 夜雨聆风
夜雨聆风当前全球主流 AI 大模型可分为国外旗舰(GPT-5、Claude、Gemini、Grok)与国内第一梯队(通义千问、文心一言、豆包、DeepSeek、Kimi、智谱 GLM、混元、星火)。
下面从核心能力、适用场景、上下文限制、收费与免费额度、信息准确性等维度,系统对比并给出选型建议(数据截至 2026 年 4 月)。

一、国外主流 AI 大模型
1. OpenAI GPT-5 系列(美国)

版本:GPT-5.4(旗舰)、GPT-5.4 Mini(轻量)、o3-Pro(推理特化)
核心优势:全能均衡,逻辑推理、数学、工具调用全球第一;多模态(文 / 图 / 音 / 视频)领先;插件生态最丰富(50 万 +)
使用场景:日常对话、写作、代码开发、数据分析、创意生成、复杂推理(科研 / 奥数)
上下文限制:GPT-5.4 128k tokens(约 9.6 万字);o3-Pro 200k tokens
收费与免费:
免费:GPT-3.5(能力有限)
Plus:$20 / 月(GPT-4o/5.4 基础)
Pro:$200 / 月(o3-Pro 顶级推理)
API:GPT-5 输入$0.015/1k,输出$0.06/1k(约 ¥110 / 百万 tokens)
局限性:中文略弱于国产模型;回复偏 “AI 腔”;国内访问需特殊网络;顶级推理订阅昂贵
答案来源与准确性:训练数据截至 2025 年底;可联网搜索(需 Plus/Pro);幻觉率约 3-5%;引用标注较弱
2. Anthropic Claude Opus 4.6/Sonnet 4(美国)

版本:Opus 4.6(旗舰)、Sonnet 4(平衡)、Haiku(轻量)
核心优势:超长上下文(200 万 tokens,约160万字);低幻觉(<2%);文笔自然、代码能力强;支持 Artifacts 实时预览
使用场景:法律合同、科研论文、书籍分析、公文写作、代码审查、长文档摘要
上下文限制:Opus 4.6 200万tokens(行业最大);Sonnet 4 200k tokens
收费与免费:
免费:Haiku 限时免费(每日限额)
Pro:$20 / 月(Sonnet 4)
API:Opus 4.6 输入$0.03/1k,输出$0.15/1k(约 ¥380 / 百万 tokens)
局限性:多模态弱(无图生 / 视频);风控极严(敏感话题易拒绝);免费额度低;国内访问困难
答案来源与准确性:训练数据截至 2025 年中;无内置联网(需插件);幻觉率 < 2%;法律 / 科研引用精准
3. Google Gemini 3.1 Pro/Ultra(美国)
Gemini 3.1 Pro
版本:Ultra(旗舰)、Pro(主力)、Flash(轻量免费)
核心优势:百万级上下文(100 万 tokens);多模态融合强(视频 / 音频理解顶尖);Google 生态深度集成(Docs/Gmail/ 搜索);速度快、成本低
使用场景:超长文档分析、视频内容理解、Google 办公协同、实时信息检索、多模态创作
上下文限制:Ultra 100 万 tokens;Pro 32k tokens;Flash 16k tokens
收费与免费:
免费:Flash(每分钟 15 次,每日 1500 次)
Advanced:$20 / 月(Pro)
Ultra:$250 / 月(全功能)
API:Pro 输入$0.02/1k,输出$0.12/1k;Flash 极低(约 ¥14 / 百万 tokens)
局限性:逻辑推理略弱于 GPT-5/Claude;中文理解一般;Ultra 订阅极贵
答案来源与准确性:实时联网搜索(Google);数据更新最快;多模态信息准确;文本幻觉率约 4%
4. xAI Grok 4 Heavy(美国)
版本:Grok 4、Grok 4 Heavy(多 Agent 并行)
核心优势:数学推理顶尖(AIME 满分);多 Agent 并行(4 个模型比对结果);回复风格幽默、“反 AI 腔”;上下文 256k tokens
使用场景:数学竞赛、金融建模、复杂逻辑推理、创意写作、需要 “个性” 的对话
上下文限制:256k tokens(约 20 万字)
收费与免费:
免费:无公开免费版
订阅:$300 / 月(Grok 4 Heavy,行业最贵)
局限性:生态小;多模态弱;价格极高;国内无法访问
答案来源与准确性:训练数据截至 2025 年底;可联网;数学推理准确率 95%+;通用知识幻觉率约 5%
二、国内主流 AI 大模型
1. 阿里通义千问 Qwen 3.6 Plus/Max(中国)
版本:Max(旗舰)、Plus(主力)、Turbo(轻量)
核心优势:中文理解顶尖;性价比极高;长文本 128k tokens;全尺寸开源(7B-110B);多模态(文 / 图 / 音)均衡
使用场景:中文写作、政策解读、电商客服、多语言翻译、企业私有化部署
上下文限制:Max/Plus 128k tokens(约 10 万字);Turbo 32k tokens
收费与免费:
免费:新用户 100 万 tokens 永久免费
API:Turbo 0.3 元 / 百万;Plus 0.8 元 / 百万;Max 20 元 / 百万(国内最低档)
局限性:语音交互弱;专业深度(医疗 / 法律)不足;依赖阿里云生态
答案来源与准确性:训练数据以中文为主(截至 2026 年初);可联网;中文幻觉率约 3%;引用标注一般
2. 字节豆包 2.0 Pro(中国)

