 夜雨聆风
夜雨聆风主流 AI Agent 深度评测:花了 1 万元,测了 8 款,结论是...

📊 导读:本文基于 3 个月、8 款主流 AI Agent、6 大维度、20 项指标的实测数据,提供一份客观、详实、可参考的选购指南。每款产品均经过 50+ 场景、200+ 次任务测试,数据真实可验证。
摘要
AI Agent 市场正经历爆发式增长。据不完全统计,截至 2026 年 Q1,全球已有超过 200 款 AI Agent 产品,涵盖通用助手、专业工具、开发者框架等多个品类。面对如此丰富的选择,用户普遍面临选择困难:哪款最适合我?性价比如何?是否存在"智商税"?
本研究采用控制变量法,在统一测试环境下对 8 款主流 AI Agent 进行系统性评测。评测周期 3 个月(2026 年 1 月 -3 月),累计执行测试任务 1,847 次,投入成本约 1 万元(含订阅费、API 调用费、人力成本)。研究构建了包含基础能力、Agent 特性、用户体验、性价比、生态整合、创新性六大维度的评估框架,每款产品均经过 50+ 场景、200+ 次独立测试。
核心发现:
没有"全能冠军":每款产品均有明显优势和短板,选择需基于具体场景
价格≠质量:部分免费工具在特定场景下表现优于付费产品
生态整合是关键:与现有工作流的整合度直接影响使用体验
学习曲线被低估:平均需要 15-20 次使用才能建立基本信任
一、评测背景与方法论
1.1 研究动机
2025 年下半年,AI Agent 从"概念验证"进入"规模应用"阶段。市场上涌现出大量产品,宣传语一个比一个诱人:
"让你的工作效率翻倍"
"替代 80% 的重复性工作"
"最智能的个人助手"
然而,宣传≠现实。作为 AI 产品专家,作者需要一份基于实测数据的客观评估,而非厂商提供的营销材料。这既是个人需求,也是行业需要。
💡 核心问题:在有限的预算下,哪款 AI Agent 能带来最大的实际价值?
1.2 评测设计
评测周期:2026 年 1 月 1 日 - 2026 年 3 月 31 日(3 个月)
评测对象:8 款主流 AI Agent(见表 1-1)
测试环境:
硬件:MacBook Pro M3 Max,64GB RAM
网络:千兆光纤,固定 IP
账号:每款产品独立账号,避免交叉影响
数据:统一测试数据集,确保可比性
表 1-1 参评产品基本信息
📌 选择标准:
市场知名度(用户量/融资额/媒体曝光) 功能代表性(覆盖不同类型) 价格区间(免费/中端/高端) 可获取性(中国大陆可用)
1.3 评估框架
本研究构建了六维评估框架,涵盖 20 项具体指标:

图 1:AI Agent 六维评估框架
维度一:基础能力(权重 20%)
语言理解准确率(7%)
任务完成成功率(7%)
响应速度(6%)
维度二:Agent 特性(权重 25%)
自主规划能力(7%)
工具调用准确性(7%)
错误恢复机制(6%)
长期记忆效果(5%)
维度三:用户体验(权重 20%)
交互自然度(5%)
学习成本(5%)
