 夜雨聆风
夜雨聆风一、论文信息
从空气流动到波的传播,很多看似复杂的动态现象,背后都可以写成偏微分方程。物理信息神经网络一度让人看到“用神经网络直接解方程”的可能,但这篇论文进一步追问:如果不再依赖反复的梯度下降,能不能把这件事做得更好?
本篇推文解读的文章来自 International Conference on Learning Representations,简称 ICLR。它是机器学习与人工智能领域最具影响力的国际会议之一,长期聚焦表征学习、深度学习及相关前沿问题,在全球学界与工业界都有很高关注度。特别值得一提的是,在 2026 年发布的第七版中国计算机学会推荐国际学术会议和期刊目录中,ICLR 已被列入 CCF-A 类会议。
英文题目: Fast Training of Accurate Physics-Informed Neural Networks Without Gradient Descent
中文题目 :无需梯度下降的高精度物理信息神经网络快速训练
作者 :Chinmay Datar,Taniya Kapoor,Abhishek Chandra,Qing Sun,Erik Bolager,Iryna Burak,Anna Veselovska,Massimo Fornasier,Felix Dietrich
来源 :OpenReview,页面标注为 Oral
二、背景与贡献
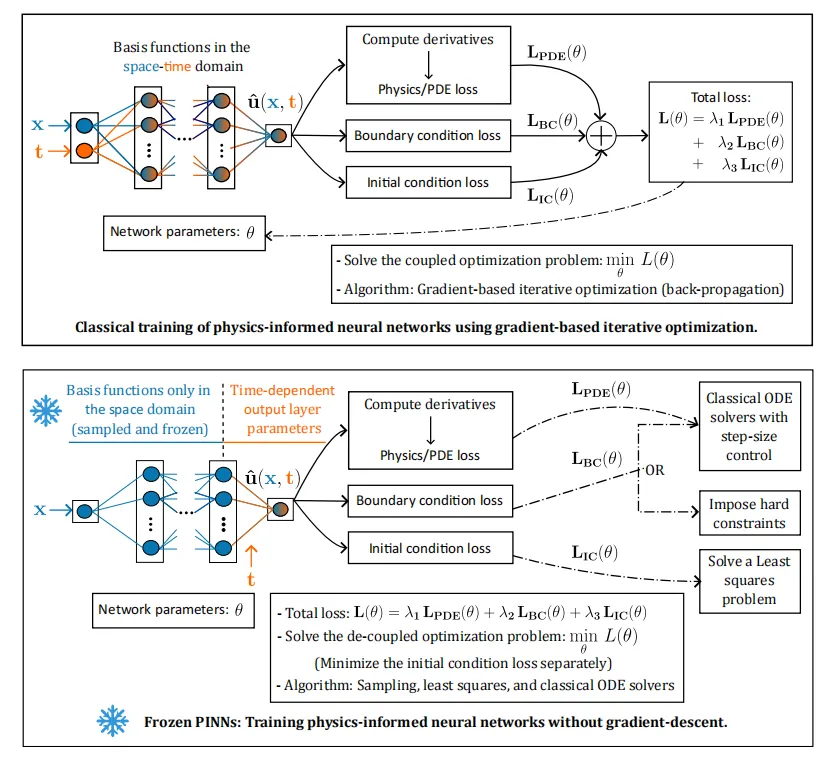
这篇文章关注的是时间依赖偏微分方程(Partial Differential Equations,PDEs)的数值求解。它把经典的物理信息神经网络(Physics-Informed Neural Networks,PINNs)重新改写成一种更接近数值分析流程的学习框架,其核心不是反复做梯度下降,而是把空间部分固定下来,再把时间部分写成常微分方程去推进。
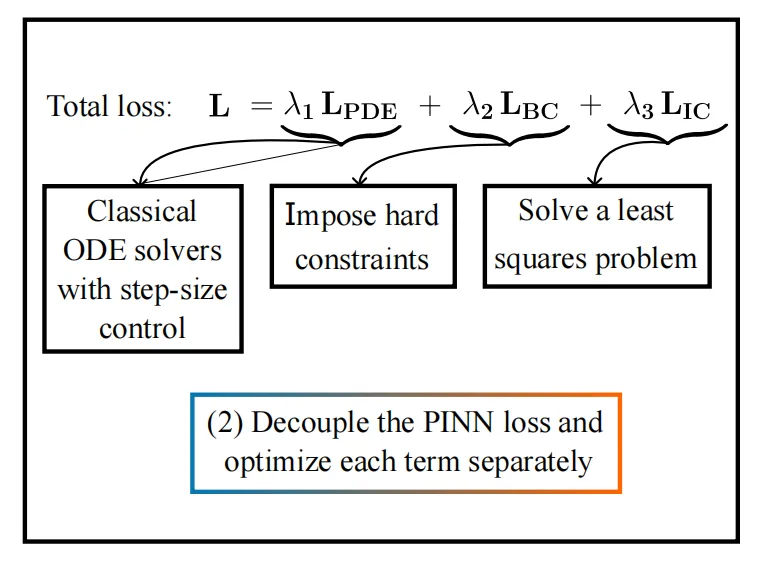
