 夜雨聆风
夜雨聆风关键词:RISC-V、PyTorch、CI/CD、RVV 向量化、RISE 项目
在刚刚落幕的 PyTorch Conf EU 2026 上,Meta 软件工程师、RISE 项目技术指导委员会联合主席 Ludovic Henry,用一句“So... how do you start?”的质朴发问,撕开了新兴硬件生态最关键的命题:如何让 RISC-V 这一潜力架构,真正承接 PyTorch 这座 AI 框架基石?

作为开源软件与新兴硬件交叉领域的深耕者、RISC-V 生态的关键推动者,Ludovic 始终聚焦 AI 软件栈在 RISC-V 上的性能突破与稳定性落地。
他带着近期重磅实践登台:深度打磨 OpenBLAS、oneDNN 等原生依赖库以释放 RVV 向量扩展潜力,主导搭建 RISC-V 专属 PyTorch 测试基础设施,更系统性拆解 “编译、测试、发布” 三重技术壁垒 —— 不靠 “一等公民” 的口号,只交付可运行的代码、可复现的测试、可持续的发布流程。

PyTorch on RISC-V: From Cross-Compilation to Native CI https://github.com/riseproject-dev/riscv-runner 4000 字,阅读 20 分钟,播客 20 分钟
从校园项目到行业挑战者:RISC-V 如何用开放重塑芯片世界? 超越英伟达 B200 19%计算密度:7nm 四 Chiplet RISC-V 开源架构——面向 AI/HPC 的代际进化路线图 1 核抵 8 核!解耦 RISC-V GPGPU 的控制流和数据访问:Vortex GPGPU 从 0.35 到 1.63 GFLOP/s/mm² 的性能飞跃
这场演讲不止是一次技术迁移的复盘:它直面 RISC-V 适配 PyTorch 的核心痛点,既解答了 RVV 向量扩展如何与动态图执行模型协同、算子优化如何上游化等深层技术问题,也破解了 NumPy/SciPy 等依赖库的“最后一公里”兼容难题,更给出了从交叉编译到原生硬件测试池的完整演进路线图。
这不仅填补了 RISC-V 在主流 AI 框架支持上的关键空白,更是一份开源硬件从“可用”走向“好用”的行业实操指南。
unsetunset本文目录
一、战略支点:为何 PyTorch 与 RISC-V 的相遇至关重要 1.1 RISC-V 的生态位与 PyTorch 的试金石效应 1.2 从云端到边缘的硬件现实 二、冰山之下:跨越编译鸿沟的工程艺术 2.1 地基重构:从操作系统到底层运行时 2.2 Python 世界的最后一公里 三、信任锚点:从“能编译”到“跑得稳”的 CI 进化 3.1 RISE Runners:打破硬件获取壁垒 3.2 漫长的绿化之旅 四、性能解耦与未来图景:走向原生加速 4.1 硬件加速的向量化路径 4.2 边缘侧的降维打击:ExecuTorch 4.3 社区驱动的飞轮效应

unsetunset一、战略支点:为何 PyTorch 与 RISC-V 的相遇至关重要unsetunset
在深入具体的技术攻坚之前,Ludovic Henry 首先勾勒了 RISC-V 在当前计算版图中的位置以及 PyTorch 所承载的象征意义。这不是一次普通的软件适配,而是开源软件栈与开源指令集架构的一次顶峰对齐。

1.1 RISC-V 的生态位与 PyTorch 的试金石效应
RISC-V 并非某家公司的私有财产,而是一个开放标准的指令集架构。其“免版税、开源、社区驱动”的特质,并已有数十亿颗芯片基于该架构出货。

从嵌入式微控制器到数据中心级处理器,RISC-V 的触角正在迅速延伸。然而,一个架构能否在算力要求苛刻的 AI/ML 时代站稳脚跟,关键取决于其对主流框架的支持程度。
在这一背景下,PyTorch 的角色被提到了战略高度。作为 RISE 项目的旗舰级项目,PyTorch 在 RISC-V 上的运行表现,被定义为检验该平台是否“准备好应对 AI/ML 工作负载”的试金石。
如果开发者无法在 RISC-V 服务器上流畅运行 PyTorch,那么所有关于开放硬件在数据中心替代 x86 或 ARM 的畅想都将是无源之水。Ludovic Henry 的演讲逻辑清晰地表明:RISE 社区的目标不仅是让代码跑通,而是要通过优化 PyTorch 这一关键负载,反向驱动 RISC-V 底层硬件特性(如向量扩展)的成熟与工具链的完善。
1.2 从云端到边缘的硬件现实
为了证明这场迁移并非纸上谈兵,下图展示了当前的硬件基础——Scaleway EM-RV1 云实例。这是一款基于真实 RISC-V 裸金属服务器的商用云产品。

