夜雨聆风
夜雨聆风目标
输入一段分享文案、短链或作品链接,输出:
• 作品基础信息 • 作者信息 • 点赞 / 收藏 / 评论 / 分享数据 • 图片下载地址 • 视频下载地址 • 动图视频流地址
核心链路:
输入文本-> 提取候选链接-> 短链还原为真实链接-> 抓取作品页 HTML-> 提取 window.__INITIAL_STATE__-> 筛出 noteData-> 生成结构化详情-> 返回前端使用解析逻辑
提取候选链接
输入通常不是纯 URL,而是一整段分享口令,需要先从文本中提取链接。
支持的链接类型:
• xhslink.com/...• www.xiaohongshu.com/explore/...• www.xiaohongshu.com/discovery/item/...• www.xiaohongshu.com/user/profile/...
示例:
const LINK_REGEX = /(?:https?:\/\/)?www\.xiaohongshu\.com\/explore\/[^\s"'<>\\^`{|},。;!?、【】《》]+/gi;const SHARE_REGEX = /(?:https?:\/\/)?www\.xiaohongshu\.com\/discovery\/item\/[^\s"'<>\\^`{|},。;!?、【】《》]+/gi;const SHORT_REGEX = /(?:https?:\/\/)?xhslink\.com\/[^\s"'<>\\^`{|},。;!?、【】《》]+/gi;function normalizeWebUrl(url) { return url.startsWith("http://") || url.startsWith("https://") ? url : `https://${url}`;}function extractCandidateLinks(text) { if (!text?.trim()) return []; const matches = [ ...Array.from(text.matchAll(SHORT_REGEX), (m) => normalizeWebUrl(m[0])), ...Array.from(text.matchAll(SHARE_REGEX), (m) => normalizeWebUrl(m[0])), ...Array.from(text.matchAll(LINK_REGEX), (m) => normalizeWebUrl(m[0])), ]; return [...new Set(matches)];}还原短链
如果提取到的是 xhslink.com 短链,不能直接解析,需要先跟随跳转拿到真实地址。
示例:
async function request(url, options = {}) { const response = await fetch(url, { headers: { accept: "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8", referer: "https://www.xiaohongshu.com/explore", "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36", ...(options.cookie ? { cookie: options.cookie } : {}), }, redirect: "follow", cache: "no-store", }); if (!response.ok) { throw new Error(`Request failed: ${response.status}`); } return response;}async function resolveUrl(url, options = {}) { const response = await request(url, options); return response.url;}提取真实链接:
async function extractLinks(text, options = {}) { const candidates = extractCandidateLinks(text); const links = []; for (const candidate of candidates) { const link = /xhslink\.com/i.test(candidate) ? await resolveUrl(candidate, options) : candidate; links.push(link); } return [...new Set(links)];}抓取 HTML
拿到真实作品链接后,直接请求页面 HTML。
示例:
async function fetchText(url, options = {}) { const response = await request(url, options); return response.text();}抓 HTML 的关键不是库,而是请求头:
• User-Agent• Referer• 可选 cookie
提取 window.__INITIAL_STATE__
作品详情通常在页面脚本里的 window.__INITIAL_STATE__ 中。
第一步:找到脚本。
const SCRIPT_REGEX = /<script\b[^>]*>([\s\S]*?)<\/script>/gi;function extractInitialStateScript(html) { if (!html) return ""; let matchedScript = ""; let match; while ((match = SCRIPT_REGEX.exec(html)) !== null) { const script = match[1]?.trim() ?? ""; if (script.startsWith("window.__INITIAL_STATE__")) { matchedScript = script; } } return matchedScript;}第二步:把脚本对象还原成可读取对象。
