 夜雨聆风
夜雨聆风在AI技术狂飙突进的今天,科研工作正在经历一场静默而深刻的变革。从文献阅读到代码编写,从数据分析到论文写作,大语言模型正在重新定义“科研生产力”的上限。然而,真正的问题不在于“AI能做什么”,而在于——你是否拥有一套属于自己的、可持续进化的AI科研系统?
为此,我们精心策划了几场深度实战培训,帮助您从“使用AI”跨越到“构建AI”,让工具真正成为您科研道路上的长期合伙人。
🌟 课程一:基于claude code、codex双AI协同论文写作撰写与质量校准:从"数据分析→论文初稿→交叉审稿"全流程
🌟 课程三:2026最新AI驱动科研全链路实战营:贯通LLM与Notebooklm应用、数据分析、自动化编程、文献及知识管理、科研写作与绘图、构建个人AI助手与科研工自动化作流培训班

📢 课程核心差异化
1.双模型交叉审稿:Claude Code写代码和论文,Codex作为独立审稿人打分、挑错、提改进意见——两个不同AI系统互相review迭代,比单一AI自查深入一个层次。
2.真实全流程:数据获取→清洗分析→统计检验→论文撰写→多轮审稿→投稿准备,两天走完核心环节。
3.真实案例:讲师以自己论文为例,展示Codex审稿从4/10逐步改进到8/10的完整轨迹(12轮迭代,课堂展示精华3轮)。
4.Claim校准:让两个AI分别评估论文核心结论的可信度,教学员用AI做批判性思考而非盲目接受。
5.学科通用:核心方法适用于任何"数据→分析→论文"的定量研究场景。
📢 课程完整产出
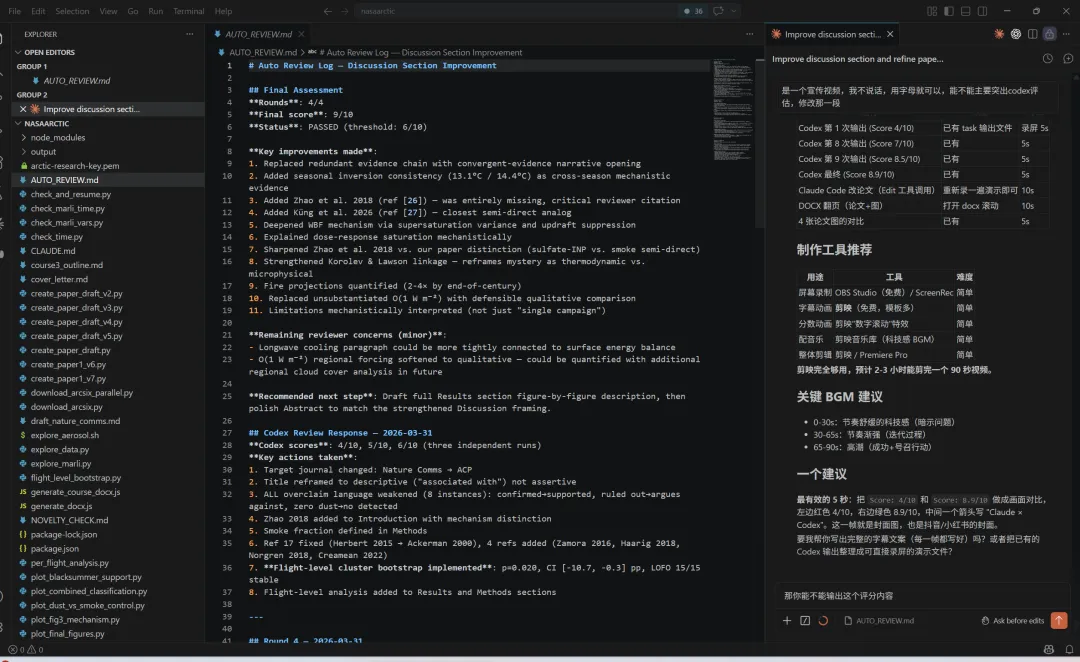
培训时间:5月16日-17日
学习方式:线上直播+助学群长期辅助指导+永久回放特权课程内容
📋 课程内容简要
第一天:Claude Code科研深度使用——从数据到论文初稿
产出:完整Claude Code项目环境-- 数据已下载、清洗、分析
1、Claude Code安装验证与模型选型(Opus/Sonnet/Haiku的成本与能力权衡)
产出:可用的Claude Code环境
2、CLAUDE.md:用一个配置文件教AI理解你的项目背景和规范
产出:项目专属CLAUDE.md
3、Memory系统:跨对话保持研究上下文(方向、数据、发现)
产出:Memory配置
4、实操:为自己的科研课题创建Claude Code项目结构
产出:完整项目骨架
案例实践:对比有/无CLAUDE.md时的回答质量——从"通用聊天"变成"懂你课题的助手"
模块二、数据获取与自动化分析
1、用Claude Code生成数据下载脚本(API/FTP/Web多种方式)
产出:下载脚本
2、数据清洗:缺失值、异常值、格式转换(NetCDF/HDF5/CSV/Excel)
产出:清洗脚本
3、自然语言→分析脚本:描述研究假设,Claude Code自动设计分析方案
产出:200+行Python脚本
4、统计检验:Bootstrap CI、Cohen's d效应量、多重比较校正
产出:统计结果JSON
案例实践:一句话需求→自动生成完整脚本→跑通→输出结果
模块三、科研绘图
1、投稿级图表标准(字体、DPI、配色、error bars)
产出:matplotlib模板
2、常见图表类型实操:scatter、heatmap、bar+CI、时间序列
产出:3-4张图
3、多panel组合图:gridspec布局与统一配色
产出:组合figure
模块四、论文初稿自动生成
1、论文结构设计:Title → Abstract → Intro → Results → Discussion → Methods
产出:论文大纲
2、Results:Claude Code读取JSON结果,生成带精确数字的段落
产出:Results初稿
3、Discussion:机制解释、文献对比、局限性
产出:Discussion初稿
4、Introduction:背景、知识空白、本文贡献
产出:完整初稿v1
关键技巧:如何让AI引用真实数字而非编造;如何用Memory防止长文写作中上下文丢失
模块五、AI伦理与期刊政策
1、主流期刊的AI使用政策(Nature/Science/Elsevier/ACS/AGU最新规定)
2、AI辅助写作的披露规范:哪些必须声明、怎么声明
3、数据隐私与保密:什么数据不能上传到云端API
