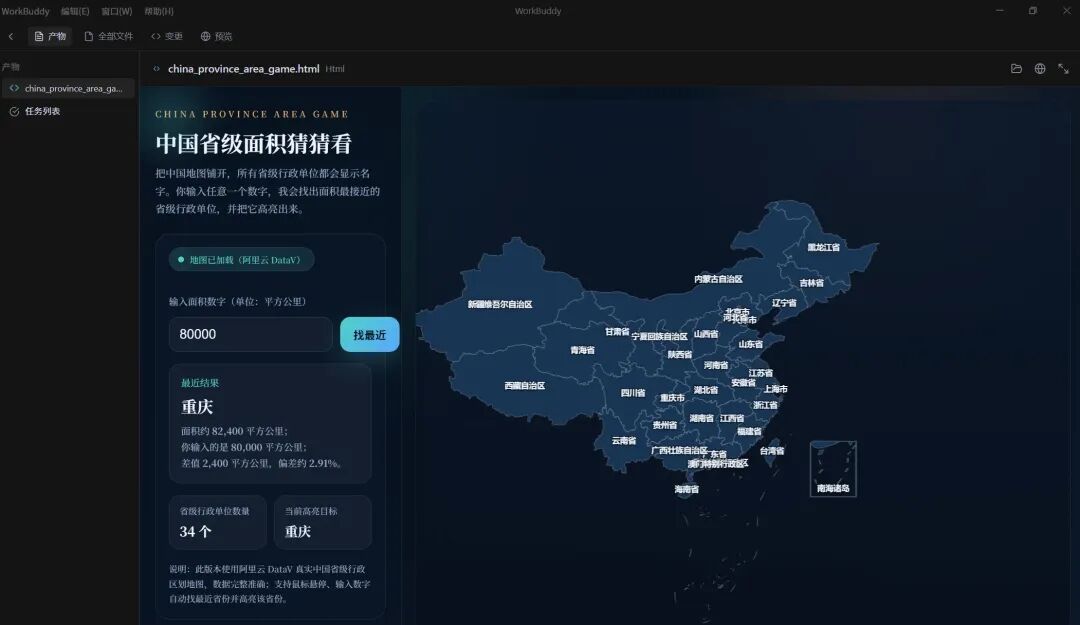
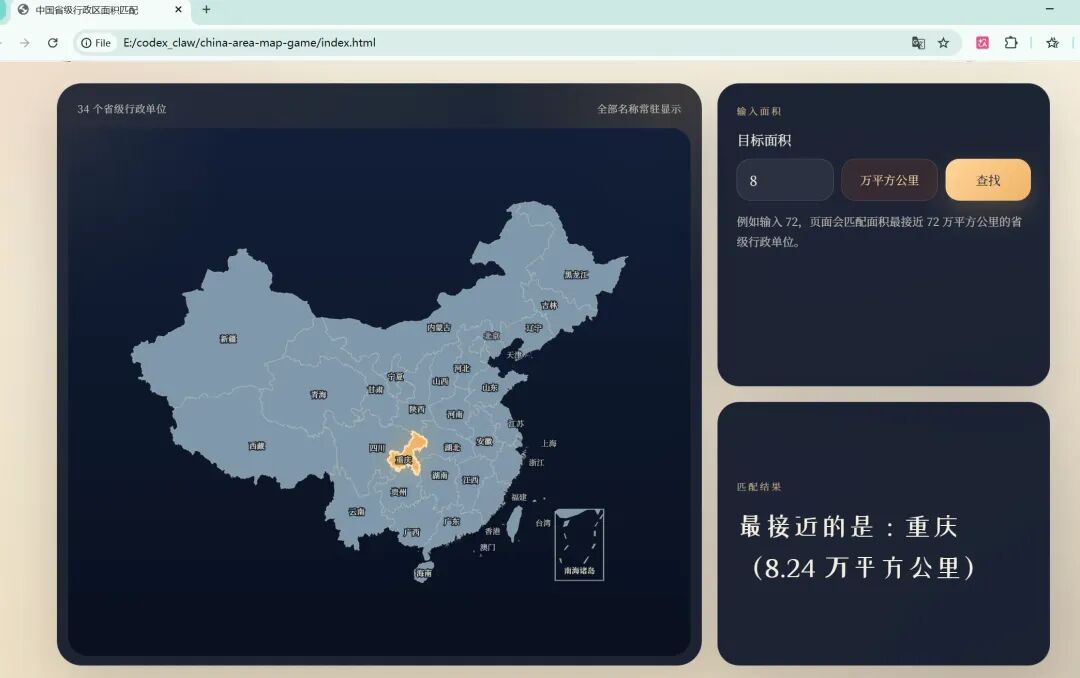
昨天,顺我朋友的活儿,我做了一个很小的实验。题目其实不复杂,就是做一个网页版中国地图互动小游戏:地图上把 34 个省级行政单位都显示出来,名称都标上去,下面给一个输入框,用户输入任意一个数字后,程序找出面积最接近的那个省级行政单位,并把对应区域高亮。这样的题目,说难不算太难,说简单也不算特别简单。因为它不是一句话问答,也不是生成一段文案,而是一个可以立刻验证结果的东西。你点一下按钮,地图亮不亮,省份对不对,页面会不会直接出错,这些都藏不住。所以我觉得,这种任务反而很适合拿来测试 AI 的真实交付能力。我把这个任务同时交给了两套 AI 去做。一套是 WorkBuddy,调用某国内模型;另一套是 Codex,调用 GPT-5.4。做这个测试,我倒不是为了给谁贴标签,更不是想搞什么简单粗暴的“谁吊打谁”。我只是想看一件事情:在同样一个小而具体、结果又很容易验证的任务里,两套 AI 的差别,最后到底会落在什么地方。结果很有意思。最后看下来,真正拉开差距的,并不是谁更会写代码表面文章,也不是谁更会讲自己做了什么,而是谁真正把事情做完了。WorkBuddy 做出来的东西,第一眼看上去并不差,甚至在某些阶段,你会觉得它已经很接近一个成品了;但用户一实际点击,问题马上暴露出来,要么地图直接没了,要么对应省份根本没有高亮。Codex 这一边则不一样,它前面花了不少力气做需求收束和方案确认,真正开始写的时候反倒没那么热闹,但最后交出来的东西是闭环的,能够实际运行,能够验证,也能够复现。我后来又把两边的交互记录、过程文档和最终截图重新看了一遍,越看越觉得,这个小实验背后其实不是一个“谁更会写代码”的问题,而是一个更本质的问题:AI 时代,真正稀缺的到底是什么。
