 夜雨聆风
夜雨聆风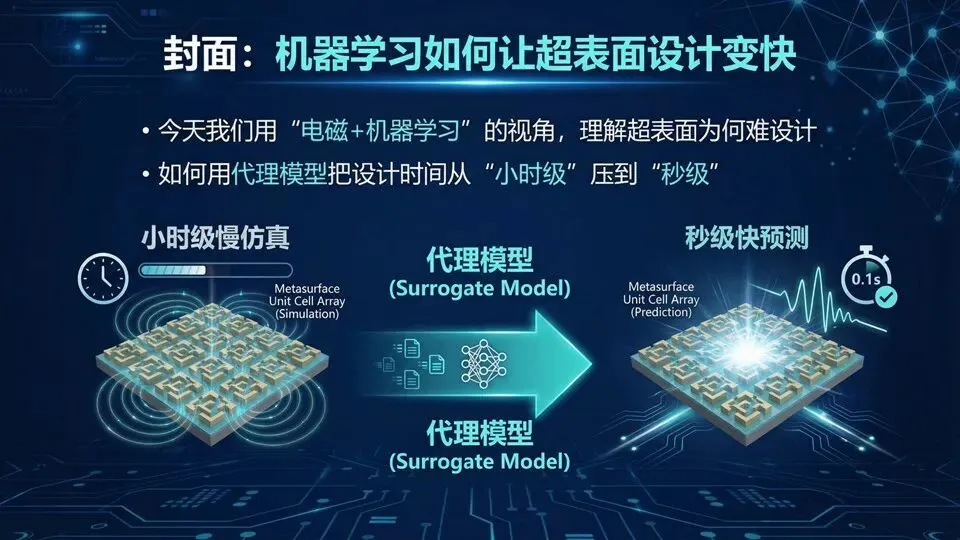
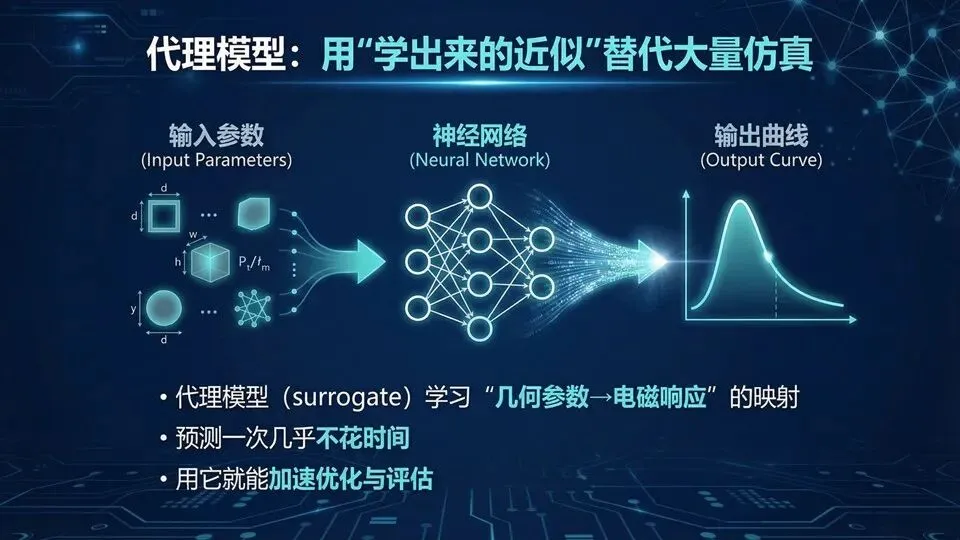
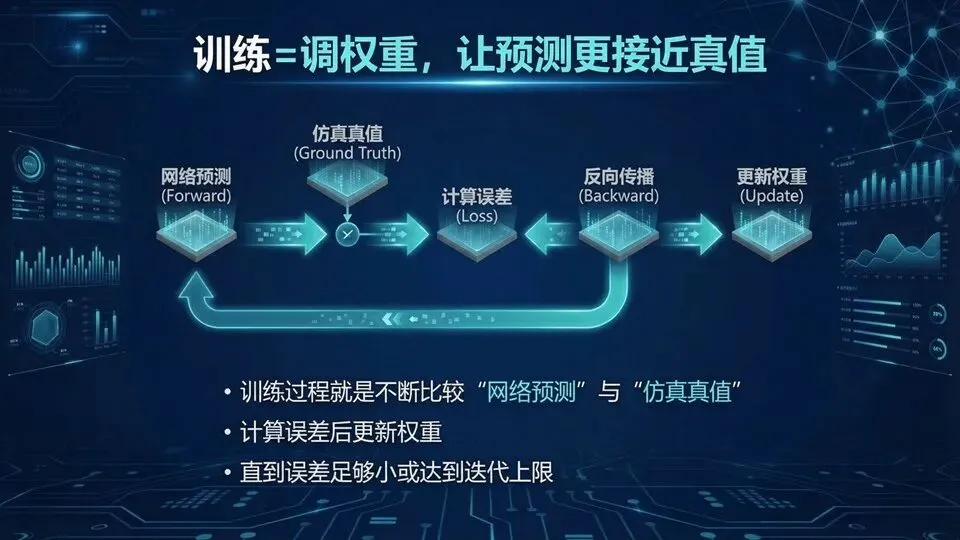
把“反复跑全波仿真”里最耗时的那部分,用学出来的代理模型替掉。你可以把传统设计想成“每改一道菜谱都要从买菜做起”,而代理模型像“训练过的试吃员”:前期先吃够样本(做一批仿真),后面就能秒级给出大致味道(预测幅相),再把少数候选回到全波/实验验收。

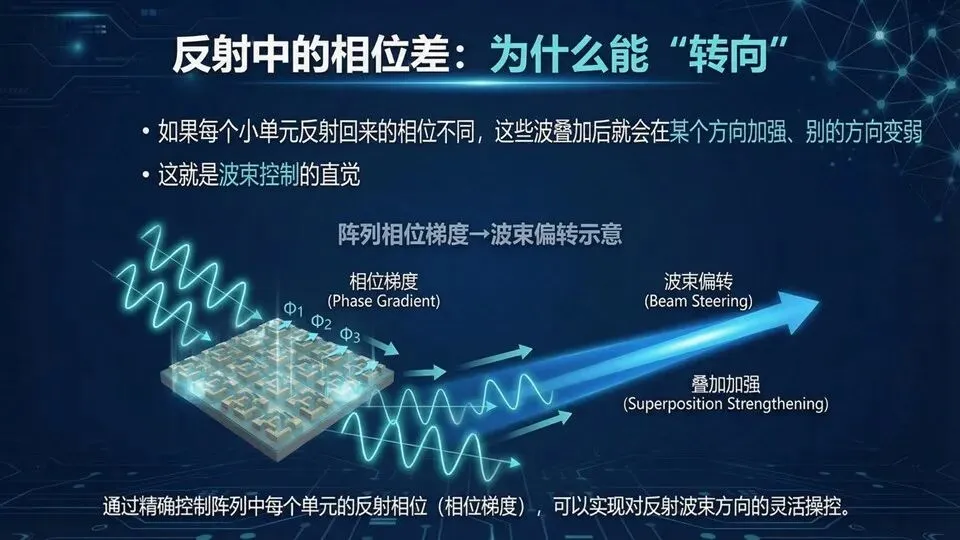
页码:07页面标题:反射中的相位差:为什么能“转向”解释文案:承接上一页“相位来自叠加”,如果每个单元反射的相位不同,波在空间叠加时就会在某个方向同相加强、在其他方向相互抵消,于是主瓣偏转。类比“体育场人浪”:每排起身时间稍微错开,人浪就朝某个方向走。记住:空间相位梯度→定向辐射/反射。提示:“方向性”来自相位分布而非单元形状本身
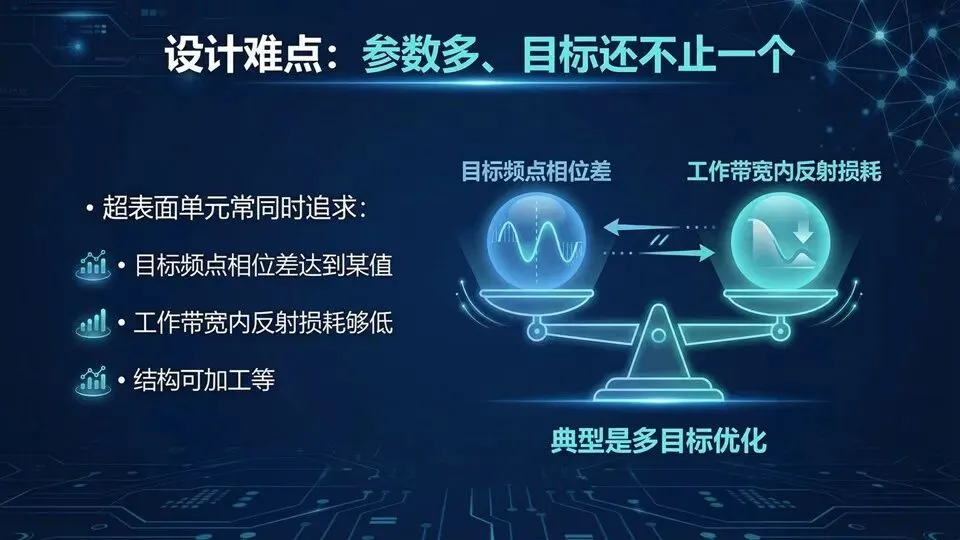
问:幅度不一致会怎样?答:会影响旁瓣与效率,所以优化里会约束“最大幅度损耗”。

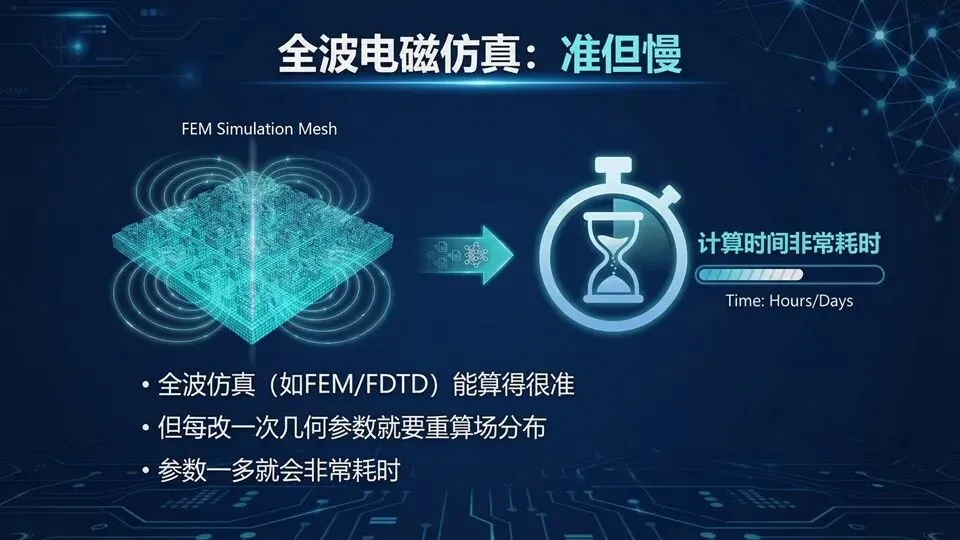
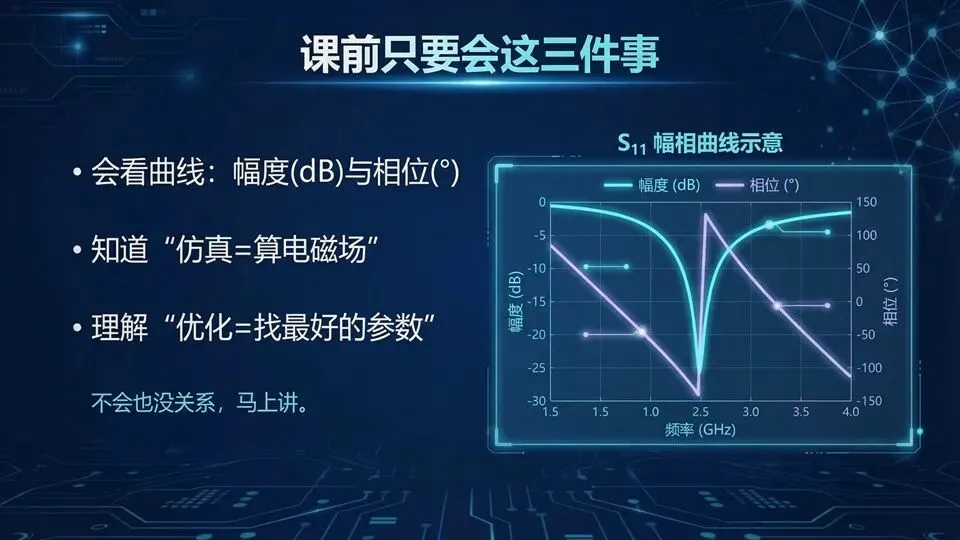
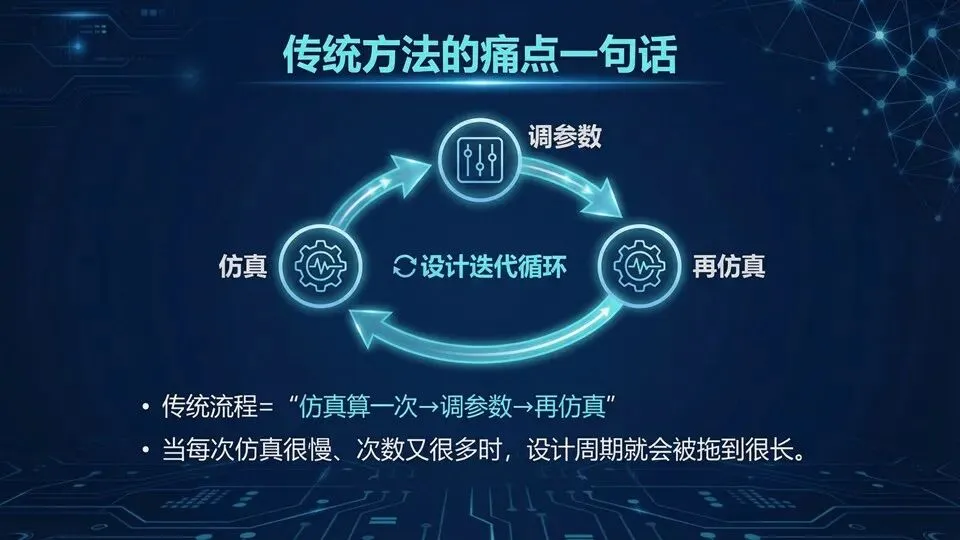
明确“准”与“慢”是 trade-off
总时间≈单次仿真时间×迭代次数
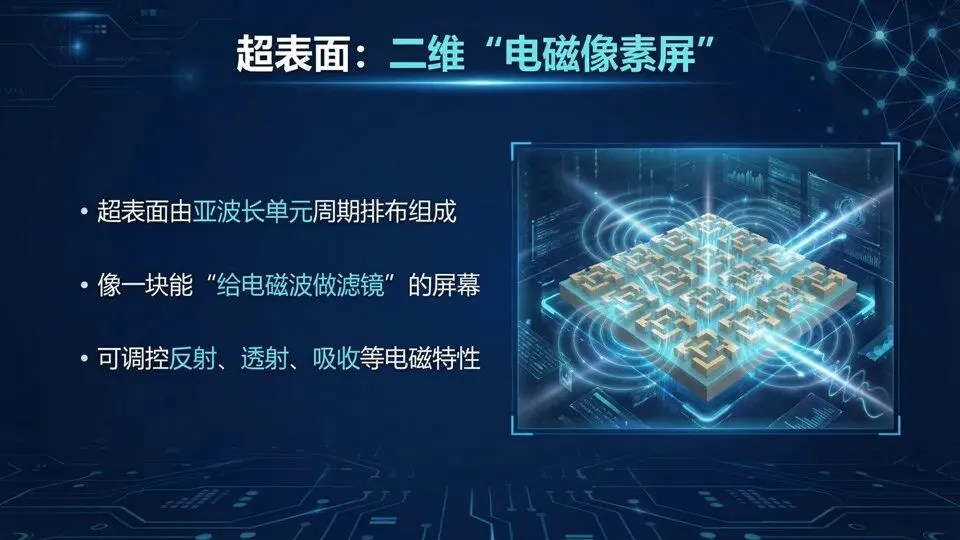
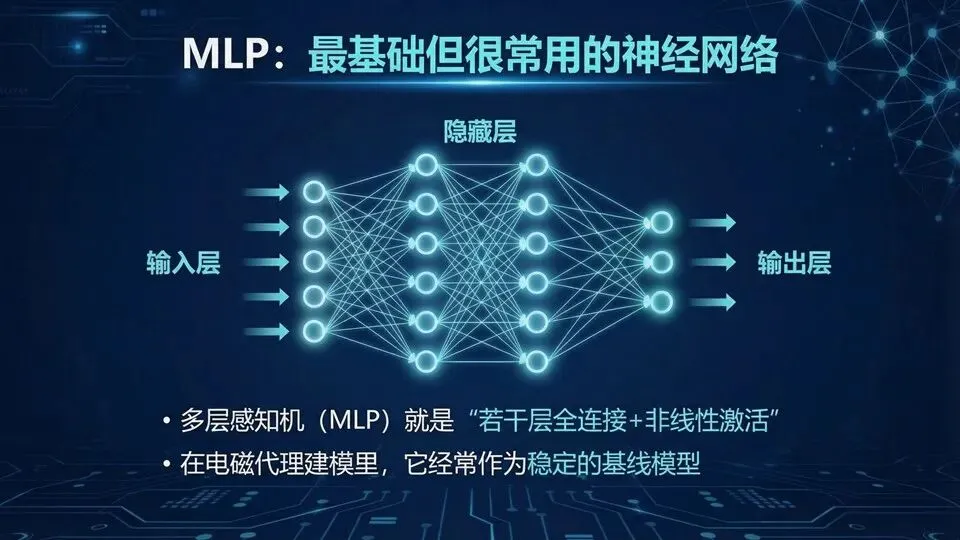
提示:“单元”与“阵列/面板”的层级关系;用手机屏“像素→图像”类比“单元→电磁功能”

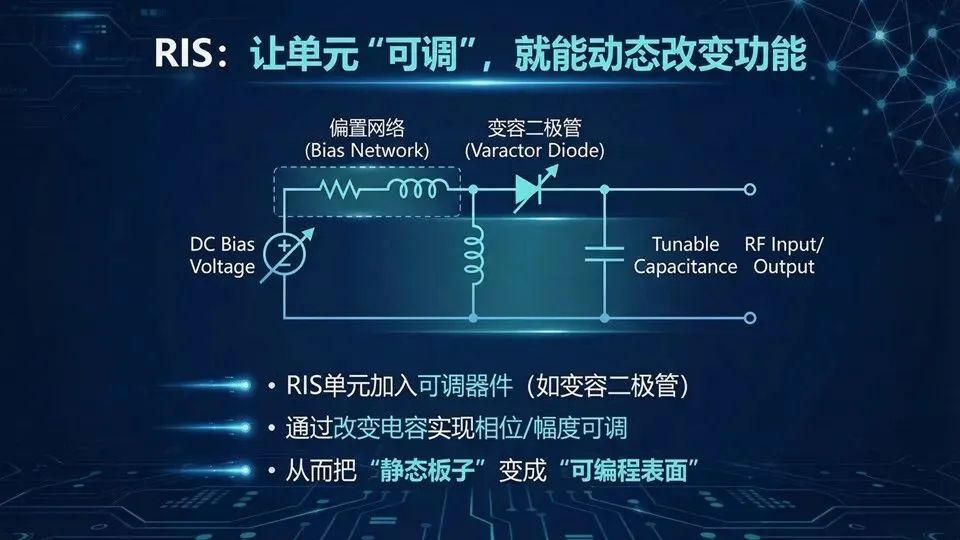
提示:RIS里的“难点=多状态”;用“旋钮调电容→相位变化”来理解
问:调电容只影响相位吗?答:通常幅度也会变,因此优化会同时约束损耗。
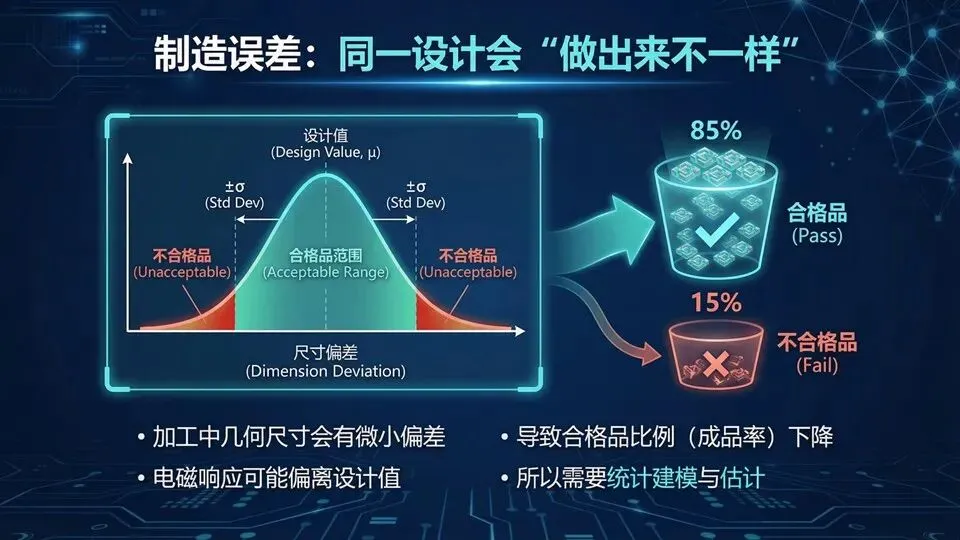
现实里还有“不确定性”:加工尺寸会有微小偏差,尤其对共振结构,几十微米就可能导致谐振点移动,曲线偏离设计值。于是工程不只问“标称最优多好”,更问“有多少样品能达标”,这就是成品率。论文第四章开篇强调:制造不确定性不可避免,传统成品率估计要做大量全波蒙特卡洛,成本非常高,因此需要快速统计建模。提示:用“考试及格率”类比成品率;强调“误差小但影响大”来自共振敏感性。
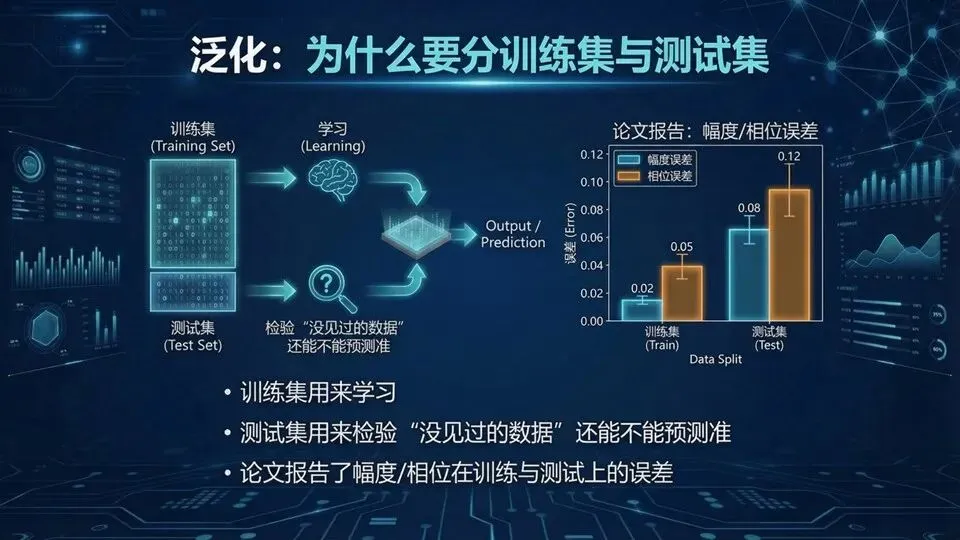
提示:用“练习题 vs 考试题”解释泛化;强调测试集要覆盖参数范围边界。

