 夜雨聆风
夜雨聆风全球AI监管三国演义:美国放权、欧洲立法、中国统筹
同样是管 AI,美国更像在重置政策重心,欧盟是在推进成文法落地,中国则在把治理做成一套分层规则栈。
前言
如果你最近同时看美国、欧盟和中国的 AI 新闻,很容易产生一种错觉:
都在谈监管,但像在说三种完全不同的语言。
美国在讲竞争力、基础设施和国家安全。欧盟在讲风险分级、透明义务和行政罚则。中国在讲发展与安全并重、备案、标识和全流程治理。
问题不是“谁更严”,而是“谁在用什么工具管什么问题”。
这也是这篇文章最想讲清的一件事:
今天的全球 AI 监管,已经不是一套统一规则,而是三条正在分叉的治理路径。
如果你是普通用户,这会影响你未来看到的 AI 标识、申诉权利和内容可信度。如果你是开发者或企业,这会直接影响产品设计、出海路径和合规成本。
一、为什么 AI 一定会走到监管这一步?
AI 之所以必然走向监管,不是因为它“新”,而是因为它已经开始影响现实决策。
比如:
• 用在招聘、信贷、教育、医疗时,它会影响人的机会和权益
• 用在图片、视频、音频生成时,它会放大伪造、误导和侵权风险
• 用在人脸识别、行为分析、公共治理时,它会碰到隐私、监控和权力边界
• 用在基础设施、网络攻防、军事场景时,它又会变成安全问题
所以,AI 监管从来不只是“管一个工具”,而是在回答三个更大的问题:
1. 哪些风险必须提前拦住?
2. 哪些创新应该留出空间?
3. 谁来为 AI 造成的后果负责?
对这三个问题,美国、欧盟和中国,给出了非常不同的答案。
二、美国:不是“完全不管”,而是把重心改成竞争力优先
很多人会把美国这一路线概括成一句话:去监管。
这不算全错,但不够准确。
更准确的说法是:美国联邦层面的 AI 政策重心,正在从“风险治理优先”转向“竞争力优先”。
1. 先发生的,是联邦政策重置
2025 年 1 月 23 日,特朗普签署 EO 14179,撤销了拜登时期强调 AI 风险治理的 EO 14110。
这件事的象征意义很强,因为它传递出的信号很明确:
• 联邦政府不想让 AI 政策首先被“安全审查”定义
• 更强调美国在模型、芯片、算力和基础设施上的领先
• AI 被视为产业竞争工具,也被视为国家安全能力的一部分
所以,美国这条线与其说是“取消监管”,不如说是:
先把联邦政策从“先谈风险”切换成“先谈领先”。
2. 但美国的“放权”,不等于没有规则
美国并不是进入“AI 无人区”了,而是把治理更多交给了几类力量共同推进:
• 联邦行政命令和采购规则
• 行业自律与企业标准
• 既有法律体系下的执法
• 芯片出口管制、盟友协同和国家安全工具
也就是说,美国的监管没有消失,只是没有像欧盟那样优先长成一部统一的 AI 总法。
至于“联邦会不会压缩州级 AI 规则的空间”,更稳妥的理解是:这是一种正在强化的政策方向,而不是一句“州法已经被统一替代”就能说清的现实。
3. 这条路线的强项和风险都很明显
它的强项是速度。
如果政策目标首先是“赢得 AI 竞赛”,那对企业最直接的利好就是:
• 产品上线节奏更快
• 试错空间更大
• 资本、算力和基础设施更容易被组织起来
但它的风险也很明显:
• 州与州之间的规则碎片化仍可能存在
• 企业自律不一定能覆盖高风险场景
• 在招聘、信贷、内容分发等领域,歧视与滥用问题不会自动消失
• 多边治理参与度下降,会削弱美国对全球规则叙事的控制力
2025 年巴黎 AI 行动峰会上,美国和英国都没有签署那份联合声明,这更像是一种姿态:美国愿意主导 AI 竞争,但未必愿意把自己绑进一套多边约束里。
一个更稳的结论
如果只用一句话概括美国:
它不是“彻底不管 AI”,而是更倾向于用竞争政策、国家安全工具和产业政策来塑造 AI,而不是先用统一强监管框架把它锁住。
三、欧盟:真正把 AI 写进法律,而且开始分阶段落地
如果说美国代表的是“政策转向”,那欧盟代表的就是另一种东西:
把 AI 治理正式写进成文法。
欧盟 AI Act 之所以重要,不只是因为它严,而是因为它给出了一个非常清晰的治理思路:
不是所有 AI 都一样危险,所以规则应该按风险分层。
1. 欧盟的核心方法:风险越高,义务越重
简单理解,欧盟把 AI 大致分成几层:
• 禁止类:被认为不可接受的 AI 实践
• 高风险类:可以用,但必须满足严格合规要求
• 有限风险类:重点是透明义务
• 最低风险类:基本不设额外门槛
这套框架的影响非常大,因为它不是只盯着“模型是不是大”,而是更在意:
• AI 会不会影响人的基本权利
• AI 是不是进入了高敏感场景
• AI 有没有对社会产生系统性风险
比如,招聘筛选、教育评估、医疗、信贷、执法辅助这些场景,在欧盟视角里就天然比“AI 游戏推荐”更值得严管。
2. 欧盟 AI Act 是如何分阶段落地的?