import vm from "node:vm";function evaluateInitialState(script) { if (!script) return {}; const cleaned = script .replace(/^window\.__INITIAL_STATE__\s*=\s*/, "") .replace(/;+\s*$/, "") .trim(); if (!cleaned || (!cleaned.startsWith("{") && !cleaned.startsWith("["))) { return {}; } try { return vm.runInNewContext(`(${cleaned})`, Object.create(null), { timeout: 1000, }); } catch { return {}; }}从初始状态中筛出作品数据
不同页面结构下,作品数据路径可能不同,常见是 PC 和手机两套结构。
示例:
const PC_KEYS_LINK = ["note", "noteDetailMap", "[-1]", "note"];const PHONE_KEYS_LINK = ["noteData", "data", "noteData"];function deepGet(input, keys, defaultValue = undefined) { let current = input; for (const key of keys) { if (current == null) return defaultValue; if (/^\[-?\d+\]$/.test(key)) { const index = Number.parseInt(key.slice(1, -1), 10); current = Array.isArray(current) ? current.at(index) : Object.values(current).at(index); continue; } current = current[key]; } return current ?? defaultValue;}function filterNoteData(payload) { const phone = deepGet(payload, PHONE_KEYS_LINK, null); if (phone && typeof phone === "object") return phone; const pc = deepGet(payload, PC_KEYS_LINK, null); if (pc && typeof pc === "object") return pc; return {};}function parseNoteDataFromHtml(html) { const script = extractInitialStateScript(html); const payload = evaluateInitialState(script); return filterNoteData(payload);}安全提取字段
第三方结构不稳定,字段提取不要写死。
示例:
function safeExtract(input, path, defaultValue) { if (!path) return input ?? defaultValue; const segments = path.split("."); let current = input; for (const segment of segments) { if (current == null) return defaultValue; const match = /^(?<key>[^\[]+)(?:\[(?<index>-?\d+)\])?$/.exec(segment); if (!match?.groups?.key || typeof current !== "object") { return defaultValue; } current = current[match.groups.key]; if (match.groups.index != null) { const index = Number.parseInt(match.groups.index, 10); current = Array.isArray(current) ? current.at(index) : Object.values(current ?? {}).at(index); } } return current ?? defaultValue;}恢复 URL 转义
很多资源地址不是直接可用 URL,而是带转义字符,需要还原。
示例:
function decodeEscapedUrl(url) { return url .replace(/\\u([\da-fA-F]{4})/g, (_, code) => String.fromCharCode(Number.parseInt(code, 16)) ) .replace(/\\x([\da-fA-F]{2})/g, (_, code) => String.fromCharCode(Number.parseInt(code, 16)) ) .replace(/\\\//g, "/");}识别作品类型
作品类型直接决定后面走图片逻辑还是视频逻辑。
示例:
function classifyWork(noteData) { const type = safeExtract(noteData, "type", ""); const imageList = safeExtract(noteData, "imageList", []); if (!["video", "normal"].includes(type) || imageList.length === 0) { return "未知"; } if (type === "video") { return imageList.length === 1 ? "视频" : "图集"; } return "图文";}提取图片资源
图片资源处理分两步:
1. 从原始图片 URL 中提取 token 2. 根据 token 重建下载地址
示例:
function extractImageToken(url) { if (!url) return ""; const raw = url.split("!")[0] ?? ""; try { const parsed = new URL(raw); const parts = parsed.pathname.split("/").filter(Boolean); return parts.join("/"); } catch { return raw.replace(/^https?:\/\/[^/]+\//, ""); }}function buildImageUrl(token, imageFormat) { if (imageFormat === "auto") { return `https://sns-img-bd.xhscdn.com/${token}`; } return `https://ci.xiaohongshu.com/${token}?imageView2/format/${imageFormat}`;}function stripShareTokenParams(url) { return url .replace(/([?&])xsec_token=[^&#]*/gi, "$1") .replace(/([?&])xsec_source=[^&#]*/gi, "$1") .replace(/\?&/g, "?") .replace(/&&+/g, "&") .replace(/[?&]($|#)/, "$1");}function cleanDownloadUrl(url, imageFormat) { const decoded = decodeEscapedUrl(url); return stripShareTokenParams(decoded);}function extractImageLinks(noteData, imageFormat) { const imageList = safeExtract(noteData, "imageList", []); const tokens = imageList .map((item) => extractImageToken(safeExtract(item, "urlDefault", ""))) .filter(Boolean); return { downloadUrls: tokens.map((token) => cleanDownloadUrl(buildImageUrl(token, imageFormat), imageFormat) ), liveUrls: imageList.map((item) => { const value = safeExtract(item, "stream.h264[0].masterUrl", ""); return value ? decodeEscapedUrl(value) : null; }), };}说明:
• downloadUrls是静态图片地址• liveUrls是动态图对应的视频流地址
提取视频资源
视频资源通常有多档流,不能随便取第一条。
支持的优选策略:
• resolution• bitrate• size
示例:
function extractVideoLinks(noteData, preference = "resolution") { const originVideoKey = safeExtract(noteData, "video.consumer.originVideoKey", ""); if (originVideoKey) { return [decodeEscapedUrl(`https://sns-video-bd.xhscdn.com/${originVideoKey}`)]; } const h264 = safeExtract(noteData, "video.media.stream.h264", []); const h265 = safeExtract(noteData, "video.media.stream.h265", []); const items = [...h264, ...h265]; if (items.length === 0) return []; items.sort((left, right) => { switch (preference) { case "bitrate": return (left.videoBitrate ?? 0) - (right.videoBitrate ?? 0); case "size": return (left.size ?? 0) - (right.size ?? 0); case "resolution": default: return (left.height ?? 0) - (right.height ?? 0); } }); const target = items.at(-1); const backupUrl = target?.backupUrls?.[0]; const masterUrl = target?.masterUrl; return [decodeEscapedUrl(backupUrl ?? masterUrl ?? "")].filter(Boolean);}生成结构化结果
最终输出不要直接把原始 noteData 返回前端,应该转成稳定结构。
示例:
function extractDetailData(noteData, sourceUrl, imageFormat, videoPreference) { if (!noteData || Object.keys(noteData).length === 0) return null; const noteId = safeExtract(noteData, "noteId", ""); if (!noteId) return null; const type = classifyWork(noteData); const detail = { id: noteId, url: sourceUrl || `https://www.xiaohongshu.com/explore/${noteId}`, title: safeExtract(noteData, "title", ""), desc: safeExtract(noteData, "desc", ""), type, authorName: safeExtract(noteData, "user.nickname", "") || safeExtract(noteData, "user.nickName", ""), authorId: safeExtract(noteData, "user.userId", ""), authorUrl: "", likedCount: safeExtract(noteData, "interactInfo.likedCount", -1), collectedCount: safeExtract(noteData, "interactInfo.collectedCount", -1), commentCount: safeExtract(noteData, "interactInfo.commentCount", -1), shareCount: safeExtract(noteData, "interactInfo.shareCount", -1), tags: safeExtract(noteData, "tagList", []) .map((item) => safeExtract(item, "name", "")) .filter(Boolean), downloadUrls: [], liveUrls: [], }; detail.authorUrl = detail.authorId ? `https://www.xiaohongshu.com/user/profile/${detail.authorId}` : ""; if (type === "视频") { detail.downloadUrls = extractVideoLinks(noteData, videoPreference); detail.liveUrls = [null]; } else if (type === "图文" || type === "图集") { const media = extractImageLinks(noteData, imageFormat); detail.downloadUrls = media.downloadUrls; detail.liveUrls = media.liveUrls; } return detail;}详情接口
请求方式
POST /api/detail请求参数
{ "url": "分享文案、短链或作品链接", "imageFormat": "jpeg", "videoPreference": "resolution", "cookie": "可选", //有cookie可以让资源更清晰 "index": [1, 3]}参数说明:
url | ||
imageFormat | auto / png / webp / jpeg / heic / avif | |
videoPreference | resolution / bitrate / size | |
cookie | ||
index |
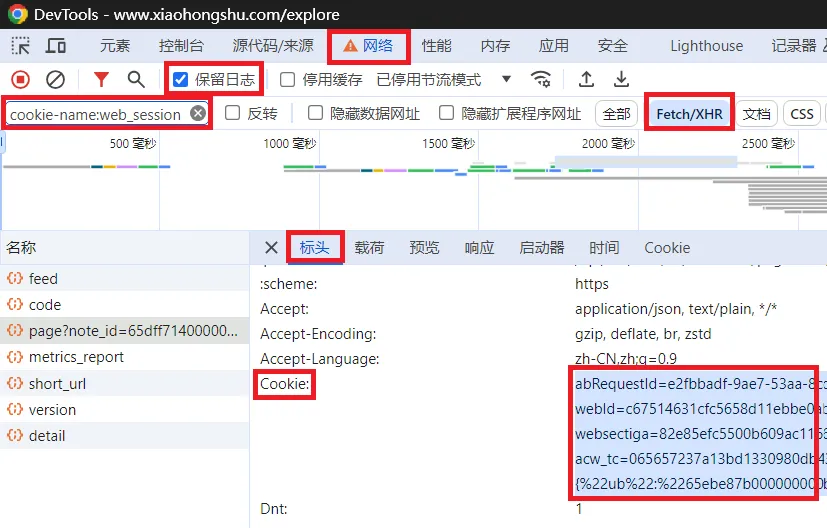
cookie 获取:
1. 打开浏览器(可选无痕模式启动),访问 https://www.xiaohongshu.com/explore2. 登录小红书账号(可跳过) 3. 按下 F12打开开发人员工具4. 选择 网络选项卡5. 勾选 保留日志6. 在 过滤输入框输入cookie-name:web_session7. 选择 Fetch/XHR筛选器8. 点击小红书页面任意作品 9. 在 网络选项卡选择任意数据包(如果无数据包,重复步骤7)10. 全选复制 Cookie 写入程序或配置文件
返回结构
{ "message": "success", "params": { "url": "..." }, "data": { "id": "作品ID", "url": "作品链接", "title": "标题", "desc": "描述", "type": "图文", "authorName": "作者昵称", "authorId": "作者ID", "authorUrl": "作者主页", "likedCount": 123, "collectedCount": 45, "commentCount": 9, "shareCount": 2, "tags": ["标签1", "标签2"], "downloadUrls": ["https://..."], "liveUrls": ["https://..."] }}接口实现
export async function getDetail(params) { const links = await extractLinks(params.url, params); if (links.length === 0) { return { message: "提取链接失败", params, data: null }; } const html = await fetchText(links[0], params); const noteData = parseNoteDataFromHtml(html); let detail = extractDetailData( noteData, links[0], params.imageFormat ?? "jpeg", params.videoPreference ?? "resolution" ); if (detail && Array.isArray(params.index) && params.index.length > 0) { const indexes = params.index .map((value) => Number.parseInt(String(value), 10)) .filter((value) => Number.isInteger(value) && value > 0); detail = { ...detail, downloadUrls: indexes.map((index) => detail.downloadUrls[index - 1]).filter(Boolean), liveUrls: indexes.map((index) => detail.liveUrls[index - 1] ?? null), }; } return { message: detail ? "success" : "failed", params, data: detail, };}调用示例