提示:两端点网络 + 知识层计算;减少仿真量靠“结构化思路”
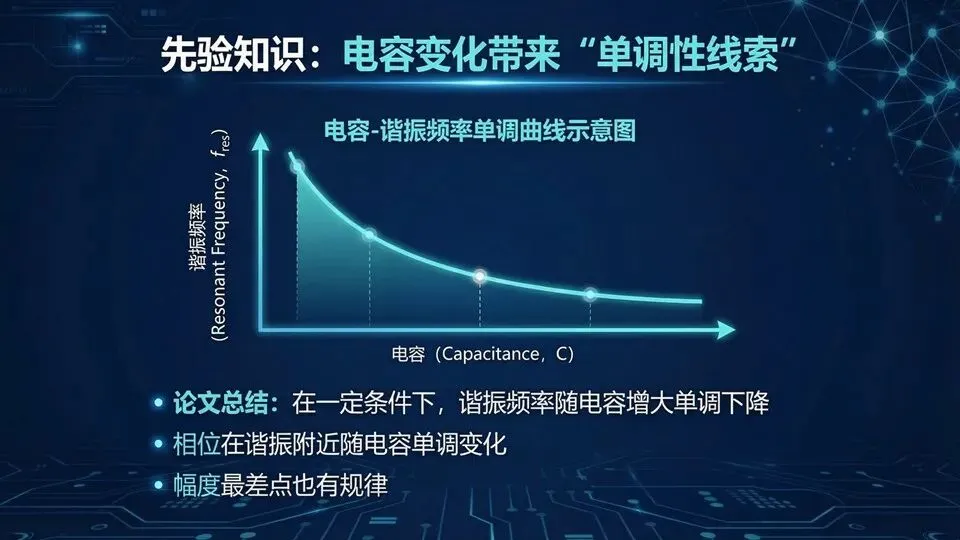
提示:用“RLC共振”给出可理解的物理直觉;强调先验用于“算范围/算最大差值”,不是算每个细节点;先验是否可用最终由验证决定。
问:先验会不会限制最优解?答:可能会,但换来数据量下降与可解释性;工程上常先用它快速筛选。
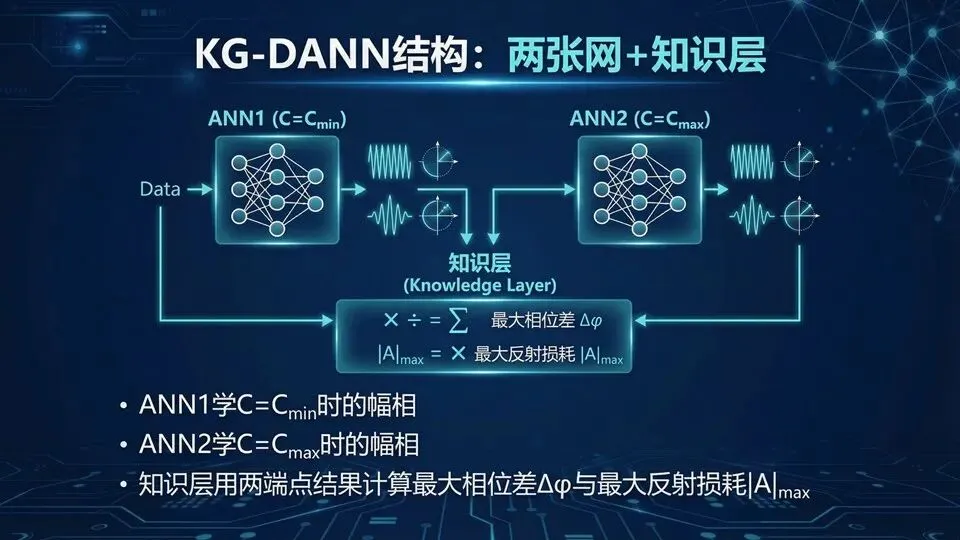
提示:“知识层不训练”,它是可解释公式;Δφ来源:两端点相位差;网络输出是“点频值”,曲线靠多频点拼起来。
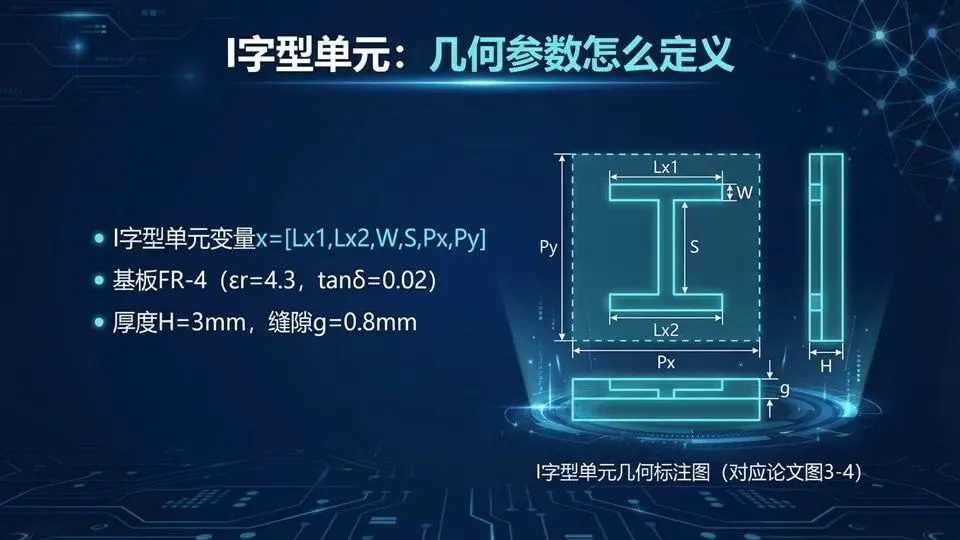
页码:26承接“结构图”,现在落到一个具体单元:I字型RIS单元。论文把它参数化为x=[Lx1,Lx2,W,S,Px,Py],并给出固定材料/尺寸:FR‑4基板(εr=4.3,tanδ=0.02)、厚度H=3 mm、缝隙g=0.8 mm等。你可以把参数化理解为“给结构装上六个旋钮”,优化器只需要调这些旋钮就能搜索设计空间。下页我们讲数据集设置:仿真频段2–8 GHz与频率采样点数,决定了模型学到“多宽的曲线”。
提示:先区分:变量(可调) vs 常量(固定);单位统一:mm、GHz、pF;周期Px/Py会影响耦合与响应。
问:为什么周期也当变量?答:周期影响等效边界与耦合,能显著改变幅相曲线。

页码:27页面标题:I字型数据集:频段与采样点解释:承接“结构参数化”,这页定“学什么范围”:论文对I字型在2–8 GHz做全波仿真,并设置601个频率采样点。频点越密,曲线细节(尤其相位跃迁区)越完整,但训练数据行数也越大(几何样本×601)。
只需要理解:频段决定模型能回答哪些频率的问题,频点数决定“曲线有多细”。下页我们讲DOE:25组训练、16组测试,以及为什么“少样本也能跑通”(背后靠结构化先验与窄范围参数空间)。提示:频段要覆盖目标工作频点;“601点”提高曲线分辨率,但会增大训练耗时;频率单位与归一化要一致。问:频段能不能更宽?答:能,但成本更高且更难学;
问:频点一定要等间隔吗?答:不一定;可在谐振附近加密,但大部分论文采用固定点数方案。
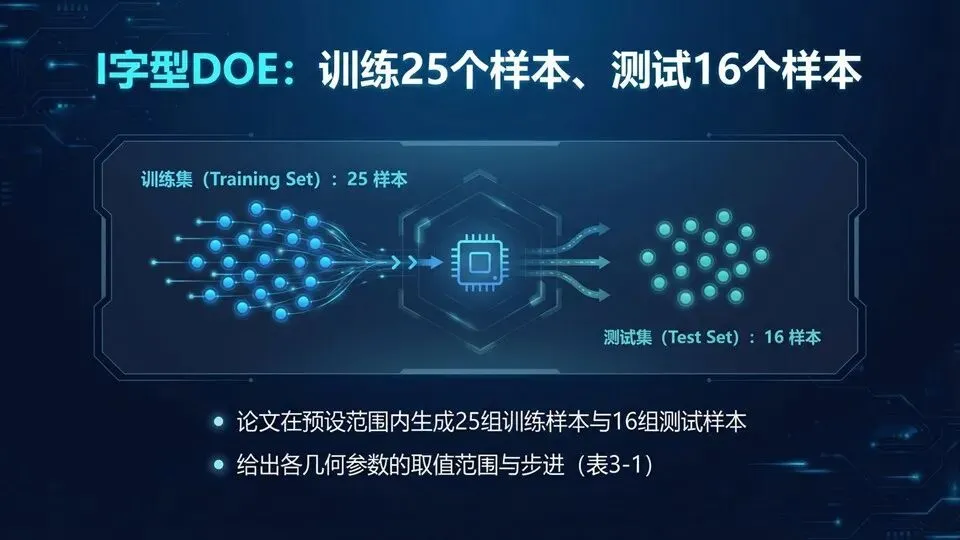
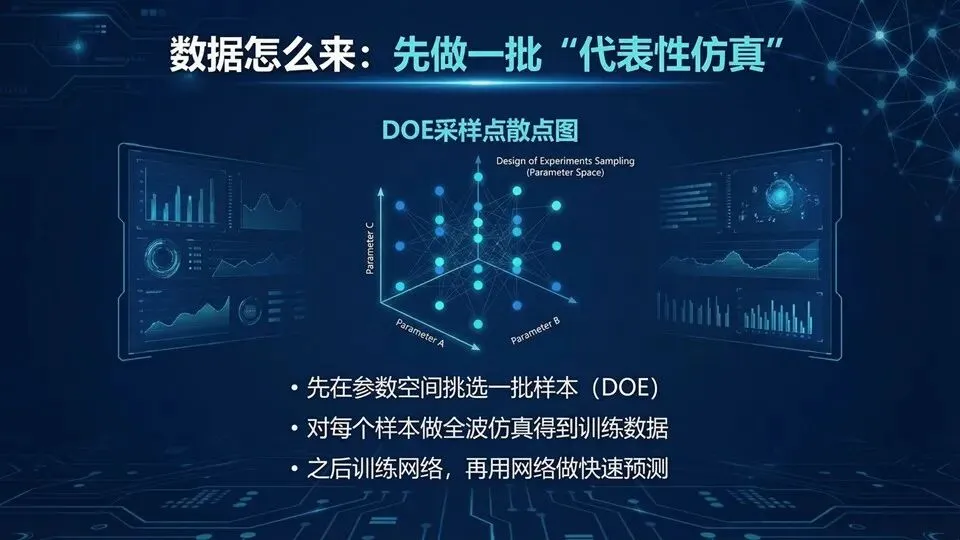
页码:28页面标题:I字型DOE:训练25个样本、测试16个样本解释:承接频率维度,这页看几何维度:给出I字型各变量的取值范围与步进,并据此生成25组训练样本、16组测试样本。DOE的目标不是“扫全组合”,而是“用少量代表点覆盖参数空间”,像在大地图上选代表城市学习地形。复现时要注意:
提示:DOE要覆盖边界与典型区
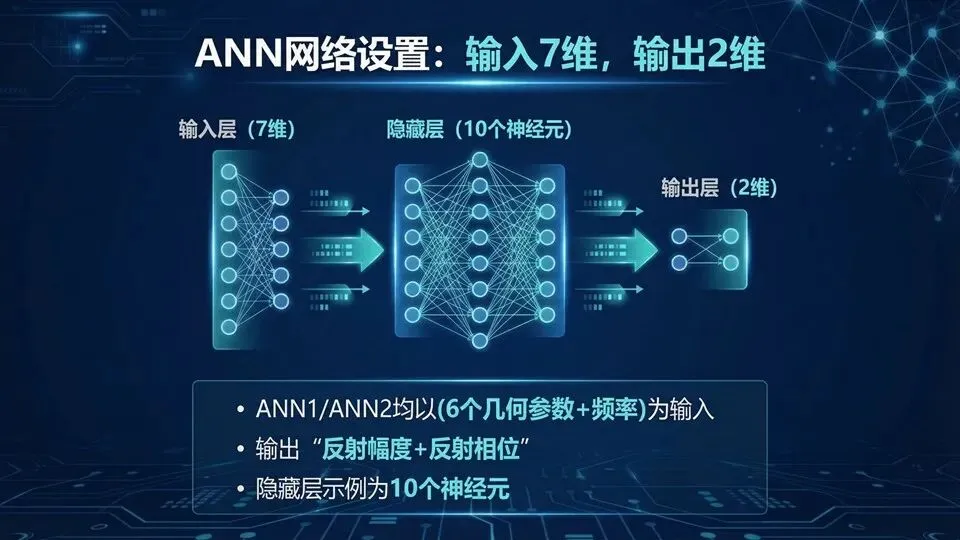
