 夜雨聆风
夜雨聆风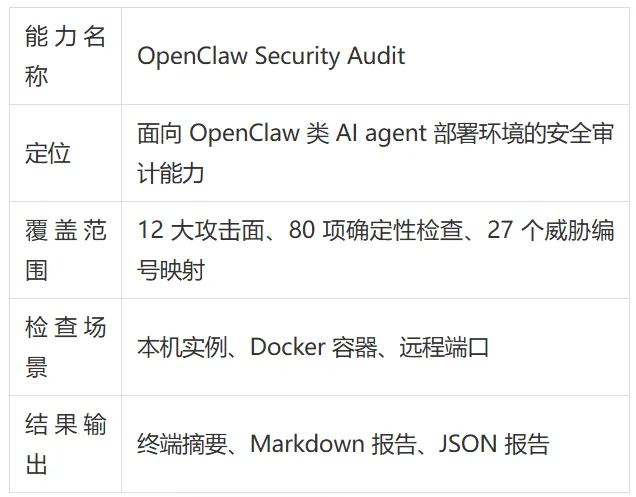
很多团队已经知道 OpenClaw 类 AI agent 部署里常见的安全风险。更难回答的问题是:
这些问题是否已经存在于当前正在运行的环境中。
OpenClaw Security Audit 就是用来回答这个问题的。它最准确的定位是:一项面向 OpenClaw 类 AI agent 部署环境的安全审计能力。
这个定义有两个边界需要先说清楚。
第一,它不只是讨论 OpenClaw 本体。我们关注的是现实里正在运行的一类 agent 环境:本机实例、Docker 容器、远程暴露端口,以及围绕这些环境展开的权限、配置、凭证、通道、日志和执行边界问题。
第二,它也不是一个声称适用于所有 agent 的通用安全平台。当前版本的目标很明确:针对 OpenClaw 类 agent 环境里那些可以确定、可以复现、可以直接定位到当前实例的问题,给出环境级的审计结果。
如果说安全基线、加固建议和检查清单回答的是“应该注意什么”,那么 Agent Check 回答的是“你当前这类 agent 环境里已经有什么问题”。
这也是它和通用安全建议最核心的区别。
这些通用建议依然重要,因为它们定义了安全基线、威胁模型和部署原则。Agent Check 则把这层认知落到当前实例上:不是泛泛提醒,而是一次确定性、可复现的环境级检查。
一、当前能力边界
从当前能力边界看,OpenClaw Security Audit 包括:
12 大攻击面
80 项确定性检查
27 个威胁编号映射
零 LLM 依赖
结果 100% 可复现
这些能力不是抽象标签,而是落在具体环境问题上的确定性规则。例如,它可以检查:
gateway 是否错误暴露到非 loopback 地址
token 是否以明文或硬编码方式存在
远程端口、容器绑定和 agent 执行边界配置是否存在明显风险
二、它支持哪些场景
它目前支持三类典型场景:
本机实例检查
Docker 容器检查
远程端口检查
输出形式也不是一句模糊结论,而是适合实际使用流程的几种结果:
终端摘要,用于快速查看问题分布
Markdown 报告,便于团队留档和流转
JSON 报告,便于后续自动化处理和集成
三、它不是什么
同样重要的是,它不是什么。
它不是把安全建议和检查清单换一种形式重新讲一遍。
它不是依赖 LLM 给出模糊判断的“安全点评”。这里所谓“零 LLM 依赖”,指的是检查结果不依赖模型输出波动,也不会因为 prompt 或推理路径变化而产生不同结论。
它也不是一个已经承诺覆盖所有 agent、所有框架、所有部署模型的通用平台。
它当前做的是一件更具体、也更有操作价值的事:
检查你当前这套 OpenClaw 类 agent 环境里,已经存在的确定性问题。
四、现已开放
OpenClaw Security Audit 现已开放。如果你正在使用 OpenClaw 类 AI agent,或者你的团队正在试点 agent、准备把 agent 接入真实流程,那么现在更值得确认的问题,不只是“有哪些风险值得关注”,而是:
你当前运行的这套 agent 环境里,已经有哪些问题。
如果这正是你想确认的内容,现在就可以体验 OpenClaw Security Audit:
https://github.com/zast-ai/openclaw-security-audit
❤️ 如果您觉得工具好用,欢迎在 GitHub 上帮我们点个 Star ⭐ ,您的支持是我们最大的动力!
