 夜雨聆风
夜雨聆风这两天我连续看了 OpenAI 发布的两样东西。
一个是 4 月 15 日 的 Agents SDK 更新。一个是 4 月 16 日 的 Codex 大更新。单看都像常规产品迭代:前者补了 sandbox、memory、skills、AGENTS.md 这些能力,后者把电脑操作、自动化、插件、浏览器、长期任务都纳入进来了。
但把这两件事放在一起看,意思就完全不一样了。
过去大家做 Agent,最先被关注的一直是模型能力。prompt 怎么写,tool call 怎么接,workflow 怎么拼,subagent 怎么拆。很多团队默认以为,只要模型继续变强、提示词继续打磨、工具不断叠加,软件层那些问题后面自然会一起解决。
现在这条路已经走到一个新阶段了。
当行业里为 Agent 试错烧掉的 Token 已经是百亿级别,大家开始补的,是软件层。模型当然还重要,但现在更缺的,已经是运行环境、状态管理、权限边界、失败恢复这些基础工作。
如果你最近也在搭 Agent,对这种变化应该不会陌生。第一版 demo 跑起来时,往往还看不出太大问题。真正部署到生产环境,问题才会集中暴露出来:在自己电脑上能跑,换个环境状态就没了;单次任务能成,链路一长就开始失控;工具接得越多,权限边界越说不清。
这也是我对最近这波变化最核心的判断:
Agent 软件接下来会越来越像一套正常软件。它会有运行时、有工作区、有记忆、有 tracing,也会有越来越清楚的治理边界。
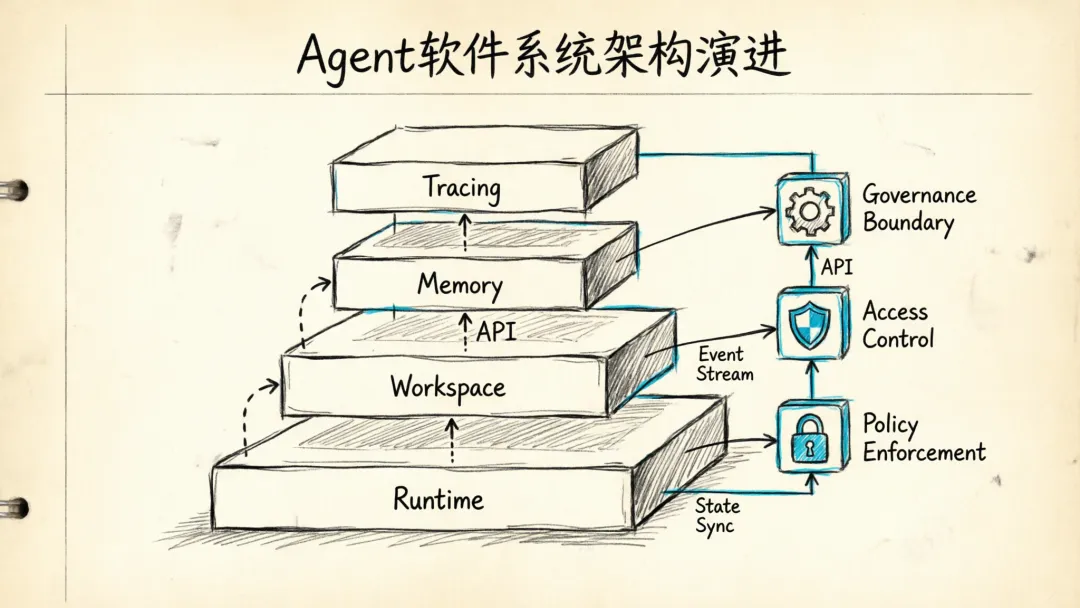
Agent 最先成熟的,会是基础设施层
如果你去看 OpenAI 这次 Agents SDK 的官方说明,最值得盯的不是功能数量,而是它给出了一套很明确的默认栈。
官方原话写得很直白:开发者需要的,不只是更好的模型,还需要一套能让 agent 检查文件、运行命令、写代码、跨很多步骤持续工作的系统。这个判断很关键,因为它等于把过去一年大家在社区里东拼西凑的东西,正式收成了一层基础设施。
这次最关键的几项,我觉得先看 harness。
OpenAI 这次不再把 Agent 讲成一个“带工具调用的模型接口”,而是直接把 model-native harness 写成核心卖点。说得直白一点,就是给 Agent 配一套更像样的运行骨架。模型怎么拿上下文,怎么调工具,怎么读写文件,怎么把任务往下传,这些不再靠每个团队自己乱拼。
