 夜雨聆风
夜雨聆风
如果你也在愁临床数据稀缺、样本量有限、传统增强方法易破坏医学特征一致性,不如换个思路,用DALL-M框架的上下文感知临床数据增强(LLM+RAG+专家知识)杀出重围!它通过检索增强生成(RAG) 整合放射学报告与权威医学资源(如Radiopaedia),用大语言模型(LLM)生成合成数据与新特征(将原始9维临床特征扩展至91维),让机器学习模型性能(如XGBoost的F1-score提升16.5%、精确率/召回率提升25%)大幅跃升,为数据受限的医疗AI场景提供可扩展解决方案。
你的课题是否适合用“上下文感知增强+领域知识锚定” 类似思路突破数据瓶颈?欢迎咨询评估~

中文标题:DALL-M:基于上下文感知的临床数据增强,利用大型语言模型
发表期刊:Computers in Biology And Medicine
发表时间:2025年5月
影响因子:6.3/Q2

研究空白:
传统方法无法捕捉特征间依赖(如人工提高心率却不调整呼吸频率);
合成过采样不引入新知识,仅重复现有数据;
缺乏结合领域知识(如放射学报告、权威医学资源)的上下文感知增强框架。
核心目标:提出DALL-M框架,利用大语言模型(LLM)的推理能力,结合检索增强生成(RAG)和专家知识,生成临床一致的合成数据与新特征,提升医疗预测模型性能。

1. 三阶段框架
Phase I:临床上下文提取与存储
输入:患者胸部X线病变标签(来自REFLACX数据集,如“胸腔积液”)。
过程:用RAG框架从Radiopaedia(放射学专业数据库)和Wikipedia检索病变相关知识(症状、病因、诊断指标),通过Neo4j向量数据库存储语义关联(优于NetworkX、Neo4j图数据库)。
输出:结构化临床知识图谱(如“胸腔积液”关联“呼吸困难”“心力衰竭”等)。
Phase II:专家输入查询与提示生成
专家知识整合:访谈2名资深放射科医生(8-15年经验),提炼诊断推理模式,形成结构化查询模板(如“{病变}的常见症状是什么?”“{病变}的潜在病因有哪些?”)。
动态提示生成:将病变标签代入模板,用RAG检索Phase I的知识图谱,生成增强临床知识(ACK)语料库(含症状、体征、实验室数据等)。
Phase III:上下文感知特征增强
新特征生成:用LLM(如GPT-4)的少样本学习能力,从ACK语料库中识别新临床特征(如“颈静脉怒张”“呼吸音减弱”)。
特征值赋值:结合患者影像报告、人口统计信息、域知识库,用RAG生成特征值(如“65岁患者胸腔积液→颈静脉怒张=是”)。
输出:增强数据集(原始9特征→扩展至91特征)。
2. 实验设计
数据集:MIMIC-IV的799例患者(含胸部X线、放射学报告、临床数据),标注5种常见病变(肺不张、实变、心脏增大、胸腔积液、胸膜异常)。
评估假设:
H1:LLM能否生成现有特征的临床相关值?(对比GPT-4、BioGPT等9种模型,用MSE衡量偏差);
H2:LLM能否生成新特征并提升模型性能?(对比原始特征、增强特征(78维)、专家输入增强特征(91维))。
下游模型:决策树、随机森林、XGBoost、TabNet,评估指标包括准确率、AUC、精确率、召回率、F1-score。
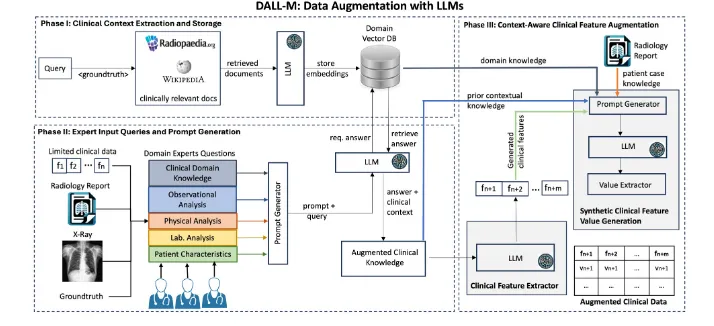
图1 使用大型语言模型生成临床相关特征的DALL-M框架概述