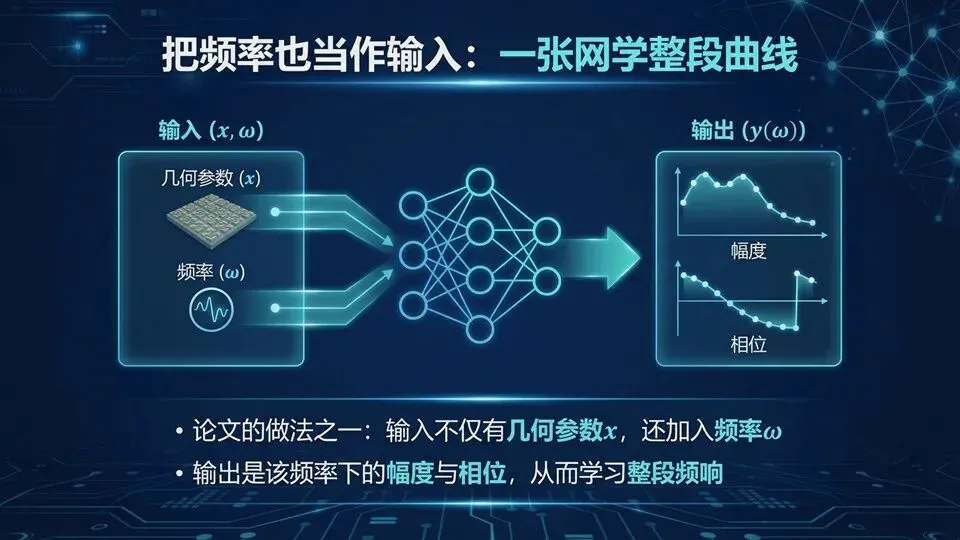
页码:29页面标题:ANN网络设置:输入7维,输出2维解释:承接DOE“数据长什么样”,网络接口必须对齐:输入是6个几何参数+频率ω,共7维;输出是线性幅度|S11|与相位φ(°),共2维。论文I字型案例给出隐藏层10个神经元,ANN1/ANN2结构一致,分别学习Cmin与Cmax端点状态。复现时你会遇到一个细节:相位有跳变,数值尺度也与幅度不同,因此通常需要相位展开与归一化;
下页我们看训练效果:误差在几个百分点意味着“能不能用于优化”。提示:这是回归任务(预测连续值);说明:ANN1=端点1,ANN2=端点2;复现要记录:归一化方式与相位处理方式。问:相位跳变怎么处理?答:常用unwrap后再归一化;若不处理,网络可能学不稳。
问:10个神经元够吗?答:在该案例范围内够用;可通过测试误差判断是否需增大容量。进阶延伸:工程替代:输出相位可用(sinφ, cosφ)编码避免跳变。
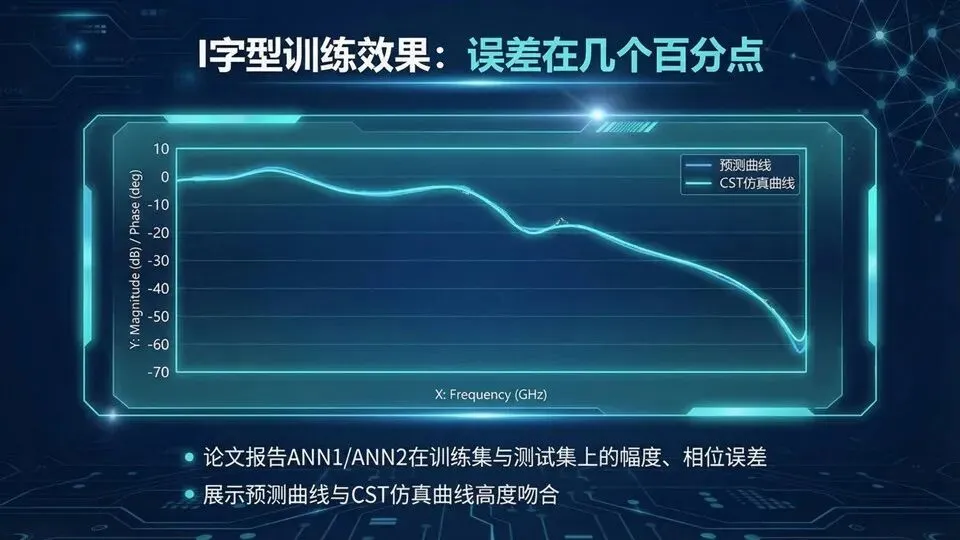
页码:30页面标题:I字型训练效果:误差在几个百分点解释:承接网络结构,这页回答“准不准”。展示了ANN1/ANN2的训练与测试误差,并给出预测曲线与CST全波仿真曲线的叠加对比。对初学者,最重要的结论不是某个小数点,而是:误差达到几个百分点时,代理模型就能在优化阶段大幅减少全波调用,
把“候选筛选”做得很快;但最终解必须回CST验证。
下页我们把工程需求写成可优化的数学目标:U1管损耗,U2管相位差,用权重α折中。提示:看“曲线重合”而不仅看误差数字;代理模型作用:快速筛选与迭代
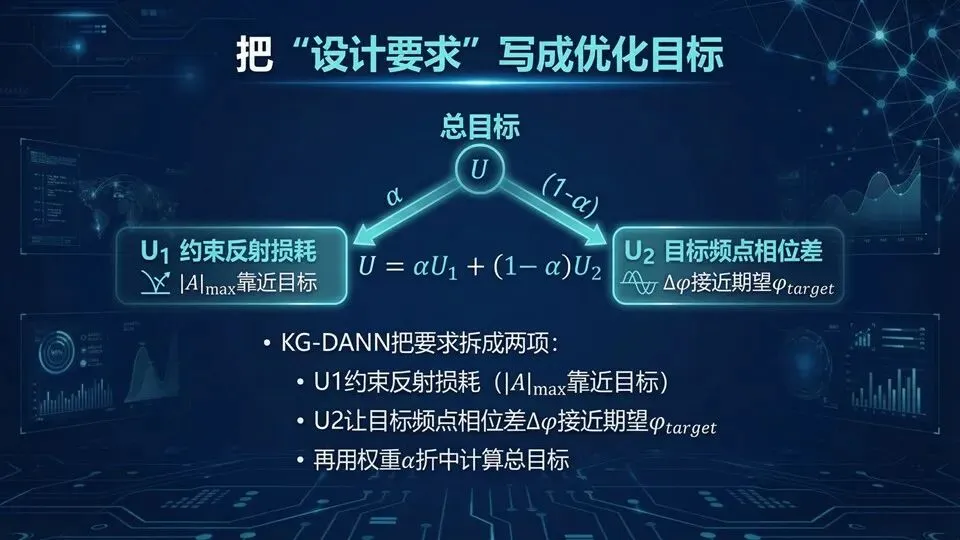
页码:31页面标题:把“设计要求”写成优化目标解释:承接“模型可用”,这页讲“怎么用”:论文把需求拆成两部分:U1约束最大幅度损耗(不让|S11|太差),U2让目标频点最大相位差Δφ接近期望φtarget,然后用权重α折中。你可以把α理解成“偏好旋钮”:α大更保幅度,α小更追相位覆盖。
这里建议你把指标写得尽量可计算:例如Δφ(x,ωT)=|φCmin−φCmax|,下页我们讲优化器:fmincon(SQP)或PSO如何在代理模型上快速收敛。提示:目标函数=把口头需求变成数字;理解“折中”不是拍脑袋,而是可调参数α;阈值若用dB,先换算或明确方向。问:为什么用加权和而不是帕累托前沿?答:加权实现简单、易操作;帕累托更全面但代价更高。
问:α怎么选?答:工程上可做α扫描,在满足约束的解中选最优。
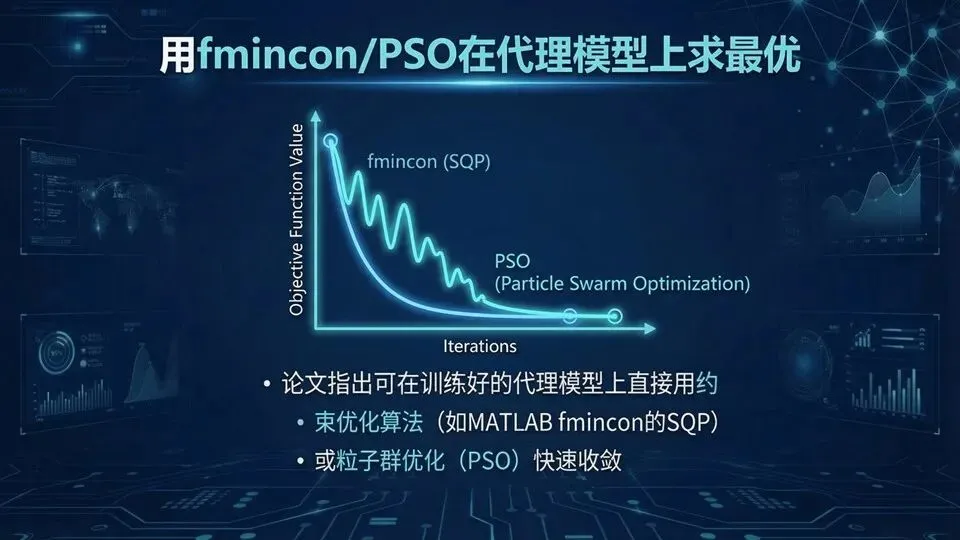
页码:32页面标题:用fmincon/PSO在代理模型上求最优解释文案:承接目标函数,这页解决“谁来找最优”。课程案例可用约束优化器(MATLAB的fmincon,算法选SQP)或粒子群PSO。关键区别在于:以前每次迭代都要调用全波仿真“打分”,现在代理模型秒级打分,优化器就能快速迭代。
