 夜雨聆风
夜雨聆风2026年,大语言模型已深度嵌入从代码开发到科学研究的企业核心流程。但对于大多数从业者而言,大模型仍是一个“黑箱”——知道它能做什么,却不太清楚它为什么能做。这种认知差距正在成为一个真实的生产力瓶颈:不理解底层原理,就无法做出有效的架构选型和性能优化。
本文将从零开始,系统拆解大语言模型的底层技术架构,涵盖Transformer核心机制、训练优化策略、推理加速方案以及2026年涌现的前沿技术趋势。
一、Transformer:现代大模型的“心脏”
1.1 从RNN到Transformer:一次架构革命
在大语言模型的发展历程中,Transformer的出现是一次彻底的范式革命。2017年Google Brain团队在论文《Attention Is All You Need》中提出的这一架构,至今仍是几乎所有主流大模型的技术基石。
在此之前,语言模型的主流架构是循环神经网络及其变体LSTM和GRU。这些架构逐个处理序列中的每一个token,形成了严重的顺序瓶颈,距离较远的token之间难以建立有效影响。更致命的是,RNN无法进行有效并行计算,训练大模型需要极其漫长的时间。
Transformer的核心突破在于:彻底抛弃了循环结构,改用纯注意力机制处理序列。这意味着模型可以在单个操作中让每个token直接关注到序列中的任何其他token,实现了每一层的全局感受野。并行计算的可行性随之而来,训练效率获得了数个数量级的提升。
1.2 自注意力机制:数学之美
自注意力机制是Transformer最核心的组件。它的核心价值在于动态捕捉序列元素间的复杂关联,实现全局上下文建模。
注意力机制的本质是一个加权求和过程。对于输入序列中的每个元素,模型会计算它与其他所有元素的相关性,然后将这些相关性作为权重,对元素的信息进行加权融合。数学上,自注意力机制通过三个矩阵的交互完成:
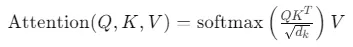
其中Q、K、V分别代表查询矩阵、键矩阵和值矩阵,它们都来自同一输入序列的不同线性变换。Q和K的点积衡量两个位置的相关程度,除以 $\sqrt{d_k}$ 是为了防止点积结果过大导致梯度消失,softmax函数将相关分数转化为概率权重,最后用这些权重对V进行加权求和。
以一个具体的指代消解任务为例。面对句子“猫追狗,它跑得很快”,自注意力机制的工作流程如下:首先将“猫”、“狗”、“它”映射为词向量并生成对应的Q、K、V矩阵;“它”的查询向量与“猫”、“狗”的键向量计算点积,得到注意力分数;根据分数对“猫”、“狗”的值向量加权求和,生成“它”的最终上下文表示。实验表明,这种机制可使指代消解准确率提升30%以上,在长文本场景中优势尤其明显。
1.3 多头注意力:并行捕捉多维度关系
单头注意力虽强大,但只能捕捉一种类型的关联。多头注意力通过并行执行多个独立的注意力头,显著增强了模型对不同类型关系的捕捉能力。在翻译任务中,不同的注意力头可能分别关注语法结构、语义相似度或领域知识。
以8头注意力为例,计算过程如下:通过线性变换将输入向量投影为8组Q、K、V矩阵,每组维度为 $d_{model}/8$;每组独立执行自注意力公式,生成8个上下文向量;最后将这8个向量拼接并通过线性层映射回 $d_{model}$ 维度。实验数据显示,8头注意力在机器翻译任务上的BLEU分数比单头版本提升15%。
通过注意力权重可视化可以发现有趣的分工现象:低序号头倾向于捕捉局部语法关系,如主谓宾结构;高序号头则更关注全局语义关联,如共指消解。这种分工机制使模型能够同时处理多层次的语言特征。
1.4 位置编码:注入序列信息
Transformer完全抛弃了循环结构,这意味着它天生不知道token在序列中的先后顺序。位置编码正是为了解决这一问题而设计——它为每个位置注入一个唯一的“位置指纹”。
最经典的位置编码方案采用正弦和余弦函数的组合:
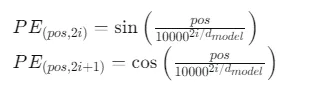
其中pos是token在序列中的位置索引,i是编码向量的维度索引。这一设计具备三大优势:不同位置编码之间的差异随距离呈指数衰减,符合语言中相邻词关联更强的规律;正弦余弦函数的周期性赋予了编码良好的外推能力,在2倍训练长度下性能仅下降5%;计算简单且不需要额外的可训练参数。
