 夜雨聆风
夜雨聆风 AI-agent-drug-design vs biopipelines 深度对比解析
AI-agent-drug-design vs biopipelines 深度对比解析
【药物研发智能体】AIDD我开源了——大模型驱动的下一代药物发现与设计体系:AI Drug Discovery 2.0
两个项目均为AI+生物医药领域的开源工具,但核心定位、架构逻辑、能力边界、落地场景存在本质差异:前者是「大模型+多智能体驱动的端到端药物发现系统」,后者是「计算蛋白设计的自动化工作流编排框架」。以下从8个核心维度展开深度对比,所有内容严格基于项目开源文档与官方定义。
一、核心定位与设计哲学(本质差异)
维度 | AI-agent-drug-design(AI Drug Discovery 2.0) | biopipelines |
核心定位 | 大模型驱动的下一代药物发现完整系统,是范式级的端到端解决方案 | 计算蛋白设计领域的自动化工作流编排Python框架,是科研效率工具 |
设计哲学 | 从「人驱动流程」到「AI驱动科学」,核心是用大模型+多智能体重构药物研发全流程,让系统具备自主科研行为能力 | 从「工具碎片化」到「接口标准化」,核心是打通主流生物信息学工具的数据壁垒,让科研人员像写实验记录一样搭建计算工作流 |
终极目标 | 构建可自动发现新靶点、设计候选分子、优化药物性质、迭代科研策略的AI药物发现平台,让药物研发进入「指数级效率时代」 | 为计算生物学家提供开箱即用的蛋白设计工作流脚手架,解决工具安装、格式兼容、集群调度的底层痛点,实现「实验思路即计算流程」 |
范式层级 | 认知层+执行层的全链路重构,是系统工程级的创新 | 执行层的效率优化,是工具集成级的创新 |
二、整体架构与技术体系
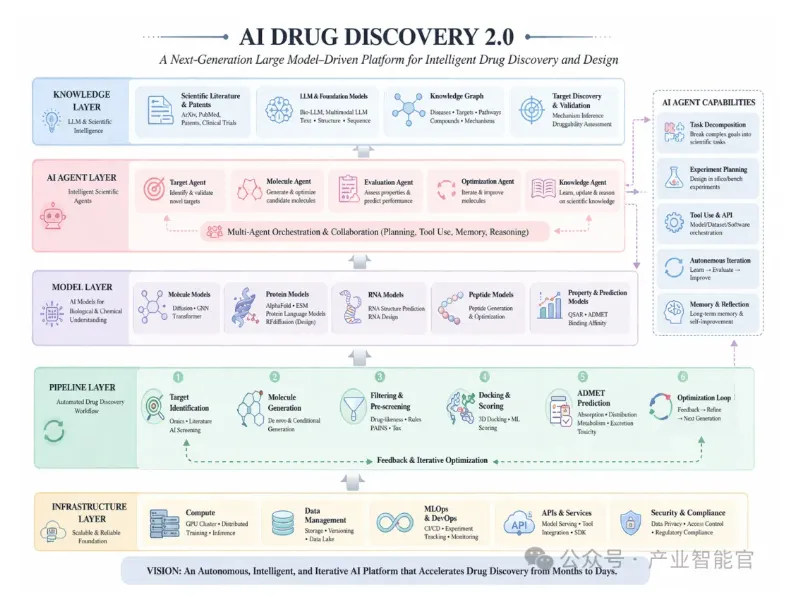
1. AI Drug Discovery 2.0:五层认知驱动架构
项目采用分层解耦的递进式架构,核心中枢是「大模型层+Agent层」,大模型是系统的「大脑」,Agent是系统的「执行决策中枢」,从底层算力到上层应用形成完整闭环:
1.基础层:Python 3.12统一开发体系、GPU/CUDA高性能计算、PyTorch/JAX框架、模块化工程结构,解决规模与效率问题;
2.模型层:AI能力核心,覆盖分子层、蛋白层、RNA/多肽层、性能预测层,封装了扩散模型、GNN、AlphaFold、RFdiffusion等核心模型;
3.大模型层:2.0版本的关键升级,是科学知识理解引擎、文献解析系统、靶点发现系统、分子设计语言接口,实现多模态推理;
4.Agent层:整个系统的核心突破点,构建了Target/Molecule/Evaluation/Optimization/Knowledge五大协同智能体,具备任务拆解、实验规划、自主迭代优化能力;
5.Pipeline层:自动化药物设计流程,串联靶点识别→分子生成→筛选→对接→ADMET预测→优化迭代的完整链路。
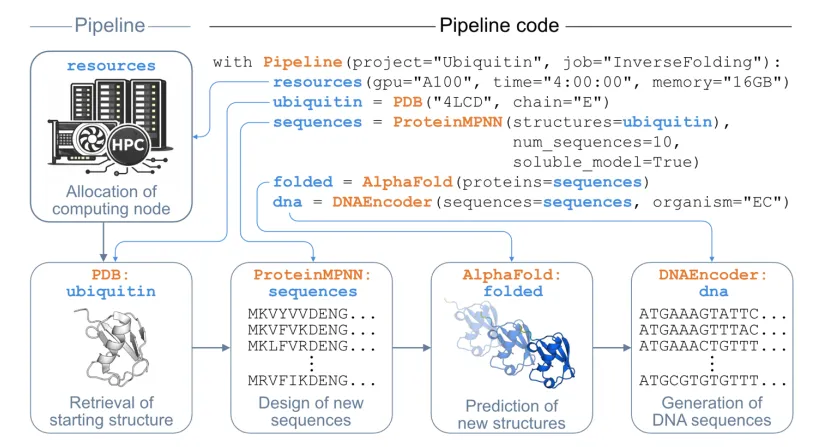
2. biopipelines:模块化工具驱动架构
项目采用**「配置-执行分离」的轻量化架构**,核心是标准化工具接口与工作流节点编排,没有自研的认知层与决策中枢,所有流程逻辑由人工定义:
•核心架构分为:核心框架层、工具封装层、示例工作流、辅助脚本四大模块;
•设计核心:将30+主流生物信息学工具封装为标准化节点,解决不同工具的格式兼容、环境依赖、集群调度问题;