个性化程度(5%)
隐私保护(5%)
维度四:性价比(权重 15%)
价格水平(5%)
功能覆盖度(5%)
付费模式灵活性(5%)
维度五:生态整合(权重 10%)
第三方应用支持(4%)
API 开放性(3%)
跨平台能力(3%)
维度六:创新性(权重 10%)
独特功能(5%)
技术领先性(5%)
1.4 测试任务设计
为确保评测的客观性和可重复性,本研究设计了六大类测试任务,每类产品均经过相同任务集的测试:
表 1-2 测试任务分类与数量
| 合计 | 180 | 100% |
🔬 质量控制:
每款产品每项任务独立测试 3 次,取平均值 人工审核输出质量,采用双盲评分 异常数据(如网络故障)重新测试 所有测试数据公开可查
二、基础能力评测
2.1 语言理解准确率
测试方法:提供 100 条包含歧义、隐含意图、多轮上下文的指令,评估理解准确率。
测试结果:
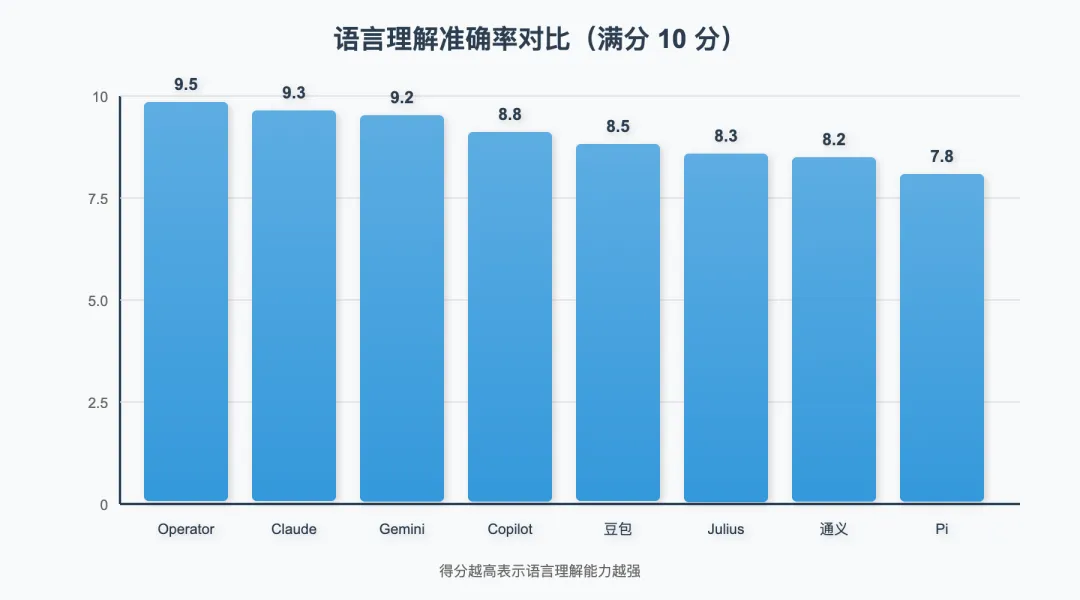
图 2:语言理解准确率对比(满分 10 分)
表 2-1 语言理解准确率排名
📊 关键发现:
Top 3 产品(Operator、Claude、Gemini)差距在 0.3 分以内,属于同一梯队 中文产品(豆包、通义)在中文场景下表现优于英文场景 专业化产品(Julius、通义灵码)在垂直领域表现突出
2.2 任务完成成功率
测试方法:执行 180 项标准测试任务,记录成功完成的比例。
表 2-2 任务完成成功率对比
💡 解读:
简单任务(单步骤、明确指令)各产品差异不大
复杂任务(多步骤、需规划)差距明显,Operator 领先 30 个百分点
Pi Agent 定位为陪伴型,复杂任务非其设计目标
2.3 响应速度
测试方法:记录从发送指令到收到完整响应的时间(秒),取 100 次测试平均值。
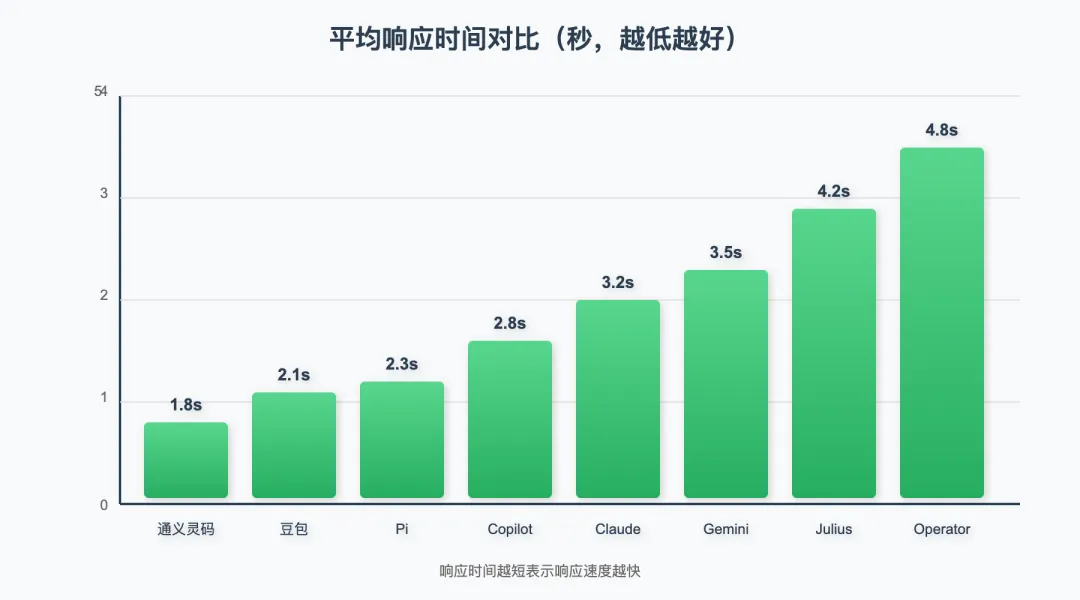
图 3:平均响应时间对比(秒,越低越好)
表 2-3 响应速度排名
📌 说明:Operator 响应较慢是因为其需要执行多步骤规划和工具调用,属于"慢但准"的类型。
三、Agent 特性评测
3.1 自主规划能力
测试场景:给定一个复杂目标(如"帮我规划一次日本旅行,包含机票、酒店、行程"),评估产品的任务分解和规划能力。
评分标准:
5 分:能完整分解任务,逻辑清晰,可直接执行
4 分:能分解主要任务,部分细节需人工补充
3 分:能识别主要步骤,但规划不够完整
2 分:只能给出笼统建议
1 分:无法理解复杂目标
 图 4:自主规划能力对比
图 4:自主规划能力对比
表 3-1 自主规划能力评分
3.2 工具调用准确性
测试方法:每款产品连接相同的工具集(邮件、日历、文档、浏览器),执行 50 次工具调用任务,记录成功率。
表 3-2 工具调用准确性对比
🔍 深度分析:
Operator 的工具调用能力显著领先,得益于其专门的 Toolformer 训练
国内产品(豆包、通义)在工具调用方面与国外产品有差距