文章指出,传统 PINNs 的主要问题来自两个方面。其一是训练目标本身过于耦合。PDE 残差、初始条件、边界条件同时进入一个非凸目标函数,参数维数高,损失之间还可能互相牵制。其二是时间在很多 PINN 里被当成普通输入维度处理,没有真正体现时间推进的因果结构。这样做会让网络基函数覆盖整个时空区域,在长时间模拟、高频时间变化、激波等问题上更容易失真。
本文提出 Frozen-PINN,其贡献可以概括为三点。
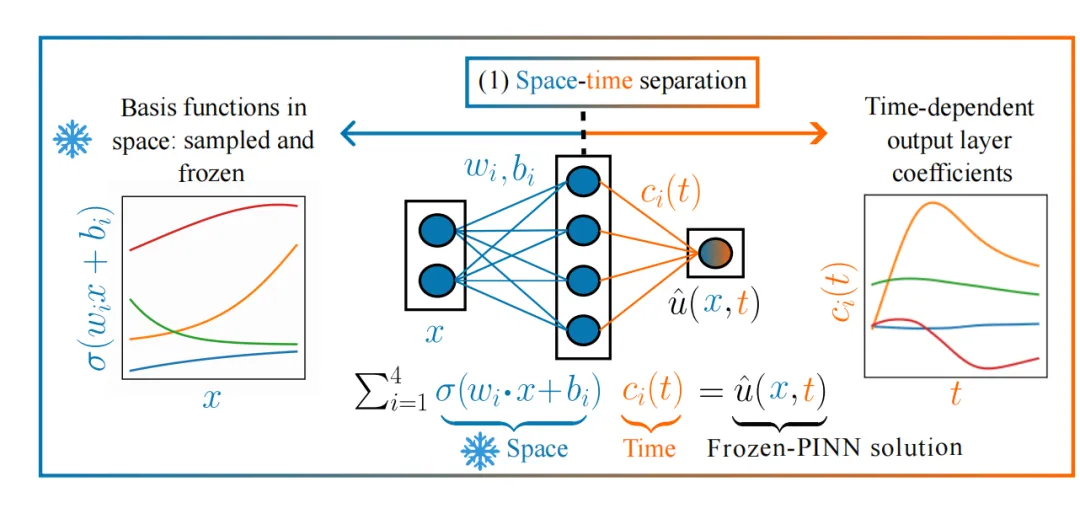
提出时空分离(space-time separation)训练思想。 空间基函数先随机采样并冻结,时间只体现在输出层系数里,从结构上保留时间因果性。
提出无梯度下降训练流程。 初值由最小二乘求解,时间演化由自适应常微分方程求解器完成,因此训练不再依赖反向传播去优化整网参数。
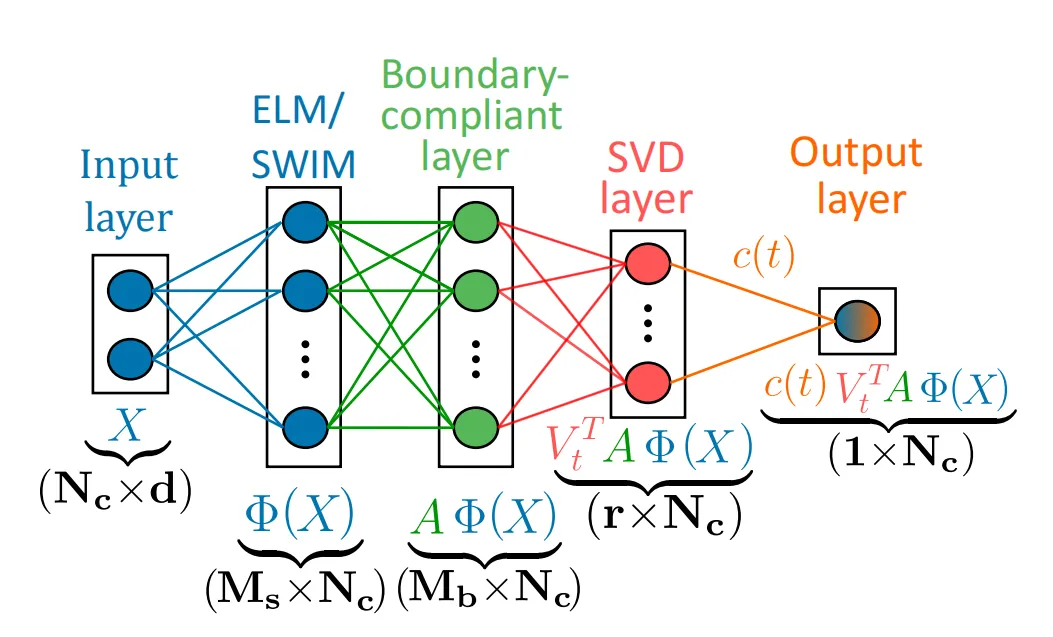
提出边界处理与压缩机制。 一方面给出边界相容层(boundary-compliant layer)与增广常微分方程两种边界处理方案,另一方面加入奇异值分解层(SVD layer)降低刚性与系统维数。
三、主要结论
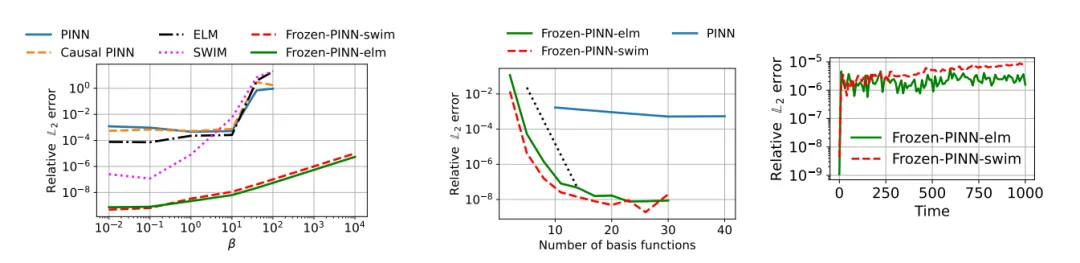
论文在九类 PDE 基准上比较了 Frozen-PINNs 与多种 PINN 变体,以及 IGA-FEM 和 FEM 等经典方法。总体上,Frozen-PINNs 在几乎所有任务上都表现出更快的训练速度与更高的精度。文中给出的结论包括:在若干基准上训练可快出 到 倍;在线性对流方程里,速度系数可增大到 ,相对 误差仍低于 ;在 的长时间模拟中,模拟到 秒时相对 误差仍低于 ;在多个高精度设定下,Frozen-PINNs 是少数能进入 到 精度区间的神经 PDE 求解器。
更细一点看,ELM 采样更适合平滑解,SWIM 采样更适合存在局部陡变和激波的解。低维问题上,Frozen-PINNs 的精度已经接近 IGA-FEM 与 FEM;高维问题上,它又保留了神经方法不依赖网格的优势。
四、方法细节
