 夜雨聆风
夜雨聆风先问一个问题
你学一门新技术,一般是什么流程?
多数人的答案是:找教程 → 看视频 → 调 Demo → 收藏 → 结束。
这个流程有个致命问题:你一直在被动接收信息,从来没有主动建构过知识。
结果就是:教程看了一堆,真正要用的时候脑子一片空白。术语都认识,拼在一起就不懂了。
今天分享的方法,核心只有一句话:
不是学完再动手,而是以用促学、以测促懂。
一、为什么你看了很多教程还是不会用
知识分成三种层次:
层次 | 表现 | 你能做什么 |
|---|---|---|
知道 | 看过、听过、有印象 | 能复读、能认出来 |
会用 | 知道在什么场景用、怎么用 | 能完成特定任务 |
理解 | 能从零推导、能向别人解释 | 能迁移到新场景 |
看教程、刷视频,只能让你达到"知道"这个层次。
想从"知道"跨到"会用"甚至"理解",靠的是主动提问 + 刻意测试 + 反复修正——而不是被动输入。
二、六步学习法,完整清单照抄
下面这套方法,我从 MIT 学霸的 AI 学习框架改造而来,本人实际用于 LangChain、LlamaIndex 的学习。
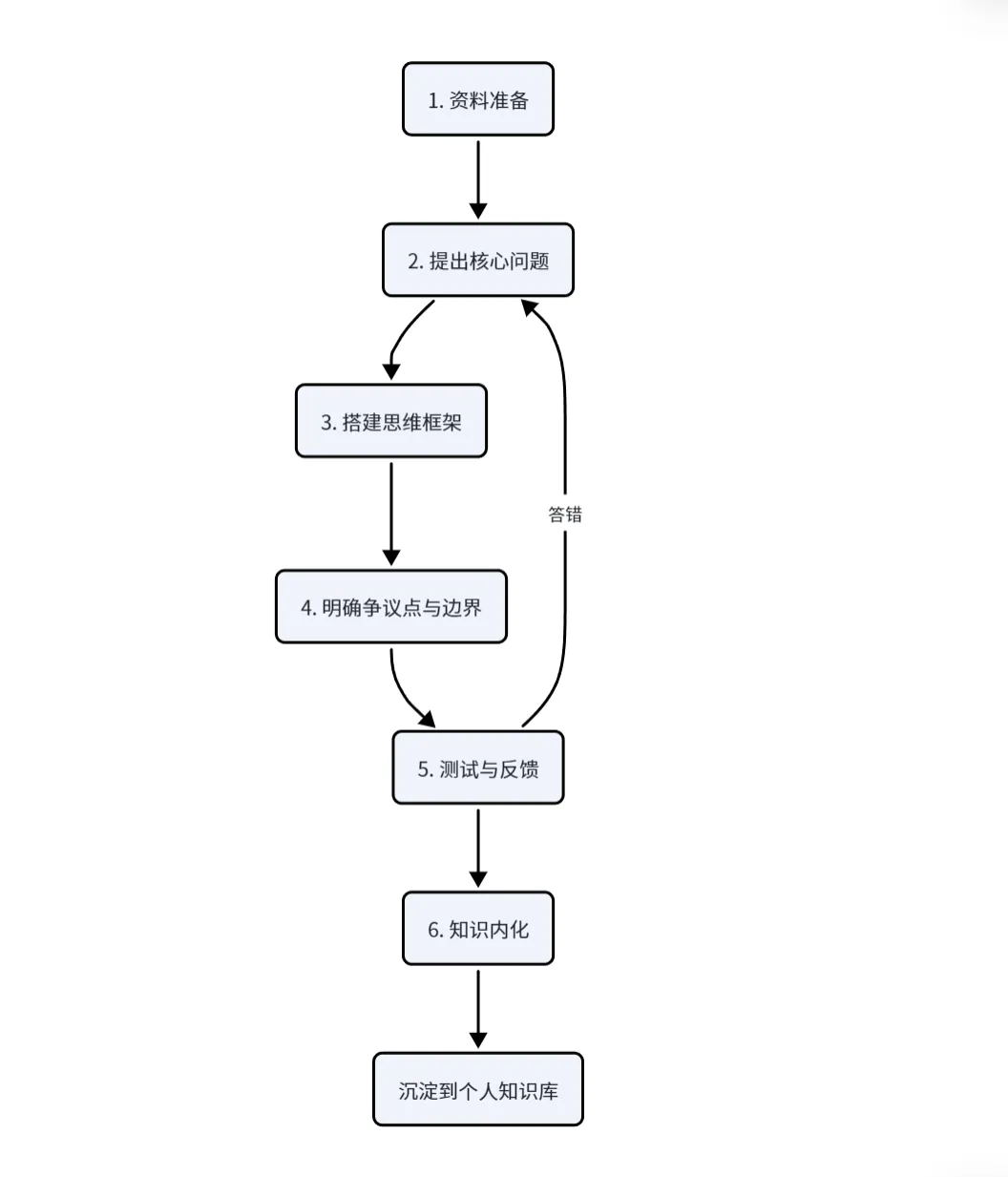
Step1:资料准备——围绕"做一件事"来组织
原则:宁精勿滥。不是"学一个领域",而是"能做一件具体的事"。
资料优先级:
优先级 | 类型 | 说明 |
|---|---|---|
P0 | 官方文档 + 快速跑通的 Demo | 最权威,能验证可行性 |
P1 | 官方教程 / Quickstart | 系统性了解全貌 |
P2 | 优质博客 / 实战案例 | 补充经验和踩坑记录 |
P3 | 论文 / 深度文章 | 理解底层原理 |
实操清单:
找到官方 Quickstart,完整跑通
把核心文档读一遍,划出"看不懂"的地方
建一个文件夹,专门放这个项目的学习资料
给每份资料标注难度等级(P0/P1/P2)
step2:提出核心问题——先问再学,带着问题去找答案
在打开任何教程之前,先逼自己用一句话回答这四个问题:
① 这个工具解决什么核心问题?