4、可复现性:Prompt日志、环境版本
第二天:Codex交叉审稿 + 迭代改进 + 投稿准备
产出:论文经过3轮交叉审稿,含完整改进记录-投稿级图表-论文DOCX + Cover Lette-学员自己课题的初步成果
模块六、Codex首次审稿
1、Codex CLI配置与使用方式(consult模式发送审稿请求)
产出:可用的Codex环境
2、把论文初稿发给Codex:要求打分、列弱点、找overclaim
产出:首次审稿报告(预计4-6/10)
3、解读审稿意见:overclaim、missing citations、statistical gaps
产出:问题清单
关键时刻:学员亲眼看到论文被打低分——"AI审稿比真人审稿更直接"
模块七、双AI迭代改进
1、Round1:修复措辞(confirms→supports, rules out→argues against)
Codex审查:重新打分
预期变化:+1-2分
2、Round2:补引用、加统计检验、完善limitations
Codex审查:再次审稿
预期变化:+1分
3、Round3:针对性修复剩余弱点
Codex审查:终审
预期变化:达到可投级
核心重点:
-科研措辞分寸:从"proves"到"is consistent with"
- 引文补充:用Claude Code的WebSearch查找缺失引用
- 每轮改进的对照记录
备注:课程案例经过12轮才从4/10到8/10。课堂3轮是精华流程展示,学员课后可继续迭代。
模块八、Claim校准——让两个AI交叉质询
1、Claude和Codex分别评估核心结论的可信度,对比分歧
产出:双方评分对比
2、根据交叉质询结果调整论文claim强度
产出:校准后的措辞
模块九、审图 + 投稿文件生成
1、Codex审图:标签、单位、配色、可读性
产出:审图报告
2、修图:去夸张标题、加error bars、colorblind-safe配色
产出:终版图表
3、Claude Code生成DOCX(嵌入图表)
产出:论文DOCX
4、引用格式化(Nature-style/APA/国标,按目标期刊选择)
产出:引用列表
5、Cover Letter自动生成
产出:cover_letter.md
模块十、学员实操 + 进阶路径
1、学员用自己的数据/课题跑一遍核心流程(分析→初稿→Codex审稿)
时间:45min
2、共性问题集中讲解 + 讲师答疑
时间:30min
3、进阶路径概览:远程计算(AWS/阿里云)、自定义SKILL、MCP扩展、引文管理器对接
时间:15min
注:请提前自备电脑及安装所需软件。
📞 报名咨询
微信二维码:

课程二

第一章、绘图原则与概念:规范清晰简洁自明
1.理解顶刊图表的核心逻辑,避免“技术正确但科学无效”的绘图误区
2.四大原则:简洁性、一致性、准确性、自明性
3.图形的基本元素(尺寸、格式、分辨率、字体、配色、高分论文案例)第二章、R语言与AI协同的智能绘图体系:
八仙过海各显神通1.R语言的基本用法和数据处理
2.R语言的做图系统
(1)Rbase基础绘图系统:基础图形函数(plot、lines、points等)
(2)ggplot2系统:层次化绘图理念,主题设计与自定义
(3)lattice系统:多面板图形与条件绘图
(4)plotly系统:交互式图表绘制与3D图形应用
3. AI驱动的科研绘图工作流(1)Prompt生成:Gemini / DeepSeek / ChatGPT生成可运行R代码(2)AI辅助设计决策:输入数据类型→推荐最佳图表类型(3)自动标注与统计增强:用AI识别显著性差异→自动生成星号标注
自动添加样本量(n=)、误差线类型(SD/SEM)第三章、科研图表的视觉美学与设计规范:完美图表华丽呈现
图表的美学与设计
1. 配色方案
2. 标题
3. 坐标轴设计
4. 图例:清晰标注图例位置与内容
5. 字体规范:字体大小、类型与间距的选择
6. 线条:线条的粗细、样式选择及其与背景的对比
7. 背景:透明或简洁背景设计,提高视觉清晰度
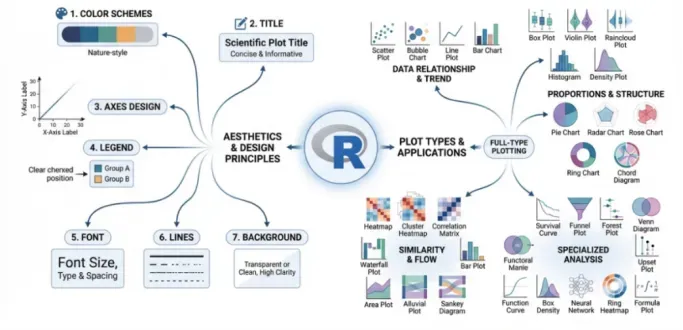
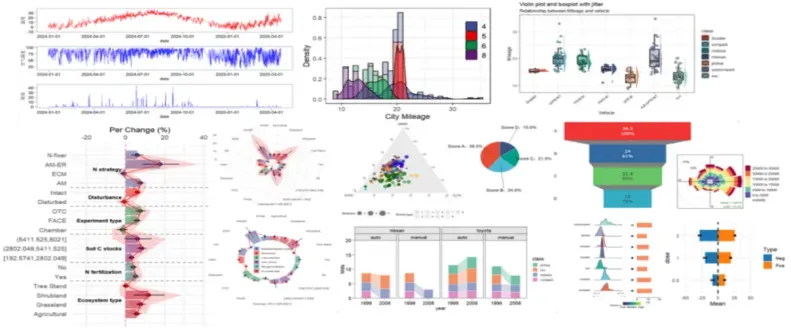
第四章、数据驱动图表选择:15+科研场景匹配
1. 常见数据格式:如何识别数据类型,选择适当图表