下页我们用一个具体设计任务落地:4 GHz需要315°相位差,同时满足幅度约束。提示:强调“优化快”的根源:函数评估变便宜;SQP可以理解为“每步解一个近似二次小问题”;提醒复现:记录TolX/TolFun、初值与边界。
问:PSO和fmincon怎么选?答:PSO更全局但慢;fmincon更快但依赖初值与可导性。
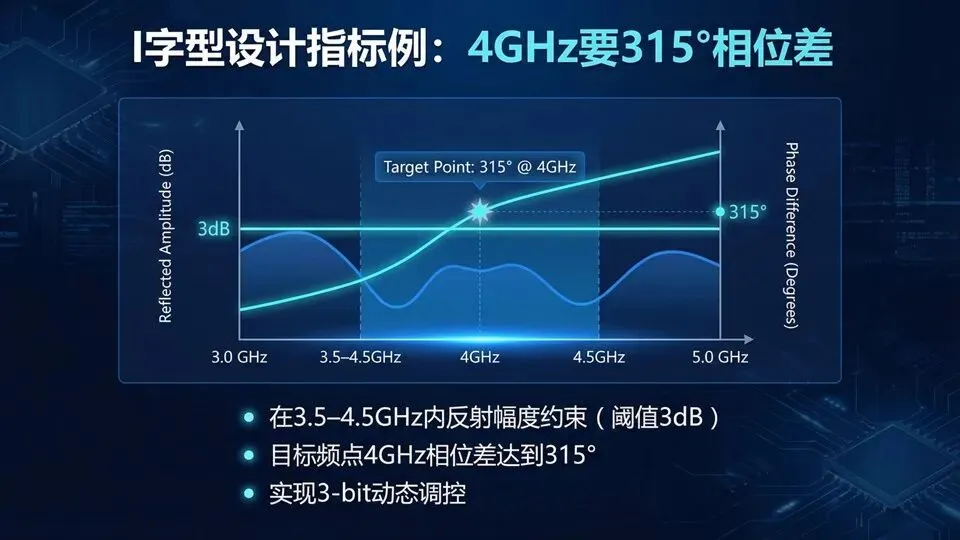
页码:33页面标题:I字型设计指标例:4GHz要315°相位差解释:承接“选好优化器”,这页给出明确任务:目标频点4 GHz要求最大相位差接近315°,并在3.5–4.5 GHz内满足反射幅度约束。课堂统一口径:若论文用“3 dB阈值”表达,请先理解为−3 dB门限,对应线性|S11|≈0.707(方向以论文具体约束为准)。315°可以记成360°−45°,正好是3‑bit八态的最高档(7×45°),表示相位覆盖几乎“绕一圈”。下页我们看优化结果:代理模型上几十秒收敛,并回CST验证曲线与带宽。提示:幅度约束要明确是“反射不能太小”还是“损耗不能太大”常见学生问题与简短回答:
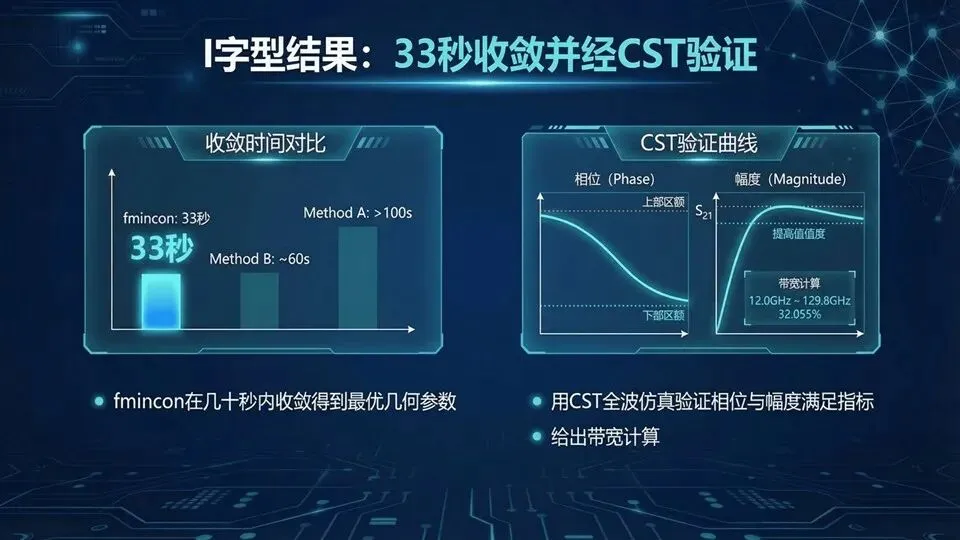
页码:34页面标题:I字型结果:33秒收敛并经CST验证解释文案:承接上一页的任务,这页强调“工程闭环”:fmincon在代理模型上快速收敛只是第一步,更关键是把最优几何参数回到CST做全波验证,检查目标频点Δφ是否达标、带内幅度约束是否满足,并按给定的带宽定义计算可用频段。提示:明确三个输出:最优x*、CST验证曲线、带宽数值,“验证失败”不罕见,需要回补数据或调整约束

页码:35文案:承接“快到底值不值”,这页用本项目时间对比回答:同类任务中,KG‑DANN总耗时约小时级,而Matlab脚本直接驱动CST做全波优化可到十几小时量级。直觉分解:直接优化每步都要全波打分;KG‑DANN把打分换成代理模型,昂贵仿真主要集中在“前期数据生成”和“最后一次验证”。所以只要你不是只做一次设计,而是要反复做不同指标或不同场景,代理模型的收益会越来越大。下页我们换到更复杂的H字型单元,看方法是否仍有效。提示:总耗时拆成:数据生成+训练+优化+验证;强调“量级差”是工程价值
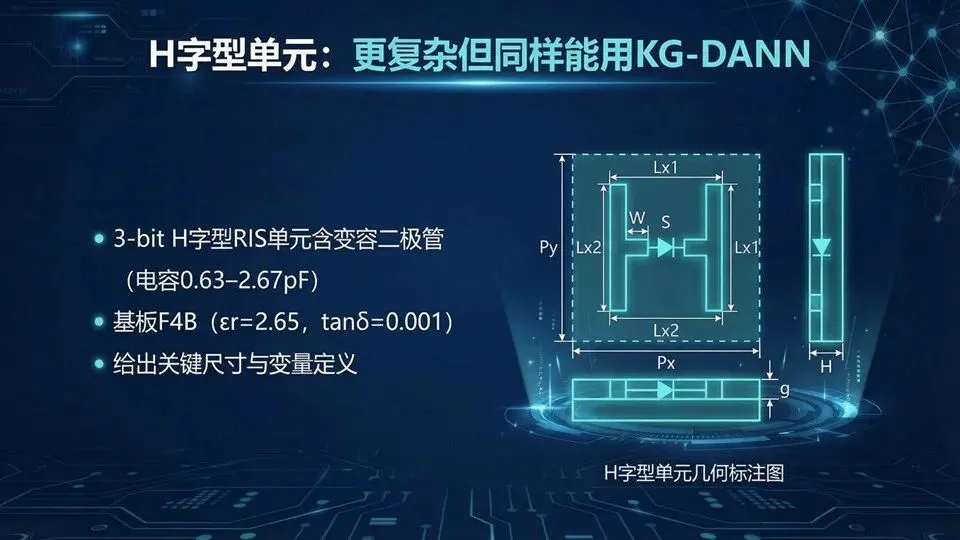
页码:36页面标题:H字型单元:更复杂但同样能用KG‑DANN解释文案:承接I字型成功案例,这页换成更复杂的H字型RIS单元。课题项目给出该单元含变容二极管(电容0.63–2.67 pF),基板为低损耗F4B(εr=2.65,tanδ=0.001),并定义新的几何变量组。复杂的意义是:响应更非线性、优化更难、全波更贵,因此更需要结构化代理。KG‑DANN在这里仍保持同一框架:只训练Cmin/Cmax两端点,知识层算Δφ与损耗指标。下页我们讲H字型的DOE与频段设置,强调“流程不变,只是参数换了”。提示:说明复杂度提升会放大“全波成本”,器件等效R/L/C会影响损耗与相位;方法可迁移:端点网络+知识层不变。
