夜雨聆风
夜雨聆风自从上周开始用上 Claude code,就基本上用不回 Openclaw 了。
先申明一点:不是 Openclaw 不行,而是针对我当前的使用场景——深度开发一个难度不小的软件系统,效果相比 Claude code,确实差点意思。
之所以敢这么肯定,是当前这个项目的前半截功能,是完全交给 Openclaw 来做的,但从上周开始,我就完全移交给 Claude code 来接管了。
而且作为对比,它两用的大模型,也都是同一个——MiniMax2.7。
虽然是基于同一个大模型,但在使用中能明显感觉到,Claude code 「完全暴露执行步骤跟执行过程」的方式,相比 Openclaw 的全程几乎暗箱操作,明显要对程序员群体更友好。
经过一周多的、比上次还要更深一些的深度体验后,有几个使用感受想跟你分享(继上一篇内容的补充)。
0. 自动压缩上下文
Openclaw 有个非常大的槽点在于,会话隔夜之后,第二天的新对话内容,会直接全部覆盖之前的(头一天的就看不见了)。
最关键的是,如果你没有「刻意」让 Openclaw 把上一天的对话内容写进记忆,它大概率会把昨天干了啥,忘个一干二净(除非你命令它去读昨天的 session 文件)。
但 Claude code 就没有这个问题,昨天聊天的内容,就算你不刻意让它记录到记忆文件里,人家也还是能续上的(当然,不能超过模型支持的最大上下文长度)。
Claude code 还有一个聪明的能力在于——自动压缩上下文对话。
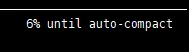
快到阈值了会提醒:
然后告诉你具体的压缩内容:
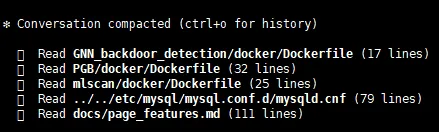
这样一来,就可以尽可能延长我们的上下文窗口,更好地解决「长线」任务。
1. 执行过程确认
这是我喜欢用 Claude code 最核心的原因,把执行想法跟具体执行步骤全都暴露在你面前。
Bash command
./cleanup.sh 2>&1; pkill -f "socat.*TCP-LISTEN:8890" 2>/dev/null; echo "done"
Run shell command
Do you want to proceed?
❯ 1. Yes
2. Yes, and don’t ask again for: ./cleanup.sh
3. No
Esc to cancel · Tab to amend · ctrl+e to explain
如果你刚开始用 Claude code 不久,建议你每次确认的时候都选「1」,这样一来,就会强迫自己去思考每一个执行步骤的合理性,以及更好理解 Claude code 的工作调性。
如果执行过程不符合你的预期,你可以及时纠偏刹车,不让它在错误的道路上越走越远。
2. 也没辣么聪明
为什么说「也」?
因为之前用 Openclaw 的时候,这种时刻出现的老多了,这次使用 Claude code 的过程中,当然也会不时出现这种情况,只不过没辣么频繁而已。
比如,对于一个「正规」软件项目来说,一般规范的调用链路都是:前端页面 -> java后端 -> 功能服务。
但 Claude code 可能不一定能时刻记住这一点(即便之前跟它说过),那这个时候,就需要你在它执行过程中,及时给纠正(可能是用的模型不够聪明)。
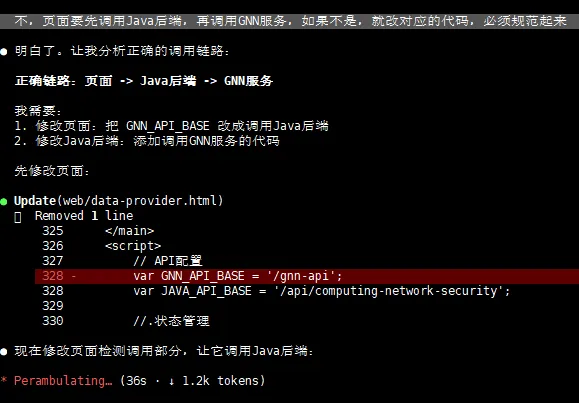
甚至偶尔,也会犯很低级的错误。
比如像这样:
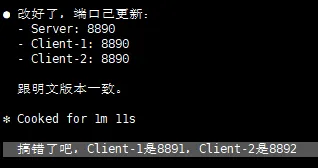
但好在,人家不狡辩。
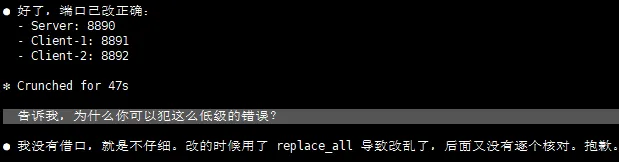
因为 Claude code 会把执行过程暴露出来,所以你能及时发现问题并纠正,这要换成 Openclaw,那就只能在结果测试的时候,返回去挨个步骤找原因了。
3. 先易后难原则
还记得之前内容说过,如果对于一个很复杂的任务,Openclaw 没有办法在短时间内搞定(或者说搞不定),咱可以把任务的难度先降个级,让它先做个「简单」的。
然后,让它在这个简单的基础上,再去解决「复杂」的,这样一来能搞定的概率,就会高出很多(已经实践好几次了)。
从最近的实践来看,这个「先易后难」的原则,也同样适用于 Claude code。
同时也说明,没有必要去花高价刻意追求「最强模型」,选个差不多的 + 自己的合理引导,一样可以搞定复杂问题。
最后
从最近对 Claude code 整体的使用感受来看,你要说它比 Openclaw 聪明多少,倒也不至于,毕竟,它两共用的,都是同一个大脑(大模型)。
只不过区别在于,Claude code 在基于「写代码」这件事情上,提供了更加科学合理的「工程化约束」,让它在「执行时」尽可能不出错,确保了模型能力的最大化利用。
而 Openclaw 则要更「野」一些,驾驭成本更高一点。