2. 科研绘图全类型绘制
(1)散点图、气泡图:适合显示两组数据关系
(2)折线图、柱状图:趋势分析与比较
(3)箱线图、小提琴图:数据分布分析
(4)云雨图、直方图、密度图:数据分布的不同展示方法
(5)饼图、雷达图、玫瑰图:比例关系与环形展示
(6)热力图、聚类热图、相关矩阵图:数据相似性展示
(7)瀑布图、条形图、面积图:时间序列或分布展示
(8)冲积图、桑基图:展示流动与比例
(9)词云图、关联图:文本数据与关系网络
(10)环形图、和弦图:比例与结构关系
(11)生存曲线图、漏斗图:生物医学与临床数据分析
(12)森林图、韦恩图、upset图:元分析与交集分析
(13)UMAP图、函数曲线图:降维与函数关系展示
(14)箱线密度图、神经网络图:机器学习与深度学习数据展示
(15)环形热图、公式图:其他特殊类型的应用
3. 图表决策树:根据变量类型/维度自动推荐最佳图表
4. 顶刊图表选取趋势分析
第五章、统计信息的可视化表达与标注规范:
精确数据尽在图中1. 图表中的统计与分析
(1)基本统计:均值、标准差、置信区间、t检验、方差分析
(2)回归分析:如何展示线性与非线性关系
(3)p值与信号:如何标注统计显著性
(4)RMSE与R²:图中显示回归模型评估指标RMSE、R2等
(5)注释与细节:如何通过注释和细节增强图表的可解释性
第六章、地理空间数据的可视化与GIS集成:
地理数据鲜活地图1. 地理信息系统(GIS)与地理空间分布绘图
(1)GIS简介:地理空间数据与GIS工具的应用
(2)空间分布图绘制:地图可视化,热力图与点图
(3)地理数据处理与可视化:如何处理地理坐标与绘图
(4)高分辨率地图导出 + 政治边界合规提醒
(5)融合AI实践应用:地理数据的实际案例分析
第七章、动态与交互式可视化进阶:
图形动态活灵活现1. GIF动图的绘制
2. 审稿意见的常见问题及处理
(1)动图制作原理:如何通过GIF展示数据变化
(2)R与其他工具的动图生成:gganimate、plotly等
(3)动图的应用场景与注意事项第八章、多图合成与出版级排版艺术:
高效布局子刊密码1. 多图合成与高级排版
(1)组图系统:如何在一张页面中合理组合多个图表
(2)高级排版技巧:排版美学与信息传达的平衡
(3)制作长文图表:如何制作长条形图、时间轴等特殊排版
(4)实践应用:结合案例进行多图合成与排版练习
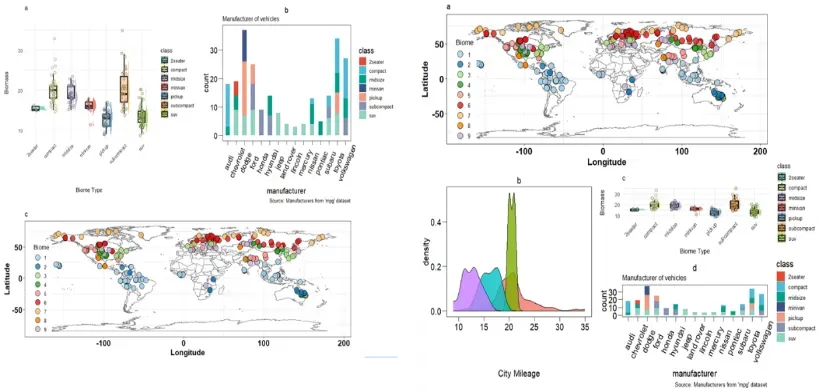
第九章、技术路线图与概念图设计流程:
概念生动逻辑清晰1. 技术路线图绘制
(1)技术路线图的概念与应用:科研工作流程与技术路线
(2)图表设计原则:如何通过图表表达技术流程与进展
(3)实践应用:技术路线图绘制的具体案例
2. 概念图绘制
(1)AI绘图:如何使用AI绘制概念图
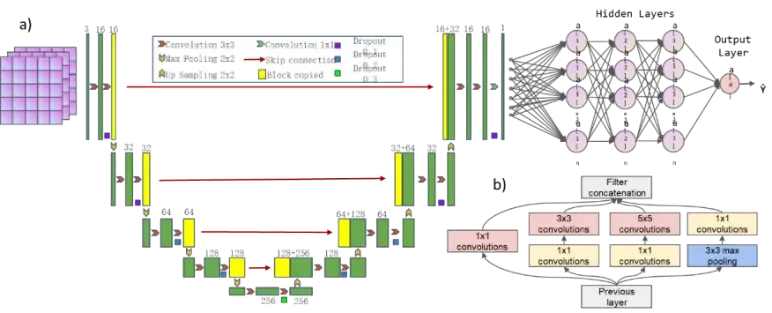
(2)神经网络图:如何使用AI辅助绘图,制作神经网络与机器学习流程图
(3)图形摘要的绘制:如何通过简洁明了的图形总结研究核心
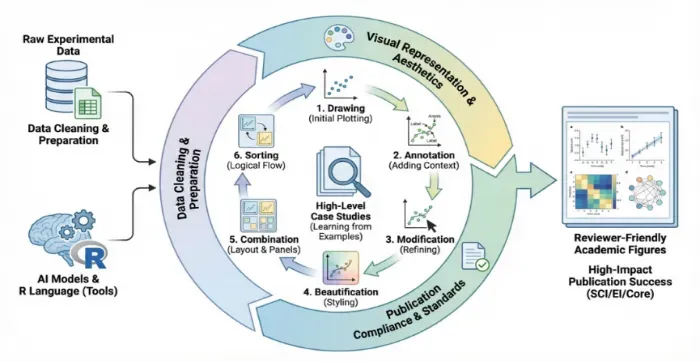
第十章、顶刊图表合规与交流讨论
1.Nature/Science/Cell图表技术规范
2.导出标准格式
3.学术伦理红线
(1)禁止拼接、重复使用、过度平滑(如Western Blot)
(2)图像原始数据保存要求(FAIR原则)
4. Caption与元数据撰写
(1)如何写Figure Legend让审稿人一眼看懂
(2)补充材料中交互图的说明规范课程三

📢 科研真正的挑战从来不是“有没有答案”,而是:如何高效整合信息、持续产生高质量IDEA,并把研究想法快速转化为可发表成果。而这,正是大多数通用AI使用方式所无法解决的。
本课程是一门面向科研人员、研究生、博士生、高校教师以及高端知识工作者的系统化实战训练营,以“工具即生产力,Agent即科研合作者”为核心理念,带你从“使用AI”进阶到“构建AI系统”。课程将系统讲解如何将主流大语言模型深度融合进:
1.科研写作与论文生产流程
2.实验与科研数据分析
3.文献管理与知识体系构建
4.科研绘图与学术级可视化表达
5.多模型协作的创新型科研思考
6.基于NotebookLM 的研究资料整合、来源引用与可信推理