最常用请求:
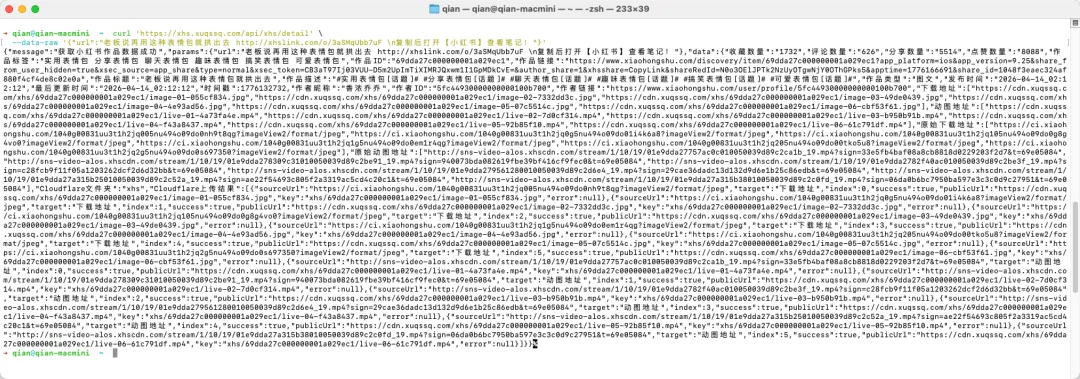
curl -X POST https://xhs.xuqssq.com/api/xhs/detail \ -H "Content-Type: application/json" \ -d '{ "url": "老板说再用这种表情包就拱出去 http://xhslink.com/o/3aSMqUbb7uF \n复制后打开【小红书】查看笔记!" }'只返回第 1 和第 3 张图:
curl -X POST https://xhs.xuqssq.com/api/xhs/detail \ -H "Content-Type: application/json" \ -d '{ "url": "老板说再用这种表情包就拱出去 http://xhslink.com/o/3aSMqUbb7uF \n复制后打开【小红书】查看笔记!", "index": [1, 3] }'带 Cookie 抓取:
curl -X POST https://xhs.xuqssq.com/api/xhs/detail \ -H "Content-Type: application/json" \ -d '{ "url": "老板说再用这种表情包就拱出去 http://xhslink.com/o/3aSMqUbb7uF \n复制后打开【小红书】查看笔记!", "cookie": "a1=...; web_session=..." }'GIF 转换
动态图通常拿到的是 MP4/H264 流,不是 GIF 文件。如果前端需要“下载 GIF”,就要本地转码。
转换参数
const GIF_MAX_DURATION_SECONDS = 10;const GIF_FPS = 12;const GIF_WIDTH = 320;const GIF_MAX_COLORS = 128;转换流程
拉取视频 Blob-> video 加载元数据-> 逐帧 seek-> canvas 绘制帧-> gif 编码-> 输出 Blob-> 下载核心代码
function loadVideo(blob) { return new Promise((resolve, reject) => { const video = document.createElement("video"); const objectUrl = URL.createObjectURL(blob); video.preload = "auto"; video.muted = true; video.playsInline = true; video.src = objectUrl; const cleanup = () => { video.removeAttribute("src"); video.load(); URL.revokeObjectURL(objectUrl); }; video.onloadedmetadata = () => resolve({ video, cleanup }); video.onerror = () => { cleanup(); reject(new Error("Video metadata load failed")); }; });}function seekVideo(video, time) { return new Promise((resolve, reject) => { const handleSeeked = () => { video.removeEventListener("seeked", handleSeeked); video.removeEventListener("error", handleError); resolve(); }; const handleError = () => { video.removeEventListener("seeked", handleSeeked); video.removeEventListener("error", handleError); reject(new Error("Video seek failed")); }; video.addEventListener("seeked", handleSeeked, { once: true }); video.addEventListener("error", handleError, { once: true }); video.currentTime = time; });}逐帧编码:
for (let frameIndex = 0; frameIndex < totalFrames; frameIndex += 1) { const currentTime = Math.min(frameIndex / GIF_FPS, Math.max(duration - 0.001, 0)); await seekVideo(video, currentTime); context.drawImage(video, 0, 0, width, height); const { data } = context.getImageData(0, 0, width, height); const palette = quantize(data, GIF_MAX_COLORS, { format: "rgb444" }); const indexedFrame = applyPalette(data, palette, "rgb444"); gif.writeFrame(indexedFrame, width, height, { palette, delay: frameDelay, });}GIF不限制时长、宽度和帧率,浏览器会明显变卡。
在线体验地址
地址:https://xhs.xuqssq.com
接口调用,可随意调用
curl 'https://xhs.xuqssq.com/api/xhs/detail' \ --data-raw '{"url":"老板说再用这种表情包就拱出去 http://xhslink.com/o/3aSMqUbb7uF \n复制后打开【小红书】查看笔记!"}'