如果只抓一个框架来看,可以先看时间线。

整体节奏可以概括成一句话:2024 生效,2025 两次落地,2026 主规则全面适用,2027 部分产品嵌入型高风险 AI 仍在更长过渡期内。
对企业和从业者来说,最值得记住的两个数字,是 2025-02-02 这个禁止类起算点,以及 3500 万欧元或 7% 这一档顶格罚则。
3. 罚则为什么让全球企业都紧张?
因为它真的不是软约束。
AI Act 最重一档罚则可以达到:
3500 万欧元,或上一财年全球营业额的 7%,取其高者。
这也是很多企业真正开始认真研究欧盟 AI 规则的原因。
不是因为它“态度强硬”,而是因为它已经把代价写进了制度里。
4. 禁止类并不等于所有相关技术都“一刀切禁用”
比如“公共场所实时远程生物特征识别”这类场景,很多讨论会直接把它理解成“完全禁止”。
但更稳的理解是:
• 欧盟对这类技术采取了极高警惕
• 原则上限制非常严
• 同时仍存在特定执法场景下的例外安排
这类条文最忌讳一句话讲死,因为法律设计往往比新闻标题更复杂。
5. 为什么中国企业也必须关心欧盟?
因为欧盟这套法并不只管“欧盟公司”。
如果你做的是下面这些事,就很难绕开它:
• 向欧盟用户提供 AI 服务
• 在欧盟市场卖带 AI 能力的产品
• 把 AI 用于招聘、信贷、医疗、教育等高敏感场景
• 基于通用大模型向欧盟市场提供能力或应用
这就是所谓的域外影响力。
所以,欧盟这条路本质上是在做一件事:
试图把自己的风险治理标准,变成全球市场进入门槛。
四、中国:不是只讲“备案”,而是在搭一整套分层治理规则
很多人一提中国 AI 监管,第一反应就是“双轨备案”。
这当然抓重点,但不完整。
更准确的理解是:
中国的 AI 治理,更像一套逐层叠加的规则栈,备案只是其中一层。
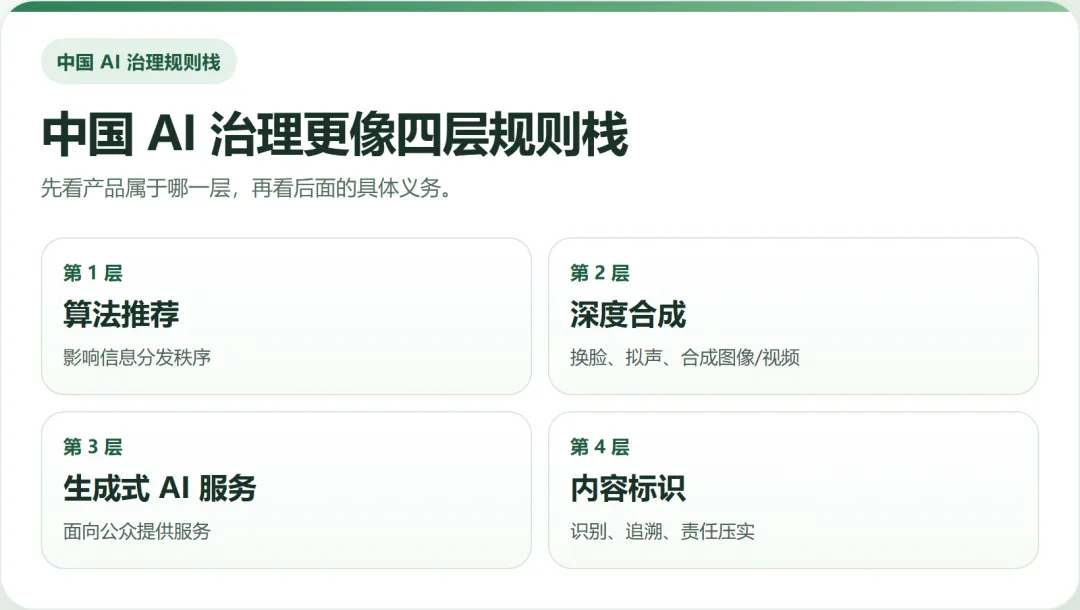
先把层次看清,再往下拆。
1. 把这套规则栈拆开来看