7.Google生态系统自动化科研工作流与AI Agent系统
通过真实科研场景与完整案例,你将学会如何让AI主动协助你思考、决策与创作,而不仅仅是被动回答问题。
通过本课程,你将不只是学会“使用AI”,而是能够真正做到:
1.构建属于自己的科研AI Agent,让AI成为你的长期研究助手
2.打造可持续复利的个人科研系统,知识与成果持续积累
3.显著提升科研效率与创新能力,减少重复劳动,专注高价值思考
4.让AI成为你稳定、可靠、可进化的科研合作者
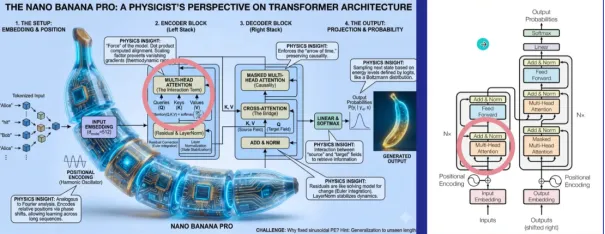
这不是一门“教你玩AI的课程”,而是一门帮助你在AI时代建立长期科研竞争力的系统训练营。最后将总结Google Gemini(Nano Banana),AI Studio,Notebooklm等谷歌一系列生态系统,如何使用这些打造专属个人自动科研系统。
当前AI发展日新月异,大模型迭代速度显著加快,或许有一天人类终将被AI淘汰,但希望你我不是最先被AI淘汰的个人。
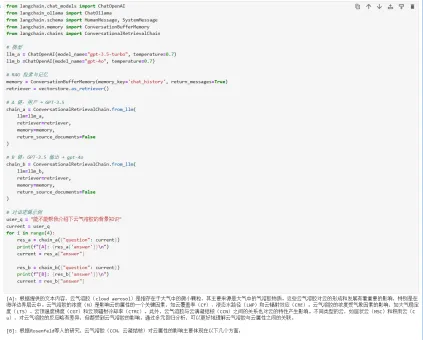
通过大语言模型生成数据统计图



Ollama部署LLAMA/DeepSeek
本地模型性能优化
RAG构建个人知识库
微调vs RAG的选择策略
Open WenUI本地部署,
如何结合Zotero和Open WenUI搭建本地知识系统
在本地环境里构建类似NotebookLM的科研生态系统(不需要科学上网,就能运行)
案例7:
本地部署DeepSeek→构建:
专属科研问答系统
私有文献分析Agent
结课成果:
一个私有科研AI Agent
多LLM分工机制
批判型/创新型Agent设计
自动迭代研究方案
模型的能力越强,Idea的创意更好
案例8:
ChatGPT+Claude→自动进行多轮讨论,生成创新研究方向。
结课成果:
一份「可投稿级研究IDEA说明书」
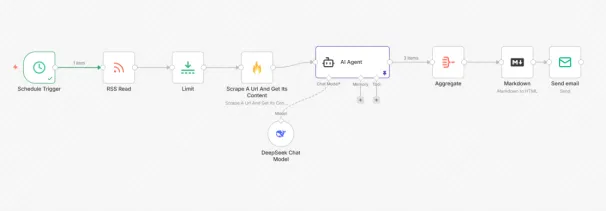
N8N基础与部署
多软件自动联动
多模型优势整合
全流程科研自动化设计
整合Google工作系统流
实战案例
案例9:
构建一个完整系统:
通过DeepSeek创建全自动科研文献搜索总结系统
最终交付:
一套可长期使用的科研文献搜索总结自动化系统

第十一章、Seedance 2.0视频生产大模型基础与科研科普自动化
课程四

📢 【全栈技能,层层递进】
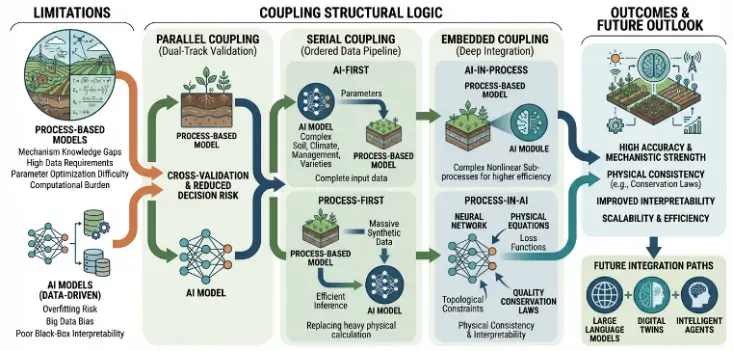
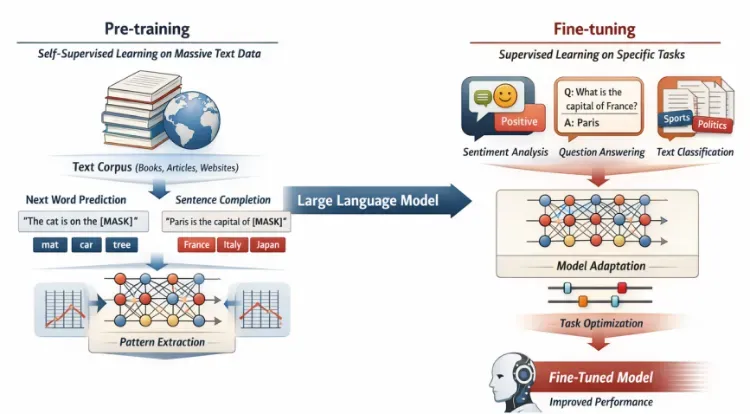
从Python高阶编程(函数式、OOP、性能优化)出发,掌握XGBoost、LightGBM等经典机器学习工具,深入CNN、Transformer、扩散模型等前沿架构;同时以科学问题为牵引,强化SHAP可解释性分析、因果推断与不确定性量化,确保AI模型的物理一致性与科学严谨性。
【革命性效率工具:氛围编程与上下文工程】
告别繁琐的重复编码。课程深度教授Vibe Coding(氛围编程)——通过自然语言与AI协同编程,实现"零门槛"快速原型开发;掌握上下文工程与RAG技术,让大模型精准理解您的领域数据,自动生成可执行的分析代码、SQL查询与科研图表,将数据分析效率提升十倍。
【科研自动化:从Chat到Agent的跃迁】
学习构建OpenClaw智能体工作流,让AI自主完成数据清洗、多维度归因分析、假设检验与报告生成。通过MCP架构连接您的本地数据库与计算环境,实现"一句话需求→自动化分析→交付洞察"的端到端科研流水线,彻底解放您的生产力。
【差异化优势】
实战导向:9大案例模块覆盖图像光谱分析、时空序列预测、科学归因、论文Idea探索等真实场景
人机协同:不仅教算法原理,更教"如何指挥AI做科研"——从提示词设计、代码审查到多Agent协作
前沿融合:传统统计思想 × 现代深度学习 × 大模型自动化三重视角,打通从算法理解到科研落地的最后一公里
本课程将为您提供兼具学术严谨性、工程实用性、技术前瞻性的学习平台。让AI成为您科研团队中最得力的智能助手,加速从数据洞察到科学发现的全过程。
课程五

🎁 学员课前准备
为确保每位学员都能顺利上手实操,课程开始前一周将讲解详细的环境配置教程,并提供一份配置说明文档,助你轻松搞定复杂环境搭建!
