 夜雨聆风
夜雨聆风AI智能体|生产部署|避坑指南
痛点:从本地跑通到线上崩盘,只缺1个配置;从数据泄露到挖矿入侵,只漏1个开关。通过这十个坑的剖析,帮你省下1个月排坑时间。

在AI智能体落地浪潮里,OpenClaw凭借ContextEngine插件化架构,成为不少团队搭建私有AI助理、企业智能体的首选方案。
但真正把OpenClaw从本地测试,推向生产环境、承载真实业务流量后才发现:官方文档的极简部署流程,全是理想状态;生产环境里的每一个坑,都能让服务直接崩盘。
从内存溢出、服务卡死,到数据泄露、依赖冲突,再到长对话失忆、API全面报错,每一个雷区都是血泪的教训。
本篇从生产环境出发真实对踩坑复盘,10个高频致命问题+可直接落地的解决方案,看完少走弯路。
01 🔓 默认配置裸奔上线,数据安全毫无保障
踩坑现象
对话记录、上传的业务文件全程明文存储,多用户使用时数据完全不隔离,日志直接打印敏感Prompt、API密钥,稍有排查就会造成核心数据泄露,完全不符合生产安全规范。
问题根源
开发模式默认兼顾易用性,所有安全加密、权限隔离开关全部关闭,仅适合本地调试,绝不能直接用于生产。
避坑方案(直接复制配置)
启用多租户隔离:userIsolation.mode=tenant
日志敏感数据脱敏:log.pii.mask=true
02 💽 记忆引擎无清理策略,磁盘极速爆满
踩坑现象
服务运行一段时间后,SQLite数据库、向量库文件体积疯狂暴涨,检索速度直线下降,最终触发OOM内存溢出,服务直接卡死重启,历史对话数据无法清理。
问题根源
默认启用lossless-claw无损记忆插件,只做数据存储,不做自动回收,长期累积直接拖垮服务器资源。
避坑方案(直接执行命令)
openclaw config set contextEngine.autoPurgeDays 7
# 限制最大上下文存储条数
openclaw config set contextEngine.maxContextCount 5000
03 🧩 技能盲目安装,引发依赖与端口冲突
踩坑现象
随意安装各类技能插件后,出现服务启动失败、WebUI正常但功能报错500、GPU进程僵死无法释放,不同技能互相干扰,无法正常运行。
问题根源
不同技能依赖不同版本的PyTorch、FastAPI等环境库,同时占用相同端口,导致依赖冲突、资源抢占。
避坑方案
仅安装官方认证、Security Scan=Benign的高星技能
同类功能技能只保留一个,杜绝重复安装
部署前执行clawhub check完成依赖检测,无冲突再上线
04 🚪 网关公网暴露未鉴权,被恶意刷流
踩坑现象
服务上线后莫名出现流量暴增,GPU占用率长期100%,自身业务无法正常使用,日志出现大量陌生非法请求,甚至遭遇挖矿程序入侵。
问题根源
默认网关鉴权模式为gateway.auth.mode=none,无任何访问限制,公网直接暴露后极易被恶意调用。
避坑方案(直接复制配置)
gateway.token=自定义高强度随机密钥
05 🧠 长文本+无损记忆,显存直接爆炸
