster(firm_id)* 输出 LaTeX 格式表格esttab using "results/tables/reg_table1.tex", ///replace/// b(3) se(3) /// star(* 0.1 ** 0.05 *** 0.01) /// title("研发强度与企业绩效") /// mtitles("OLS""FE""IV") /// scalars("N Observations""r2 R-squared""F F-statistic") /// addnotes("标准误聚类到企业层面""*** p<0.01, ** p<0.05, * p<0.1") ///label booktabs关键选项说明:
b(3) | ||
se(3) | ||
star() | ||
mtitles() | ||
scalars() | ||
booktabs | ||
label | ||
drop(_cons) |
7.8 FinanceMCP:中国金融数据直通 Claude
FinanceMCP 是专为中国市场设计的 MCP 服务器,集成 Tushare API,提供 14 个核心数据工具。
数据覆盖:
A 股、港股、美股、基金、债券、期权 宏观经济指标:GDP、CPI、PPI、PMI 等 11 项 实时财经新闻(7+ 主流财经媒体) 资金流向、龙虎榜、融资融券
Claude Code 接入:
# 方式 1:全局安装npm install -g finance-mcp# 方式 2:Claude Code 直接添加claude mcp add finance-mcp配置 Tushare Token:
在 tushare.pro 注册账号 从个人中心获取 API Token 学生可在 QQ 群(290541801)申请 2000 免费积分 在环境变量或配置文件中设置 Token
使用示例:
从 Tushare 获取 2020-2024 年 A 股所有上市公司的年度财务数据,包括营业收入、净利润、研发支出、总资产、行业分类,保存为 CSV 并做基本的描述性统计。7.9 VS Code + LaTeX Workshop 学术论文环境配置
安装步骤:
安装 TeX Live(完整版约 4GB)或 MikTeX VS Code 中安装 LaTeX Workshop 扩展 配置中文支持(XeLaTeX 编译器)
settings.json 关键配置:
{"latex-workshop.latex.tools":[{"name":"xelatex","command":"xelatex","args":["-synctex=1","-interaction=nonstopmode","%DOC%"]},{"name":"bibtex","command":"bibtex","args":["%DOCFILE%"]}],"latex-workshop.latex.recipes":[{"name":"xelatex → bibtex → xelatex × 2","tools":["xelatex","bibtex","xelatex","xelatex"]}],"latex-workshop.view.pdf.viewer":"tab"}经济学论文常用 LaTeX 宏包:
\usepackage{booktabs} % 美观的三线表\usepackage{threeparttable} % 表格注释\usepackage{graphicx} % 插图\usepackage{amsmath} % 数学公式\usepackage{natbib} % 参考文献管理\usepackage{hyperref} % 超链接\usepackage{ctex} % 中文支持(中文论文)7.10 CoPaper.AI 与因果推断前沿方法
CoPaper.AI 在 2026 年已全面支持机器学习与因果推断的交叉方法:
支持的前沿方法:
Causal Forest(因果森林) DML(Double/Debiased Machine Learning) Meta-Learners(S-Learner、T-Learner、X-Learner) Synthetic DID(合成双重差分)
自动代码生成: 系统根据研究设计自动生成使用 econml、grf、DoubleML 等包的可执行代码。
工作流:
在研究信息表中选择因果推断方法 系统自动推荐最适合的前沿方法 生成代码并在内置环境中执行 输出标准格式的回归表和图表 逐章人工审核确认
7.11 StatsPAI:Agent 原生的因果推断与计量经济学工具包
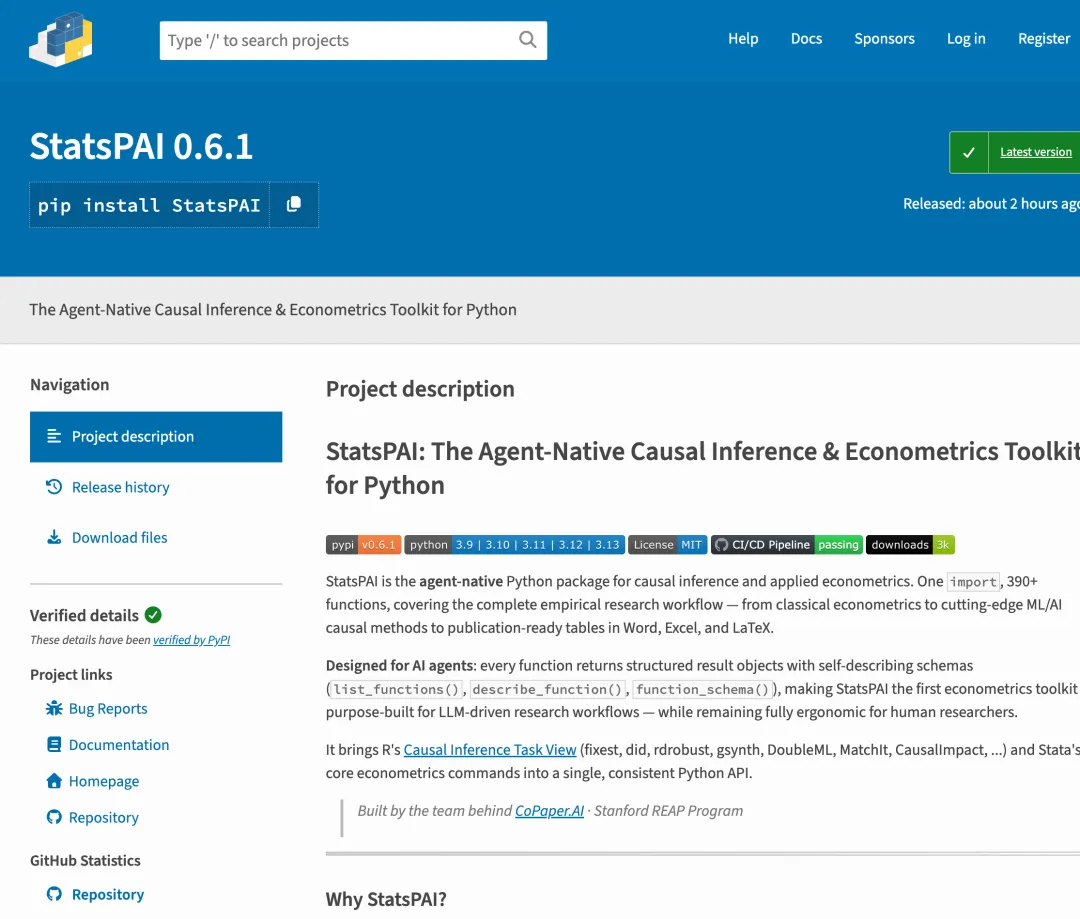
StatsPAI 是由 CoPaper.AI 团队(斯坦福 REAP 项目)开发的开源 Python 包,专为 AI Agent 驱动的实证研究设计。它将传统分散在 R 包(fixest、did、rdrobust、gsynth、DoubleML、MatchIt)和 Stata 计量命令中的能力,统一到一个 Python API 中。
GitHub 地址: github.com/brycewang-stanford/StatsPAI
核心特点:一个 import,390+ 函数,覆盖完整实证研究流程。
安装:
pip install statspai为什么说它是"Agent 原生"?
