夜雨聆风
夜雨聆风
最近刷招聘网站,几个岗位格外扎眼:
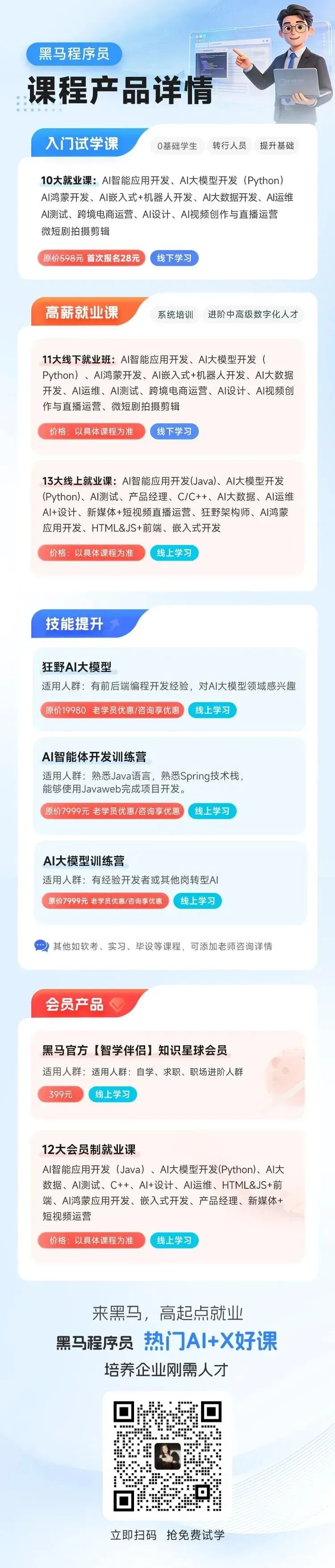
· GPU集群运维工程师(大厂双休)13-16K
· GPU集群运维工程师15-23K
· 算力交付工程师15-25K


截图来来源网络(如侵删)
部分岗位月薪已经摸到2W+,普遍比传统运维高出20%–40%,即便如此,企业依然招不到人。这些岗位有一个共同的名字——AI运维工程师。
为什么这么缺?当前,金融、电商、政企、互联网等行业全线向AI化转型,智算中心、GPU集群、大模型服务密集上线。模型有了,算法也不缺,但企业却卡在了最关键的一步——上线。
当企业试图把大模型从“Demo”推向生产环境时,问题接踵而至:GPU不会调、推理慢得离谱、并发一高就崩、成本蹭蹭往上涨……谁能把大模型部署上线、稳定跑起来、控住成本、快速排障,谁就是企业争抢的香饽饽。
这就是AI运维——高薪+刚需+不可替代。

今天播妞带来一个好消息:黑马程序员AI运维课程全新推出——《企业级AI大模型架构设计与部署运维实战》,用一个真实的企业级智能客服系统,带你走完从模型选型、推理优化到高可用运维的完整落地闭环。
为什么选择智能客服作为实战项目?
因为智能客服覆盖了AI运维最核心的挑战——高并发、低延迟、稳定性、成本控制,也是企业当前最迫切、最典型的大模型应用场景。在金融、电商、政企、互联网等行业,客服系统正是高频AI场景的代表。
传统人工客服模式随着业务扩张,问题日益突出:
·人力成本高,难以规模化扩展
·响应效率有限,高峰期服务质量难保障
·服务质量不稳定,依赖个人经验
·知识更新成本高,培训周期长
·无法实现7×24小时高质量服务
·重复性问题占比高,资源浪费严重
这些问题,正是大模型可以解决的痛点。而能解决这些痛点的人,正是企业高薪争抢的AI运维工程师。

