 夜雨聆风
夜雨聆风
不少人手机里
都有个“什么都舍不得删”的相册
憋到 256 G 全红,束手无策
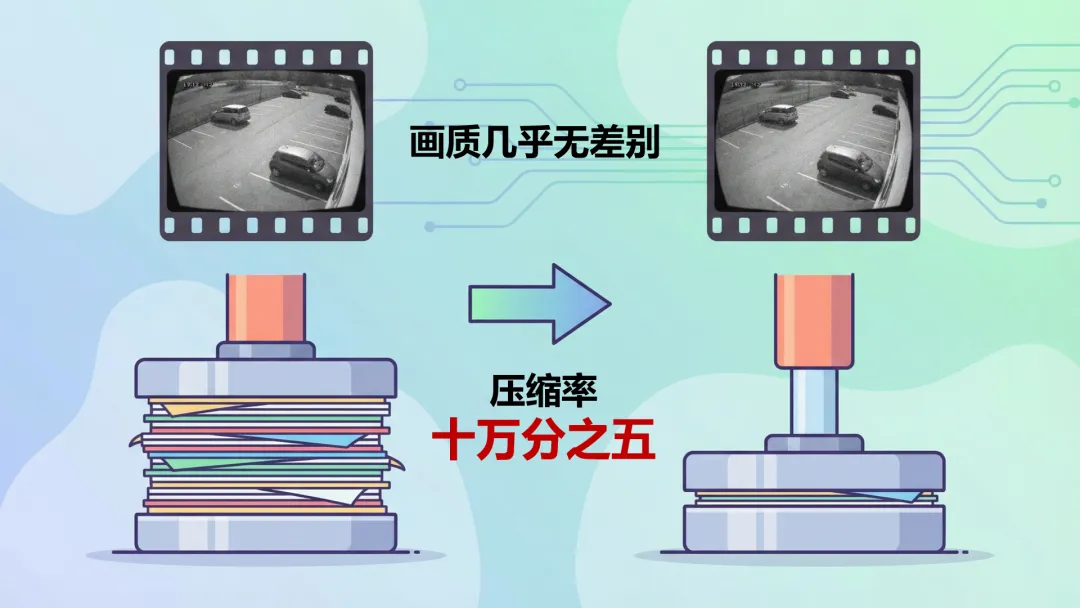
现在,一条朋友圈九宫格的文件大小
就能装下所有
还几乎不牺牲画质
这是什么三体人的“降维压缩”吗?
其实,针对监控摄像头视频
有一项技术
已经实现了这种极致压缩