相比于模拟器(QEMU)上的交叉编译验证,真实硬件的存在让后续的 CI/CD 流程具备了物理意义上的可靠性。值得注意的是,虽然当前硬件已可用于基础构建,但 Ludovic Henry 也预告了下一代 RVA23 标准硬件的到来,承诺提供 2-3 倍的性能跃升。

这种代际预告暗示了当前 RISC-V 软件栈正处在黎明前的“算力忍耐期”,开发者正在利用当前硬件完善生态,以待下一代向量化硬件爆发。

unsetunset二、冰山之下:跨越编译鸿沟的工程艺术unsetunset
“Step 1: Make it compile.”。
这句话听起来轻描淡写,但任何有过交叉编译或新架构 bring-up 经验的工程师都明白,这背后隐藏着一座巨大的依赖项冰山。
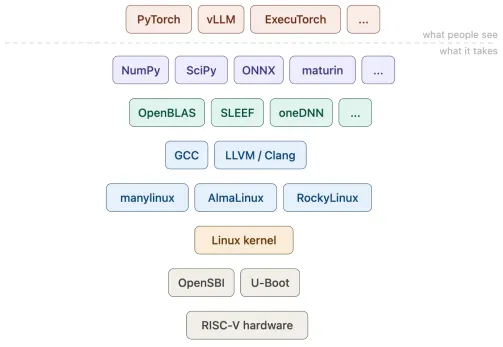
Ludovic Henry 以抽丝剥茧的方式,展示了 RISE 社区过去两年在这一层面的艰苦作业。
2.1 地基重构:从操作系统到底层运行时
任何框架的运行都建立在稳健的操作系统与工具链之上。在 x86 生态中习以为常的
pip install,在 riscv64 架构下却是一场供应链的重塑。
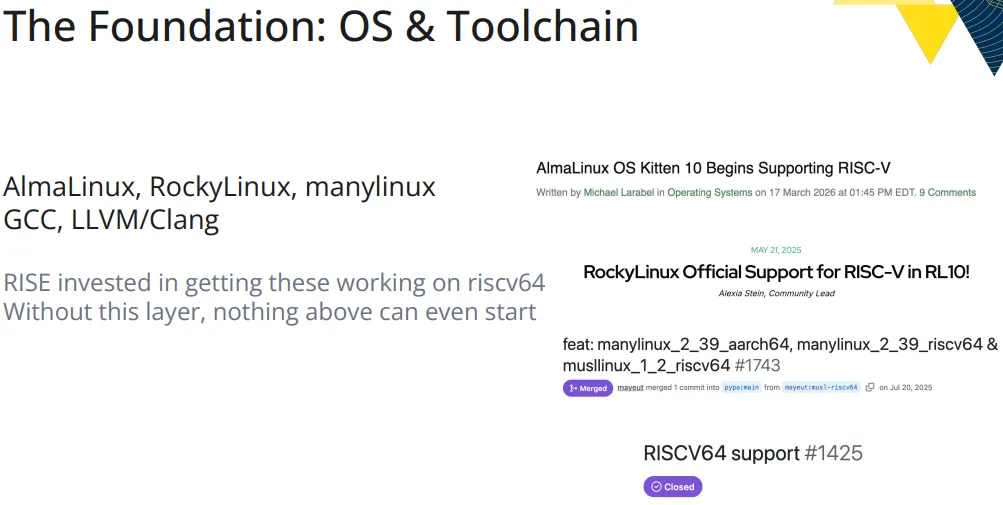
上面截图拼贴揭示了一幅宏大图景:AlmaLinux、RockyLinux 开始为 riscv64 提供官方支持,许多 linux 与 musllinux 的 wheel 标准被扩展以纳入 riscv64。这不仅仅是重新编译一次内核,而是要让 GCC/LLVM 能够为 RISC-V 生成正确且高效的代码,特别是对后续性能至关重要的 RVV 向量扩展支持。
Ludovic Henry 特别强调了数学库这一层的挑战。
在 AI 运算中,OpenBLAS 和 oneDNN 是 CPU 推理性能的核心加速库。如果没有针对 RISC-V Vector 扩展的手工汇编优化或 intrinsics 重写,PyTorch 在 CPU 上的计算图将退化为标量运算,性能将低至无法接受的水平。

