 夜雨聆风
夜雨聆风大家好,我是林之愿。
今天给大家讲一个我最近折腾出来的工作流——两个 AI Agent 怎么共享同一套 Obsidian 笔记体系。
前两天我在 Obsidian 里写一篇关于 LLM Wiki 的笔记,写到一半突然想起来一个问题,Karpathy 最早是在哪个分享里提出这个概念的,我当时没记。
以前这个问题的解法是,切出去搜,收藏,读完了再切回来继续写。
但现在我的解法是,继续打字,同时给 Telegram 上的 Hermes 发了一条消息,「帮我查一下 Karpathy LLM Wiki 最早的来源」。
三十秒后 Hermes 回复了,顺便把这个来源截图保存到了 vault 里的 raw/articles/ 目录下,顺手还更新了 wiki/concepts/ 里那张 C-009-LLM-Wiki 的相关链接。
我回到 Obsidian,Graph View 里多了一个节点。
这个过程里我做了什么?
几乎什么都没做。就是发了一条消息。
这就是我今天想跟你聊的东西,两个 AI Agent 怎么协作同一套知识体系,以及为什么我觉得这才是「第二大脑」真正能运转的原因。
说实话我自己折腾这套东西也花了点时间,不是上来就成的,中间踩过几个坑,后面会说到,先把这个workflow是什么讲清楚。
两个 Agent,同一个 Vault
先交代一下我的工具栈。
我同时用两个 AI Agent,Claude Code 和 Hermes。
Claude Code 通过 Claudian 插件直接在 Obsidian 里运行,是我的主力写作搭档。能直接读写我的笔记文件,执行命令,调用技能,在 Obsidian 那个窗口里直接跟我对话。
Hermes Agent 通过 Telegram 接入,是我的外挂大脑。手机上随时能发消息,帮我查资料、跑流程、写脚本。
重点来了,两者共用同一个 Obsidian Vault。
这意味着什么,Hermes 查到的资料、建立的链接、沉淀的知识,Claude Code 下一秒就能读到。反过来也一样。
不是两个工具,是同一个大脑的两个入口。
编译思维:Vault 是仓库,不是备忘录