然后是 sandbox 开始变成默认配置。
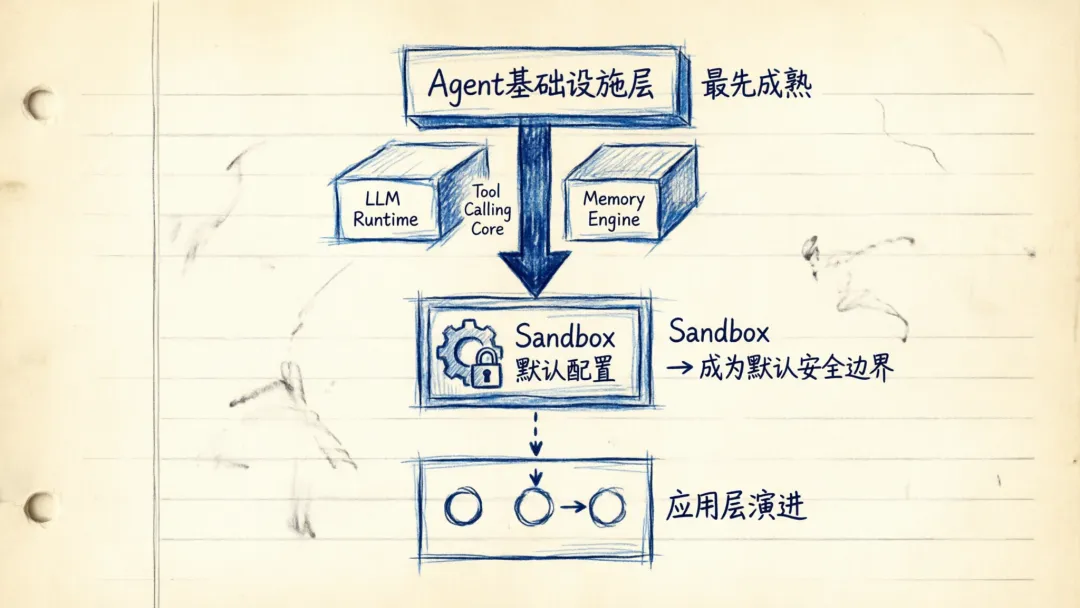
官方这次单独把 native sandbox execution 拎了出来,还给了 Manifest 这种描述工作区的抽象。意思很直接:Agent 以后不是只活在 prompt 和 API 里,它得有一个真正可执行任务的运行环境。要能读文件、装依赖、跑命令、写结果,还要知道输入在哪、输出写哪、断了之后怎么接着跑。
这就已经不是聊天机器人思路了。
再往下看,memory 也开始从技巧变成系统部件。
以前大家说 Agent 有记忆,很多时候指的是“存一点历史记录”或者“把上轮结果再喂回去”。这次 OpenAI 在 SDK 里直接把 configurable memory、sessions、snapshotting and rehydration 这些能力摆出来,意思很清楚:记忆以后会更像运行时状态的一部分,而不是产品经理在外围补的一层能力。
还有一组东西很多人容易忽略:skills、MCP、AGENTS.md。这次它们不是零散功能,而是被标准化地写进同一套栈里。
这件事背后的变化是,Agent 软件终于开始正面处理真实世界的复杂度。它要接外部工具,要接收团队规则,要接受局部知识注入,还要在不同任务里复用经验。靠一长段系统提示词硬扛,已经不够了。
你当然可以说,这些能力开源社区早就有了,今天不过是 OpenAI 把大家熟悉的东西重新打包了一遍。
这话说对一半。
单个组件当然不是今天才有。真正的变化,在于这些东西开始被收敛为默认组合,而且是按“生产环境能不能稳定运行”来收。以前很多团队做 Agent,做着做着就卡在各种工程细节里:本地能跑,一上线就不稳定;demo 好看,恢复不了;能执行,但审计和权限一塌糊涂。走到这一步,行业开始向基础设施层收敛,本身就是成熟信号。
再看 Codex 这次更新,那个方向就更明显了。
OpenAI 在官方博客里写得很直:Codex 现在可以操作电脑、调用更多工具和应用、记住偏好、学习之前的动作,还能接手持续性的、可重复的工作。换句话说,Agent 不再只是等你一句一句使唤的接口,它开始更像一个带工作区、带记忆、带任务链的执行软件。