1.安装好Python、Git、VS Code
2.准备至少1-2个可调用API的模型账号
3.准备安装或已安装OpenClaw、Hermes、Cursor、Claude Code、Codex
4.自带一个科研题目、一份数据样例或2-3篇代表性论文,便于课堂演练
5.若计划实操本地部署,建议电脑具备较大内存或可连接GPU服务器
🎯课程结束后建议交付成果
1.一个已完成基础配置的OpenClaw科研环境
2.一份《科研任务-模型-Token选型卡》
3.一份《本地大模型部署与接入说明卡》
4.一份《科研Agent编程工具对比表》
5.两个科研Skill初稿
6.一份《科研MCP接入蓝图》
7.一份《科研云端数据管理与下载流程模板》
8.一套个人多模型论文写作自动化流程图
9.一份《个人OpenClaw科研助手搭建方案》
10.一份《NotebookLM、Claude Code、Obsidian的知识工作流》
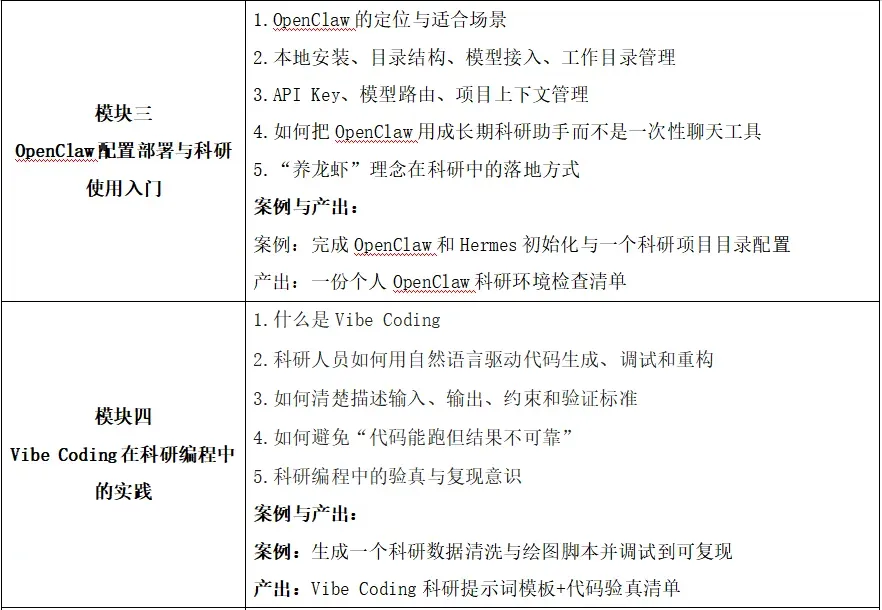
⚡ 培训目标
1. 独立完成 OpenClaw、Hermes的安装、配置、模型接入与基础使用。相对于Openclaw,Hermes具有自我成长的功能。
2. 理解 Token、上下文窗口、调用成本与模型能力边界
3. 学会比较并选择不同大模型,尤其是 DeepSeek 、Qwen、Chatgpt、Opus、Gemma4、Kimi、GLM、Minimax
4. 掌握开源大模型本地部署的基本路径,如Ollama的适用场景,Ollama本地部署Gemma4和Qwen3.5后运行Claude,保存本地数据隐私性。Openclaw、Codex、Claude Code运行本地大模型
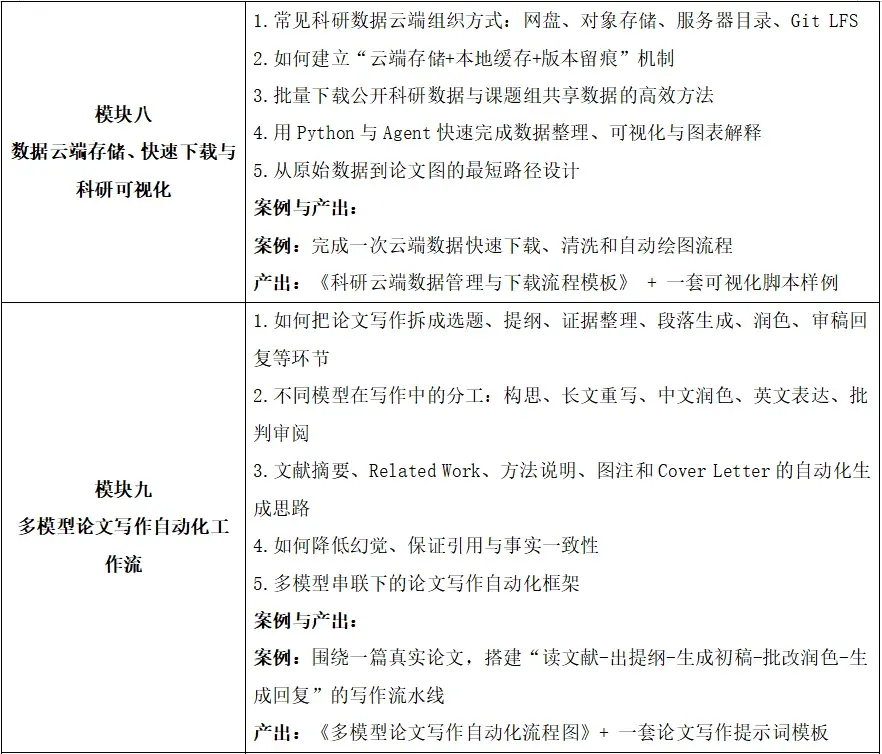
5. 学会建立科研数据的云端存储、快速下载与版本化管理流程
6. 掌握Vibe Coding在科研编程中的正确工作方法
7. 学会用Agent完成科研数据可视化与结果解释
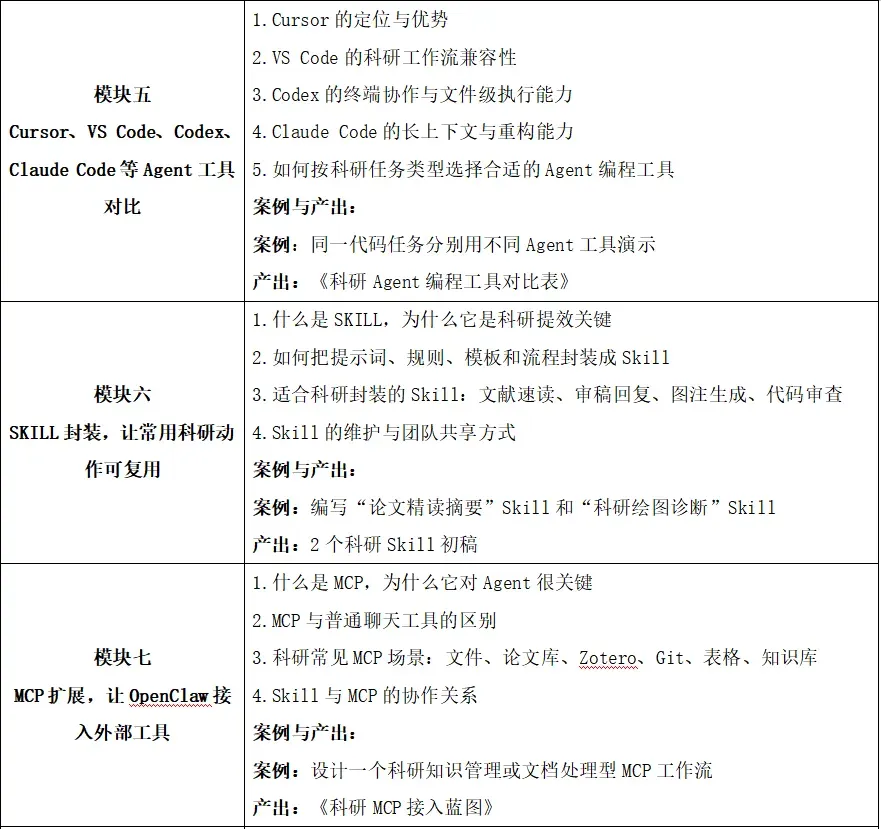
8. 学会使用Cursor、VS Code、Codex、Claude Code 完成科研代码任务
9. 学会编写科研SKILL,理解MCP的扩展价值
10. 设计一套属于自己的多模型论文写作自动化工作流
11.掌握一套从NotebookLM、Claude Code、Obsidian知识管理自动化工作流(无论是老师还是学生都可以复现MIT研究生48小时掌握一门课)
12.通过Hermes Agent生成Karpathy的LLM-Wiki的Obsidian知识库
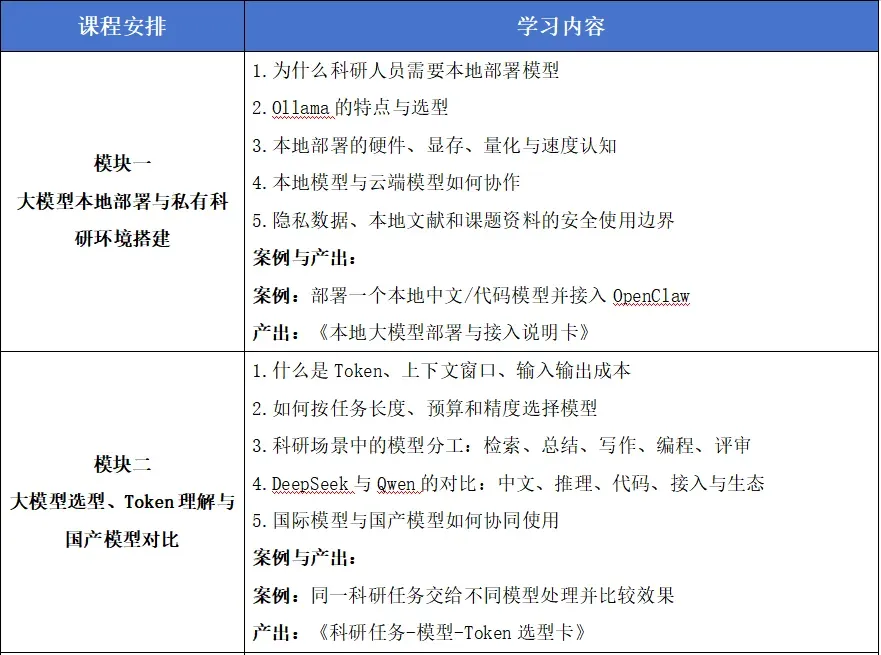
📢重点专题说明
1.如何讲清楚Token选择:
1)Token是模型处理文本的基本计量单位,不等于简单字数
2)选模型不仅看“聪不聪明”,还要看上下文、速度、成本和稳定性
3)真正高效的科研工作流通常是多模型分工,而不是只用一个最贵模型