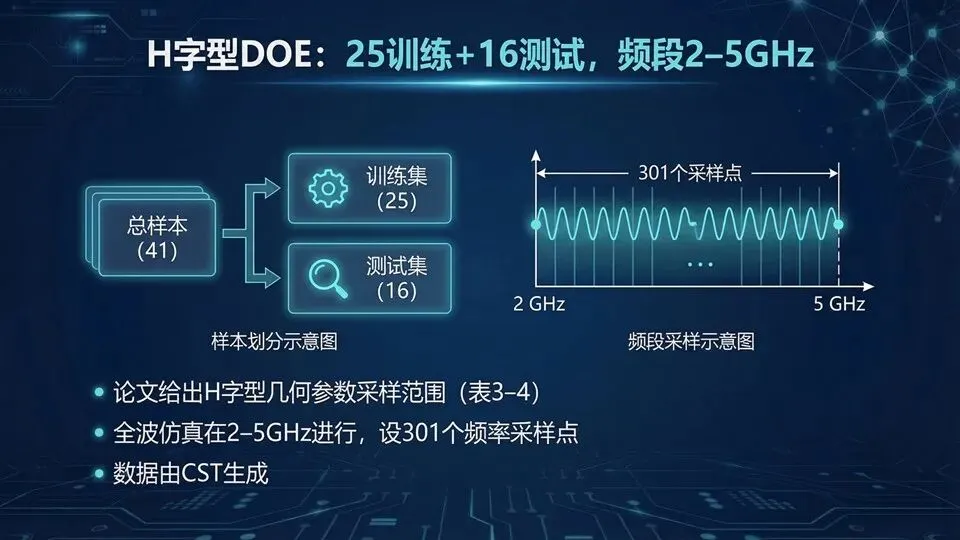
页码:37页面标题:H字型DOE:25训练+16测试,频段2–5GHz文案:承接H字型结构,这页明确“学的范围与数据规模”:论文给出H字型参数采样范围,训练25、测试16;仿真频段2–5 GHz并设置频率采样点。把它与I字型对照:频段变了,变量范围变了,但数据管线不变——DOE采样→全波仿真→端点网络训练→测试误差评估。提示:对比I字型:频段与变量不同,但方法相同;训练/测试划分是为了验泛化。样本组合细表若缺失会影响完全一致复现。
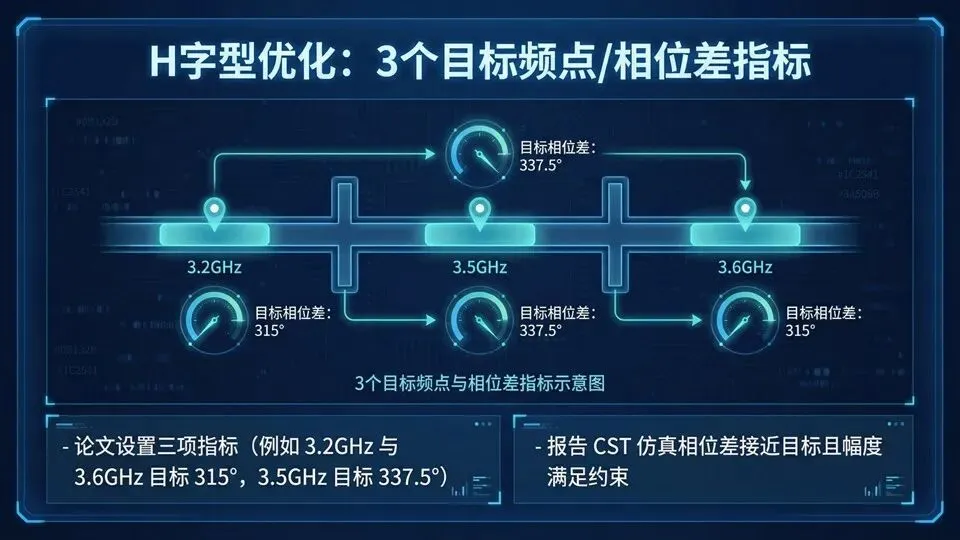
页码:38页面标题:H字型优化:3个目标频点/相位差指标解释文案:承接“数据建好”,这页展示工程任务更真实的一面:同一个单元可能要在多个频点满足不同相位差要求。给出三项目标(如3.2 GHz、3.6 GHz目标315°,3.5 GHz目标337.5°),依旧用同一代理模型框架求解,然后用CST验证各频点的相位差是否接近目标、带内幅度是否满足约束。代理模型一旦训练好,换指标就是换“考试题”,不必重训(只要仍在参数范围内)。下页强调这种复用带来的效率。提示:解释337.5°=360°−22.5°,与更细bit量化有关;多频点指标=更真实工程需求;每个指标都要回CST核对。
问:多个指标冲突怎么办?答:通过权重、约束或分阶段求解折中;

页码:39页面标题:H字型效率:模型建好后“秒级换指标”解释文案:承接多目标,这页重点是“复用价值”:代理模型开发(数据生成+训练)是一次性成本;开发完成后,针对不同目标频点、不同相位差需求,只需在代理模型上重新跑优化,单次求解可达秒级。论文用时间对比强调:与直接Matlab‑CST全波优化相比,总耗时显著降低。课堂上你可以把它理解为:先建“工具厂”,后面每个新任务都像换一张订单,不用重新造机器。提示:把耗时拆成“开发时间”与“每次求解时间”;强调复用前提:参数范围、结构与材料不变。
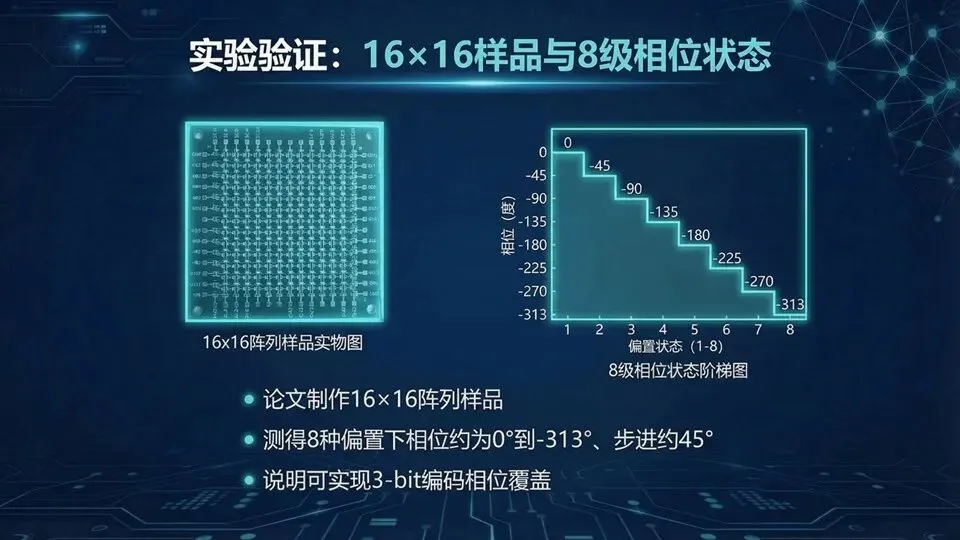
页码:40页面标题:实验验证:16×16样品与8级相位状态解释文案:承接“仿真与优化”,这页用实验把可信度拉满:论文制作16×16阵列样品,测得8种偏置状态下相位约从0°到−313°、步进约45°,对应3‑bit八态的离散相位覆盖。
对初学者,实验的意义在于:它证明“离散档位”不是纸上谈兵,确实能由偏置电压与电容状态映射得到。你不必纠结相位是正还是负,因为零点取决于参考;关键是“相对步进”和“覆盖范围”。下页从单元走向阵列理论:如何用相位补偿公式让主瓣指向目标方向。问:为什么不是刚好−315°?答:器件非理想与损耗会带来偏差;工程上看是否满足容差。