StatsPAI 的每个函数都返回结构化的 result 对象,自带 schema 描述。内置三个发现函数:
sp.list_functions()— 列出所有可用函数 sp.describe_function("did")— 获取函数的详细说明 sp.function_schema("did")— 获取参数的 JSON Schema
这意味着 Claude Code、Codex 等 AI Agent 可以自动发现、理解和调用任何 StatsPAI 函数,无需人工编写提示词模板。
方法覆盖(390+ 函数):
发表级输出:
每个函数内置 Word + Excel + LaTeX + HTML 四种格式输出:
import statspai as sp# 运行 DID 分析result = sp.did(data, y="ln_revenue", treat="treated", post="post_2015", fe=["firm_id", "year"], cluster="firm_id")# 查看结果result.summary()# 导出result.to_latex("results/tables/did_table.tex")result.to_word("results/tables/did_table.docx")result.plot() # 自动生成平行趋势图和动态效应图# 引用信息result.cite() # 生成引用所用方法论的参考文献自动化稳健性检验:
# 一键规格曲线分析(Specification Curve)sp.spec_curve(data, y="ln_revenue", x="rd_intensity", controls_pool=["size", "age", "leverage", "industry"], fe_pool=["firm_id", "year", "province"])# 一键稳健性报告sp.robustness_report(result, placebo=True, # 安慰剂检验 psm_did=True, # PSM-DID alt_outcomes=["roa", "profit"]) # 替换因变量异质性分析:
# 一键分组异质性分析sp.subgroup_analysis(data, y="ln_revenue", treat="treated", post="post_2015", subgroups=["ownership", "region", "firm_size"])# 自动生成分组回归表和系数对比图交互式图表编辑器(v0.6 新功能):
fig = result.plot()sp.interactive(fig) # 打开类似 Stata Graph Editor 的 WYSIWYG 编辑器# 支持 29 种学术主题、实时预览、自动生成可复现代码与 Claude Code 的配合:
在项目的 CLAUDE.md 中添加:
## 分析工具本项目使用 StatsPAI 进行所有计量分析。使用 sp.list_functions() 查看可用方法。所有回归结果用 .to_latex() 导出到 results/tables/ 目录。配置后,Claude Code 会自动使用 StatsPAI 的 API 执行分析任务,无需你手写代码。
对比传统工具的优势:
subgroup_analysis() | |||
robustness_report() | |||
sp.interactive() |
八、参考来源
1. 文科生小白入门:计量经济学家 Sant'Anna 的 Claude Code 工作流 — 搜狐 sohu.com/a/998724643_121124024
2. Claude Code 国内使用指南 2026:3 个方案对比 — 知乎 zhuanlan.zhihu.com/p/2010435773195911381
3. Claude Code 完全指南:使用方式、技巧与最佳实践 — 博客园 cnblogs.com/knqiufan/p/19449849
4. 2026 Claude Code 工作流最佳实践:当 AI 写 90% 的代码 — ccino.org blog.ccino.org/p/claude-code-workflow-best-practices-2026
5. Codex CLI 国内使用教程(2026 年 2 月最新版) — 小林coding xiaolincoding.com/other/codex.html
6. 2026 年国内 Codex 安装教程和使用教程:GPT-5.3-Codex 完整指南 — 知乎 zhuanlan.zhihu.com/p/2004914542765941622
7. 2026 最新 Codex CLI 国内安装与使用全攻略 — 知乎 zhuanlan.zhihu.com/p/2024551339116491690
8. Codex CLI 国内使用教程(2026 年 4 月最新版) — 编程指北 csguide.cn/private/how-to-use-codex.html
9. CLAUDE.md 全方位指南:构建高效 AI 开发上下文 — 腾讯云开发者社区 cloud.tencent.com/developer/article/2619981
10. CLAUDE.md 文件介绍(Claude Code 核心配置文件) — CSDN blog.csdn.net/Dontla/article/details/150590085
11. Claude Code Skills 保姆级安装和使用教程 — 博客园 cnblogs.com/javastack/p/19176207
12. Skills 技能包开发与自动化实战教程 — 博客园 cnblogs.com/gccbuaa/p/19472806
13. 6 小时掌握 Stata 操作与 AI 辅助 — 经管之家 baoming.pinggu.org/Default.aspx?id=493
14. 75 个 Stata AI 提示实例:提升数据分析效率 — 搜狐 sohu.com/a/830261336_121902920
15. Stata 配置分享:如何通过 VS Code 和 Jupyter 获得更好的 Stata 使用体验 — Beetles' Blog beetlesliu.github.io
16. VScode+Stata:在 VScode 中编辑和运行 Stata 命令 — CSDN blog.csdn.net/arlionn/article/details/119278946
17. 当大学论文多了"AI 味",高校如何给 AI 工具使用立规矩 — 金羊教育 edu.ycwb.com/2025-04/01/content_53329026.htm
18. 多所高校明确论文写作中 AI 使用限度:严禁生成核心观点 — 科技日报 stdaily.com/web/gdxw/2026-03/24/content_491381.html