4)要教会学员把高质量模型用在关键步骤,把高性价比模型用在重复步骤
2.中国两个大模型与美国三个大模型对比:
1)DeepSeek适合推理链、代码、数学与结构化任务
2)Qwen适合中文理解、通用办公、生态兼容和平台接入
3)Gemini的Nano Banana适合绘图
4)Opus搭配Claude Code适合写代码和论文
5)Chatgpt5.4搭配Codex适合执行任务
6)教学中应强调“任务分工”而不是简单比较谁更强
3.如何“养龙虾进行科研”:
1)长期培养一个懂你课题和工作习惯的科研助手
2)用规则、Skill、MCP、知识材料和模板持续迭代Agent
3)把每次科研实践沉淀成可复用的流程资产
4.本地部署与云端协同:
1)敏感数据、私有材料和高频重复任务优先考虑本地模型
2)高质量推理、长文写作和复杂审阅可调用云端强模型
3)最实用的方案往往不是全本地或全云端,而是“本地保密+云端增强”的混合策略
📋 课程内容简要

课程六

📢 课程核心差异化
1.真实数据驱动:使用Cochrane/JAMA已发表RCT的真实数据,非模拟数据,可溯源至原始文献。
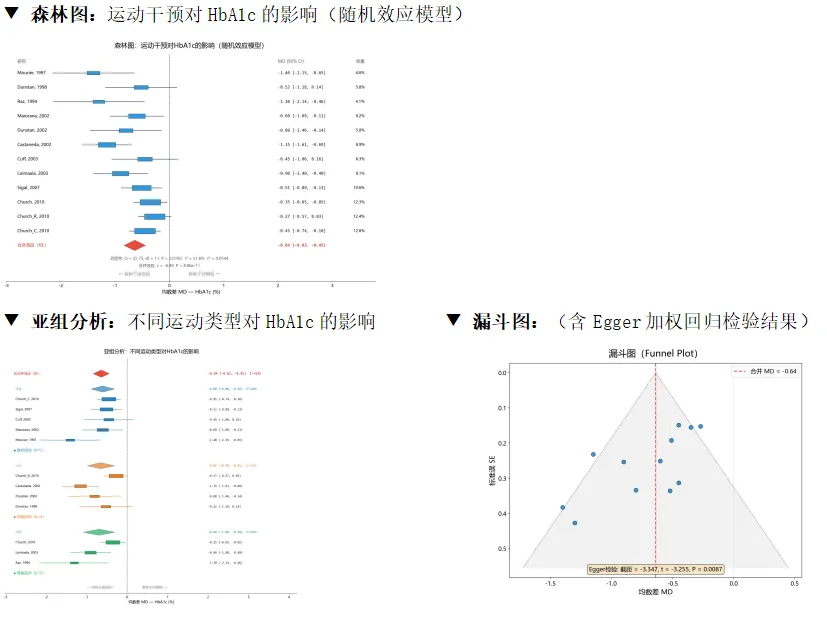
2.一条主线贯穿:从PICOS设计→PubMed检索→AI筛选→效应量计算→DL随机效应模型→森林图→漏斗图→亚组分析→敏感性分析→Results段落,两天做完完整Meta-Analysis。
3.AI深度提效:用Hermes Agent自动生成检索式、批量筛选文献、运行统计脚本、生成投稿级图表、撰写Results段落——亲眼见证AI把传统2周的工作压缩到2小时。
4.代码经双轮审阅:所有脚本经两轮代码审阅(Codex Review),Egger检验修正为加权回归(WLS)、SMD方差统一为含J²的Hedges标准公式、PRISMA计数改为动态计算,统计公式逐项验证。
5.带走你的专属科研智能体:你将带走一个配置好的Hermes Agent和Meta-Analysis统计Skill,利用其自进化能力,未来可一键复用到你的任何课题中。
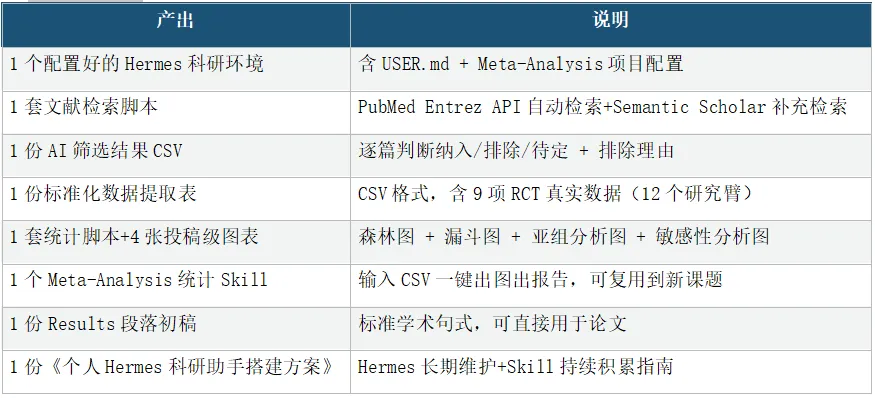
📢 课程完整产出
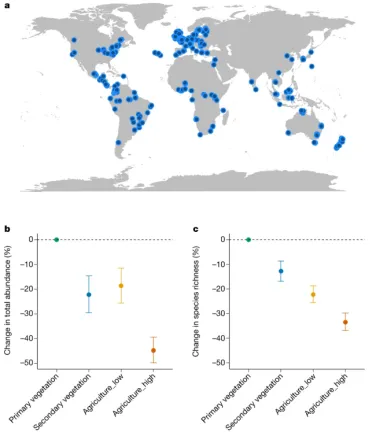
📢 【课程产出图表示例】(以下均为课程真实数据生成)
📅 培训时间
直播时间:5月30日-31日(腾讯会议直播)
🎯 培训方式
在线直播+助学群辅助+导师面对面实践工作交流
📋 课程内容简要
第一天:Hermes部署 + AI辅助文献检索与筛选
产出:Hermes科研环境 + 检索脚本 + 筛选结果 + 数据提取表
模块一、Hermes Agent部署与科研配置
1、Hermes安装→模型接入(DeepSeek/OpenAI/Anthropic)→验证运行
2、模型选择策略:Opus写作/Sonnet编码/Haiku批量筛选/Ollama本地
3、配置USER.md:让Hermes从通用助手变成"你的课题组成员"