二、MoE架构:参数规模与计算成本的解耦
2.1 从密集到稀疏
传统大语言模型采用密集型架构,前馈神经网络层在处理每个输入时都会激活所有参数。当模型参数扩展至数千亿级别时,这一设计的局限性日益凸显:所有参数参与计算导致推理速度缓慢、硬件成本高昂;完整模型加载至内存使部署极为困难;参数规模指数级增长带来巨大的训练周期和成本。
混合专家模型正是在这一背景下应运而生的关键技术路径。MoE的核心思想将庞大的神经网络分解为多个专门的子网络,通过动态路由机制为每个输入选择最适合的专家进行处理。这种“分而治之”的策略实现了参数规模与计算成本的有效解耦——模型的参数可以轻松扩展到数千亿甚至万亿级别,但每次前向传播只激活其中的一小部分。
2.2 路由机制:Keep-TopK
MoE的核心组件包括专家网络和门控网络两个部分。专家网络是多个独立的前馈神经网络子模块,每个专家专注于学习某一类特定的模式;门控网络则负责为每个输入token动态选择合适的专家组合。
其中最经典的路由策略是Keep-TopK,其数学表达为:
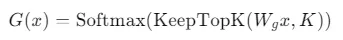
门控网络首先计算输入x与所有专家的匹配分数,然后仅保留分数最高的K个专家,将其余专家的权重置为零,最后对保留的K个权重进行Softmax归一化。通常K远小于专家总数,例如在DeepSeek V3中,虽然模型拥有数百个专家,但每次推理仅激活其中8个。这种稀疏激活机制使得MoE模型能够在保持可控推理开销的前提下,实现参数规模的巨大扩展。
2.3 负载均衡挑战
MoE架构面临一个棘手的工程问题:负载不均衡。门控网络可能倾向于将大多数token分配给少数几个“万能”专家,而大部分专家几乎从不被激活。这不仅浪费了参数容量,还会导致模型无法充分利用专家的专业化潜力。
为了解决这一问题,研究者引入了负载均衡损失作为训练目标的一部分。常用的Auxiliary Loss通过惩罚专家被选中的概率方差来鼓励均匀分配,而Expert Capacity机制则为每个专家设定一个最大可处理token数量的上限,超出部分的token将直接丢弃。华为盘古Ultra和DeepSeek V3等2025年的代表性MoE模型都在这一方向进行了深入优化。
三、从思维链到测试时扩展:推理范式的演进
3.1 思维链推理:让模型学会“思考”
传统大模型直接输出最终答案,对于复杂问题表现不佳。思维链提示通过在提示词中加入“让我们一步步思考”这样的引导语,促使模型在输出最终答案前显式地生成中间推理步骤。
一项2026年3月发表的系统性理论研究揭示了思维链的工作机制:思维链提示激活了模型的任务分解能力,将复杂问题拆解为一系列更简单的子任务,这些子任务正是模型在预训练阶段已经熟练掌握的技能。从理论角度看,思维链将一个大型分类任务分解为多步推理过程,每一步都降低了问题空间的复杂度。然而,传统思维链存在一个根本局限:推理过程必须被“说”出来,即用离散的token序列来表达,这导致推理步骤变长时计算开销呈线性增长。
3.2 潜在思维链:推理与语言生成的解耦
为了突破这一局限,2026年初,研究者提出了潜在思维链这一重要创新。其核心洞察是:推理本质上是一个确定性规划过程,不一定要被表达为自然语言。潜在思维链将推理与语言表达解耦,推理在模型的连续隐空间中进行规划,仅在必要时才由解码器将推理结果转化为文本。
这种设计带来的核心优势在于:模型可以动态决定何时终止推理,不再依赖固定的推理步数超参数;推理在隐空间中进行,避免了token生成带来的高额开销;更重要的是,潜在思维链学习到了更广阔、更鲁棒的解决方案空间,为推理时搜索提供了透明且可扩展的基础。
3.3 测试时扩展:用计算换智能
测试时扩展是2026年大语言模型推理优化的前沿范式。其核心思想极其简洁而强大:在推理阶段动态增加计算资源,以换取更高质量的答案。具体手段包括多次采样取最优、链式思考、工具调用以及自适应深度搜索。
这一范式的出现源于2025年下半年形成的产业共识:后训练阶段的扩展效益已接近饱和,继续增加训练数据或微调轮次带来的收益微乎其微,而推理阶段的“额外计算”能够以亚线性成本实现指数级的性能提升。这一思路最早由OpenAI o1系列模型验证——通过隐式链式推理和多次采样验证,将70B模型在数学难题上的正确率提升了2到3倍。随后,DeepSeek-R1和Qwen系列的开源实现进一步将测试时扩展从实验室演示推向生产部署。