19. 复旦大学关于本科毕业论文中使用 AI 工具的规定(试行) — 复旦大学 fudan.design/ai.html
20. 2026 最终版:Claude 注册、订阅与稳定使用全攻略 — 红孩儿Redman redman.blog/index.php/2026/03/26/claude2026
21. Claude Code Sub Agent 完全指南:打造专属 AI 编程助手团队 — Kelen kelen.cc/posts/claude-code-subagent-tutorial
22. Claude Code 多 Agent 入门:从一问一答到并行协作 — CSDN blog.csdn.net/Rabbit_QL/article/details/159380443
23. Claude Code 入门实战 5:子代理(Subagent)使用指南 — 知乎 zhuanlan.zhihu.com/p/2010819906703213018
24. Claude Code 新功能:Worktree 并行开发 — 知乎 zhuanlan.zhihu.com/p/2008960546398049214
25. 告别频繁切换分支!Git Worktrees + Claude Code 并行开发 — 腾讯云 cloud.tencent.com/developer/article/2623910
26. Claude Code 接入四大国产编程模型 DeepSeek、GLM、Qwen、Kimi 全指南 — 知乎 zhuanlan.zhihu.com/p/1944667171704779382
27. 五分钟国内配置 Claude Code + DeepSeek 模型完全操作指南 — 知乎 zhuanlan.zhihu.com/p/2010102236194296717
28. Claude Code 使用指南:从官方配置到接入第三方模型 — Kevnu kevnu.com/zh/posts/claude-code-usage-guide-from-official-configuration-to-integrating-third-party-models
29. 计划模式(Plan Mode)详解 — Claude Code 中文站 claude-code-hub.org/docs/foundation/plan-mode
30. Claude Code 新手实战指南:11 条经验分享 — 知乎 zhuanlan.zhihu.com/p/1939514155024490599
31. Stata 回归结果输出之 esttab 详解(更新版) — 腾讯云 cloud.tencent.com/developer/article/1820267
32. Stata 结果输出:用 esttab 命令绘制 LaTeX 表格 — 连享会 lianxh.cn/details/948.html
33. winsor2:离群值和异常值的缩尾处理 — CSDN blog.csdn.net/arlionn/article/details/118303408
34. Python linearmodels 面板数据回归(一) — 知乎 zhuanlan.zhihu.com/p/543143370
35. 使用 NVM 安装 Node.js 22 并配备国内镜像加速 — 博客园 cnblogs.com/clnchanpin/p/19172032
36. FinanceMCP:Tushare + Claude 中国金融数据 MCP 服务器 — GitHub github.com/guangxiangdebizi/FinanceMCP
37. CoPaper.AI 全面支持机器学习 × 因果推断前沿方法 — 知乎 zhuanlan.zhihu.com/p/2019799009443730889
38. AI 赋能课程改革,厦大经济学科探索教学新思路 — 厦门大学 chow.xmu.edu.cn/info/1032/36802.htm
39. 50 种 Matplotlib 科研论文绘图合集 — 知乎 zhuanlan.zhihu.com/p/220345912
40. Claude 新王牌 Skills 深度解析:让 AI 秒变行业专家 — 知乎 zhuanlan.zhihu.com/p/1966598753134842902
英文来源
1. Paul Goldsmith-Pinkham: Claude Code for Applied Economists — Markus Academy markusacademy.substack.com/p/claude-code-for-applied-economists
2. Awesome AI for Economists — GitHub github.com/hanlulong/awesome-ai-for-economists
3. Awesome Econ AI Stuff (Skills) — GitHub Pages meleantonio.github.io/awesome-econ-ai-stuff
4. Claude Code 官方文档(中文) — Anthropic code.claude.com/docs/zh-CN/quickstart
5. OpenAI Codex CLI 文档 — GitHub github.com/openai/codex
6. Stata MCP 扩展文档 — GitHub github.com/hanlulong/stata-mcp
7. AEA: Generative AI for Economic Research (2025 Update) — AEA aeaweb.org/content/file?id=23290
8. 7 Best AI Tools for Economics (2026) — Dupple dupple.com/learn/best-ai-for-economics
9. Claude Code Best Practices — Anthropic code.claude.com/docs/zh-CN/best-practices
10. Using Skills to Extend Claude — Anthropic code.claude.com/docs/zh-CN/skills
11. StatsPAI GitHub Repo —
- 本培训由 来自斯坦福大学 REAP团队的 CoPaper.AI 创始人 Bryce Wang(王几行 XING) 开展,面向中国国内高校经管类/社会科学各方向的教师和学生。
- 本培训通过线上在每周末进行,滚动开班,满 20 人立即开营
- 费用:原价 ¥799,目前 5折 ¥399。2 人以上的团购均有优惠。
- 咨询微信:brycewang2026
