 夜雨聆风
夜雨聆风4月份,国外三家公司几乎同时放大招。
Ahtnropic 发布了编程测试全场第一的Claude Opus 4.7,但是呢,庆祝的人几乎没有,倒是好多人在骂涨价的。
OpenAI 把codex 从一个模型,做成了独立的产品,还开源了命令行工具。
Google 更狠,直接把一个接近旗舰水平的模型 完全开源(Apache 2.9 协议),商用还是干嘛用完全免费。
但是最炸裂的新闻不是上面的,而是Anthropic 做了一个不敢给你用的模型因为“太强了”。
Claude Opus 4.7: 编程测试87.6%,但用户想退回旧版
先说Anthropic。
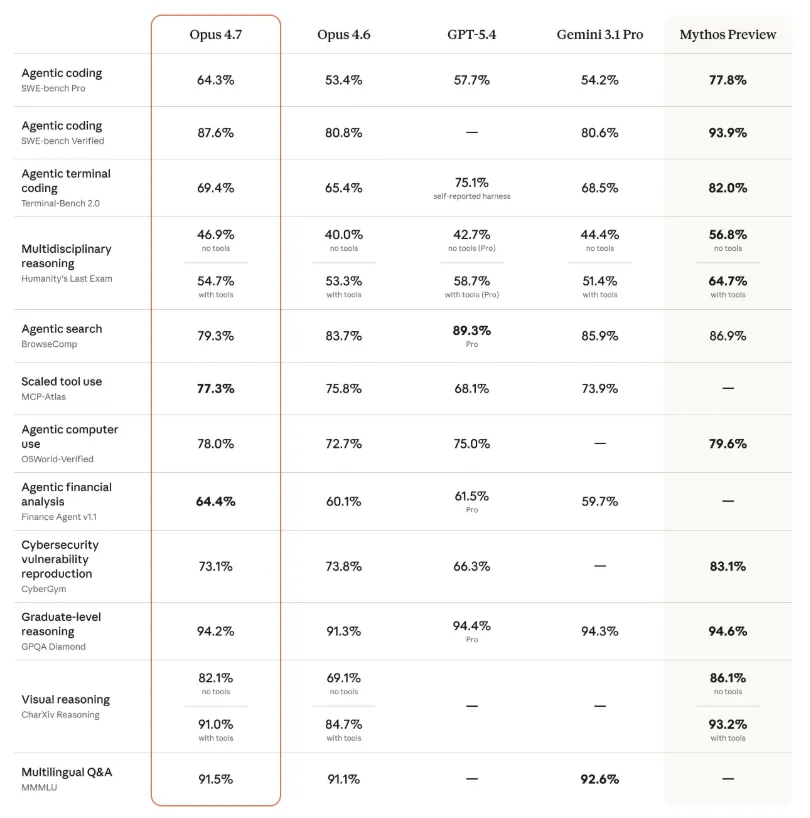
opus 4.7 正式发布出来之后,官方给了一堆的数据,其中最亮眼的是这个SWE-bench Verified 87.6%。
SWE-bench 简单说就是给AI一个真实的Githu Issue,让它自己去读代码,定位问题,修复问题,跑测试。最终结果是 87.6%。 这意味着什么? 意味着你给它10个bug,它自己能修好将近9个。
上一代opus 4.6是 80.8%, Google 的 Gemini 3.1Pro 大约是 83%。OpenAI 的 GPT-5.3-Codex 大约是72%。claude 直接把差距拉到了两位数。
出了编程, Opus 4.7 还升级了视觉能力(能看更高清的图片)、长周期自主工作(能自己去检查自己的代码)、生成更高质量的界面和文档。
听起来很厉害,跃跃欲试的样子是吧。
但是:社区炸了。
1. 钱包炸了
opus 4.7 用了一个新的分词器(Tokenizer)。分词器是指: AI读文字的“切菜方式”——一段话怎么切成一个个的token。不同的切法,token数量不一样。
Anthropic的token定价没变还是$5/百万输入token,$25/百万输出token。 然后是opus 4.7 的新切法。同样的文字内容,token 数量多了1.0~1.35倍。这意味着虽然定价没变,但是你消耗的多了。因为你用了更多的token,实际费用涨了 20%到35%。
更狠的是,Opus 4.7 在高推理等级下会“思考更多”——尤其是在Agent多轮对话的后半段。消耗提升的很明显 很恐怖,但与之对应的可靠性也提升了许多。
还有一个痛点:Claude code 在4.7发布之后,悄悄把默认推理等级从“high”调到了“xhigh”。 xhigh更贵、更慢、但是更准。用户没有主动选择,而是“被动”升级了。
所以大家都在戏称 opus 4.7 为“钱包杀手”,甚至有篇文章的名字就叫做“Claude Opus 4.7 Is Here. So Are the Wallet Jokes.”