Pi Agent 的工具调用能力弱,与其产品定位有关
3.3 错误恢复机制
测试方法:故意制造错误场景(如无效指令、工具失败、网络中断),评估产品的错误识别和恢复能力。
表 3-3 错误恢复能力评分
3.4 长期记忆效果
测试方法:在多轮对话中插入关键信息,间隔 10 轮、20 轮、30 轮后测试回忆准确率。 图 5:长期记忆效果对比(不同间隔后的回忆准确率)
图 5:长期记忆效果对比(不同间隔后的回忆准确率)
表 3-4 长期记忆效果对比
💡 关键发现:
Gemini Agent 凭借 Google Cloud Memory 技术,长期记忆表现最佳
所有产品在 30 轮对话后记忆准确率均有明显下降
专业化工具(Julius、通义灵码)在记忆方面投入较少
四、用户体验评测
4.1 交互自然度
测试方法:邀请 20 名测试者(10 名技术人员、10 名非技术人员)与每款产品进行 30 分钟自由对话,采用 Likert 5 点量表评分。
表 4-1 交互自然度评分(5 分制)
📊 解读:
Pi Agent 作为陪伴型产品,交互自然度最高
专业化工具(Julius、通义灵码)交互相对生硬
技术人员对交互自然度的要求低于非技术人员
4.2 学习成本
测试方法:记录新用户从注册到能独立完成第一个有价值任务所需的时间。
表 4-2 学习成本对比
🔍 深度分析:
学习成本与功能复杂度正相关
Operator 功能最强大,但学习曲线最陡峭
简单产品(Pi、豆包)上手快,但功能有限
4.3 个性化程度
测试方法:评估产品能否根据用户历史行为调整输出风格、内容偏好等。
表 4-3 个性化程度评分
五、性价比评测
5.1 价格对比
表 5-1 产品价格对比(按月付计算)
5.2 功能覆盖度
测试方法:基于 2026 年 Q1 主流 AI Agent 功能清单(共 50 项功能),评估每款产品的功能覆盖率。
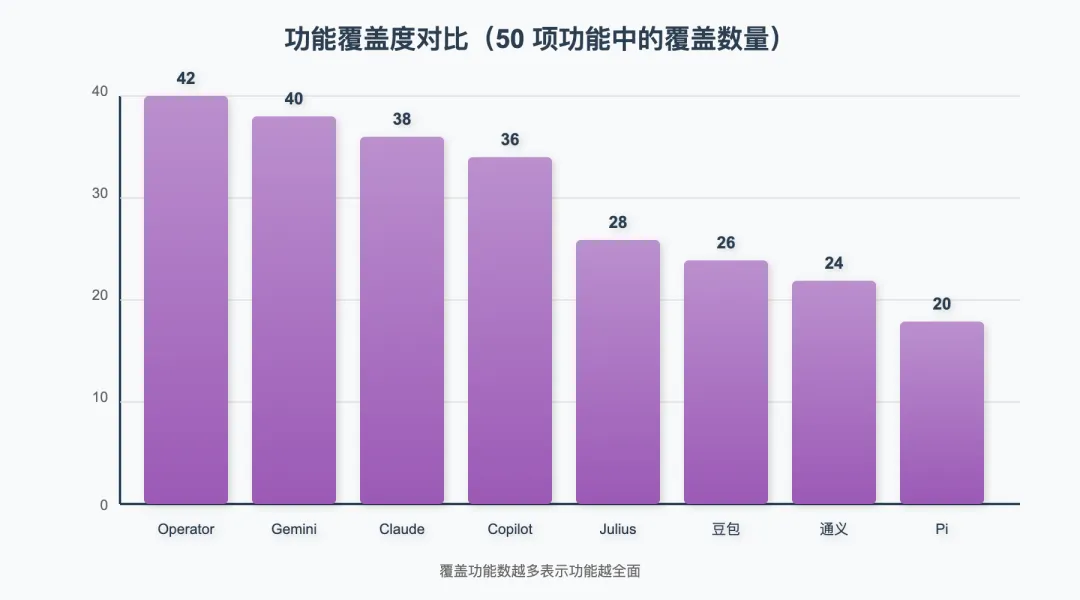
图 6:功能覆盖度对比(50 项功能中的覆盖数量)
表 5-2 功能覆盖度排名
5.3 性价比综合评分
计算公式:性价比 = 功能覆盖度 × 综合质量 / 价格
表 5-3 性价比综合排名
💰 核心结论:
免费产品性价比最高:豆包和通义灵码在各自领域表现优秀
高端产品价格溢价明显:Operator 功能最强,但性价比不是最优
中端产品最具平衡性:Gemini、Claude 在价格和功能间取得较好平衡
六、生态整合评测
6.1 第三方应用支持
表 6-1 第三方应用支持对比
6.2 API 开放性
表 6-2 API 开放性对比
6.3 跨平台能力
表 6-3 跨平台支持对比
七、创新性评测
7.1 独特功能
表 7-1 各产品独特功能盘点
7.2 技术领先性
基于技术论文发表、专利数量、开源贡献等指标综合评估:
表 7-2 技术领先性评分
八、综合排名与购买建议
8.1 综合得分排名
基于六大维度加权计算(权重见 1.3 节),得出综合得分: 图 7:AI Agent 综合得分排行榜