•执行逻辑:用户通过极简的类实验语法定义工作流节点与数据流转逻辑,框架自动生成执行脚本,无缝运行在Jupyter/Colab或SLURM超算集群,无需修改代码。
三、核心能力与覆盖场景
能力维度 | AI-agent-drug-design(AI Drug Discovery 2.0) | biopipelines |
覆盖药物模态 | 全模态覆盖:小分子药物、多肽/环肽、蛋白质/抗体、RNA/核酸药物,适配ADC、基因编辑工具的辅助设计 | 核心聚焦蛋白质/多肽设计,附带小分子化合物库筛选能力,无RNA/核酸药物、完整小分子药物研发链路支持 |
核心功能边界 | 覆盖药物研发早期全流程:<br>1. 靶点发现与验证<br>2. 文献解析与机制推理<br>3. 分子/蛋白/多肽从头设计<br>4. 虚拟筛选与对接评估<br>5. ADMET成药性预测<br>6. 多轮自主优化迭代<br>7. 全流程数据归档与自学习 | 聚焦计算蛋白设计全流程:<br>1. 蛋白反向折叠与序列设计<br>2. 蛋白骨架从头设计<br>3. 配体-蛋白结合亲和力优化<br>4. 化合物库SAR筛选<br>5. 融合蛋白/生物传感器设计<br>6. 蛋白突变体优化 |
自动化能力 | 决策层+执行层全自动化:多智能体自主拆解任务、调用工具、评估结果、调整策略、迭代循环,无需人工干预即可完成端到端研发 | 执行层自动化:仅实现人工定义工作流的自动化执行,流程逻辑、节点参数、优化方向均需人工设计,无自主决策与迭代能力 |
闭环能力 | 完整的「Target→Molecule→Evaluation→Optimization→Feedback」自主迭代闭环,系统可基于评估结果自主启动新一轮优化,实现自学习 | 单工作流的执行闭环,无跨轮次的自主反馈与迭代能力,新一轮实验需人工重新设计工作流 |
四、技术栈与工具集成逻辑
维度 | AI-agent-drug-design(AI Drug Discovery 2.0) | biopipelines |
核心技术栈 | 自研核心:<br>1. 生物医药大模型(BioMedGPT/LLaMA微调)<br>2. 多智能体协同框架<br>3. 端到端Pipeline编排体系<br>集成工具:AlphaFold、ESM、RFdiffusion、ProteinMPNN、DiffDock、Chemprop等,工具作为Agent的调用对象,服务于AI决策 | 无自研核心算法,核心是工具集成与标准化封装:<br>完整集成RFdiffusion、ProteinMPNN、AlphaFold、Boltz2、GNINA、LigandMPNN等30+主流蛋白设计工具,提供统一的Python接口,解决工具间的格式兼容问题 |
大模型能力 | 大模型是系统的核心,承担知识理解、任务拆解、机制推理、决策制定的核心作用,是整个系统的「大脑」 | 无原生的大模型认知能力,无自研的生物医药大模型集成,核心能力不依赖大模型 |
Agent能力 | 自研五大协同智能体,具备工具调用、任务规划、反思优化、多智能体通信的完整能力,是系统实现自主科研的核心 | 无Agent体系,无自主决策、任务规划、反思优化能力 |
工具调用逻辑 | Agent基于任务目标自主判断需要调用的工具、设置参数、解析结果,是AI决策驱动的工具调用 | 人工预先定义工具调用顺序、参数、数据流转逻辑,框架仅负责自动化执行,是人工定义驱动的工具调用 |
五、工程化与部署能力
维度 | AI-agent-drug-design(AI Drug Discovery 2.0) | biopipelines |
