 夜雨聆风
夜雨聆风「搞懂AI」系列 · 第一章 · AI基础概念| 上期我们搞懂了训练、微调、RAG、Agent。这一期继续扫盲——多模态、开源vs闭源、参数量、推理、量化。看完这篇,AI新闻里的技术术语再也难不倒你。
先从一个"看不懂"的瞬间说起
之前,我刷到一条AI新闻:
"Meta 发布了 Llama 3.1 405B 开源模型,采用 BF16 量化方案,支持多模态输入,推理成本降低 40%……"
我盯着这段话看了半天:
405B 是啥? BF16 量化又是啥? 多模态输入是啥意思? 推理成本为啥能降低?
每个字都认识,连在一起就是天书。
如果你也有这种"看不懂AI新闻"的挫败感,这一期就是专门为你写的。
五个概念,逐个击破
1️⃣ 多模态(Multimodal)—— AI 不再只"会聊天"
🎭 类比:从"只会听"到"能看能听能说"
想象一个人:
- 普通AI
= 只会听人说话、然后回答(比如早期的 ChatGPT,只能处理文字) - 多模态AI
= 能看图片、能听声音、能读文字、还能生成图片/视频(比如 GPT-4V、Claude 3、Gemini)
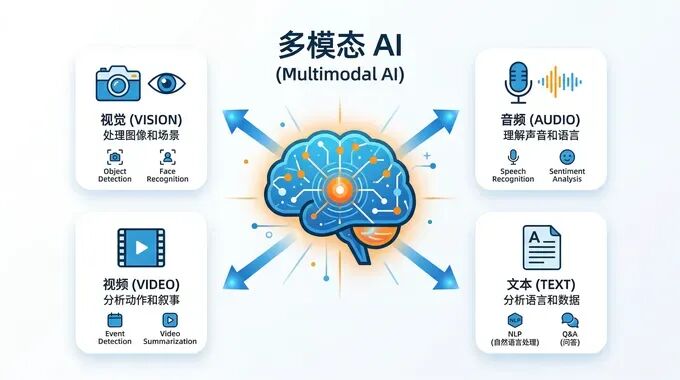
🔍 具体能做什么?
💡 一句话总结
多模态 = AI 能同时处理多种类型的信息(文字、图片、音频、视频),不再局限于单一形式。
为什么重要?因为真实世界本来就是"多模态"的——我们看图说话、听声音辨人、看视频学知识。多模态AI更接近人类的真实交互方式。
2️⃣ 参数量(Parameters)—— AI 的"脑容量"
🧠 类比:大脑里的神经元连接
人脑有约 860 亿个神经元,神经元之间的连接越多,理论上能处理的信息越复杂。
AI 模型的参数量,就相当于它的"脑容量":
参数越多 → 能记住的东西越多 → 能力通常越强 参数越少 → 更轻量、更快、更省资源
📊 常见模型的参数量对比
B = Billion(十亿),T = Trillion(万亿)
⚠️ 但参数量不是唯一标准!
很多人以为"参数越多越好",其实不完全对:
- 训练质量
更重要:同样是70B,训练得好的模型可能比训练差的100B更强 - 架构优化
:新架构能用更少参数达到更好效果 - 使用场景
:手机端跑不了大模型,小模型反而更实用
💡 一句话总结
参数量 = AI 模型的"脑容量",是衡量模型规模的重要指标,但不是唯一指标。
3️⃣ 推理(Inference)—— AI 的"思考过程"
🎯 类比:考试时的"答题过程"
想象一个学生:
- 训练
= 平时学习、做题、复习(我们上一期讲过) - 推理
= 真正考试时,看到题目、思考、写出答案的过程
AI 也是同样的道理:
- 训练阶段
:模型在海量数据中学习规律(费时间、费算力、一次性) - 推理阶段
:你问它问题,它给出回答(每次提问都要进行)
🔍 为什么"推理成本"很重要?