2. 老prompt 直接失效
费用还不是最让人崩溃的。
opus 4.7 的指令遵循的更“字面化”了——你说什么它就做什么。不在回去主动的理解你的意图。以前4.6会自动推断、泛化的指令 4.7不干了。
Anthropic 自己都在迁移的指南中提到:“rompts written for earlier models can sometimes now produce unexpected results”—— 给旧模型写的prompt,现在可能产生意外的结果。——更直白的意思就是说“之前你用的很舒服的提示词,现在给4.7用可能会有意想不到结果。”
再加上 Opus 4.7 默认更少调用工具,对于依赖工具链的 Agent 工作流来说,某些步骤可能被跳过。
3. 4.6 本身就已经在“降智”了
更要命的是,在4.7发布之前, 已经有大量用户在吐槽 Opus 4.6 “变笨”。
GitHub 上堆了几个月的"degraded quality"和"incomplete results"投诉。有人做了数据对比,表明Claude 性能下降了 67%(虽然 Anthropic 否认了)。Anthropic 员工公开否认故意降级模型,但承认调整了使用限制。
所以很多的用户的感受就是 4.6不行了。 4.7又太贵,还不如之前的4.6用着舒服。
编程测试拿了第一,用户反而想退回旧版——这大概是 AI 圈最讽刺的一幕。
4. Mythos:太强了,所以锁起来
如果说Opus 4.7 是”明升暗涨“,那mythos 就是 Anthropic 的真正的王牌——但是”我们不配用“。
Mythos的内部代号是Capybara(水豚), 是Anthropic下最强的模型。 在4月7日 发布了一份详细的安全评估报告, 标题是:"Assessing Claude Mythos Preview's cybersecurity capabilities"。
评估 Claude Mythos Preview 的网络安全能力。
报告的核心结论是在说 “ythos 在网络安全领域的能力,远超当前任何公开模型。”
他能做什么?自动发现零日漏洞(之前没人发现过的安全漏洞)、构建攻击链、执行渗透测试。 在之前的测试中发现,Mythos能在所有的主流操作系统和浏览器中发现高危漏洞。
然后Anthropic 做了一个决定: 就是 限制发布。
Mythos Preview 目前仅限通过审核的安全研究人员使用,普通开发者和普通的用户都使用不了。
Anthropic的意思是这样的:Mythos的网络安全能力不是依靠专门的训练 去训练出来的,而是它本身强大的编程能力和推理能力带来的”副产品“,你把编程能力拉的足够的高,那么它就自然而然的能够发现代码里的安全漏洞——然后利用这些漏洞。
就好像本来是为了切菜顺手一直在研究一把绝世好”刀“,当出现之后发现他干别的事情也特别顺手特别强, 那就算了不能让它去做一些其他的事情,还是留存起来吧。
与此同时,Anthropic 搞了一个叫 Project Glasswing 的项目,联合OpenAI、Google一起研究网络安全的问题。为了在AI的网络安全能力继续暴涨之前,先把防御体系建好。
Mythos真的是可以称之为 Anthropic 的最强产品 强到——他们自己都觉得害怕。
OpenAI 从模型到产品
2月份,OpenAI发布了GPT-5.3-Codex。注意这不是一个普通的模型升级,而是一个产品。
codex 之前只是一个模型的名字, 现在变成了一个独立的产品线,有APP、CLI(命令行工具)、有IDE插件,几乎覆盖了程序员的所有的入口。
它(代指GPI-5.3-Codex)的编程能力(SWE-bench 72%)虽然不如Claude opus 4.7,但是 openai的玩法不一样: 它不只是给你了一个API,而是给你了一个AI同事。
你可以一边让它干活,一边跟它对话,调整反响,他不会丢掉上下文。并且openai 说这个模型是“第一个参与了自己训练的模型”——Codex团队用早期版本调试训练过程,管理部署,诊断测试结果。
Codex cli开源了(MIT协议)。这是运行在你终端里的编程Agent,支持多个模型后端,也就是说你可以使用codex cli 来调用 claude、gemini等等。
安全方面openai的做法和Anthropic 的做法不太一样。GPT-5.3-Codex 是 OpenAI 第一个被标记为"High capability"的网络安全模型。它是通过“发布+护栏”不是给锁起来(当然也没有mythos那么强的能力),增加了安全过滤之后,高风险的请求会被自动路由到能力较弱的GPT5.2.