支撑这套工作流的核心方法论,来自 Karpathy 的 LLM Wiki 理念。
他有个隐喻我特别认同,Obsidian Vault 等于代码仓库,LLM 等于编译器。
不是整理笔记,是编译知识。
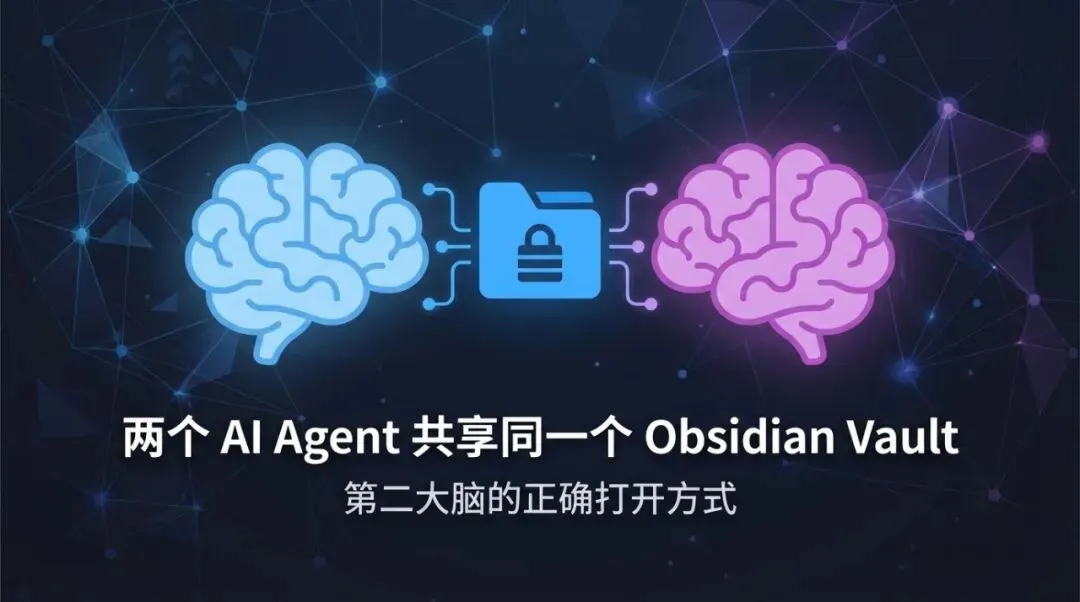
软件工程那套思路直接搬过来,三层严格分离,raw/ 放原始资料只读不改,wiki/ 是编译产物由 LLM 维护,outputs/ 是运行时输出。
增量处理,每天新来几篇文章增量编译,不用全量重建。可追溯,每个知识条目都能链接回原始来源。
这个感觉很爽,就是你跟别人说「我记得在哪里看过这个说法」,不再是靠脑子回忆,而是一路追到 raw/articles/ 下面第三段。
具体怎么配置
说真的,这部分是我踩坑最多的地方,一上来眉毛胡子一把抓,结果规则乱掉,后来才想明白得先定好几条基本规范。
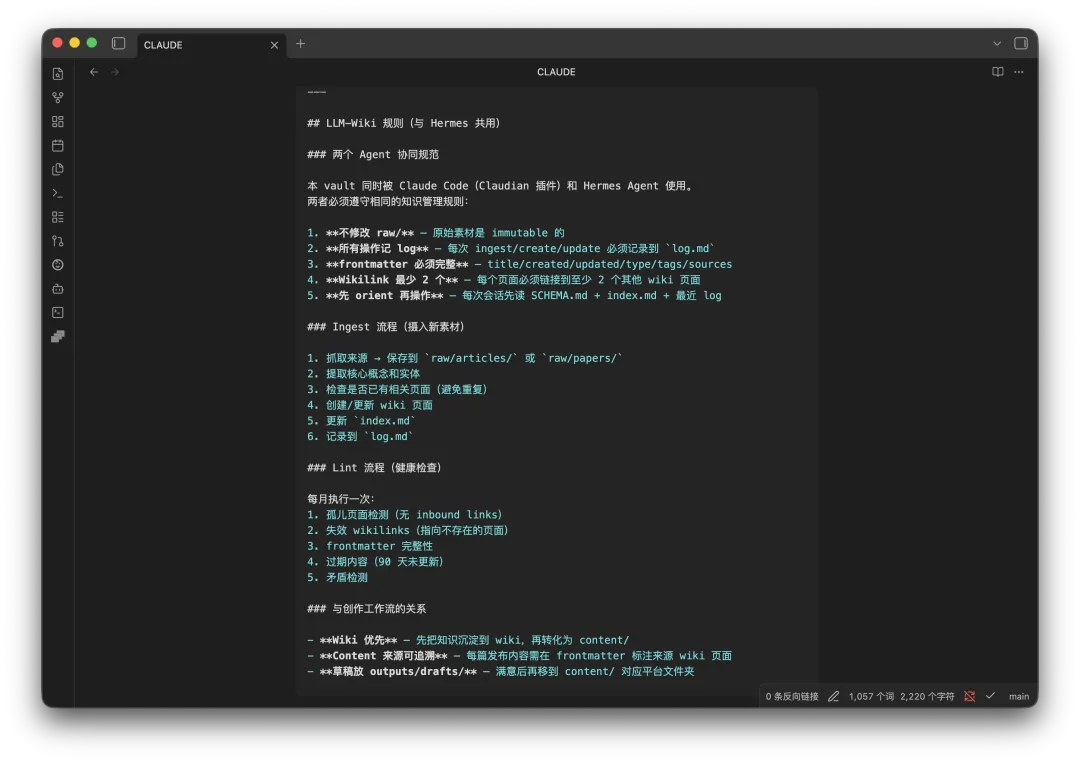
知识编译规则
raw/ 怎么进,原始素材进来之后只读不改。Web Clipper 抓网页、Podwise 抓播客,都先存到 raw/articles/ 或 raw/papers/,这是不可变的事实来源,后面找不到原文是很痛苦的。
wiki/ 怎么建,每篇 wiki 笔记必须有完整 frontmatter,title、created、updated、type、tags、sources,六字段缺一不可。还有个关键约束,Wikilink 最少 2 个,每篇笔记必须链接到至少 2 个其他 wiki 页面,我一开始偷懒只写 1 个,结果 Graph View 里全是孤岛,没形成一个网络。
编译流程是这样的,攒了 5 到 10 篇 raw 之后,做第一次编译,读 raw → 生成摘要 → 提取概念 → 更新索引,增量处理,不用全量重建。
双 Agent 协同规范
这一节是我专门写给两个 Agent 看的,也是整个体系能真正跑起来的关键,不然两个 Agent 各干各的,vault 分分钟乱给你看。
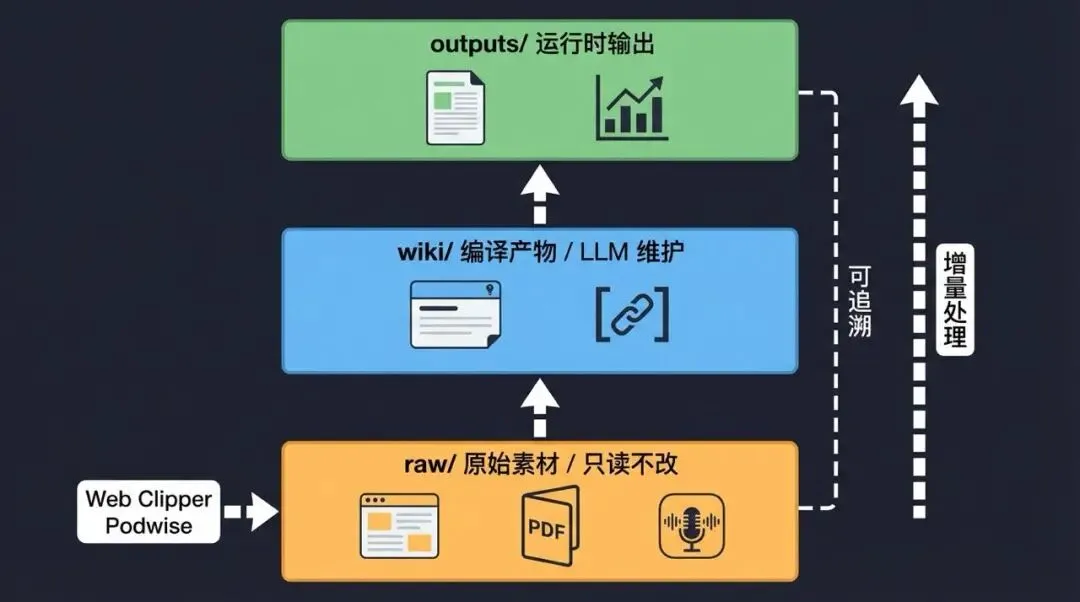