4、备用方案:Claude Code替代+预录数据集兜底
模块二、PICOS设计与检索策略
1、AI辅助检索策略设计:Hermes生成PubMed检索式+MeSH词扩展
2、检索式逻辑完整性检查
3、其他学科案例展示(大气科学、心理学、教育学)
模块三、AI自动化文献检索与初筛
1、PubMed Entrez API批量检索(Biopython) 产出:检索脚本
2、Semantic Scholar补充检索 + 去重合并
3、AI辅助标题摘要筛选(逐篇判断+排除理由) 产出:筛选CSV
4、PRISMA 2020流程图生成(matplotlib动态计算)
模块四、数据提取与效应量计算
1、数据提取表设计+AI辅助PDF数据提取
2、效应量计算:均数差(MD)+标准化均数差(Hedges'g,含J校正)
3、使用课程真实数据(9项RCT/12臂,含Church 2010三臂试验说明)
第二天:统计分析 + Skill封装 + 个人落地
产出:4张投稿级图表 + 统计Skill + Results段落 + 个人方案
模块五、Meta-Analysis统计分析
1、DerSimonian-Laird随机效应模型(手动实现5步算法,纯numpy)
2、异质性检验:Q统计量、I²、τ²产出:统计报告
3、森林图:权重方块+合并钻石+数值标注(纯matplotlib)
4、亚组分析:按运动类型分组+组间异质性Q_between
5、漏斗图+Egger加权回归检验(正确WLS实现)
6、Leave-one-out敏感性分析 产出:4张投稿级图表
模块六、Skill封装与Hermes进化
1、将全套统计流程封装为Hermes Skill(输入CSV一键出图出报告)
2、Hermes自动优化Skill+团队共享方式
3、MCP扩展简介:Zotero文献管理、批量读PDF
模块七、AI辅助结果解读与写作
1、Hermes自动解读统计输出→生成Results段落初稿
2、标准学术句式模板(效应量+CI+P值+异质性描述)
3、AI写作边界:擅长格式化结果描述,需人工核验数值和引用
模块八、综合演练与个人落地
1、两天流程回顾:PICOS→检索→筛选→提取→统计→解读
2、学员自选题实操(60分钟):用自己的选题走全流程
3、Hermes长期维护方案:持续进化+Skill积累
4、Q&A+课后资源发放。
注:请提前自备电脑及安装所需软件。
📞 报名咨询
微信二维码:


| 线上、线下课程安排 |
AI赋能R-Meta分析核心技术:从热点挖掘到高级模型、助力高效科研与论文发表"培训班
直播时间:4月24日-27日
关于举办“OpenClaw+Vibe Coding核心实战玩法,手把手教你本地部署与云端协同,“养”出隐私安全且强大的科研辅助”培训班
直播时间:5月23日-24日
第四期: 2026基于前沿AI-Agent2.0驱动的科研全链路实战营: 一站式掌握LLM与Notebooklm应用、数据分析、自动化编程、文献管理到论文写作的核心技能、手把手搭建本地LLM与Agent,体验多模型“圆桌会议”的头脑风暴、基于N8N与OpenClaw、Claude Code构建从文献挖掘到成果产出的自主智能体、解锁Seedance2,轻松将论文转化为高质量的科研科普视频