不是背定义,是用自己的话说:"它能让我在什么场景下不用写那么多代码"。
② 这个工具的核心思维模式是什么?
比如 LangChain 的核心是"把 LLM 调用封装成可组合的 Chain";LlamaIndex 的核心是"把文档组织成可高效检索的索引"。能说清楚这个,比会调 API 重要十倍。
③ 这个工具的争议点和局限在哪里?
去 GitHub Issues 或 Reddit 上搜一圈,看看用户在抱怨什么。知道它"不能做什么",比知道"能做什么"更值钱。
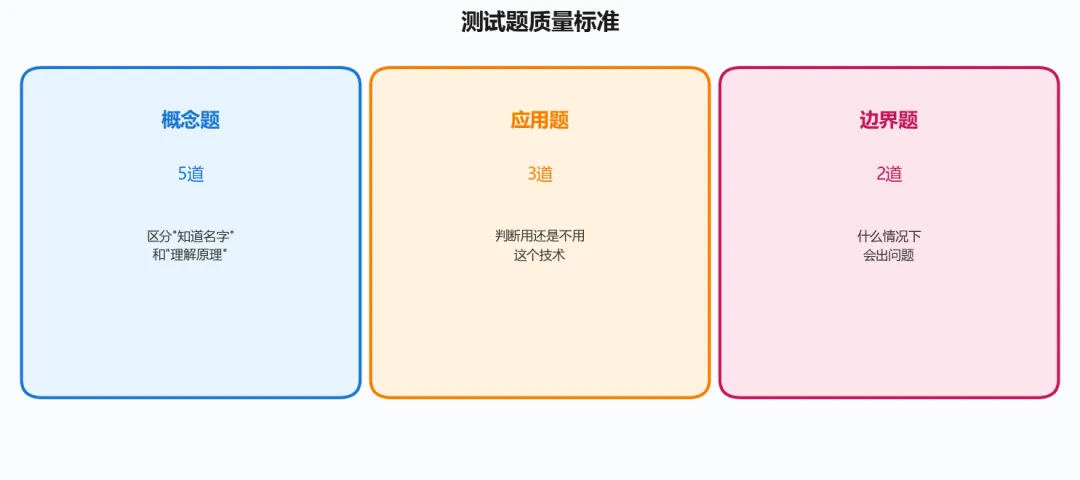
④ 我能出 10 道题检验自己是否真的理解了吗?
这步最关键——10 道题里要有:
5 道概念理解题(不是背定义,是考理解)
3 道应用判断题(什么场景用 / 不用这个工具)
2 道边界情况题(什么条件下它会出问题)
step3:搭建思维框架——让 AI 帮你提炼
把收集的资料(或者链接)丢给 AI,让它帮你提炼:
Prompt 模板:"请帮我梳理 [框架名] 的核心概念体系,用结构化方式表达,重点说明各模块之间的关系,用中文回答。"
得到框架后,自己再动手画一遍:

Step4:明确争议点和边界——知道"不能做什么"更重要
重点厘清三件事:
1. 它和同类框架的核心差异是什么?
用 AI 生成对比表:"请对比 LangChain 和 LlamaIndex 在 RAG 数据检索这个场景上的设计差异"
2. 什么场景下它的性能会下降或失效?
LangChain:大项目时 Chain 调试困难;LlamaIndex:过于专注数据索引,应用编排能力弱。
3. 社区公认的痛点是什么?