本课程紧扣“企业级大模型部署与运维实战”核心目标,通过实际项目带你系统掌握从模型选型、环境搭建、推理优化,到高可用架构设计与平台化运维的完整闭环。
核心内容模块:
· GPU算力基础与IB网络架构:重点讲解GPU显卡硬件原理(如计算单元、显存、带宽、PCIe)、多卡协同机制,以及InfiniBand(IB)/ RDMA高性能网络架构,理解大模型训练与推理中的算力与网络瓶颈
· 大模型基础与技术选型:涵盖主流大模型体系、开源与闭源模型对比、推理框架选型(如vLLM、TensorRT-LLM等),以及不同业务场景下的模型选型策略
· 部署架构与环境搭建:包括GPU服务器环境准备、驱动与CUDA安装、容器化部署(Docker/Kubernetes)、模型加载与推理服务搭建。
· 业务集成与应用落地:讲解RAG(检索增强生成)、Agent应用模式,以及大模型与实际业务系统(客服、推荐、智能问答等)的集成方案
· 高可用架构设计:涵盖服务拆分、负载均衡、弹性伸缩、容灾设计、多机多卡部署等,构建企业级稳定可靠的大模型服务体系。
· 运维监控与故障处理:包括日志体系、指标监控(Prometheus/ Grafana)、链路追踪、常见故障定位与应急处理(如OOM、延迟抖动等)
学后可以掌握的核心能力:
👉掌握企业级大模型落地全流程能力:从模型选型、环境搭建、服务部署到上线运维,具备独立完成大模型从PoC到生产环境落地的实战能力。
👉掌握GPU算力与高性能网络的工程化应用:理解GPU显卡架构、显存与带宽瓶颈,以及IB/RDMA网络在多机多卡场景下的作用,能够进行算力资源规划与优化。
👉具备AI业务集成与场景落地能力:能够将大模型与实际业务结合(如RAG、Agent、智能问答、客服等),推动AI能力在企业中的真正落地。
👉具备高可用架构设计与故障处理能力:能够设计稳定可靠的大模型服务架构,掌握常见故障(OOM、延迟抖动、服务雪崩等)的排查与应急处理方法。
👉提升AI时代核心竞争力:补齐“大模型+运维+架构”复合技能短板,具备参与企业AI基础设施建设与技术决策的能力。
学后可以适应的岗位:
AI运维工程师(AIOps/LLM Ops)
DevOps工程师(AI方向)
GPU/算力运维工程师
基础设施运维工程师(AI基础设施方向)
项目目标:
基于大模型(LLM)与RAG技术,构建一个具备高并发处理能力、精准知识问答与多轮对话能力的企业级智能客服系统,在提升用户体验与响应效率的同时,有效降低人工成本,实现7×24小时稳定服务。
同时,通过推理优化、高可用架构及完善的运维监控体系,确保系统具备可扩展、可运营、成本可控的工程化落地能力。
服务成功运行示例:
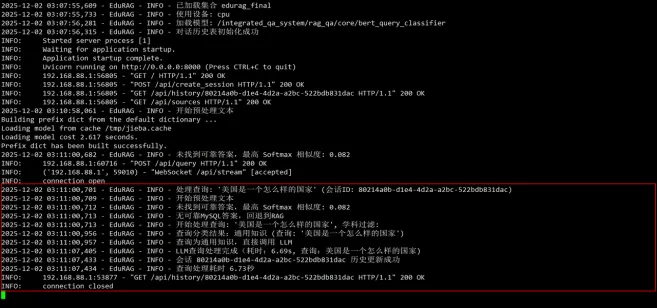
项目涉及技术点:
本项目深度集成大模型部署、推理优化、高可用架构及平台化运维全技术体系,兼顾本地与云端模型调用、GPU算力与高性能网络环境。
1. 大模型与推理技术
· LLM推理原理(Token生成机制、上下文窗口):大模型通过逐Token生成方式进行文本输出,每一步基于已有上下文预测下一个Token;上下文窗口决定模型一次可处理的最大文本长度。
· Prompt工程(指令设计、上下文构造):通过设计输入指令与上下文结构,引导模型生成更准确、符合预期的结果,是提升效果的关键手段。
· 模型服务化(API化封装、服务调用流程):将模型封装为标准API服务,供业务系统通过HTTP或RPC方式调用,实现解耦与复用。
2. RAG与知识库体系
· Embedding模型原理与选型:将文本转换为向量表示,用于语义相似度计算,不同模型在精度与性能上存在差异。
· 向量数据库(Milvus):专门用于存储和检索高维向量数据,支持快速相似度搜索。