踩坑现象
上传长文档、进行多轮深度对话后,GPU显存瞬间占满且不自动释放,推理速度从秒级变为分钟级,严重时直接导致服务崩溃重启。
问题根源
无损记忆引擎会将全文内容全量加载至上下文,大幅消耗显存,无任何分片与压缩机制。
避坑方案(直接复制配置)
限制输入:maxInputTokens=8192
开启自动上下文压缩:autoCompact=true
06 ⚠️ 技能权限过大,遭遇恶意指令攻击
踩坑现象

服务出现异常进程、本地文件被篡改删除、非法网络外联,存在极大的服务器安全风险。
问题根源
技能默认获取主机最高执行权限,恶意技能或指令注入后,可随意操作服务器资源。
避坑方案(直接复制配置)
权限限制:skill.permission=read-only
封禁非必要外网访问技能
07 🔌 WebUI正常,API调用持续403/404
踩坑现象
网页端功能使用完全正常,但通过第三方工具、代码调用API时,频繁出现403无权限、404路径不存在,对接业务完全受阻。
问题根源
跨域配置、路由前缀、鉴权请求头未统一,API接口与WebUI权限规则不一致。
避坑方案(直接复制配置)
gateway.api.prefix=/v1
08 🧠 多轮对话频繁失忆,上下文不继承
踩坑现象
对话过程中频繁丢失历史信息,切换技能后直接清空上下文,历史对话仅保留最近1-2轮,完全无法支撑长流程业务交互。
问题根源
默认会话策略为短期模式,技能间记忆不互通,上下文生命周期极短。
避坑方案(直接复制配置)
contextEngine.shareBetweenSkills=true
09 🔗 向量库断开,服务全程阻塞卡死
踩坑现象
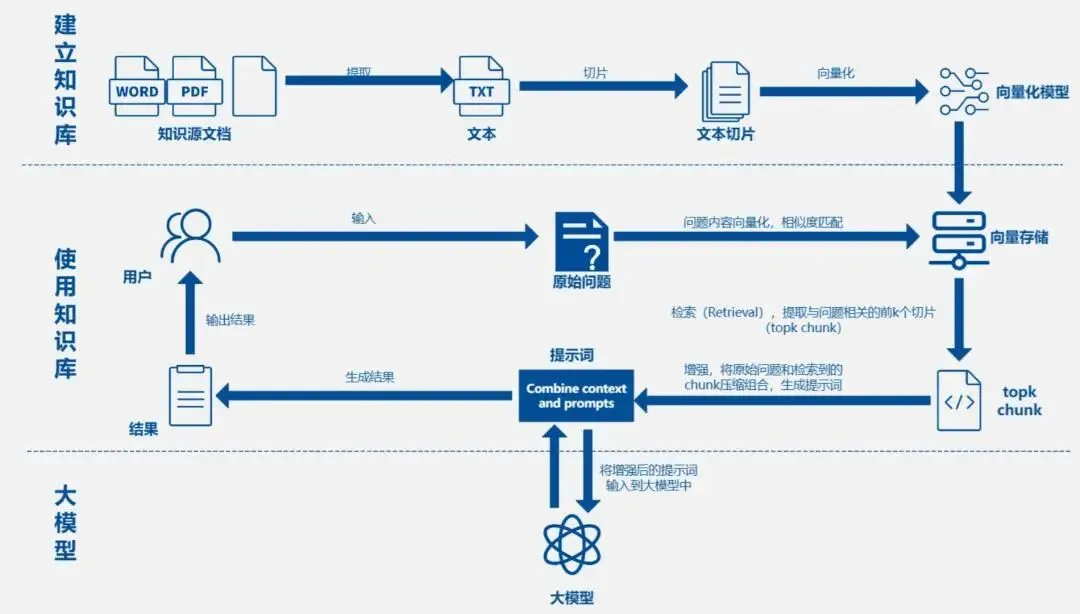
外接Qdrant、Chroma向量库网络波动或宕机后,OpenClaw服务不自动降级,全部请求进入阻塞排队,最终全面超时宕机。
问题根源
未配置熔断、降级、重试机制,外部依赖故障直接传导至核心服务。
避坑方案(直接复制配置)
circuitBreaker.enable=true
10 📦 版本升级后,历史记忆数据不兼容
踩坑现象
升级OpenClaw版本后,历史会话无法加载,提示上下文版本不匹配,存量数据彻底无法使用。
问题根源
ContextEngine存储结构小版本迭代存在兼容性差异,直接升级会导致数据无法读取。
避坑方案
升级前务必执行备份:openclaw context backup
跨版本升级先查看更新日志,确认数据兼容性
生产环境不盲目追新,优先选择稳定版部署
AI智能体落地,从来不是功能堆砌,而是稳定、安全、可靠的生产化改造。
OpenClaw的ContextEngine插件化,确实降低了AI智能体的搭建门槛,但生产环境无小事,每一个忽略的细节,都可能演变成线上故障。
生产部署的核心,永远是先求稳,再求强。
别等服务宕机、数据泄露、业务中断后再补救,提前避开这些坑,才能让AI智能体真正落地,成为高效的生产力工具。
后续会持续分享OpenClaw性能优化、企业级私有化部署的实战经验,欢迎关注交流。