去 GitHub Stars > Issues > discussions 翻一圈,比读十篇博客有用。
Step5:测试与反馈——答错比答对更重要
这是整个方法论最核心的一步。
流程:
用第二步生成的 10 道题做自测
每道题必须给出判断依据,不能只写答案
答错的题 → 定位漏洞来源(哪个概念理解错了?)
针对漏洞追问 AI:"我在 [具体问题] 上答错了,你能帮我分析我哪里理解错了吗?"
修正理解,重新做一遍同类型题目
自测质量标准:
好的测试题,能区分"知道名字"和"理解原理":
❌ "LangChain 是什么"
✅ "LangChain 的 LCEL 解决了什么问题?它和传统 Chain 有什么不同?"
❌ "LlamaIndex 是做检索的吗"
✅ "在什么场景下我应该优先选 LlamaIndex 而不是 LangChain?"
Step6:知识内化——从零能搭出来,才算学会
合上资料,从零开始,能独立搭建完整流程,才算内化。
内化三层次:
层次 | 标准 | 说明 |
|---|---|---|
第一层 | 能跑通 Demo | 知道"怎么做" |
第二层 | 能独立搭建完整项目 | 理解"为什么这样做" |
第三层 | 能向别人解释原理 | 达到"教就是学" |
每次学习完成后必做:
整理踩坑记录(what/why/how)
写一份代码片段注释版(这份代码为什么要这么写)
把框架图手绘一遍,存到笔记里
更新自己的知识库索引
三、LangChain 和 LlamaIndex 各学多久、怎么学
作为方法论的实际案例,附上两个框架的学习路径:
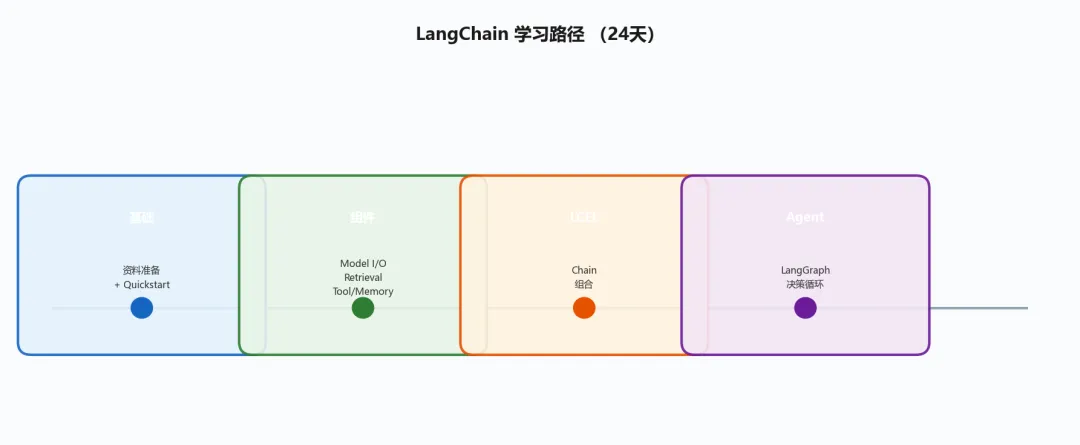
LangChain 优先学这些:
1.Model I/O(Prompt Template / Chat Model / Output Parser)
2.LCEL(LangChain Expression Language)——理解它就理解了 LangChain 一半
3.Retrieval(向量检索的核心组件)
4.Agent(ReAct 模式 + LangGraph)
LlamaIndex 优先学这些:
1.Node Parser(文档怎么切分,比用什么 Embedding 更重要)
2.VectorStoreIndex + Retriever(核心检索流程)
3.Query Engine + Synthesizer(怎么合成答案)
4.LlamaHub(80+ 数据连接器,用过的都说香)
两者关系一句话: LlamaIndex 是数据索引的专家,LangChain 是应用编排的专家。RAG 场景里,它们是互补的——LlamaIndex 负责"找对数据",LangChain 负责"把数据送进 LLM 并输出"。
四、最后说一句
方法论的东西,看完谁都觉得自己懂了。
真正的区别,在于你有没有用这套方法,认真学完一个完整的东西。
从 LangChain 或者 LlamaIndex 开始都可以,用六步法过一遍:
资料准备 → 提核心问题 → 画框架图 → 厘清边界 → 做题测试 → 内化沉淀
学完一个,你会有一种很奇怪的感觉——之前收藏夹里那些"以后再学"的东西,突然就觉得没那么难了。
因为你已经在主动构建,而不是被动接收了。
延伸阅读:
LangChain 官方文档:https://python.langchain.com/docs/
LlamaIndex 官方文档:https://docs.llamaindex.ai/