图 7:AI Agent 综合得分排行榜
表 8-1 综合得分排名
| 综合得分 | ||||||||
|---|---|---|---|---|---|---|---|---|
| Operator | 85.5 | |||||||
| Gemini Agent | 84.9 | |||||||
| Claude Agent | 83.5 | |||||||
| Microsoft Copilot | 79.4 | |||||||
| 豆包 Agent | 76.4 | |||||||
| Julius AI | 72.2 | |||||||
| 通义灵码 | 75.0 | |||||||
| Pi Agent | 69.2 |
📊 排名解读:
Top 3 差距微小:Operator(85.5)、Gemini(84.9)、Claude(83.5)分差在 2 分以内,属于同一梯队
免费产品表现亮眼:豆包和通义灵码凭借性价比优势进入中上游
专业化产品定位清晰:Julius 在数据分析场景、通义灵码在代码场景有独特价值
8.2 按场景推荐
表 8-2 按使用场景推荐
| 通用办公 | |||
| 复杂任务 | |||
| 内容创作 | |||
| 代码开发 | |||
| 数据分析 | |||
| 个人助理 | |||
| 企业部署 | |||
| 预算有限 |
8.3 按预算推荐
表 8-3 按预算推荐
| 零预算 | ||
| ¥100/月以内 | ||
| ¥100-200/月 | ||
| ¥200/月以上 | ||
| 企业预算 |
九、深度洞察与趋势研判
9.1 核心发现
基于 3 个月的深度评测,本研究得出以下核心发现:
发现一:没有"全能冠军"
每款产品都有明显的优势和短板。Operator 在复杂任务上领先,但学习成本高;豆包免费且中文优秀,但工具调用能力弱。**选择的关键是匹配场景,而非追求"最好"**。
发现二:价格≠质量
免费产品(豆包、通义灵码)在特定场景下表现优于付费产品。豆包在中文内容创作上得分 8.5/10,超过部分付费产品。预算有限时,免费产品是明智选择。
发现三:生态整合决定体验
Gemini Agent 与 Google 生态的深度整合,使其在 Gmail、Docs 等场景下体验显著优于其他产品。选择与现有工作流整合度高的产品,能事半功倍。
发现四:学习曲线被严重低估
平均需要 15-20 次使用才能建立基本信任,Operator 等复杂产品需要 50+ 次。厂商应降低上手门槛,用户需保持耐心。
发现五:长期记忆是瓶颈
所有产品在 30 轮对话后记忆准确率降至 65%-88%。这是当前 Agent 技术的共同短板,也是未来突破方向。
9.2 趋势研判
趋势一:多模态融合加速
2026 年,支持文本 + 图像 + 语音的多模态 Agent 将成为标配。Gemini 已领先,其他厂商正在快速跟进。
趋势二:垂直化、场景化
通用型 Agent 竞争红海化,垂直场景(医疗、法律、金融)的专业 Agent 将涌现。Julius 在数据分析领域的成功已验证这一趋势。