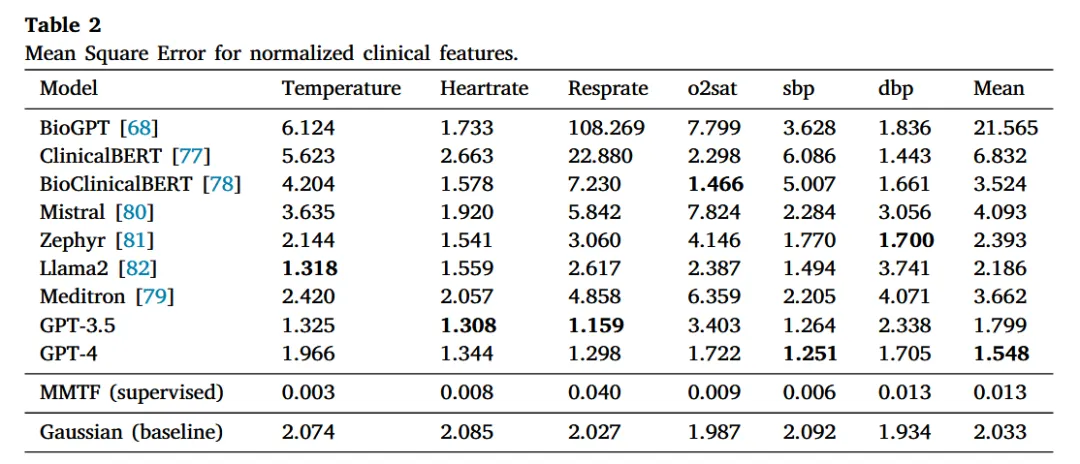
模型对比:GPT-4表现最优(平均MSE=1.548),显著优于高斯基线(2.033)和医学专用模型(如BioClinicalBERT的3.524)(见表2)。
关键发现:通用LLM(GPT-4)因训练数据多样性优于领域专用LLM(如BioGPT),且温度参数设为0.1时可减少幻觉(高温度易生成无关症状)。

图2.实验I中用于生成氧饱和度(%)特征值的提示示例
2. 信息检索质量(Phase I优化)
数据源与存储:结合Wikipedia+Radiopaedia、存储在Neo4j向量数据库时,LLM回答最完整(如“肺不张”症状包含“呼吸急促”“低氧饱和度”,而单一数据源或图数据库存在信息缺失)(见表3)。