部署架构 | 云原生微服务架构,核心模型与Agent均独立封装为Docker容器,通过gRPC/RESTful API通信,支持从本地笔记本到云端GPU集群的规模化部署 | 轻量化脚本化架构,无微服务与容器化设计,支持单机Jupyter/Colab运行,也可提交到SLURM集群执行,核心是科研场景的轻量化部署 |
工程化体系 | 完整的MLOps体系:<br>1. MLflow实现全链路实验追踪与复现<br>2. DVC实现大规模数据集版本管理<br>3. FastAPI构建API网关<br>4. Celery实现异步任务调度<br>5. Milvus向量数据库实现长期记忆与知识检索<br>6. GitHub Actions实现CI/CD持续集成 | 基础的工程化能力:<br>1. 提供环境配置文件与依赖管理<br>2. 支持GitLab CI/CD<br>3. 无原生的实验追踪、版本管理、向量数据库体系<br>4. 核心聚焦工作流执行,无规模化管线运维能力 |
前端交互 | 基于Gradio/Streamlit构建交互式Web界面,支持自然语言输入、任务进度可视化、3D分子结构展示,面向非编程背景的研发人员 | 核心基于Jupyter/Colab笔记本交互,无原生的Web可视化界面,需要基础的Python编程能力 |
算力调度 | 基于Kubernetes实现算力弹性伸缩,支持多GPU并行任务调度,适配大规模分子生成与虚拟筛选场景 | 支持SLURM集群任务调度,无原生的弹性算力管理,适配科研级的中小规模计算任务 |
六、目标用户与落地场景
维度 | AI-agent-drug-design(AI Drug Discovery 2.0) | biopipelines |
核心目标用户 | 1. 药企创新药研发团队<br>2. AIDD领域创业者<br>3. AI+生物医药交叉领域工程师<br>4. 具备基础研发能力的生物/化学科研人员 | 1. 计算生物学家/结构生物学家<br>2. 蛋白设计领域科研人员<br>3. 酶工程/合成生物学实验室<br>4. 具备基础Python能力的实验组科研人员 |
核心落地场景 | 1. 创新药早期研发全流程(靶点发现→先导化合物优化)<br>2. 管线级的小分子/蛋白/多肽药物研发<br>3. 企业级AI药物发现平台搭建<br>4. 突发传染病的快速药物研发 | 1. 学术科研中的蛋白从头设计与突变优化<br>2. 酶改造、生物传感器设计、抗体表位设计<br>3. 小分子化合物库的虚拟筛选与SAR分析<br>4. 科研工作流的复用与规模化执行 |
商业化潜力 | 具备完整的商业化落地能力,可直接作为药企的AI药物研发平台,支撑管线级项目 | 核心定位是学术科研工具,无完整的商业化管线支撑能力,主要解决科研场景的工作流自动化问题 |
七、核心优势与现存局限
AI-agent-drug-design(AI Drug Discovery 2.0)
核心优势:
1.范式级创新:国内首个开源的「大模型+多智能体」驱动的端到端药物发现系统,实现了从「人工试错」到「AI自主科研」的范式重构;
2.全链路覆盖:从靶点发现到候选分子输出的完整闭环,覆盖小分子、蛋白、多肽、核酸全药物模态,是目前开源领域覆盖最完整的AIDD系统之一;
3.工程化完善:微服务架构、容器化部署、完整的MLOps体系,支持从科研原型到工业化落地的无缝迁移;
4.低门槛使用:支持自然语言驱动的药物设计,非编程背景的药物化学家也可快速上手,无需掌握底层算法细节。