豆包 2.0 Pro
版本:Pro(旗舰)、免费版(基础)
核心优势:语音交互极强(准确率近 100%);中文口语化理解好;视频脚本生成高效;定价低;日活破亿
使用场景:日常聊天、语音助手、短视频创作、办公辅助、学习辅导
上下文限制:Pro 64k tokens(约 5 万字);免费版 8k tokens
收费与免费:
免费:基础功能永久免费(每日限额)
Pro:30 元 / 月(无限对话 + 高级功能)
API:约 1 元 / 百万 tokens
局限性:复杂推理弱;长文本处理一般;专业能力不足
答案来源与准确性:训练数据中文为主(截至 2026 年初);内置联网搜索;幻觉率约 4%;口语化回答准确
3. DeepSeek V3.2/R1(深度求索,中国)

版本:R1(推理特化)、V3(通用)
核心优势:数学 / 代码顶尖;推理成本极低(约为 OpenAI 的 1/27);国产算力(华为昇腾);中文能力强
使用场景:代码开发、数学证明、学术研究、低成本 API 调用、私有化部署
上下文限制:V3 128k tokens;R1 64k tokens
收费与免费:
免费:新用户 500 万 tokens 永久免费
API:V3 输入 2 元 / 百万,输出 3 元 / 百万;R1 输入 4 元 / 百万,输出 16 元 / 百万(性价比极高)
局限性:多模态弱;行业落地案例少;生态较小
答案来源与准确性:训练数据中文 + 代码(截至 2026 年初);无内置联网;数学 / 代码准确率 90%+;通用知识幻觉率约 3%
4. Kimi K2.5(月之暗面,中国)

