 夜雨聆风
夜雨聆风从零配置你的第一个自动化投研workflow
每天早上8点,你打开电脑:看行情软件里的A股三大指数、看同花顺的资金流向、刷财经网站新闻、再打开备忘录写今日关注点……一通操作下来,30分钟没了。
一年250个交易日,每天30分钟,就是125个小时。这些时间本来可以读一份研报,或者吃顿早饭。
这30分钟可以自动化。不需要写什么复杂框架,一套OpenClaw配置就能跑起来。
这篇文章,手把手带你从零搭一套自动化投研系统。
先搞懂三个核心概念
OpenClaw有三个"引擎",我用一个比喻来解释。
第一个:sessions_spawn = 派多个助手同时干活。
有一堆资料要整理,自己干要很久,叫5个助手同时干就快多了。sessions_spawn就是这个作用——告诉它要做什么,它同时派出多个子Agent并行处理,同时爬A股数据、美股数据、新闻、资金流向。
第二个:cron = 定时闹钟。
设一个时间,到点了自动触发。可以设"每个工作日早上8点给我发晨报",也可以设"每天收盘后自动复盘"。不像Python脚本要一直跑着,它就是一个精准闹钟。
第三个:heartbeat = 持续巡逻的哨兵。
持仓标的出现异动,或者宏观数据出了大消息,heartbeat会主动发现并通知你,不用你手动去查。
一句话:sessions_spawn负责"同时干",cron负责"定点干",heartbeat负责"持续巡逻"。
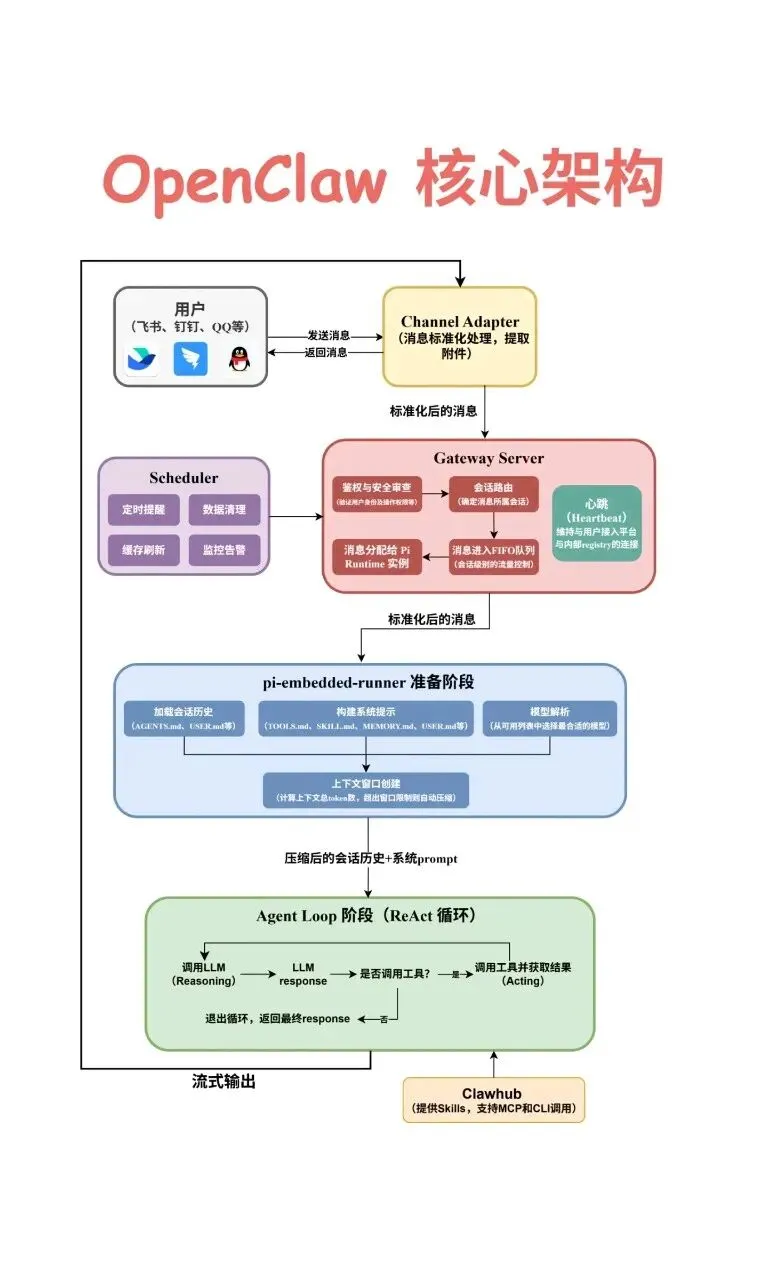
第一步:基础配置
openclaw配置好后,会在用户目录生成配置文件,结构如下:
~/.openclaw/
├── config.json # 主配置文件(cron、agent、heartbeat)
├── workspace/
│ ├── SOUL.md # AI助手人设
│ ├── USER.md # 用户信息
│ ├── HEARTBEAT.md # 心跳检查清单
│ └── MEMORY.md # 长期记忆
HEARTBEAT.md 是巡逻清单,建议这样写:
# Heartbeat 检查清单 — 投研监控
## 安静时间
- 23:00-08:00 不打扰,直接返回 HEARTBEAT_OK
## 每次检查
- [ ] 在安静时间内?是的,直接返回 HEARTBEAT_OK
## 交易时段检查(每30分钟,9:15-15:30)
- [ ] 检查持仓标的是否有异常波动(>5%)
- [ ] 如有大幅波动,立即生成预警简报
## 新闻检查(每2小时)
- [ ] 搜索持仓标的或关注行业的最新新闻
- [ ] 重大突发消息立即推送
清单每次心跳触发时都会被读取,清单越长消耗token越多,控制在200行以内。
第二步:sessions_spawn 派生子Agent
这是最核心的部分。sessions_spawn允许同时派多个子Agent并行干活,主Agent等着收结果。
基础用法:
# 定义多个采集任务
search_tasks = [
{"topic": "A股今日行情分析", "source": "akshare"},
{"topic": "美股隔夜动态", "source": "yfinance"},
{"topic": "今日宏观新闻", "source": "web"}
]
# 为每个任务创建并行子代理
subagent_ids = []
for task in search_tasks:
result = sessions_spawn(
prompt=f"""
请执行以下任务:
主题:{task['topic']}
数据源:{task['source']}
要求:
1. 获取最相关的3-5条结果
2. 提取关键信息并总结
3. 返回结构化结果摘要
""",
model="gpt-4o-mini", # 子任务用轻量模型,省钱
timeout=60 # 60秒超时
)
subagent_ids.append(result['id'])
print(f"子代理已创建: {result['id']} -> {task['topic']}")
投研实战:并行采集A股+美股+新闻+资金流向。
我自己搭这套系统的时候,一开始是串行采集——先查A股,再查美股,再看新闻,全部跑完要4分钟。后来改成并行,40秒搞定。不过这里有个坑:并行派出去的子Agent数量不是越多越好,我试过同时派20个,结果API限流了,有些任务直接超时失败,建议控制在8个以内。
class ResearchDataAggregator:
"""投研数据聚合器——并行采集A股、美股、宏观数据"""
def __init__(self):
self.data_sources = [
{"name": "A股行情", "type": "akshare",
"task": "获取上证指数、深证成指、创业板指今日行情"},
{"name": "美股行情", "type": "yfinance",