文章考虑的时间依赖 PDE 写成
其中边界条件与初始条件分别为
Frozen-PINN 的近似解写成
这里 只依赖空间并且在采样后冻结, 只依赖时间。文章特别说明,这种写法并不要求真解本身可以分离变量。
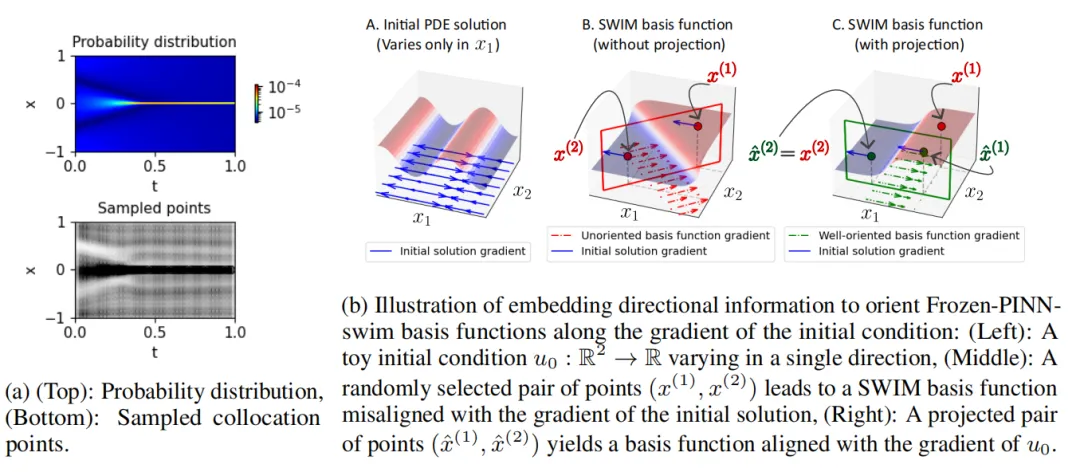
在隐藏层采样上,作者使用两种策略。极限学习机(Extreme Learning Machine,ELM)直接随机采样权重与偏置。SWIM 则利用两点 构造方向明确的基函数,其权重与偏置可写成
把上式代回 PDE 后,时间系数满足一个常微分方程
其中
而初始条件不是靠训练损失去拟合,而是直接由最小二乘给出
边界条件有两种做法。若边界形式较规则,则构造边界相容层,使边界条件在结构上成立。若几何更复杂,则采用增广常微分方程
最后,为降低系统刚性,作者对 做截断奇异值分解,得到更低维的正交基,再在该基上推进时间系数。这样既减少了 ODE 维数,也改善了条件数。
伪代码如下:

五、消融与数值实验
实验覆盖线性对流方程、Euler-Bernoulli 梁方程、波动方程、Burgers 方程、复杂区域非线性扩散、Kuramoto-Sivashinsky 方程、五维反应扩散方程以及最高到一百维的热方程。结果最值得关注的有四点。
高频时间变化与长时间模拟。 线性对流方程中,传统 PINNs 在高对流速度下明显失效,而 Frozen-PINNs 仍能保持较低误差。
激波与局部陡变。 在 Burgers 方程里,SWIM 通过重采样把陡峭基函数放到激波附近,效果明显好于 ELM 以及傅里叶和 Chebyshev 基。
复杂几何。 在树枝状区域的非线性扩散问题中,Frozen-PINNs 直接在点云上工作,省去了复杂网格构造。
高维扩展。 在十维到一百维热方程上,Frozen-PINN-elm 相比 PINNs 保持更高精度,且训练时间通常更短。