· 语义检索与相似度计算:基于向量距离(如余弦相似度)查找与用户问题最相关的内容。
· 企业知识库构建(数据清洗、切分、索引):对业务数据进行预处理和结构化,提升检索准确率与生成效果。
· 检索增强生成(RAG)整体架构设计:通过“先检索再生成”的方式,将外部知识注入大模型,提升回答准确性并降低幻觉。
3. 推理加速与性能优化
· 推理框架(vLLM、TensorRT-LLM):提供高性能推理能力,优化显存使用与吞吐量。
· KV Cache机制:缓存历史计算结果,避免重复计算,从而显著提升推理速度。
· 动态/静态Batching:将多个请求合并处理,提高GPU利用率与吞吐能力。
· 模型量化(INT8/FP16等):降低模型精度以减少显存占用和计算量,在性能与精度之间做平衡。
· 并发处理与延迟优化:通过队列调度、异步处理等方式,提高系统并发能力并降低响应时间。
4. 高性能网络架构
· InfiniBand(IB)网络原理:一种高带宽、低延迟的网络技术,广泛用于AI集群中提升节点间通信效率。
· RDMA通信机制:实现内存之间的直接数据传输,绕过CPU,显著降低延迟并提升吞吐量。
· 高吞吐低延迟网络设计:通过网络架构设计与参数调优,保障大规模推理服务的稳定通信能力。
5. 容器化与云原生技术
· Docker容器化部署:将应用与依赖打包成容器,实现环境一致性与快速部署。
· Kubernetes(K8s)资源调度:通过K8s实现容器编排、资源调度与服务管理,是大模型平台的核心基础设施。
· Pod/Service/Ingress设计:分别负责应用运行、服务暴露与外部访问,是K8s网络模型的核心组件。
· 自动化部署与CI/CD流程:通过流水线实现代码到服务的自动构建、测试与发布,提高交付效率。
项目亮点:
①从PoC验证到生产级落地的完整工程闭环
项目不仅关注模型效果验证,更重点打通从模型选型、推理服务构建到生产环境高可用运行的完整链路,覆盖部署、优化、监控与运维全过程,真正解决企业“大模型能用但无法上线”的核心痛点。
②RAG驱动的高可信智能问答体系
通过构建企业级知识库与语义检索系统,结合检索增强生成(RAG)架构,实现“外部知识注入+可控生成”,有效降低大模型幻觉问题,在保证回答自然性的同时显著提升准确率与业务可信度。
③面向高并发场景的推理性能优化体系
围绕实际业务访问压力,系统性引入KV Cache、动态Batching、模型量化等多维优化手段,从计算、显存与调度层面全面提升吞吐能力与响应速度,实现性能与成本的平衡。
④GPU算力与高性能网络协同优化能力
深入结合GPU硬件特性与多机多卡部署模式,利用RDMA/IB网络降低节点间通信开销,突破分布式推理瓶颈,体现真实AI基础设施层面的优化能力。
⑤企业级高可用与服务治理架构设计
基于分布式架构构建多实例部署体系,引入负载均衡、限流、熔断、降级与弹性扩缩容机制,保障系统在高并发与异常场景下依然具备稳定性与服务连续性。
⑥可观测性驱动的运维体系建设
构建以指标(Metrics)、日志(Logs)、链路(Tracing)为核心的全栈可观测体系,实现从性能分析到故障定位的闭环能力,大幅提升运维效率与系统可控性。
⑦强业务贴合度与可复用架构设计
以智能客服为核心场景,覆盖企业最典型的高频应用,同时架构具备通用性,可快速复用于智能问答、知识助手、内部Copilot等多类AI场景。
项目流程图:
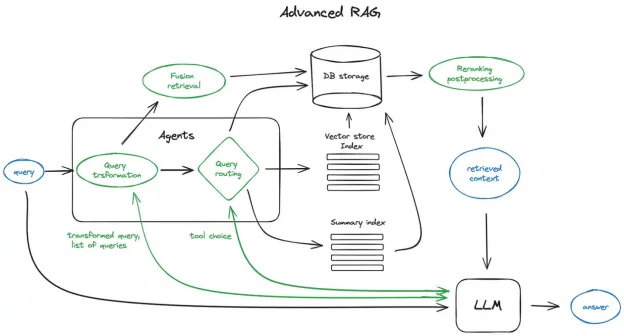
如果你也想成为企业高薪争抢的AI运维工程师,这个项目就是你的实战起点。黑马程《企业级AI大模型架构设计与部署运维实战》,等你来挑战。