"task": "获取标普500、纳斯达克指数隔夜行情"},
{"name": "资金流向", "type": "akshare",
"task": "获取今日北向资金流向数据"},
{"name": "市场新闻", "type": "web",
"task": "搜索今日A股市场重大新闻(前5条)"},
]
def parallel_collect(self):
"""并行采集所有数据源"""
subagent_ids = []
for source in self.data_sources:
prompt = f"""
你是投研数据采集专家。请执行以下任务:
任务:{source['task']}
数据源类型:{source['type']}
请返回结构化数据,包含:
- 数据类型
- 关键数值/摘要
- 数据时间戳
- 简要分析判断(用一句话)
输出格式:JSON
"""
result = sessions_spawn(
prompt=prompt,
model="gpt-4o-mini",
timeout=120,
tools=["web_search", "web_fetch", "exec"]
)
subagent_ids.append({
"id": result['id'],
"source": source['name']
})
print(f"已创建子代理 [{source['name']}]")
return subagent_ids
sessions_spawn代码截图风格,展示并行派生的代码
第三步:cron 定时任务配置
cron就是一个精准定时器,可以设"每个工作日早上8点触发",也可以设"每周五收盘后触发"。
Cron表达式:
| 表达式 | 含义 |
|---|---|
0 8 * * 1-5 |
每个工作日早上8点(开盘前) |
0 15 * * 1-5 |
每个工作日下午15点(收盘后) |
0 9,10 * * 1-5 |
每天9点和10点(盘中检查) |
*/30 * * * * |
每30分钟 |
0 21 * * 0-4 |
美股收盘后(北京时间21点) |
实战配置:工作日早8点触发晨间简报。
{
"cron": {
"timezone": "Asia/Shanghai",
"jobs": [
{
"id": "morning-briefing",
"schedule": "0 8 * * 1-5",
"message": "生成今日市场早报,包括外围市场隔夜表现、A股重要新闻、机构晨会观点",
"channel": "feishu",
"model": "claude-3-sonnet",
"enabled": true
},
{
"id": "a-share-close-report",
"schedule": "0 15 * * 1-5",
"message": "生成收盘简报:三大指数涨跌幅、成交额、北向资金、热点板块"
},
{
"id": "us-stock-after-close",
"schedule": "0 21 * * 0-4",
"message": "美股收盘分析:标普500、纳斯达克、特斯拉、英伟达等核心资产表现"
},
{
"id": "weekly-research",
"schedule": "0 17 * * 5",
"message": "生成周度投研报告:本週市场回顾、下周展望、重点关注标的"
}
]
}
}
命令行添加也很方便:
openclaw cron add \
--schedule "0 8 * * 1-5" \
--message "生成今日市场早报" \
--channel "feishu"
第四步:数据源接入
用两个主力库:akshare(A股)和yfinance(美股),都是免费开源的。
不过说实话,akshare用久了你会发现接口稳定性一般,有时候早上开盘那会儿数据返还有延迟,建议等开盘后5-10分钟再跑采集任务。
akshare — A股数据
pip install akshare -i https://pypi.tuna.tsinghua.edu.cn/simple
完整采集脚本:
#!/usr/bin/env python3
"""
A股数据采集脚本 by akshare
"""
import akshare as ak
import pandas as pd
import json
from datetime import datetime
def collect_a_share_data():
"""采集A股核心数据"""
results = {}
# 1. 全市场实时行情
try:
spot_df = ak.stock_zh_a_spot()
results['market'] = {
"total_count": len(spot_df),
"advances": len(spot_df[spot_df['涨跌幅'] > 0]),