K2.5
版本:K2.5(旗舰)
核心优势:长文本之王(200 万字处理);数学推理强;图文公式联合推理;支持本地文档上传分析
使用场景:法律合同、科研论文、书籍阅读、金融建模、学术写作
上下文限制:200 万tokens(约 160 万字,国内最大)
收费与免费:
免费:每日 10 次长文档分析免费
Pro:50 元 / 月(无限长文档 + 高级功能)
API:输入 4 元 / 百万,输出 21 元 / 百万
局限性:仅文本(无多模态);通用对话能力一般;价格偏高
答案来源与准确性:训练数据中文 + 学术(截至 2026 年初);可联网;长文档理解准确率 95%+;幻觉率约 2%
5. 百度文心一言 5.0(中国)
版本:5.0(旗舰)、4.0(主力)
核心优势:多模态生成强(文生图 / 视频);中文知识问答领先;生态成熟(用户 3 亿 +);企业服务完善
使用场景:创意生成、教育问答、金融投顾、内容创作、企业知识库
上下文限制:5.0 64k tokens;4.0 32k tokens
收费与免费:
免费:基础版永久免费(每日限额)
Pro:49 元 / 月(无限对话 + 多模态)
API:约 5 元 / 百万 tokens
局限性:专业深度(医疗 / 法律)不足;逻辑推理弱于 GPT/Claude
答案来源与准确性:训练数据中文为主(截至 2026 年初);内置联网;幻觉率约 3%;中文引用较准
6. 智谱 GLM-5(中国)

智谱GLM-5
版本:GLM-5(旗舰)、GLM-4.6(主力)
核心优势:代码能力强(SWE-bench 77.8%);Agent 搜索领先;国产算力(华为昇腾);学术背景(清华)
使用场景:代码开发、Agent 应用、搜索增强、学术研究、私有化部署
上下文限制:200k tokens(约 16 万字)
收费与免费:
免费:GLM-4-Flash 永久免费(每日限额)
API:GLM-4-Plus 5 元 / 百万;GLM-5 22 元 / 百万
局限性:多模态弱;生态较小;中文口语化一般
答案来源与准确性:训练数据中文 + 代码(截至 2026 年初);可联网;代码准确率 90%+;幻觉率约 3%
7. 腾讯混元 Turbo(中国)

Turbo
版本:Turbo(旗舰)、Standard(主力)、Lite(轻量)
核心优势:微信生态深度集成;文档解析强;多模态(图 / 文)均衡;MoE 架构效率高
使用场景:微信 / 企业微信助手、文档处理、社交内容创作、游戏开发
上下文限制:Turbo 64k tokens;Standard 32k tokens
收费与免费:
免费:Lite 永久免费
API:Standard 4.5 元 / 百万;Turbo 15 元 / 百万
局限性:专业性不足;依赖腾讯生态;更新较慢
答案来源与准确性:训练数据中文为主(截至 2026 年初);可联网;幻觉率约 4%;社交语境理解好
8. 科大讯飞星火 X1(中国)