第一层,算法推荐治理。 针对的是具有舆论属性、社会动员能力,或者可能显著影响信息分发秩序的推荐算法。
第二层,深度合成治理。 针对的是换脸、拟声、合成图像、合成视频、虚拟场景等深度合成能力。
第三层,生成式 AI 服务治理。 重点落在面向公众提供服务的生成式 AI 产品,涉及安全评估、备案、内容管理等要求。
第四层,生成合成内容标识。 这一步很重要,因为它说明中国的治理重点,已经从“能不能做”进一步走向“做了之后怎么识别、怎么追溯、怎么压实责任”。
2. 这意味着什么?
意味着中国这条路线,不是单纯地“批不批备案”,而是更强调:
• 上线前有门槛
• 上线后有责任
• 内容生成要能识别
• 出问题后要能追溯
这也是为什么很多人会觉得中国监管“更像全生命周期治理”。
因为它关心的不只是模型训练那一刻,而是:
• 数据从哪来
• 服务给谁用
• 内容怎么生成
• 风险怎么防
• 责任怎么落实
3. 但中国也不是“所有 AI 产品都走同一种备案流程”
这一点必须讲清楚。
并不是所有做 AI 的团队,都会落到同一套手续上。
真正要判断的是:
• 你的产品是不是面向公众提供服务
• 它是推荐算法、深度合成能力,还是生成式 AI 服务
• 是否涉及舆论属性、社会动员能力或高敏感行业
• 是否会影响用户重大权益
• 是否涉及内容标识、数据安全、个人信息保护等配套义务
所以,对企业来说,最危险的误区不是“没听说过备案”,而是:
误以为所有 AI 产品只要查一个表、走一套流程就够了。
4. 这条路线的优势和难点
它的优势是治理动作比较早,也更强调可追溯和责任压实。
但难点也很现实:
• 技术更新速度比规则细化速度更快
• 新能力经常先出现,再补配套解释
• 开源模型和私有部署会拉高监管边界判断难度
• 跨境数据、跨境服务和跨境部署,会让实际合规更复杂
所以,中国这条线的关键词不是“简单管住”,而是:
发展与安全并重,且越来越强调精细化治理。
五、三种路径,真正不同的到底是什么?