上图确认了 RISE 对 OpenBLAS RVV 支持的贡献,并指出 oneDNN 的适配是当前工作的重中之重。对于具备芯片背景的读者而言,这暗示着社区正在为 RISC-V 定制一套高效的 GEMM 微内核,这是所有上层矩阵运算的物理基础。
2.2 Python 世界的最后一公里
当 C/C++ 底层库编译通过后,也进入了更为繁琐的“Python 最后一公里”。

NumPy、SciPy、ONNX、maturin——这些 PyTorch 生态的基石库必须逐个生成适配 riscv64 的原生 wheel 包。Ludovic Henry 在幻灯片中嵌入了一段 Docker 命令行录屏,展示了在 linux/riscv64 容器中成功安装 maturin 的瞬间。这段看似简单的录屏实则是巨大的里程碑:它意味着RISC-V 平台已经具备了 Python 原生扩展的构建能力。
这一环节最棘手的问题在于解决 ABI 兼容性与二进制分发标准。由于 RISC-V 的历史包袱较轻,社区得以在一开始就推动 manylinux_2_31_riscv64 这类较新的 ABI 标准,避免了 ARM 生态早期碎片化的覆辙。这使得开发者可以像使用 x86 机器一样,直接通过 pip 拉取预编译的轮子,而无需在本地耗尽数小时进行源码编译。
unsetunset三、信任锚点:从“能编译”到“跑得稳”的 CI 进化unsetunset
跨越了编译的千山万水之后,抛出了一个工程哲学层面的论断:No CI = no official support。

对于一门成熟的软件工程学来说,软件能否在特定架构上运行,不取决于某次手动编译的成功,而取决于是否有一个持续验证、且结果公开的自动化测试体系。
3.1 RISE Runners:打破硬件获取壁垒
为了解决开发者手中没有 RISC-V 硬件的问题,RISE 项目推出了具有变革意义的 RISE RISC-V Runners。

这是一种托管在 GitHub Actions 上的免费、裸金属、生命周期短暂的 CI 服务。其架构设计直接对标 GitHub 官方提供的 x86/ARM 运行器。通过简单的 runs-on: ubuntu-24.04-riscv 配置,任何开源项目都能获得真实的 RISC-V 算力验证。
这不仅降低了准入门槛,更重要的是建立了一套标准化的验证流程。下一代规划——RVA23 硬件与 VM 运行器、setup-python 等动作的开箱即用——显示 RISE 正在试图抹平 RISC-V 与主流架构在 DevOps 体验上的最后一丝差异。

3.2 漫长的绿化之旅
有了硬件,接下来的任务便是所揭示的“Greening the Test Suite”。

PyTorch 拥有数十万个测试用例,在 x86 上通过率极高,但在新架构上,隐含的未定义行为、端序假设、时间精度差异都会导致测试变红。Ludovic Henry 描述了团队和外包人员如何系统性地排查失败用例、提交补丁并向上游反馈。这是一个枯燥但绝对必要的净化过程。
从芯片与编译器的角度看,CI 变绿的过程实质上是软硬件接口规范对齐的过程。例如,某些测试失败可能并非 PyTorch 代码有误,而是触发了 RISC-V 特定内存模型下的竞态条件,或是 GCC 针对 RVV 向量化生成的代码在边界对齐上存在问题。解决这些问题是反向打磨 RISC-V 软件栈鲁棒性的最佳途径。
unsetunset四、性能解耦与未来图景:走向原生加速unsetunset
在解决可用性问题后,自然过渡到性能与发布策略。
4.1 硬件加速的向量化路径
下面架构示意图直观展示了 RISC-V 硬件加速栈:OpenBLAS + RVV 与 oneDNN。
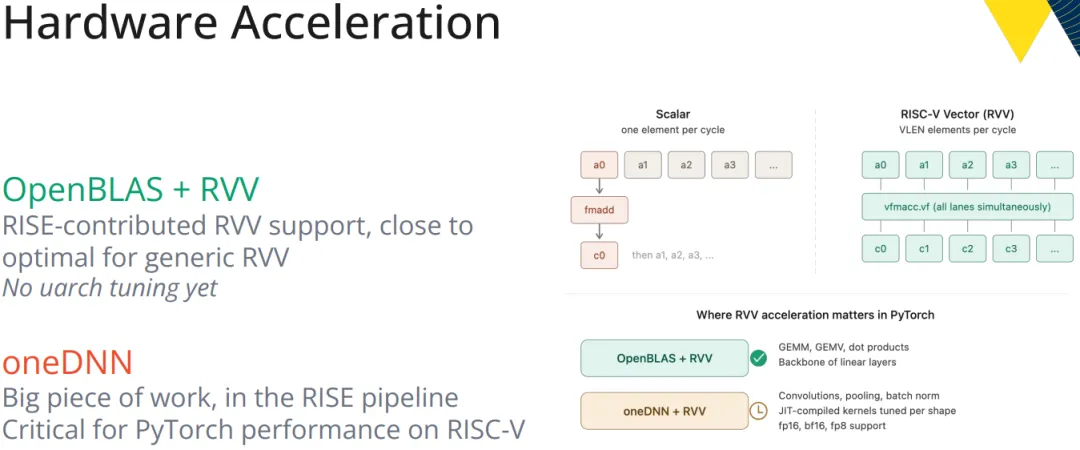
Ludovic Henry 坦诚地指出,虽然 OpenBLAS 的 RVV 支持已接近最优(针对通用 RVV),但针对特定微架构的调优尚未开始。这是典型的“先求有,再求好”策略。对于专业听众而言,oneDNN 作为 Intel 开源的深度神经网络加速库,其 pipeline 中的 RISC-V 适配工作预示着未来 PyTorch 在 RISC-V 上的卷积、RNN 等算子将能享受到现代 CPU 的缓存阻塞与指令重排优化。
4.2 边缘侧的降维打击:ExecuTorch
除了数据中心场景,下面还特意点名了 ExecuTorch。