X1
版本:X1(旗舰)、星火 V3(主力)
核心优势:中文数学能力第一;语音交互延迟 < 5 秒;教育 / 医疗场景适配强;方言理解好
使用场景:教育辅导、医疗问诊、语音助手、数学解题、方言交互
上下文限制:X1 32k tokens;星火 V3 16k tokens
收费与免费:
免费:基础版永久免费(每日限额)
Pro:39 元/月(无限对话 + 高级功能)
API:约 4 元/百万 tokens
局限性:代码生成弱;高负载稳定性待提升;多模态一般
答案来源与准确性:训练数据中文 + 教育 / 医疗(截至 2026 年初);可联网;数学准确率 90%+;幻觉率约 3%
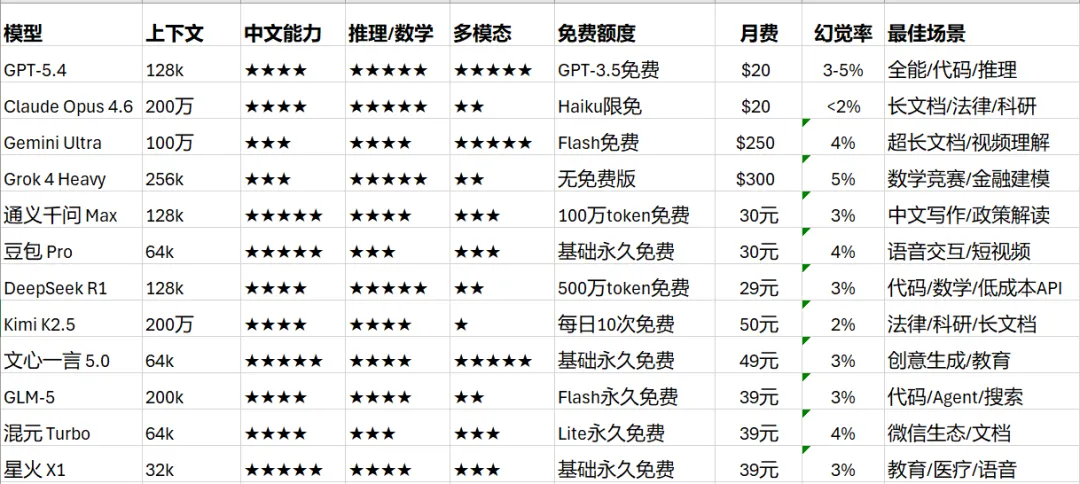
三、核心维度对比总表(2026 年 4 月)
四、选型建议(按需求场景)
日常主力(中文优先):豆包 Pro > 通义千问 Plus > 文心一言 5.0(免费够用,中文自然,价格低)
全能+推理+代码:GPT-5.4 > Claude Sonnet 4 > DeepSeek R1(国际顶尖,逻辑强,代码准)
长文档/法律/科研:Claude Opus 4.6 > Kimi K2.5 > Gemini Ultra(百万级上下文,低幻觉)
低成本API/私有化:DeepSeek V3 > 通义千问 Turbo>GLM-4-Flash(免费额度大,调用成本极低)
多模态/创意生成:GPT-5.4 > Gemini Ultra > 文心一言 5.0(文生图 / 视频强,创作友好)
语音交互/方言:豆包 Pro > 星火 X1 > 通义千问 Plus(语音准,方言理解好)
微信生态/办公:混元 Turbo > 豆包 Pro > 通义千问 Plus(微信集成,文档解析强)
五、关键维度总结对比
1. 综合能力排名(2026现实)
第一梯队(全球)👉 GPT-5 / Claude / Gemini
第二梯队(逼近)👉 DeepSeek / Kimi / Qwen
第三梯队👉 文心 / 豆包 / 星火 / 混元
2. 典型场景选型
✅ 咨询 /研究 /复杂分析
首选:GPT-5 / Claude
备选:Kimi / DeepSeek
✅ 编程 / AI Agent /自动化
首选:Claude
备选:GPT / DeepSeek
✅ 多模态(视频/语音/图像)
首选:Gemini
备选:GPT
✅ 成本敏感(企业部署)
首选:DeepSeek / Kimi
次选:Qwen
✅ 中文办公 /政务 /本地化
首选:通义 / 文心 / 星火
✅ 私有化 / 数据安全
首选:DeepSeek / Qwen / GLM
六、核心趋势判断(非常重要)
1. “没有最强,只有最合适”
用户开始同时使用多个模型(80%以上)
2. 成本正在成为决定性变量
DeepSeek / Kimi 正在“用价格重塑市场”
3. Agent能力成为下一战场
Claude、Grok、GPT 都在强化“自动执行任务”
4. 开源 vs 闭源分化加剧
国外:能力领先
国内:成本+可控领先
七、最终选型建议(一句话版)
国外模型:GPT-5全能最强,Claude长文本/低幻觉无敌,Gemini多模态/超长文档突出,Grok数学推理顶尖但极贵。
国内模型:通义千问/豆包中文+性价比之王,DeepSeek代码/推理成本最低,Kimi长文档国内第一,文心一言/星火/混元/GLM各有生态与场景优势。
趋势:国产模型在中文、性价比、长文本、语音上已追平甚至超越国外;国外模型在全能推理、多模态、生态上仍领先。
如果你只记住一段:
要最强能力 → GPT / Claude
要代码 → Claude
要多模态 → Gemini
要低成本 → DeepSeek / Kimi
要中文+本地化 → 通义 / 文心
要企业部署 → Qwen / DeepSeek / GLM