第一,不修改 raw/,原始素材不可变,Agent 只读不写。
第二,所有操作记 log,每次 ingest、create、update 必须记录到 log.md,包括时间、操作内容、涉及的文件。
第三,frontmatter 必须完整,六字段缺一不可。
第四,Wikilink 最少 2 个,避免知识孤岛。
第五,先 orient 再操作,每次会话先读 SCHEMA.md 加 index.md 加最近 log,确保 Agent 理解当前知识体系的完整状态再动手。
一开始可能会觉得这五条太啰嗦,但相信我,跑通之后你会回来感谢我的。
Skill 安装
规则有了,具体操作得封装成可复用的 Skill,不然每次都要手把手教 Agent 怎么做,累死。
我的方案是装在两个地方,Claude Code 用 /.claude/skills/,Hermes 用 /.hermes/skills/。
必装的有三个。
obsidian-dual-agent,定义两个 Agent 如何感知彼此状态、怎么分配任务,这个是基本框架。
llm-wiki,Karpathy LLM Wiki 的具体操作规范,包括怎么 ingest、怎么 query、怎么 lint,让 Hermes 在 Telegram 上也能完整执行编译流程,不是只回你一句话,而是真的帮你把活干完。

CLAUDE.md 是核心
我在 vault 根目录写了一个 CLAUDE.md,把上面的协同规范全部写进去,作为两个 Agent 共用的协作契约。
核心原则就一条,规则是活的,每次纠正 Agent 的错误之后,让它自己更新 CLAUDE.md,「Update your CLAUDE.md so you don't make that mistake again」。
不是写完就完事,是随着实践不断进化。
Ingest 和 Lint
有规则还不够,还得有两个持续跑的流程来保证体系不腐烂,不然一个月之后 vault 就长满杂草了。
Ingest 流程是这样跑的,抓来源 → 保存到 raw/ → 提概念 → 检查重复 → 建 wiki 页面 → 更新 index → 记 log,六步走完。这个流程由 Hermes 在后台跑,我只需要发一条消息,就是一开始说的那个场景。