最新提出的MemCoT框架更进一步,将长上下文推理重新定义为迭代式的、带状态的信息搜索过程。通过引入多视角长期记忆感知模块和任务条件的双短时记忆系统,MemCoT在多个基准测试上达到了最优水平。评估显示,受MemCoT增强的多个开源和闭源模型,在LoCoMo和LongMemEval-S基准上实现了最优性能。
四、训练优化:从BF16到FP8
大模型的训练过程本身也经历了深刻的效率革命。
传统训练使用FP32或BF16精度。BF16保留了FP32的指数位范围,大幅减少了梯度下溢问题,同时将内存占用减半,已成为大模型训练的默认精度选择。但2026年,FP8训练正成为新的技术焦点。
FP8将每个参数压缩至8比特,相比BF16进一步将内存占用减半。如果FP8训练能够保持与BF16相当的精度,那么同样硬件配置下的模型规模可以翻倍,或者训练速度可以大幅提升。然而,FP8的低精度带来了严重的数值稳定性挑战:梯度可能溢出或下溢,训练过程容易发散。
ICLR 2026接收的MOSS框架提出了两项关键创新:两级微缩放策略为敏感的激活值提供更精细的量化粒度,在精度与去量化开销之间找到平衡;线性层权重的自动缩放消除了训练过程中昂贵的最大值归约操作。实验结果显示,MOSS成功训练了7B参数的FP8模型,性能与BF16基线相当,同时实现了高达34%的训练吞吐量提升。这意味着用FP8训练大模型已不再是学术实验,而是具备工业级可行性的技术方案。
五、推理优化:KV缓存与注意力加速
5.1 KV缓存:避免重复计算的经典优化
自回归语言模型在生成每个新token时,需要重新计算之前所有token的注意力分布。KV缓存的核心思想是将已经计算过的Key和Value向量存储起来,在后续的生成步骤中直接复用,避免了重复计算。对于生成长度L的序列,KV缓存将复杂度从O(L²)降低为O(L),这对于长文本生成是质的飞跃。
5.2 TurboQuant:在不牺牲精度下压缩KV缓存
KV缓存带来的新问题是内存占用。随着上下文窗口从几千扩展到数百万token,KV缓存的内存需求呈线性增长,迅速成为推理瓶颈。
2026年3月,Google发布了TurboQuant技术,专门解决KV缓存内存爆炸这一“最令人头疼、讨论最少的问题”。TurboQuant通过先进的压缩算法,在完全不牺牲模型精度的前提下将KV缓存内存占用缩减至六分之一。在Gemma和Mistral模型的测试中,该技术在NVIDIA H100硬件上实现了6倍内存节省和8倍注意力计算加速。
正如Forrester首席分析师所言,受GPU内存而非计算能力限制的企业,可以在现有硬件上运行更长的上下文窗口、支持更高的并发性,或在相同工作负载下减少GPU总支出。这项技术的发布标志着KV缓存压缩已从学术研究走向生产级可用。
六、世界模型:大模型的下一个战场
如果前面讨论的技术都集中在“让模型更准确”的维度,那么世界模型则代表了一个不同的方向:让模型理解物理世界。
2026年最引人注目的事件之一,是图灵奖得主Yann LeCun离开Meta,创立AMI Labs并融资10.3亿美元,专注构建他称之为“世界模型”的技术。与此同时,李飞飞创立的World Labs也独立融资10亿美元,投资者包括AMD、Autodesk、NVIDIA和Fidelity。
LeCun的核心批判直指当前大模型的根本局限:“语言模型预测的是文本,而非物理现实。”世界模型的核心功能是基于行动者提出的想象动作序列,预测未来可能的世界状态。世界模型的质量直接决定了智能体的决策上限——若其预测缺乏合理性,将引入系统性偏差,导致策略收敛于次优甚至危险的行为。
IBM Distinguished Engineer对LeCun思想的解读提供了一个清晰的概括:“系统应该学习现实的潜在结构和动态,而不仅仅是文本中的模式。”2026年4月,智元发布了Genie Envisioner 2.0世界模型,实现了动作驱动的物理进化引擎和内置激励模型,使机器人能够在虚拟环境中自主学习与决策。
世界模型的质量决定了智能体的决策上限,这一领域的技术突破将直接影响具身智能向AGI的演进路径。从生成更准确的token,到预测世界的下一帧——这或许是大语言模型底层原理的终极演进方向。