我觉得这才是这两天最该看的地方。
表层讨论还在围着“哪个 Agent 更聪明”打转,底层已经开始补“Agent 到底应该怎样作为软件存在”。
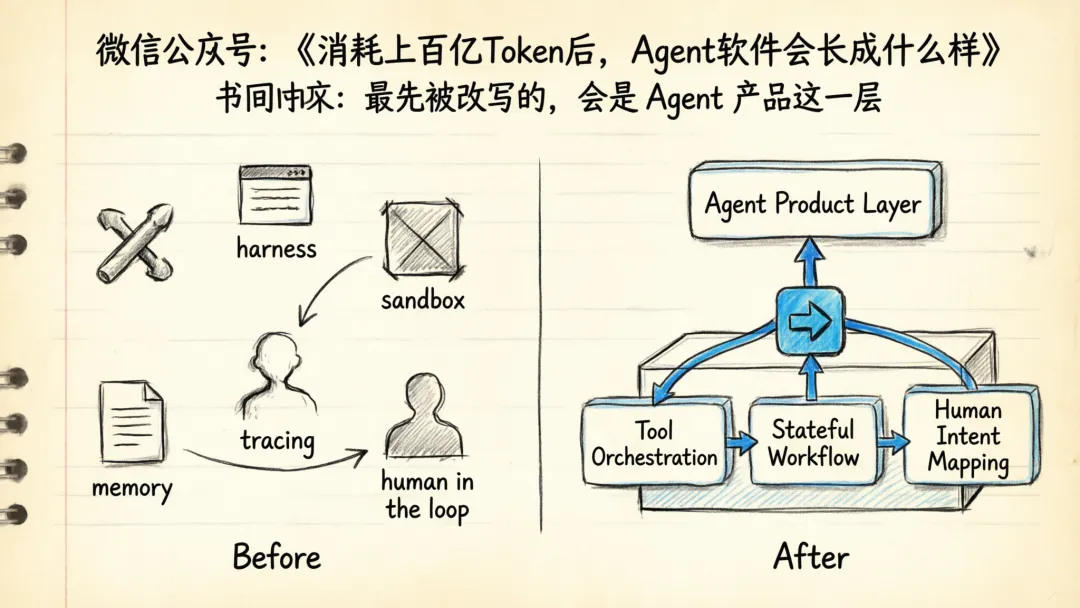
最先被改写的,会是 Agent 产品这一层
这波变化先打到的,不会是所有用户,也不会是所有公司。
最先被改写的,是现在这批 Agent 产品和开发者工具。
过去一年,很多团队还能靠一层包装继续推进:换个 UI,接几把工具,配几套 workflow,外面再包一点记忆和模板,产品就能上线。那时候用户也愿意买单,因为光是“能跑起来”这件事,本身就足够新鲜。
后面这层红利会越来越薄。
原因很简单。等 harness、sandbox、memory、tracing、human in the loop 这些东西慢慢变成 SDK 和平台默认件之后,光靠“我也能调模型、我也能接工具”这层差异,就撑不住了。你得回答更硬的问题:
•你的 Agent 到底在哪个环境里跑?
•它断了之后怎么恢复?
•它能带着状态跑多久?
•它碰到敏感数据怎么隔离?
•它的记忆是产品资产,还是 prompt 垃圾堆?
这些问题一旦摆上桌,很多看起来很热闹的 Agent 产品会突然暴露短板。
对独立开发者来说,这反而是好消息。
因为底层基础工作被平台收走一部分之后,个人开发者更容易把时间放在业务逻辑上,而不是天天手搓运行时。以前要自己拼很久才能跑通的一堆东西,后面会越来越多地直接变成默认能力。门槛会降,但竞争也会更硬。以后更值钱的,不是“你也做了一个 Agent”,而是“你把哪类真实工作做通了”。
对大公司和企业团队,要求会变得更高。
Agent 能不能演示,已经不够了。能不能审计,能不能恢复,能不能进内网,能不能控制权限,能不能把人真正纳入回路里,这些才会决定它能不能进入生产环境。官方这次把 sandbox 和 harness 分开讲,还专门强调安全、持久化和 scale,本质上就在回答这个问题。
还有一类人会先感受到压力:做中间层包装的团队。
如果你的产品核心卖点还是“把几个模型和工具接起来,帮你跑个 Agent”,那后面会越来越难受。因为 SDK 层一旦开始提供更完整的默认栈,用户会问一句很现实的话:你到底替我解决了哪一段最难的脏活?