PyTorch 在边缘侧的部署利器与 RISC-V 在嵌入式领域的天然优势在此形成了战略交汇。对于 AI 芯片从业者来说,这意味着未来大量的端侧 AI 推理芯片(基于 RISC-V IP 核)将拥有一个极其丝滑的模型部署工作流——模型在云端 PyTorch 训练,导出为 .pte 文件,直接运行在指甲盖大小的 RISC-V MCU 上。
4.3 社区驱动的飞轮效应
在演讲的尾声,Ludovic Henry 发出了具体的行动呼吁,并描绘了下图所展示的“良性循环”:更多的库迁移 → 更丰富的 CI 验证 → 更稳定的平台体验 → 吸引更多开发者 → 发现更深层性能瓶颈 → 驱动硬件改进。
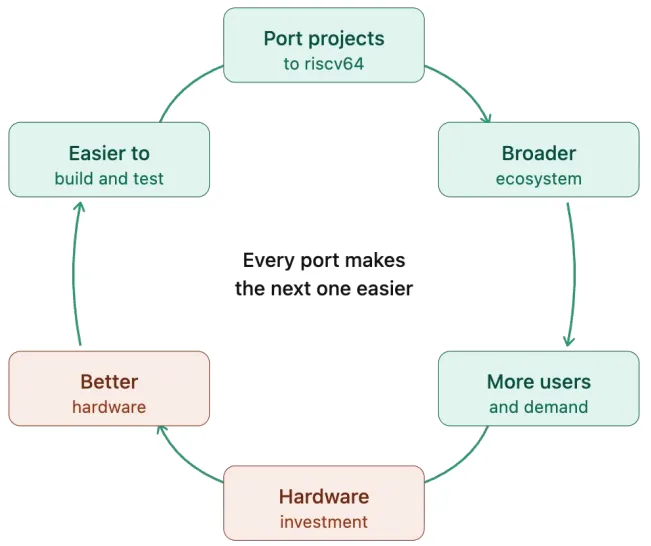
这份演讲最大的价值在于其诚实性。它没有宣称 RISC-V 已经超越了 x86,而是通过页码的递进,诚实地展示了底层代码迭代,到最终用户可见的 pip install 之间,到底隔着多么浩繁的工程细节。
RISC-V 在 AI 领域的崛起并非一道“是与否”的选择题,而是一个关于“何时到来”的时间函数。

正如演讲最后结语所言——Not if, but when. 当编译、测试、发布这三座大山被社区合力移除后,一个真正开放的、无专利壁垒的 AI 算力时代轮廓已然清晰可见。
用 Python 写一个开源 RISC-V 向量编译器:MLIR 与 xDSL 的 GEMM 代码生成,较 OpenBLAS 最高提升 35% 8.1倍性能飞跃!MICRO'25 开源RISC-V GPGPU算力突破:混合精度融合点积单元,可配置融合架构 剖析RISC-V不同平台性能:PMU剖析与基于LLVM硬件无关Roofline,分析SiFive、平头哥C910和进迭时空性能