如果只把这次测试看成“GPT-5.4 比某国内模型强”,那这个结论太浅了。因为即便这个判断在这次任务上大概率成立,它也没有解释清楚,究竟强在什么地方。我自己更倾向于把这件事理解为:两边真正的差别,不只是代码生成能力的差别,而是任务闭环能力的差别。什么叫闭环?说得简单一点,就是从用户一句模糊的需求开始,最后走到一个可以交付、可以验证、可以复现的结果,中间不能断。你要能收需求,能拆任务,能选方案,能实现,能排错,最后还得能验收。少一步都不行。很多 AI 现在已经很会“局部表现优秀”了。你让它分析一段代码,它能分析得头头是道;你让它写一个界面,它也能很快给你一个看起来不错的版本;你让它解释 bug,它甚至能说出一整套很像资深工程师的话。问题在于,这些“局部能力”并不天然等于“能把事情做完”。这也是为什么我越来越觉得,AI时代真正重要的能力,也许不是“会不会写提示词”这么简单,而是你有没有一种把事情做成闭环的习惯。你能不能把问题定义清楚,能不能把边界说清楚,能不能分辨“看起来合理”和“实际上可用”的区别,能不能要求它在结束前自己先验证一遍。这些东西,过去像是管理能力、产品能力、项目能力,现在慢慢也开始变成使用 AI 的基础能力。我前面看自己那几篇关于 AI 的笔记时,也有一个越来越强的感受:AI 并不是把“思考”这件事从我们这里拿走了,而是把很多过去隐性的能力显性化了。以前一个人做事,需求不清楚、过程不严谨、验证不到位,很多时候还能靠经验和临场反应补一补;但当你把任务交给 AI 以后,这些问题就会被迅速放大。你说不清,它就做偏;你不验,它就容易停在一个“自我感觉已经完成”的位置上。从这个角度看,这次不是 WorkBuddy 输给了 Codex,而是“会说”和“会做完”之间的差距,被一个很小的网页小游戏放大出来了。
 夜雨聆风
夜雨聆风