每次你跟 ChatGPT 聊天,背后都在进行推理计算:
这就是为什么:
GPT-4 比 GPT-3.5 贵(推理成本更高) 有些AI服务按"token数"收费(推理越多,费用越高) 各厂商都在优化"推理效率"(让AI回答得更快更便宜)
💡 一句话总结
推理 = AI 接收输入、进行计算、生成输出的过程。是你每次用AI时实际发生的"思考"。
4️⃣ 开源 vs 闭源 —— AI 的"开放程度"
🔒 闭源模型 = 黑盒子
像 ChatGPT、Claude、Gemini 这些:
✅ 优点:开箱即用,不用折腾,通常效果更好 ❌ 缺点:你不知道它怎么工作的,数据要传到对方服务器,不能自己修改
🔓 开源模型 = 透明盒子
像 Llama、Qwen、DeepSeek、Mistral 这些:
✅ 优点: 可以免费下载到自己电脑/服务器上运行 数据不用外传,隐私更安全 可以自己修改、微调、二次开发 社区活跃,有很多衍生版本 ❌ 缺点:需要自己部署,有一定技术门槛
📊 主流开源 vs 闭源模型
| 闭源 | ||
| 开源 | ||
| 国产开源 |
💡 一句话总结
开源 = 代码和模型权重公开,可以自己下载使用;闭源 = 只能用API,看不到内部。各有优劣,看场景选择。
5️⃣ 量化(Quantization)—— 让大模型"瘦身"
🎒 类比:行李箱的压缩打包
想象你要出门旅行:
原本带一个 28寸大行李箱(能装,但笨重) 量化 = 把衣服真空压缩,换成 20寸登机箱(轻便了,但能装的东西差不多)
AI 模型的量化就是这个原理:
原本模型用 32位浮点数存储参数(精度高,但占内存大) 量化后改成 16位、8位甚至 4位(精度略有损失,但体积大幅缩小)
📉 常见量化精度
BF16是 Google 提出的一种 16位格式,比 FP16 更稳定,现在很常用。
🎯 量化的好处
- 省显存
:70B 模型原本需要 140GB 显存,量化后可能只要 40GB - 跑得更快
:计算量减少,响应速度提升 - 能在普通设备上跑
:甚至能在手机、树莓派上运行小模型
⚠️ 量化的代价
精度会有一定损失,但现代量化技术(如 GPTQ、AWQ、GGUF)已经能做到"几乎感觉不到差异"。
💡 一句话总结
量化 = 用更低的数字精度存储模型参数,让大模型"瘦身",能在更小的设备上运行。
本期总结:一个表记住五个概念
再看一遍那条新闻:
"Meta 发布了 Llama 3.1405B开源模型,采用BF16 量化方案,支持多模态输入,推理成本降低 40%……"
现在你懂了:
405B = 4050亿参数的大模型 开源 = 可以免费下载使用 BF16 量化 = 用16位精度存储,省显存 多模态 = 能处理图片、文字等多种输入 推理成本降低 = 回答问题更省算力、更便宜
💬 互动时间
来做个小测试,看你记住了多少:
1. 你想在手机上本地运行一个AI助手,不需要联网,应该选什么类型的模型?
- A. 闭源大模型
- B. 开源且量化过的小模型 ✅
2. 为什么同样的模型,BF16版本比FP32版本跑得更快?
- A. 因为BF16是更好的品牌
- B. 因为量化后计算量减少了 ✅
3. GPT-4V 里的 "V" 代表什么?
- A. Very good
- B. Vision(视觉),表示支持多模态 ✅
评论区告诉我,你答对了几道?还有哪些概念想深入了解?
下期预告 🔮
基础概念扫盲还没结束!
下一期:Prompt 工程进阶——从"随便说话"到"精准控制AI"
我们会深入讲:
什么是 CoT(思维链)?为什么能让AI更聪明? Few-shot 提示是什么? 怎么给AI设定"角色"让它回答更专业?
Prompt 写得好,AI 效果能差10倍,这期别错过!
*「搞懂AI」系列 · 每周更新 · 关注不迷路*。
是新朋友吗?记得先点蓝字关注我哦~
点“在看”给我一朵小黄花