现存局限:
1.对算力要求较高,完整的端到端流程需要GPU集群支撑,单机运行效率有限;
2.全流程的可解释性仍需提升,Agent的自主决策逻辑需要更完善的人工校验机制;
3.湿实验验证的管线级案例仍需持续积累,工业化落地的完整验证数据有待补充。
biopipelines
核心优势:
1.工具集成度高:开箱即用整合了30+主流蛋白设计工具,解决了工具安装、格式兼容、环境依赖的行业痛点,大幅降低了AI蛋白设计的使用门槛;
2.轻量化高兼容:同一套代码可无缝运行在Colab笔记本和SLURM超算集群,无需修改,适配学术科研的多样化算力环境;
3.场景深度适配:聚焦蛋白设计领域,提供了大量现成的示例工作流(反向折叠、激酶结构域重设计、FRET生物传感器优化等),科研人员可直接复用;
4.开源社区活跃:苏黎世大学学术团队持续维护,有完整的文档与教程,适配最新的蛋白设计模型与工具。
现存局限:
1.无自主决策与迭代能力,仅能执行人工定义的工作流,无法实现端到端的自主研发;
2.覆盖场景窄,核心聚焦蛋白设计,对小分子药物研发的全流程、靶点发现、核酸药物设计的支持极弱;
3.工程化能力有限,无微服务化、规模化部署的能力,无法支撑企业级管线研发;
4.无大模型认知能力,无法实现自然语言驱动的工作流设计、文献解析、机制推理。
八、差异化总结与互补性
核心差异化一句话总结
AI Drug Discovery 2.0是「AI驱动的药物研发大脑」,核心解决「药物研发从0到1的自主创新问题」;biopipelines是「蛋白设计的自动化工具箱」,核心解决「科研工作流从1到N的效率提升问题」。
前者是认知层的范式重构,后者是执行层的效率优化;前者是完整的端到端系统,后者是垂直领域的工具框架。
天然互补性
两个项目可形成完美的能力互补,构建更完整的AI药物研发体系:
1.biopipelines的蛋白设计工具链,可作为AI Drug Discovery 2.0模型层的补充,强化系统在蛋白/抗体设计领域的工具深度与场景适配性;
2.AI Drug Discovery 2.0的大模型+Agent能力,可为biopipelines提供工作流的自动设计、动态调整、自主优化能力,让biopipelines从「人工定义的自动化」升级为「AI驱动的自主优化」;
3.学术科研场景中,可通过biopipelines完成蛋白设计的精细化工作流执行,通过AI Drug Discovery 2.0完成靶点发现、文献解析、多轮优化的全局决策,形成「AI决策+工具执行」的完整科研闭环。

生物智能:在生物先进产业场景中构建“状态感知-实时认知-自主决策-精准执行-学习提升”的生物科学智能(Biology_and_AI);实现生物产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。

生物产业+物理AI=生物智能
产业智能官:Science_and_AI
加入知识星球“生物智能研究院”:生物产业OT技术(自动化+机器人+工艺+精益)和新一代IT技术(云计算+物联网+区块链+大数据+人工智能)深度融合,在场景中构建“状态感知-实时认知-自主决策-精准执行-学习提升”的生物科学智能;实现生物产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。
版权声明:产业智能官(ID:Science_and_AI)发表的文章,除非确实无法确认,我们都会注明作者和来源,涉权请联系协商解决,联系、投稿邮箱:wolongzy@qq.com