如果把三方都压成“谁严谁松”,其实会看错重点。
更关键的差异在这里:
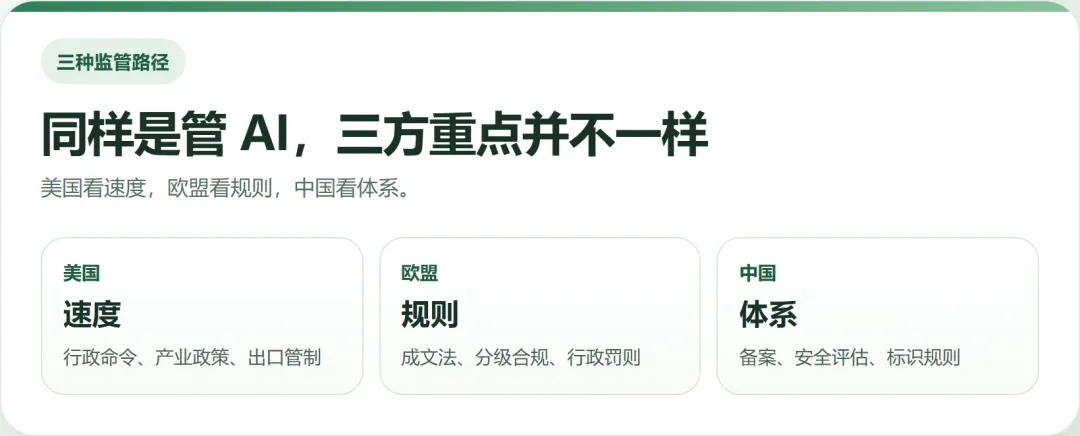
放到企业视角里,美国更像先看政策风向,欧盟更像先看市场门槛,中国更像先看产品属于哪一类。
但这三者都不是静止不动的模型,而是会继续演变的政策路径。
六、这对普通用户和企业,分别意味着什么?
如果你是普通用户
你未来大概率会越来越频繁地遇到三件事:
• 更多 AI 内容标识,而不是“看起来像真就算真”
• 影响重大权益的 AI 系统,会被要求承担更高透明度和审查责任
• 平台和服务提供者,会越来越难对“AI 生成内容的来源”完全不做说明
但也要注意:
这不等于所有国家、所有平台、所有场景都会同时给你一样的权利和保障。
现实世界里,规则落地速度、平台执行力度、司法解释口径,都会影响你真正能得到什么保护。
如果你是企业或开发者
比起问“哪个国家更严”,更应该先做一个四问自查:
1. 你的目标用户在哪个市场?
2. 你的产品是否面向公众?
3. 你的 AI 是否进入招聘、信贷、医疗、教育、执法等高敏感场景?
4. 你的服务到底更接近推荐、生成、深度合成,还是通用模型能力输出?
这四个问题,往往比一句“要不要备案”“算不算高风险”更能帮你少走弯路。
一个更实用的判断是:
• 做中国市场,要先想清产品类型和服务对象
• 做欧盟市场,要先判断风险分类和市场进入义务
• 做美国市场,要关注联邦政策风向、州法变化和行业合规实践
小结
这轮全球 AI 监管分化,表面上看是“谁更严谁更松”,本质上其实是三套不同的治理哲学在同时展开:
• 美国优先考虑的是竞争力与领先地位
• 欧盟优先考虑的是风险分级和制度约束
• 中国优先考虑的是发展、安全与责任链条
所以,今天真正值得记住的,不是“全球已经有一套统一 AI 规则”。 恰恰相反:
全球 AI 正在进入一个规则并行、标准分叉、合规前置的时代。
对普通用户来说,这决定了你未来会如何识别 AI、质疑 AI、信任 AI。 对企业来说,这决定了 AI 产品还能不能只靠“先做出来再说”。
思考与练习
如果你想把这篇文章真正用起来,可以试着回答下面两个问题:
1. 你的产品如果同时面向中国和欧盟市场,哪一部分会先触发合规成本?
2. 你的 AI 能力到底属于“推荐”“生成”“深度合成”还是“高风险决策辅助”?不同分类,决定了你后面的治理路径。
下期预告
监管讨论的是外部规则,下一篇我们继续看 AI 内部真正危险的地方:
《AI安全的真实威胁:幻觉、偏见还是失控的Agent?》
到时候我们会继续拆三个问题:
• AI 的“幻觉”到底有多危险?
• Agent 失控最先伤到的会是谁?
• 普通用户该怎么判断一个 AI 系统值不值得信任?
关注专栏,不错过后续更新。
作者:ECH00O00
首发于专栏《AI风向标》
如果这篇文章对你有启发,欢迎点赞、收藏、转发。你的支持是我持续创作的最大动力。❤️