"declines": len(spot_df[spot_df['涨跌幅'] < 0]),
"timestamp": datetime.now().strftime("%Y-%m-%d %H:%M:%S")
}
except Exception as e:
results['market'] = f"获取失败: {e}"
# 2. 三大指数(上证/深证/创业板)
try:
indices = [
("上证指数", "000001"),
("深证成指", "399001"),
("创业板指", "399006")
]
index_data = []
for name, code in indices:
df = ak.stock_zh_a_hist(symbol=code, period="daily",
start_date=datetime.now().strftime("%Y%m%d"),
end_date=datetime.now().strftime("%Y%m%d"))
if not df.empty:
row = df.iloc[-1]
index_data.append({
"name": name,
"close": float(row['收盘']),
"change_pct": float(row['涨跌幅'])
})
results['indices'] = index_data
except Exception as e:
results['indices'] = f"获取失败: {e}"
# 3. 北向资金
try:
capital_df = ak.stock_market_closs_rd()
north = capital_df[capital_df['方向'] == '北向']['今日净流入'].sum()
results['capital_flow'] = {"north": float(north)}
except Exception as e:
results['capital_flow'] = f"获取失败: {e}"
# 4. 北向资金 TOP10
try:
top_df = ak.stock_hsgt_north_net_flow_in_em(symbol="北向资金")
results['top_stocks'] = top_df.head(10)[['股票代码', '股票名称', '净流入']].to_dict('records')
except Exception as e:
results['top_stocks'] = f"获取失败: {e}"
return json.dumps(results, ensure_ascii=False, indent=2)
if __name__ == "__main__":
print(collect_a_share_data())
yfinance — 美股数据
pip install yfinance
#!/usr/bin/env python3
"""
美股数据采集脚本 by yfinance
"""
import yfinance as yf
import json
def collect_us_stock_data(symbols=None):
"""采集美股核心数据"""
if symbols is None:
symbols = ["SPY", "QQQ", "AAPL", "MSFT", "NVDA", "TSLA", "^VIX"]
results = {}
for symbol in symbols:
try:
ticker = yf.Ticker(symbol)
info = ticker.info
hist = ticker.history(period="5d")
if not hist.empty:
latest = hist.iloc[-1]
prev = hist.iloc[-2] if len(hist) > 1 else latest
change_pct = ((latest['Close'] - prev['Close']) / prev['Close'] * 100) if prev['Close'] else 0
results[symbol] = {
"name": info.get('shortName', symbol),
"price": round(float(latest['Close']), 2),
"change_pct": round(change_pct, 2),
"volume": int(latest['Volume'])
}
except Exception as e:
results[symbol] = {"error": str(e)}
return json.dumps(results, ensure_ascii=False, indent=2)