另外,OpenAI 还在 3 月发布了 GPT-5.4,支持原生电脑操作和 100 万 token 上下文窗口。上图所示就是 codex app使用 computer use的能力。
Google:闭源冲性能,开源冲生态

Google的打法, 是这三家里面最具有“阳谋”味道的。
闭源线:Gemini 3.1Pro(2月发布)
ARC-AGI-2得分 77.1%(推理能力测试),SWE-bench月83%,主打 “vibe coding”(氛围编程)和 Agentic coding(自主编程)。Google官方也有所提到说这是 “builder's model”——给开发者用的模型。
开源线:Gemma 4(4月发布)
这才是Google这波的一个大杀招。
Gemma 4 是一个开源模型家族(Apache 2.0协议)有四个尺寸: 1B、4B、12B、27B。商用完全免费,没有任何的限制。你可以使用它做你任何想做的事情,私有化部署进行收费?完全没问题,Google 不会找你收一分钱。
原生多模态(文本+图片+视频+音频)256k上下文窗口,27B的版本在很多的基准测试上已经接近了GPT4的级别。
Google 的策略一目了然。通过闭源模型守住旗舰性能,用开源模型去抢开发者生态。你用Gemma 4开发了应用,以后想升级到Gemini 3.1pro,迁移成本几乎为0——毕竟他们是一个技术栈。
这跟Meta 的 Llama 走的是同一条路,但Google 走的更远,Meta的开源模型在能力上和闭源旗舰还有一些差距,二Gemma 4 的27B已经在逼近Gemini 3.1pro了。
从这三大巨头的动作中看到了什么趋势?
1. 安全从口号变成了真问题。Mythos的限制发布,Project Glasswing 联合竞对制定标准、以及GPT-5.3-Codex 首个"High capability"网络安全标记——这些都不只是公关稿,而是做出了实际行动。
AI的能力已经强到安全不在只是“未来才需要面对的问题”,而是需要受到警醒提前去做准备、迫在眉睫必须要处理的问题。Anthropic 选择锁起来,OpenAI 选择加护栏,Google 选择开源让社区一起审计——三种策略,同一个判断:AI 的网络安全能力已经到了临界点。
接下来,安全合规会从"加分项"变成"入场券"。不是谁模型强谁赢,是谁的安全框架被行业接受谁赢。并且安全合规后续的重要性也是不言而喻。
2. 开源抢生态、闭源守旗舰成为标准打法
Google走的最远(Gemma 4 Apache 2.0)OpenAI 在跟进(Codex cli 开源),而Anthropic 则是完全闭源。
但对开发者来说,一个关键的拐点来了: “开源模型足够用”,那么当开源模型的能力逐渐逼近了闭源旗舰,闭源的溢价就只剩了最后的那 10%-20% 的性能差距,是否值那个价格呢? 这很难评。
3. 从“谁的模型更聪明”变成“谁的agent更好用”
2026年初的这波发布,有一个共同点:大家都在往agent的方向卷。
OpenAI把 codex 做成了独立的产品,Anthropic给 claude code 加了 /ultrareview 和 auto mode,Google 给 Gemini 3.1 Pro 打出了"vibe coding"的标签。
模型是底座,但是决胜点是在产品的体验。 这也是变相的论证了 虽然 claude 的 opus 4.7 编程测试第一,但是大家的反馈却大多数是负面的。
价格战从明面变成了“暗战“
Anthropic:标价不变,换分词器变相涨价 35%。
OpenAI:GPT-5.3-Codex 比 5.2 快 25%,变相降价。
Google:Gemma 4 直接免费。
AI 的价格战已经从"每百万 token 单价"的明面竞争,变成了"实际使用成本"的暗战。谁能让用户花更少的钱办更多的事谁就能赢。Anthropic 的"暗涨"操作,在社区口碑上已经付出了代价。与此同时国内的模型的价格跟之前相比也是在逐步涨价的阶段。
模型的能力差距在缩小,但是产品化和安全框架的差距在拉大
开源模型(Gemma 4)拉平了底座能力——任何人都可以免费获得一个接近旗舰性能的模型。但Agent产品化(codex的完整产品体验,claude code 的深度集成)和安全框架这两个维度却不是开源就能解决的。
4 月的 AI 圈,三家公司,三种策略,一个共同的判断:AI 的能力已经强到需要认真对待安全问题的程度了。
至于谁的路走对了——市场会用钱包投票。Anthropic 已经在第一轮投票中失了分。
还有最近吵的火热的Anthropic 使用claude需要进行身份证明验证,以及禁止中国用户以及中国控资超过百分之50的公司进行使用。背景是 美国对于AI技术出口严格监管。 大家觉得 anthropic的这一“骚操作”是怎么样的呢?
END
关注我们