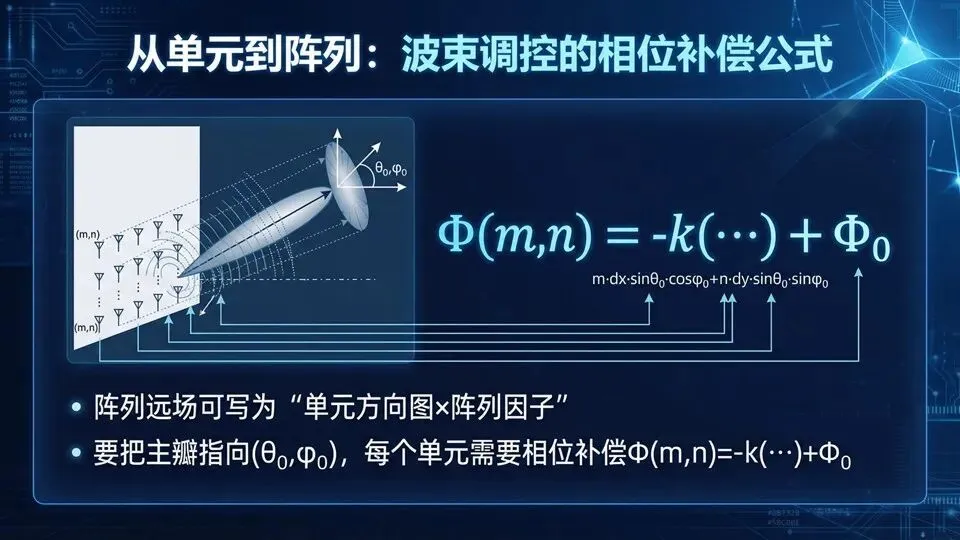
页码:41页面标题:从单元到阵列:波束调控的相位补偿公式解释文案:承接实验“单元有八态相位”,阵列要做的是把这些相位排成一个“让目标方向同相叠加”的图案。论文将远场写为“单元方向图×阵列因子”,并给出相位补偿Φ(m,n)的公式:本质是用波矢k与单元位置坐标计算传播相位,再加上补偿让目标方向相位对齐。
让所有单元在目标方向“齐步走”。下页我们用3‑bit编码序列示例直观看到:相位梯度越大,偏转角越大。提示:m,n是阵列索引,θ0,φ0决定补偿量;离散编码需要把连续相位量化到8态。

页码:42页面标题:3‑bit编码序列:相位梯度越大,偏转角越大解释文案:承接相位补偿公式,这页把连续补偿落到离散编码上:课题项目给出三组3‑bit编码序列,并对应理论主瓣方向约15°、30°、45°,再与CST远场仿真对比验证。直觉很好记:序列变化越“陡”,相位梯度越大,波束偏转越大。类比滑坡:坡越陡,球滚偏得越厉害。复现时要注意:序列数字本身不是相位,而是“状态编号”,需通过表3‑9映射到电容/相位档位。下页给出阵列仿真设置要点,避免你“设错边界导致方向图乱跳”。提示:编码→电容→相位的映射必须一致;理论角度与仿真角度不必完全相等,但应接近。
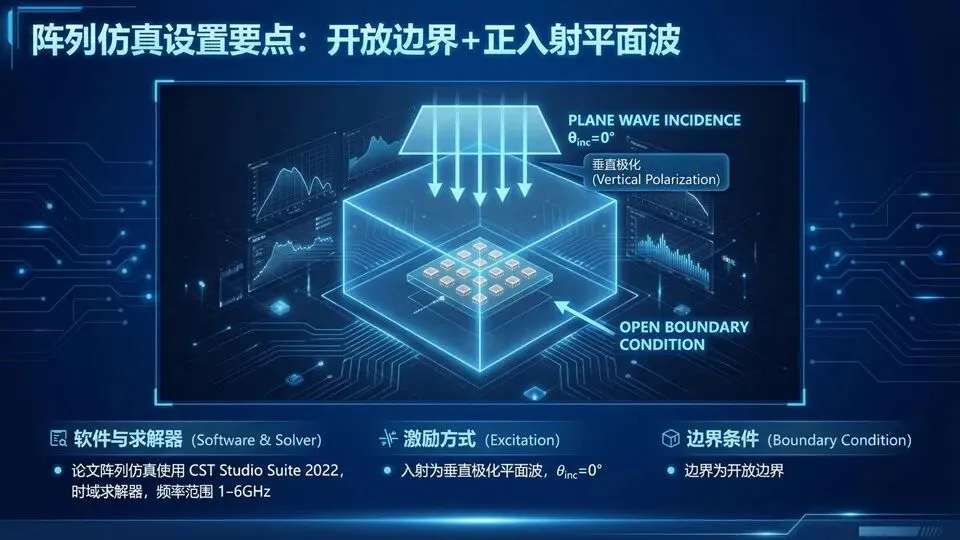
页码:43页面标题:阵列仿真设置要点:开放边界+正入射平面波解释文案:承接“要复现远场”,这页给出必抄设置:论文阵列仿真使用CST Studio Suite 2022,时域求解器,频率范围1–6 GHz;入射为垂直极化平面波、θinc=0°;边界为开放边界,用于模拟自由空间、避免边界反射污染远场。对初学者,这些设置比公式更关键:因为你只要设错边界或极化,就会得到完全不同的方向图,误以为方法不对。下页我们转入方法二:统计建模与成品率估计,解释为何量产阶段更需要“快”。提示:求解器/频段/边界(先对齐再谈结果);说明“开放边界”是为了让远场更接近真实自由空间。问:开放边界是不是PML?答:常通过PML实现开放效果,具体随软件选项而定。
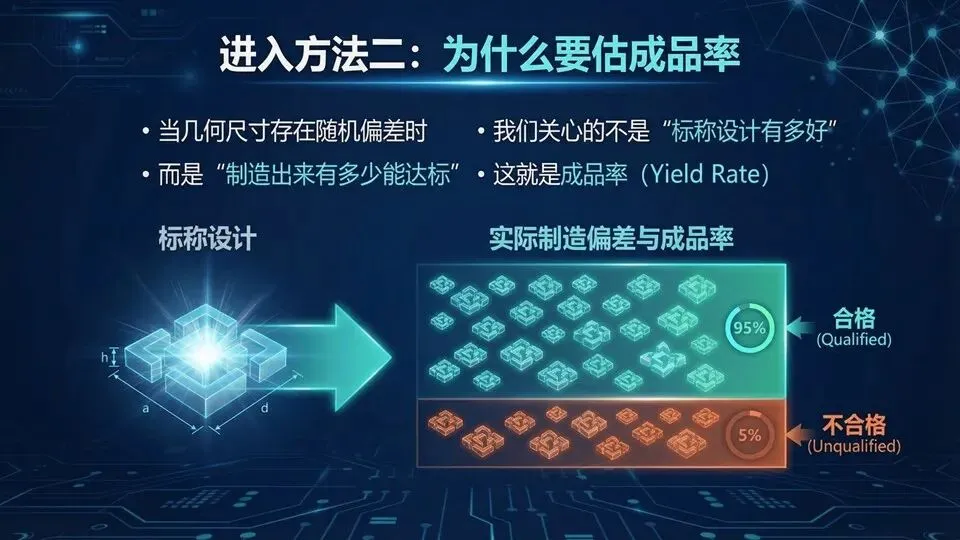
页码:44页面标题:进入方法二:为什么要估成品率解释文案:承接前面“设计能做出来”,现在进入“做出来是否稳定”:当几何尺寸存在随机偏差时,我们关心的不是标称响应有多好,而是“制造出来有多少能达标”,这就是成品率。它像考试的及格率:平均分高不等于都及格。传统成品率估计往往用蒙特卡洛+全波仿真,对每个随机样本做一次全波,成本极高;因此需要快速统计建模方法在保证精度的前提下降低全波次数。下页正式介绍Neuro‑TF:用传递函数把频响“压缩成少量参数”,再用神经网络预测这些参数。提示:统计问题的难点:需要大量样本;Neuro‑TF的关键是“物理可解释中间表示”问:成品率阈值怎么定?答:由系统指标/工程规范决定;。