这一版本将正激励噪声应用到前沿的神经网络视频压缩模型后,在固定场景的监控视频上成功实现了十万分之五的压缩率,是传统视频编码方案的 1%。

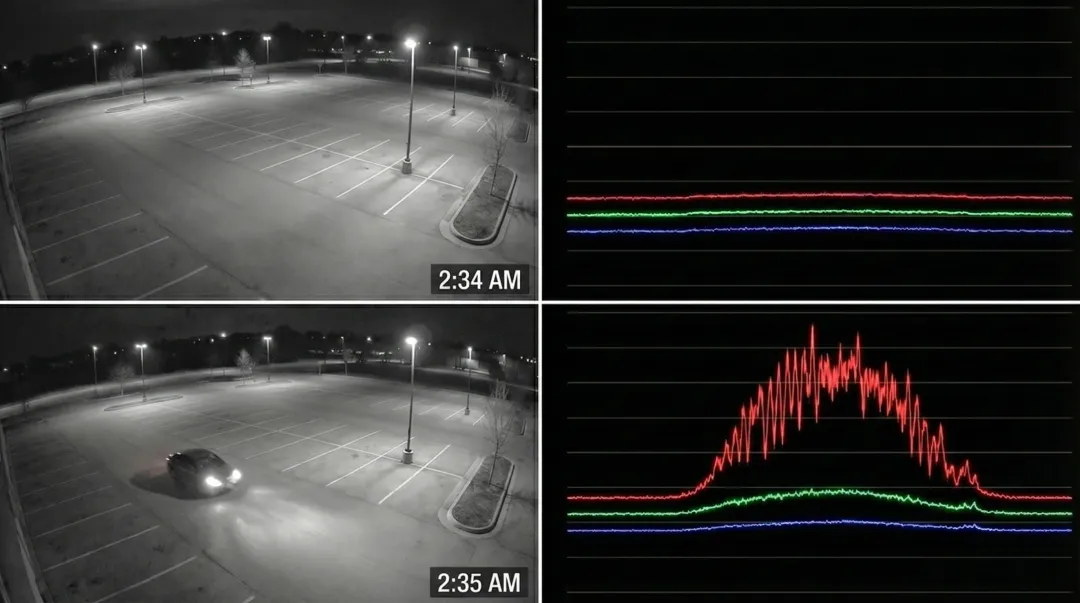
监控摄像头不眠不休地录制,产生天量数据,存储贵,调取难,但这其中绝大部分又是“无效静态画面”。那么正激励摄像头 2.0 实现极限压缩的秘诀是什么?
答案是:利用“噪音”来训练 AI。
TeleAI 科研团队发现,监控场景中那些短暂出现的扰动(噪声),比如突然走过的行人、闪烁的灯光、飘过的树叶,恰恰是帮助 AI 理解场景的“正激励噪声”(Positive-incentive Noise,Pi/π-Noise)。
正激励摄像头正是通过这些含有“良性噪音”的监控片段,对视频压缩模型进行针对性微调,让 AI 恍然大悟:“哦!原来这个场景里,墙壁、地面这些是几乎不变的‘背景板’,偶尔动来动去的才是需要重点记录的主角!”,使编码场景中的静态元素所消耗的码率显著下降。
AI 学会了“偷懒”,用极少的码率去传输不变的背景,把宝贵的空间留给真正在变化的画面。于是,即使视频在传输过程中只占用超低码率,但画质依然清晰。