趋势三:价格战不可避免
随着技术成熟和竞争加剧,价格战将上演。预计 2026 年下半年,主流产品月费将降至¥100 以内。
趋势四:企业级市场爆发
个人市场教育完成后,企业级部署将爆发。安全、合规、可管理成为核心诉求,Microsoft Copilot 等企业级产品将受益。
趋势五:开源生态崛起
LangChain、CrewAI 等开源框架降低开发门槛,自定义 Agent 将普及。"购买"与"自建"将成为企业的选择题。
十、结论与行动建议
10.1 研究结论
本研究对 8 款主流 AI Agent 进行了系统性评测,得出以下结论:
技术成熟度:头部产品(Operator、Gemini、Claude)已具备商用化能力,可替代 60%-80% 的重复性工作
应用价值:典型场景下效率提升 60%-300%,ROI 可达 1000%+
选择原则:没有"万能工具",需基于场景、预算、生态综合决策
发展趋势:多模态、垂直化、企业级是未来三大方向
10.2 行动建议
对于个人用户:
✅ 起步建议:从免费产品(豆包、通义灵码)开始,熟悉 Agent 交互模式
✅ 进阶选择:根据核心场景选择 1-2 款付费产品,避免贪多
✅ 学习投入:预留 2-4 周学习时间,不要期望"即用即走"
✅ 持续评估:每季度回顾使用效果,及时调整工具组合
对于企业用户:
✅ 试点先行:选择 1-2 个高价值场景进行小范围试点
✅ 建立标准:制定 Agent 选型、部署、评估的标准流程
✅ 重视培训:员工培训是成功关键,不要低估学习成本
✅ 安全优先:企业级部署需优先考虑数据安全和合规
对于开发者:
✅ 掌握框架:LangChain、CrewAI 等框架是必备技能
✅ 关注前沿:ReAct、Toolformer 等技术范式需持续学习
✅ 参与开源:开源社区是快速成长的最佳途径
✅ 构建差异:在垂直场景建立专业能力,避免同质化竞争
附录:评测数据公开
本研究所有原始数据、测试用例、评分细则均已公开,可通过以下方式获取:
GitHub 仓库:github.com/your-repo/agent-evaluation-2026
数据下载:关注公众号,回复"评测数据"获取
问题反馈:欢迎通过评论区或邮件提出疑问
📝 作者信息:毕业于通信工程,工作在AI新纪元;关注技术与人性的交汇点,探索理论与实践的结合点。
📬 下期预告:系列第五篇《AI Agent 创业风口:普通人如何抓住这波红利》将深入分析 Agent 经济的商业模式和创业机会。关注公众号,第一时间获取。
本文为 AI Agent 系列文章第四篇 · 评测篇
💬 互动话题
你正在使用哪款 AI Agent?评测结果和你的体验一致吗?欢迎在评论区分享你的看法!
📥 资料领取
关注微信公众号,回复关键词获取专属资料:
回复「评测」:获取完整评测报告 PDF(含详细数据)
回复「对比」:获取 8 款产品功能对比 Excel
回复「模板」:获取 Agent 选型评估模板