直播时间:6月5日-8日
最新AI-Python机器学习、深度学习核心技术与前沿应用及Agent自动化全链路实践高级研修班
直播时间:5月16日-17日、23日-24日
一图胜千言-顶刊级科研绘图工坊暨AI支持下的Nature级数据可视化方法与实战
直播时间:5月15日-16日、22日-23日
最新AI+Python驱动的高光谱遥感全链路解析与典型案例实践高级培训班
直播时间:5月22日-23日、29日-30日
北斗高精度数据解算实战:破解城市峡谷/长基线/无网区难题,从毫米级定位到自动化交付的全流程攻坚进阶培训班
直播时间:5月21日-24日
直播时间:5月30日-31日、6月6日-7日
三维地质建模全链路实践技术——从数据清洗预处理到复杂构造建模、矿体圈定与储量估算培训班
直播时间:4月28日-30日
最新合成孔径雷达干涉测量InSAR数据处理、地形三维重建、形变信息提取、监测等实践技术应用高级培训班
直播时间:5月9日-10日、16日
第八期:融合DeepSeek、GIS 与 Python 机器学习的全流程地质灾害风险评估、易发性分析、信息化建库、灾后重建及SCI论文成果撰写高级培训班
直播时间:5月13日-14日、18日、20日-21日
从机理到实践告别“黑箱”模拟:0penGeaSys(0GS6)多物理场 THMC 全耦合建模与 Python 自动化分析高级实战营
直播时间:5月23日-24日、30日-31日
最新Hermes Agent 技能封装与科研自动化实战:以 Meta-Analysis 为例-实现从文献检索到绘图的一站式工作流培训班
直播时间:5月30日-31日





A尚研修简学践行,您随行的导师平台


NO1:平台逐步建立完整的教学方案,深度促进科研交叉技术融合,成为众多课题组及个人实践技术提升首选内容。
NO2:Ai尚研修为了更好的发展,特邀30多位专家学者作为顾问专家,为Ai尚研修平台长期发展提供了宝贵的建议及工作指导。
NO3:Ai尚研修创建云导师教学模式,最大化促进交叉学科的专业问答及交流,已经建立云导师社群300+,不仅可以学习,还为您身边带来专业的导师。
NO4:Ai尚研修建立了长期免费学术讲座:聚焦基础原理、前沿热点技术、庖丁解文、实践技术、成果推广等专题,每月4期左右,已开展完200+期,上平台都可以免费观看前期讲座。
NO5:为了深度对接用户需求,依托专家团队,针对技术咨询服务、数据处理合作、软件开发、搭建高性能计算平台等领域开展合作。
云导师【点亮科研简学践行、您的随行导师平台】
超级会员专享


END
声明: 本号旨在传播、传递、交流,对相关文章内容观点保持中立态度。涉及内容如有侵权或其他问题,请与本号联系,第一时间做出撤回。
END
Ai尚研修丨专注科研领域
技术推广,人才招聘推荐,科研活动服务
科研技术云导师,Easy Scientific Re
search