Lint 流程是每月一次的健康检查,孤儿页面检测、失效 wikilinks、frontmatter 完整性、过期内容、矛盾检测,五项全过才能说 vault 健康。
Vin 说过一句话我特别认同,「这件事我一个人做不到,阅读所有这些文件、理解它们之间的关联,作为一个人类来说根本不可能」。
Agent 做得到。而且不会忘。
核心认知
Vin 还说了一句让我想了很久的话,你不再管理 Agent,你管理你的 Vault。
Agent 从 Vault 里提取信息做决策,如果决策错了,他改 Vault,不是改 Agent。
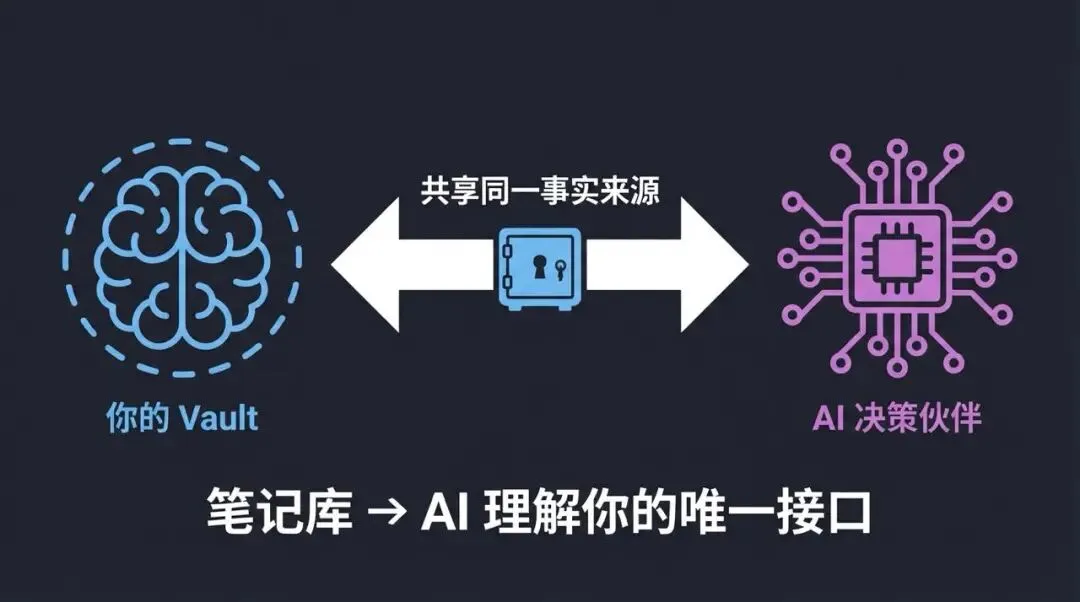
笔记库不是给你看的备忘录,而是 AI 理解你的唯一接口。
你写得越深、越结构化、越持续更新,AI 就越能代表「此刻的你」来做决策。
第二大脑的真正含义不是把笔记存起来,而是让你和 AI 共享同一个事实来源。
怎么开始
可能有些朋友觉得这套东西很复杂,其实门槛没有想象的那么高,我说一下我自己是怎么起步的,不一定是最优解,但至少证明这条路走得通。
第一步,下载 Obsidian,免费,建一个 Vault,不需要任何配置。
第二步,开始写,每天一条笔记就够了,反思、想法、学到的东西,关键词是持续,不要一开始就追求完美。
第三步,写一个 CLAUDE.md 文件,告诉 AI 你是谁、你在做什么,哪怕只有 10 行,它就能让 AI 从通用助手变成懂你的搭档。
说实话一开始可能有点笨拙,AI 给的东西不一定是你想要的,需要反复调整,这个过程走完,你会真正理解为什么第二大脑值得花这个时间。
最后说两句
99.99%的人不会花时间真正去设置这样一套东西。
这恰恰意味着,那些愿意花时间的人,会获得巨大的优势。
Obsidian 加 Claude 不是在教你用工具,是在教你,用工程化的方式,把你自己的思考变成可被 AI 调用、可被持续积累、可被检索使用的资产。
你的笔记库会一直跟着你,工具会换,资产不会。
/ 作者:林之愿