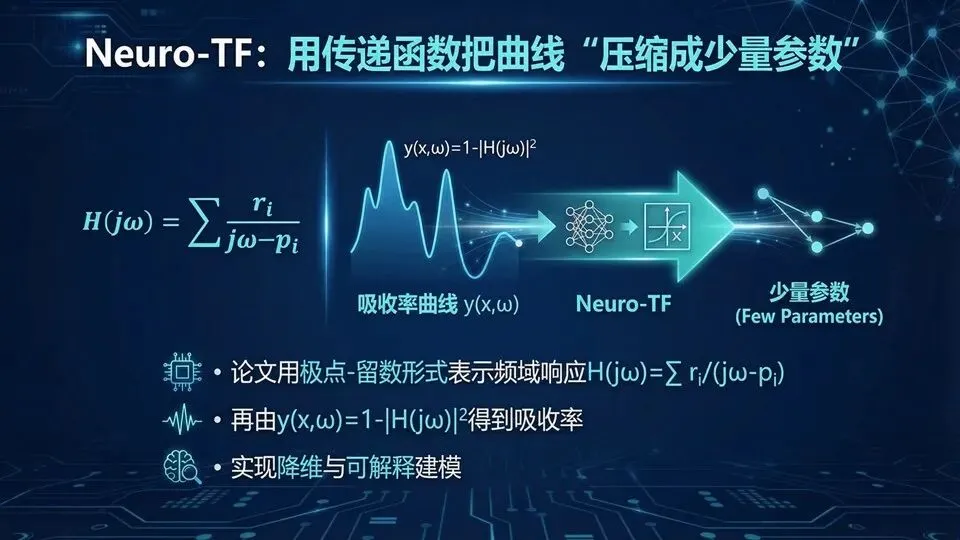
页码:45页面标题:Neuro‑TF:用传递函数把曲线“压缩成少量参数”解释文案:承接成品率需求,Neuro‑TF的核心是“先换表达,再做学习”。论文用极点‑留数形式表示频域响应:H(jω)=Σri/(jω−pi),再由 y(x,ω)=1−|H(jω)|² 得到吸收率。直观理解:一条复杂的吸收曲线,往往由少数共振模态主导;极点像“共振位置”,留数像“强度与形状”,把曲线压缩成可解释参数后,再让神经网络学“几何→参数”。这比纯黑盒直接学曲线更稳健。下页我们讲关键步骤:怎样从仿真S11曲线反推出极点/留数——矢量拟合(Vector Fitting)。提示:极点/留数提供可解释性与约束;最终输出是吸收率,不是相位。

页码:46页面标题:矢量拟合:从S11曲线提取极点与留数解释文案:承接“需要极点/留数”,矢量拟合的直觉是:不再用“任何曲线都能拟合”的黑盒,而是用有物理意义的有理函数去逼近频域响应。论文指出直接最小二乘在高维/多峰情况下会数值不稳定,因此采用Vector Fitting:先给一组初始极点,再通过迭代更新极点,让拟合误差逐步下降,最终得到极点pi与留数ri。下页我们进入两阶段训练:先学极点/留数,再端到端微调。提示:用“先猜形状→再迭代修正”解释VF;复现风险:初始极点策略与实现库选择。问:初始极点怎么选?答:工程上常用对数均匀分布或成对复数极点初始化,并强制稳定性。
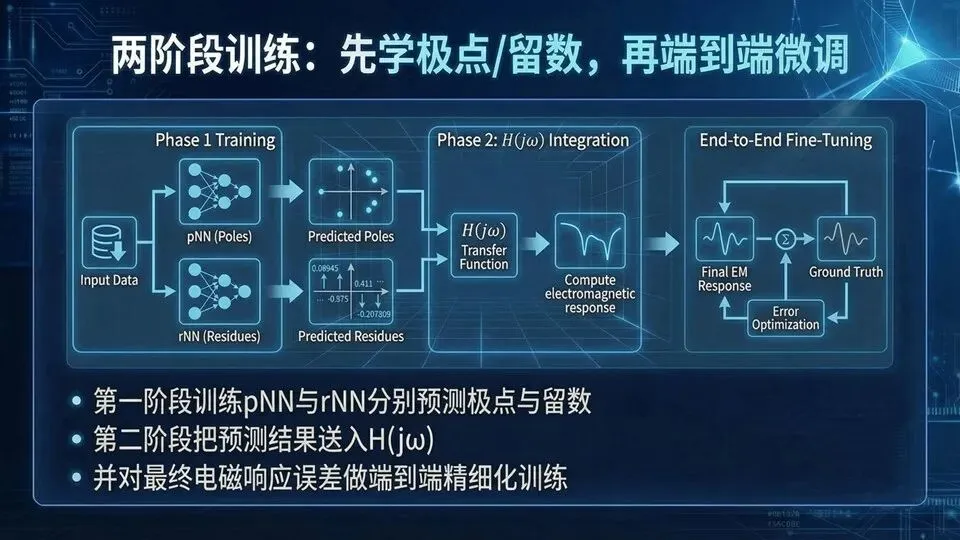 页码:47页面标题:两阶段训练:先学极点/留数,再端到端微调解释文案:承接矢量拟合“拿到监督标签(pi,ri)”,这页解释为何分两阶段:第一阶段训练pNN与rNN分别预测极点与留数,让网络先学一个稳定、可解释的中间表示;第二阶段把预测的(pi,ri)送入传递函数H(jω),再由y=1−|H|²得到吸收率,与全波真值做端到端误差最小化微调,修正第一阶段误差对最终曲线的放大。类比“先学拼音再写作文”:先把字母学准,再把文章整体写顺。下页进入实例:吸波单元9个变量、目标频段阈值如何设定。提示:两阶段目的:训练稳定 + 对齐最终任务;端到端微调能显著改善谐振细节拟合。
页码:47页面标题:两阶段训练:先学极点/留数,再端到端微调解释文案:承接矢量拟合“拿到监督标签(pi,ri)”,这页解释为何分两阶段:第一阶段训练pNN与rNN分别预测极点与留数,让网络先学一个稳定、可解释的中间表示;第二阶段把预测的(pi,ri)送入传递函数H(jω),再由y=1−|H|²得到吸收率,与全波真值做端到端误差最小化微调,修正第一阶段误差对最终曲线的放大。类比“先学拼音再写作文”:先把字母学准,再把文章整体写顺。下页进入实例:吸波单元9个变量、目标频段阈值如何设定。提示:两阶段目的:训练稳定 + 对齐最终任务;端到端微调能显著改善谐振细节拟合。