if __name__ == "__main__":
print(collect_us_stock_data())
新闻数据 — web_search / web_fetch
新闻用web_search搜,再配合web_fetch抓正文:
# 并行搜索多个主题
topics = [
"A股 今日行情 分析",
"美联储 加息 最新动态",
"宁德时代 财报 最新",
]
for topic in topics:
result = web_search(query=topic, count=3)
for item in result['results']:
print(f"📰 {item['title']}")
print(f" {item['url']}")
第五步:串联成完整workflow
前面的模块都可以串起来了。整体流程:
定时触发(cron) → 并行采集(sessions_spawn) → AI分析汇总(主Agent) → 推送通知(channel)

第六步:推送通知
报告生成完了,要发出去。常用的是飞书和Telegram组合
Telegram推送:
import requests
def push_to_telegram(bot_token, chat_id, message):
url = f"https://api.telegram.org/bot{bot_token}/sendMessage"
payload = {
"chat_id": chat_id,
"text": message,
"parse_mode": "Markdown"
}
requests.post(url, json=payload)
飞书Webhook推送:
def push_to_feishu(webhook_url, message):
payload = {
"msg_type": "text",
"content": {"text": message}
}
requests.post(webhook_url, json=payload)踩过的5个坑
搭这套系统过程中踩过不少坑,总结5个最常见的:
1. akshare数据有延迟
akshare是免费公开数据,存在数秒到数十秒的延迟,不适合高频日内交易。做日频或周频投研分析的话完全够用。建议收盘后5-10分钟再触发cron,确保数据完整。
更要命的是,有次我早上8点准时触发cron取数据,结果返回的"今日行情"其实是昨天的——因为交易所还没开盘,数据根本没更新。教训:取当日数据前先判断下当前时间是否在交易时段内。
2. cron表达式写错
最早最容易犯的错误。想设"每个工作日早上9点",写成了0 9 * * *——这会触发周六周日,而周一到周五才交易。正确写法是0 9 * * 1-5,1-5代表周一到周五。建议配置里加上checkMarketOpen条件,AI会先判断是否为交易日再执行。
3. 子Agent超时卡住
并行派出去10个子Agent,9个都跑完了,1个卡在网络请求上,主流程一直等。解法是给每个子Agent设置合理超时(60-120秒),同时在主流程里做超时兜底——超过时间就放弃等待,继续处理已返回的结果。
4. API费用爆炸
Heartbeat默认每30分钟跑一次,用GPT-4的话一个月账单挺可观。经验:heartbeat用本地轻量模型(比如ollama/llama3:1b),主力分析任务才用大模型。这一个配置能省70%以上的API费用。
我有个朋友不信邪,用GPT-4跑heartbeat跑了两个月,一看账单心凉了,后来换成本地模型,费用直接降了一个数量级。
5. heartbeat检查太频繁耗token
HEARTBEAT.md内容太长,每次读取都消耗token。清单控制在200行以内,用状态追踪文件记录上次检查时间,这样每次心跳只需要判断"这次该不该查邮件/日历/行情",而不是每次都把所有检查跑一遍。
这套系统能做什么、不能做什么
说点实在的。
能做的:
每天自动采集行情数据,生成晨报/复盘报告 盘中持续监控持仓标的大幅波动,主动预警 并行采集多个数据源,大幅节省投研准备时间 积累每日市场数据,形成自己的数据库
不能做的:
不能替代真正的投资决策。AI能告诉你"北向资金今日净流入50亿",但要不要加仓,这是你自己的判断。 不能预测市场。历史数据展示的是过去,不是未来。 不能完全无人的自动化。系统跑起来后,还是要定期看看配置是否正常、数据是否有异常。
我有个朋友搭了一套类似的系统,用了三个月后说:"现在每天早上的30分钟重复劳动全没了,但是我发现多出来的时间并没有让我赚钱——因为真正的投研工作才刚刚开始。"
这话很实在。自动化帮你省了搜集信息的时间,但分析信息、判断决策、承受结果,这些永远是你自己的事。工具是放大器,不是替代品。
好了,这篇教程就到这里。从安装到workflow串联,主要的坑都帮你踩过了。有什么问题欢迎留言交流。
风险提示:本文仅供参考,不构成投资建议。