超低码率,更优画质表现
在动态较多的监控片段中,采用传统编码将 2K 视频压缩到码率不足 600 kbps 后,运动物体周围出现了明显的色块和彩色噪点,甚至在人走过后还有残影。
正激励相机则有效避免了这些问题,灭火器箱上的文字和墙壁上的插孔始终清晰。
在静态画面更多的监控画面中,正激励相机可以将 2K 视频的传输码率压缩到 120 kbps,仅为原始码率的 1%,画质依旧清晰。
传统编码在压缩到如此低的码率后,画面中明显可见大量彩色噪点,墙壁上还存在明显的色块,插座和文字的细节模糊不清。
同等画质表现,占用更少带宽
更多针对静态场景视频的测试表明,若要实现相同画质(以 PSNR 指标为参考),正激励摄像头所需的码率最低。
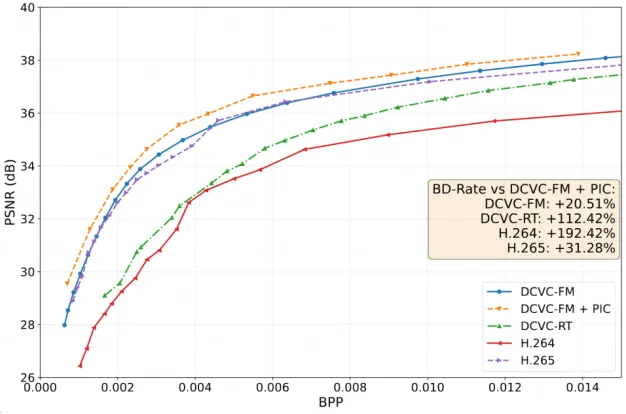
与神经网络视频压缩模型相对比:未经微调的 DCVC-FM 模型平均需要额外 20.5%的码率才能实现与正激励摄像头相同的传输质量;去除了显式动态建模的 DCVC-RT 模型,则需要额外 112% 的传输码率。
与传统的编码方案相对比:较先进的 H.265 编码需要 1.31 倍于正激励相机的码率,才能实现相同的画质。更传统的H.264 编码则需要多达 2.92 倍。
在动态较多的监控片段中,正激励摄像头仍能实现明显的率失真性能提升。
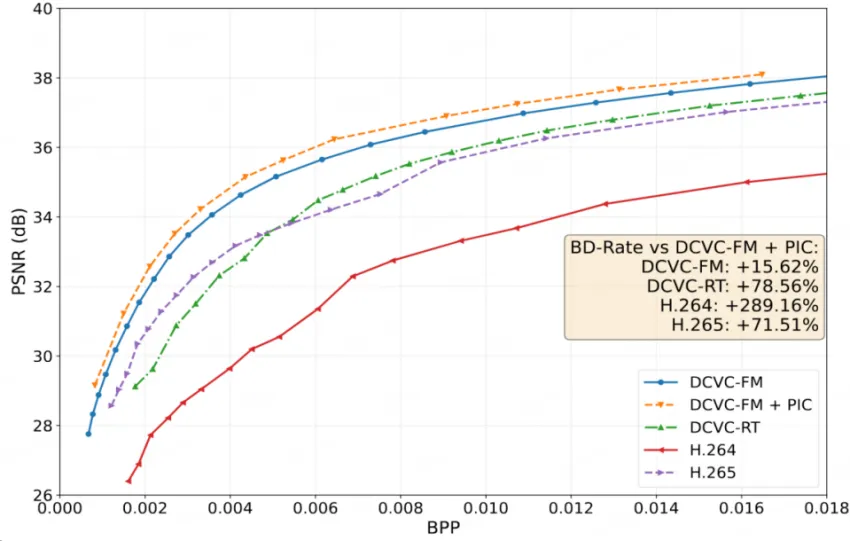
与神经网络视频压缩模型相对比:未经微调的 DCVC-FM 模型平均需要 1.16 倍的码率水平;网络结构更简单的 DCVC-RT 模型则需要 1.79 倍的码率。
与传统的编码方案相对比:H.265 编码比正激励摄像头需额外增加71.5%的码率;H.264 则需额外增加 289%的码率。

TeleAI 正激励摄像头以智传网(AI Flow)的信容律作为理论基础,充分利用模型智能来压缩数据量,从而满足下游应用“以计算换带宽”的需求。
在通算一体的端边云分层网络中,云端节点具有充足的计算资源,但边缘节点的上行网络带宽常常是高度受限的。正激励摄像头高度可控的计算开销,解决了这一痛点。
其网络参数量与 DCVC-FM 相同,编码端仅有 640 万参数,解码端也只有 3850 万参数,相比动辄数十亿的大模型参数而言要少得多,且在云端用少量数据微调后就能见效,完全可以规模化应用。
在智慧城市、公共安防、交通枢纽
正激励摄像头2.0
让海量监控数据
告别存储与带宽的焦虑
在智慧园区、家庭看护
让关键动态瞬间
始终清晰可辨
以智能压缩之力
看得更多,存得更精,传得更快
相关工作

C. Yuan, Z. Jia, J. Shao, X. Li*, "Enhancing Neural Video Compression of Static Scenes with Positive-Incentive Noise", arXiv:2603.06095.
X. Li, "Positive-incentive Noise", IEEE Transactions on Neural Networks and Learning Systems (TNNLS), 2024.
H. Zhang, S. Huang, Y. Guo, X. Li*, "Variational Positive-incentive Noise: How Noise Benefits Models", IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025.
J. Shao and X. Li*, "AI Flow at the Network Edge", IEEE Network, vol. 40, no. 1, pp. 330-336, Jan. 2026, doi: 10.1109/MNET.2025.3541208.
H. An, W. Hu, S. Huang, S. Huang, R. Li, Y. Liang, J. Shao, Y. Song, Z. Wang, C. Yuan, C. Zhang, H. Zhang, W. Zhuang, X. Li*. "AI Flow: Perspectives, Scenarios, and Approaches", Vicinagearth 3, 1 (2026).