当然,这个项目只是黑马AI运维就业班课程中的冰山一角。无数同学通过系统学习黑马AI运维课程,实现了人生的华丽逆袭!
2025年黑马AI运维学生就业成绩单:
↓↓↓



这些就业数据背后,是一个个真实的人生转折,如果你也想和他们一样,从迷茫到高薪,从普通到不可替代,AI运维就是你2026年不容错过的选择!
黑马AI运维课程,率先融入千亿参数级AI大模型技术,构建“技术纵深+产业实战”双轮驱动的复合型人才培养模式。同时,我们深度联合阿里云、华为云、科大讯飞等行业领军企业,合作共建课程内容体系,所学内容可以覆盖运维岗位90%以上的技能需求。
黑马AI运维课程以五大核心优势为支撑,助力学员实现“所学即所用、所学即所需”,在激烈的就业市场中脱颖而出,成为职业运维精英!
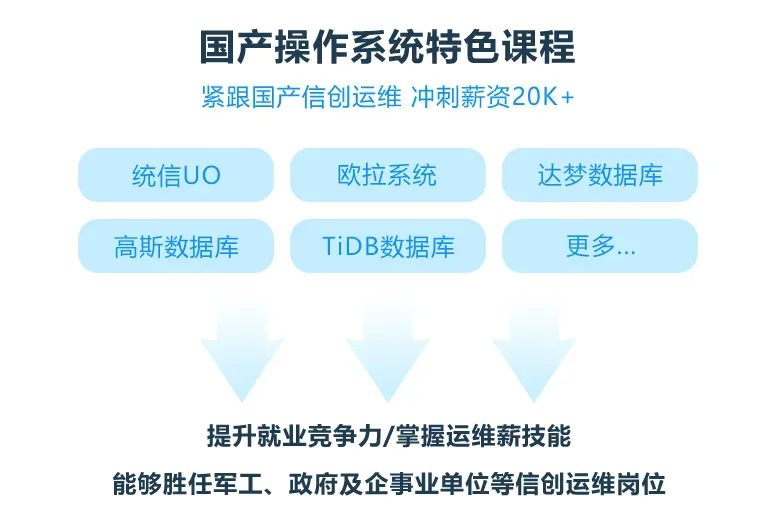
课程优势一:聚焦国产信创运维
聚焦国产操作系统(如统信UOS、欧拉系统)和数据库(如达梦、TiDB)的运维管理,学员通过系统安装、高可用配置与安全管理实战,具备服务政府、军工等信创环境的运维能力,适应国产技术生态发展。
课程优势二:多行业融合的实战矩阵
课程设计覆盖金融、电商、教育、医疗等多领域的高阶项目矩阵,聚焦支付系统的高可用架构、电商订单处理的高并发优化等核心场景。通过企业级任务实践(如性能瓶颈排查、容灾策略实施),锻造学员跨行业适配的运维专精能力。
课程优势三:沉浸式场景化教学架构
依托50+企业级仿真场景(如Nginx流量分发、数据库集群同步),学员在真实运维环境中执行关键任务(如故障根因分析、系统恢复演练),大幅提升技术洞察力与临场决策能力。
课程优势四:AI驱动的运维革新
深度融合AI大模型技术,推动运维流程的智能化转型(如自动化脚本生成、智能异常检测)。通过AI基础设施的部署与优化实践(如模型推理加速、资源动态监控),赋予学员下一代技术运维的核心竞争力。

课程优势五:云原生实训与认证加持
基于阿里云企业级平台打造70%实操课程,无缝对接阿里云ACA/ACP认证体系,帮助学员构建系统化的云运维能力,并显著提升职业履历的全球认可度。
时代浪潮奔涌向前,高薪、前景广、发展稳、门槛友好——AI运维正成为职场新风口!
无数学长学姐通过在黑马学到的真本领,实现了薪资翻倍的职业飞跃。如果你也想抓住这波AI浪潮,别再犹豫了,来黑马,下一个高薪学员,就是你!
来黑马,学AI运维
AI全程赋能,助你紧抓“薪”机遇
线上线下皆可学,扫码立即咨询
还能免费领取学习资料

来黑马,高起点就业
黑马好课、好老师、好服务
匠心打造多学科、多元化课程体系
线上线下皆可学(不脱产不离校)