问:为什么不直接端到端?答:两阶段提供更好的初始化与可解释性。
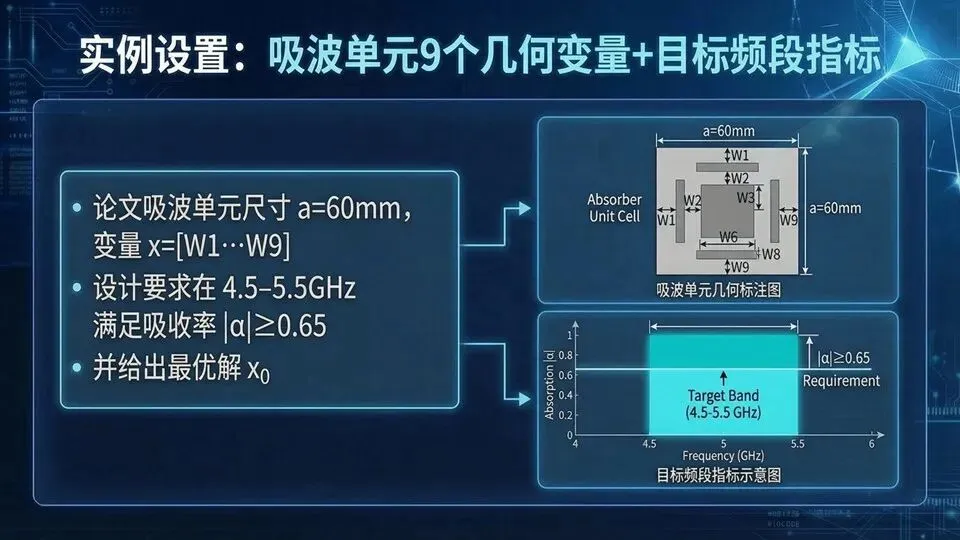 页码:48页面标题:实例设置:吸波单元9个几何变量+目标频段指标解释文案:承接训练策略,这页把任务说得“可判定”:吸波单元尺寸a=60 mm,设计变量x=[W1…W9];指标是在4.5–5.5 GHz内吸收率≥0.65。论文还为成品率估计设定制造偏差:每个参数独立正态分布,标准偏差20 μm,并在x0±20 μm范围内DOE生成81个训练样本。可以把0.65看成“及格线”,后面成品率就是统计有多少样本在目标频段都能过线。下页我们看对比结果:传统MC、Neuro‑TF、Pure‑NN在成品率与耗时上的权衡。提示:“0.65阈值=合格线”;误差分布假设会影响成品率结论。
页码:48页面标题:实例设置:吸波单元9个几何变量+目标频段指标解释文案:承接训练策略,这页把任务说得“可判定”:吸波单元尺寸a=60 mm,设计变量x=[W1…W9];指标是在4.5–5.5 GHz内吸收率≥0.65。论文还为成品率估计设定制造偏差:每个参数独立正态分布,标准偏差20 μm,并在x0±20 μm范围内DOE生成81个训练样本。可以把0.65看成“及格线”,后面成品率就是统计有多少样本在目标频段都能过线。下页我们看对比结果:传统MC、Neuro‑TF、Pure‑NN在成品率与耗时上的权衡。提示:“0.65阈值=合格线”;误差分布假设会影响成品率结论。
问:为什么用|α|写法?答:论文如此表述;工程上吸收率通常为0–1实数,这里按论文阈值判定。

页码:49页面标题:性能对比:MC(71%) vs Neuro‑TF(77%) vs Pure‑NN(55%)解释文案:在500个随机样本上比较:传统全波蒙特卡洛MC成品率约71%,但耗时约58.33 h;Neuro‑TF成品率约77%,同时把全波仿真次数从500降到81、总耗时降到约12.11 h;Pure‑NN虽也减少仿真,但成品率约55%,偏差明显。课堂结论很清晰:Neuro‑TF用物理结构化表示换来了更可靠的统计预测,同时大幅减少全波调用。提示:对比:成品率、全波次数、总耗时;Pure‑NN的典型问题:漏谐振峰→判定失真。

页码:50页面标题:自测题:你真的理解了吗解释文案:承接上一页的对比结果,这页用三问把全课收束成“能复述、能迁移”的能力:
①KG‑DANN为何只训练Cmin/Cmax?——因为多状态太贵,用两端点+知识层先快速得到关键指标Δφ与损耗,再把有限候选回全波验收;②Neuro‑TF为何用极点‑留数?——因为它把曲线变成“可解释的模态参数”,统计预测更稳;
③复现KG‑DANN至少需哪些软件?——CST生成数据、MATLAB训练与优化(fmincon/SQP),并保留全波验证环节。