消融实验说明,SVD 截断阈值控制了速度与精度的平衡;在 Burgers 方程上,SVD 层带来约 倍宽度压缩与约 倍加速;在复杂区域非线性扩散上,Frozen-PINN-elm 的 SVD 层可把宽度压缩到原来的约 ,时间约加速 倍;在五维反应扩散问题中,利用投影后的 SWIM 基函数,只用 个内部点就能达到与 个点接近的误差水平。
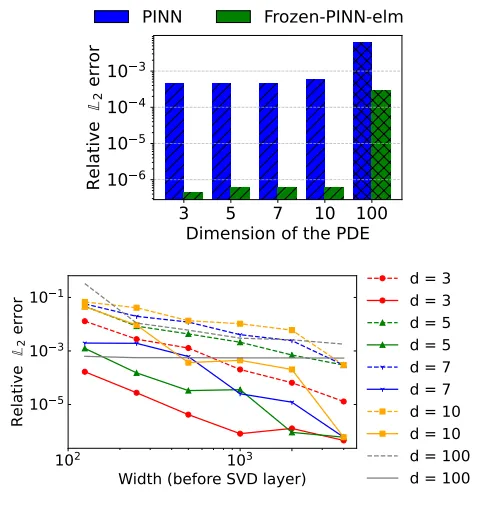
表格见原文第10页表2,照录如下:
六、我们的思考
通过学习这篇文章,我们从统计学和AI交叉的观点出发,认为这篇文章可能适合作为快速前向求解器使用。
第一,它可以直接服务于贝叶斯逆问题(Bayesian inverse problems)与不确定性量化(uncertainty quantification)。这类任务往往要反复调用 PDE 前向模型,Frozen-PINN 的快速求解特性会直接影响后验采样与变分推断的成本。
第二,它的时间推进是显式因果的,因此很适合和状态空间模型(state space models)、序贯蒙特卡洛(sequential Monte Carlo)、滤波与数据同化结合。
第三,ELM 与 SWIM 的差异提示我们,可以把基函数采样、配置点设计、SVD 截断都看成统计决策问题,进一步引入实验设计(design of experiments)和主动学习(active learning)方法。
第四,文章目前假设 PDE 已知,因此未来可以把它扩展到参数识别、模型校准、多保真近似,以及带观测噪声的概率数值计算(probabilistic numerics)中。
另外,就论文自身的后续方向而言,论文作者也指出了几条值得继续推进的路线,包括更复杂空间结构下的 Navier-Stokes 类问题、周期性重采样如何突破 Kolmogorov 宽障碍,以及在特定 PDE 设定下的逼近理论。这些问题如果和统计学习中的泛化误差、模型选择与不确定性传播联系起来,后续会更有研究空间。
本篇推文的封面、图片、表格全部来自论文原文:Fast Training of Accurate Physics-Informed Neural Networks Without Gradient Descent