3. 新特征增强效果(H2验证)
特征扩展:DALL-M将原始9特征扩展至78特征(自动生成),经专家输入后达91特征(含“麻醉史”“吸烟史”等)。
模型性能提升:
增强数据集(91特征)使XGBoost的F1-score提升16.5%,精确率/召回率提升25%(对比原始8特征);
专家输入进一步优化,随机森林精确率再增3%(见表4)。
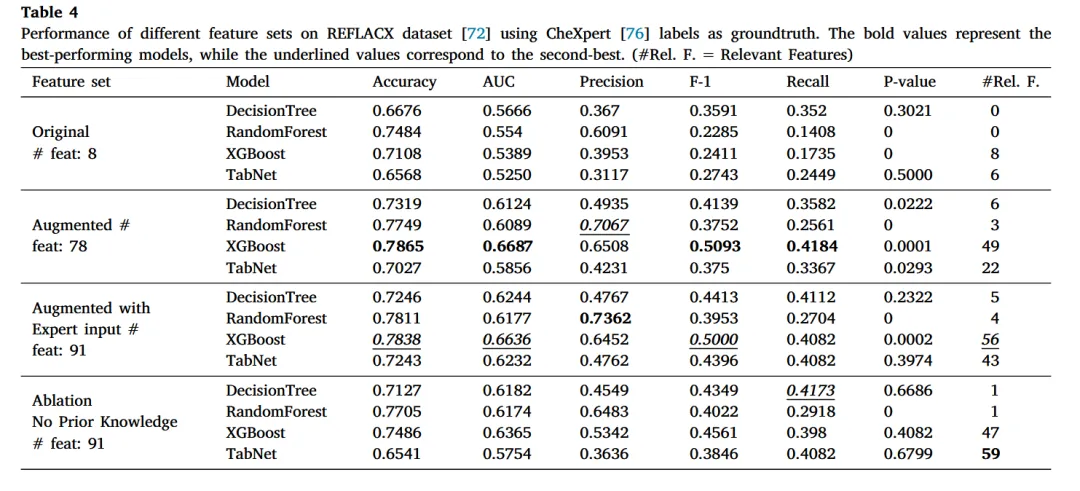
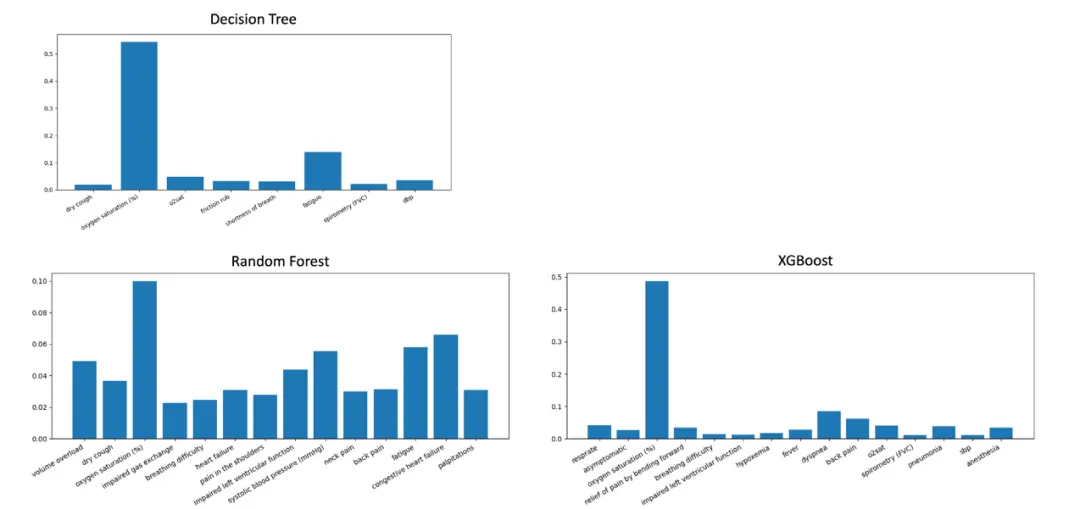
图3 使用决策树、随机森林和XGBoost的放大心脏轮廓的特征重要性分布示例
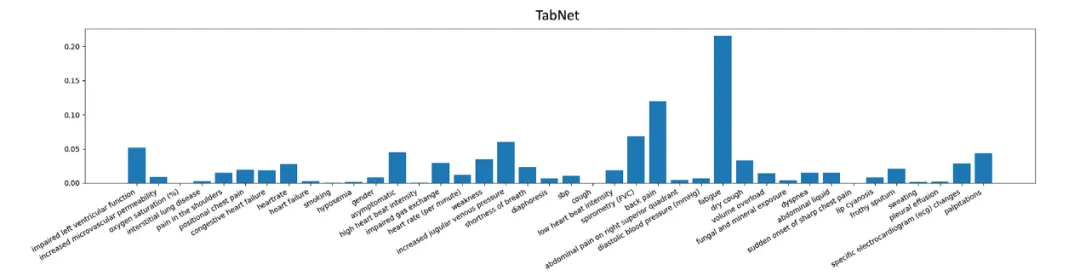
图4 使用TabNet的放大心脏轮廓的特征重要性分布示例
特征重要性:XGBoost识别49个关键特征(如“胸腔积液”“心脏增大”),与放射科医生评估相关性最高(见图5)。
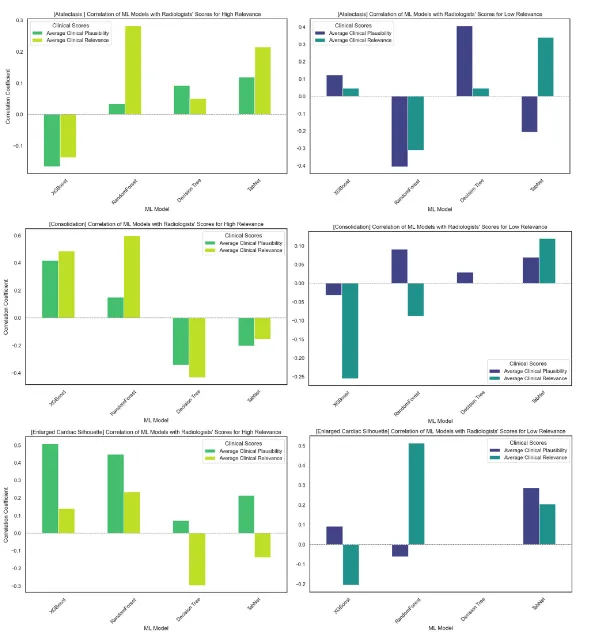
图5 机器学习模型与放射科医生高相关性和低相关性特征的临床评分的相关性
4. 消融实验与对比
ACK的必要性:移除增强临床知识(ACK)后,所有模型性能显著下降(如XGBoost的AUC从0.6636降至0.6365),证明领域知识检索是核心。
对比传统方法:DALL-M优于SMOTE(插值无新特征)、GAN(不可解释)、高斯噪声(破坏一致性),因生成上下文感知新特征(见表1对比)。

提出DALL-M框架,首个结合LLM、RAG、专家知识的临床表格数据增强方法,生成上下文感知新特征(如“颈静脉怒张”)并赋值;
实证表明:DALL-M将原始9特征扩展至91特征,使XGBoost的F1-score提升16.5%,精确率/召回率提升25%;
验证ACK(增强临床知识) 是关键,移除后性能显著下降,证明领域知识检索优于单纯提示工程。
局限与展望:
挑战:LLM幻觉风险、计算成本高(如GPT-4)、伦理合规(GDPR);
未来方向:多模态融合(影像+EHR)、偏见缓解(对抗去偏)、实时临床部署。
结论:DALL-M通过“检索-生成-验证”闭环,为数据稀缺的医疗场景提供可扩展、临床一致的增强方案,推动AI驱动的诊断模型发展。
后续协助方向:是否需要我帮你进一步解读DALL-M框架的技术细节(如RAG实现),或基于该研究设计数据增强实验方案?