答不上来,产品就容易被压成一层壳。
这跟早年的 Web 软件很像,而且像得有点过分。
最开始大家都是手搓。路由自己写,认证自己做,状态自己管,部署脚本也得自己拼。后来这些东西慢慢沉到框架、中间件和云服务里,应用层才开始把时间花在业务上。Agent 软件现在就在这个阶段附近。前面那段“手工作坊时代”快过去了,后面会进入一个更像正常软件工业的阶段。
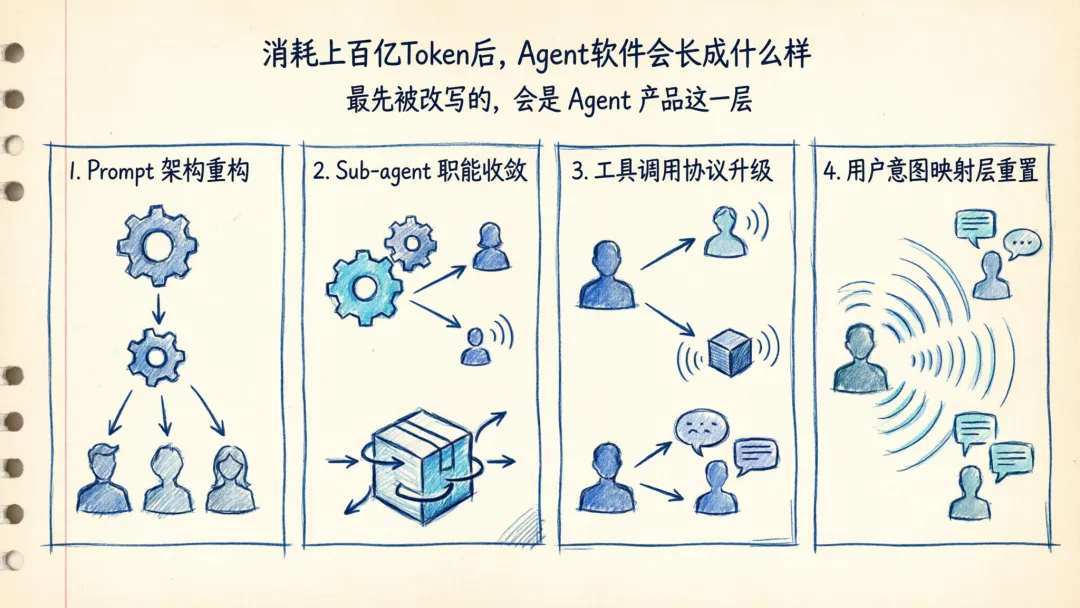
所以今天如果你问我,消耗了上百亿 Token 之后,Agent 软件会长成什么样。
我的回答其实很简单。
它会越来越像一套有运行时、有边界、有状态、有恢复能力的软件系统。模型能力还是发动机,但真正决定这台车能不能长途跑、能不能稳定进入生产环境、能不能交给别人开,已经是软件层那一整套东西了。
这也是为什么我觉得,这两天最值得盯的,不是某个 demo 又惊艳了多少人。
更该盯的,是谁先把 Agent 从一个“能演示的能力”,做成一套“能长期运行的软件”。
如果你今天就想拿这篇去对照自己的项目,先别急着加 prompt,也别急着继续拆 subagent。先把这四件事看清:
•它到底在哪个环境里跑
•它的状态和记忆存在哪
•任务挂掉之后怎么恢复
•哪些动作必须有人接管
这四个问题如果还答不上来,后面大概率还会反复返工。对今天的大多数 Agent 来说,真正的短板已经不在“它会不会答”,而在“这套东西到底能不能稳定地跑下去”。
