 夜雨聆风
夜雨聆风1. 选择“启动器”
还是选择 ollama,命令行,适合轻度使用。
所有交互只要打开一个普通的(非管理员)PowerShell 窗口即可。
验证是否运行
> ollama --version
ollama version is 0.21.1
2. 检查硬件
这个笔记本电脑很一般,但是它配备一张英伟达 4GB 的显卡 GTX 1650,因此姑且称它是初级的游戏笔记本电脑。
MSI Prestige 15 A10SC
系统:Windows 11 Home, 25H2
CPU: Intel Core i7-10710U @ 1.10 GHz (1.61 GHz)
内存:16 GB
显卡 GTX 1650 Max-Q, VRAM 专用内存 4 GB
3. 大语言模型选型
还是把硬件的指标告诉 Gemini,以及主要使用场景,譬如希望用它管理 Obsidian 笔记、查找文档、整理思路,以及协助撰写文章等,然后由 Gemini给出建议。
为这台笔记本电脑选型的最后结果是这两款👇
> ollama list
NAME ID SIZE MODIFIED
gemma4:e4b c6eb396dbd59 9.6 GB 11 days ago
gemma3:4b a2af6cc3eb7f 3.3 GB 11 days ago
Gemma 3 4B (Instruct):擅长遵循指令并进行逻辑推理。完全可以在本机显存中正常运行。
Gemma4:E4B:谷歌为 2026 年的工作流程而设计,能够更出色地处理各种“代理型”任务,它更擅长执行多步骤的指令,比如“阅读这三份笔记,总结其中的矛盾点,然后撰写一篇关于该内容的社交媒体帖子”。
选好大语言模型,就可以直接让它跑起来,跑起来以后进入模型的对话,退出它打 /bye 命令回到命令行。
> ollama run <LLM_MODEL>
>
>>> /bye
>
4. 大语言模型的量化
如果觉得标准的 Gemma 3 4B 模型速度稍慢,Ollama 可以跑经过“量化优化训练”的版本,其性能更为出色。可以尝试运行以下命令来测试:
> ollama run gemma3:4b-it-qat
而 Gemma 4 目前只有基础版本,自动采用高质量的量化方式(通常是 Q4_K_M)。
接下去的讲解均假设使用标准的 Gemma 3 4B 和 Gemma4:E4B 模型,量化模型同理。
5. GPU 没用上怎么破?
大语言模型跑起来后查看模型运行情况:
> ollama ps
NAME ID SIZE PROCESSOR CONTEXT UNTIL
gemma4-smooth:latest b9997a00f454 10 GB 100% CPU 4096 4 minutes from now
当 CPU 的使用率达到 100%,意味着 NVIDIA 显卡处于闲置状态,而所有的处理工作都由 CPU 来承担。这样一来,大语言模型相关的操作会变慢,同时也会让笔记本电脑的温度比正常情况下高得多。由于英伟达显卡拥有 4GB 的 VRAM,要尽量将模型中的更多层级在 GPU 上处理,其余部分才在 CPU 上运行:
更新驱动程序
本地 AI 功能需要 CUDA 的支持。 如果 NVIDIA 驱动程序过于陈旧,Ollama 将无法使用 GPU 进行运算。
前往 NVIDIA 驱动程序页面,NVIDIA Driver Page。
下载最新的“Studio Driver”(推荐用于 MSI Prestige 系列产品),或适用于 GTX 1650(笔记本版)的“Game Ready Driver”。
设置 GPU 环境变量
新建 Windows 用户“环境变量”
OLLAMA_NUM_GPU,变量值设为1,然后重启 ollama 进程。重启时先强制终止 ollama 进程,重新启动。
> stop-process-name "ollama*"-force
>
> ollama run <LLM_MODEL>
在模型文件中使用 “num_gpu” 参数
如果仍然无法解决上面的问题,可以强制让程序将相关图层卸载到 GPU 上。
为每个模型创建一个DOCKERFILE 的文本文件(无需添加扩展名),然后生成一个简单定制的模型。这样我们就有了以下四个模型:
> ollama list
NAME ID SIZE MODIFIED
gemma3-gpu:latest d35deb41fb79 3.3 GB 8 days ago
gemma4-smooth:latest b9997a00f454 9.6 GB 10 days ago
gemma4:e4b c6eb396dbd59 9.6 GB 11 days ago
gemma3:4b a2af6cc3eb7f 3.3 GB 11 days ago现在运行
ollama run gemma3-gpu或者ollama run gemma4-smooth,会强制大语言模型在 GPU 上进行处理。这意味着模型的所有参数数据都已被成功加载到了 NVIDIA 的 VRAM 中,ollama ps命令得出处理器 100% GPU,说明 Gemma 3 4B 和 Gemma 4 E4B 的容量都在 4GB 范围之内,可以存储在显卡中。> ollama ps
NAME ID SIZE PROCESSOR CONTEXT UNTIL
gemma4-smooth:latest b9997a00f454 10 GB 100% GPU 4096 4 minutes from now这时显卡 VRAM 理想情形使用率为 80%,略高也无妨,这是用于存储模型的“内存”,如果 GPU 能够正常工作,CPU 的使用率应该会降至 50%或更低,而大语言模型的反应速度会大大提升。
在 Ollama 中, num_gpu=99的作用是将尽可能多的图层卸载到 GPU 上,这样就不必去猜测具体的层数gemma3:4b-> gemma3-gpu
DOCKERFILE 文本文件g3gpu
在终端中运行FROM gemma3:4b
PARAMETER num_gpu 50ollama create gemma-gpu -f g3gpugemma4:e4b-> gemma4-smooth
DOCKERFILE 文本文件g4smooth
在终端中运行 `ollama create gemma4-smooth -f g4smooth 注意:FROM gemma4:e4b
PARAMETER num_gpu 99
PARAMETER num_ctx 4096
PARAMETER temperature 1.0
6. 网络设置
设置静态 IP 地址
“Windows 设置”>“网络与互联网”>“Wi-Fi/以太网属性”。 将 IP 分配方式从“自动(DHCP)”更改为“手动”,并开启 IPv4 功能。 请为其指定一个特定的地址(例如 192.168.1.100),该地址应位于其它设备所使用的地址范围之外。将 Ollama 配置为“监听”模式
新建 Windows 两个用户“环境变量” :
重启 Ollama,验证
> netstat -an | findstr 11434如果结果是
0.0.0.0:11434— 完全正确,Ollama 在“监听”网络。
如果结果是127.0.0.1:11434— 错误,说明 Ollama 仍旧只在本地提供服务。检查OLLAMA_HOST变量或者重启 Ollama。OLLAMA_HOST,变量值设为0.0.0.0。OLLAMA_ORIGINS,变量值设为*。调整 Windows 防火墙设置
在 MSI 设置中,搜索 “Windows Defender 防火墙:高级安全功能” (Windows Defender Firewall with Advanced Security)。 点击“Inbound 入境规则” > “新建规则”。 选择“端口” > “TCP” > “特定的本地端口”: 11434 。 选择“允许连接”,并将其命名,譬如 “Ollama Remote”。 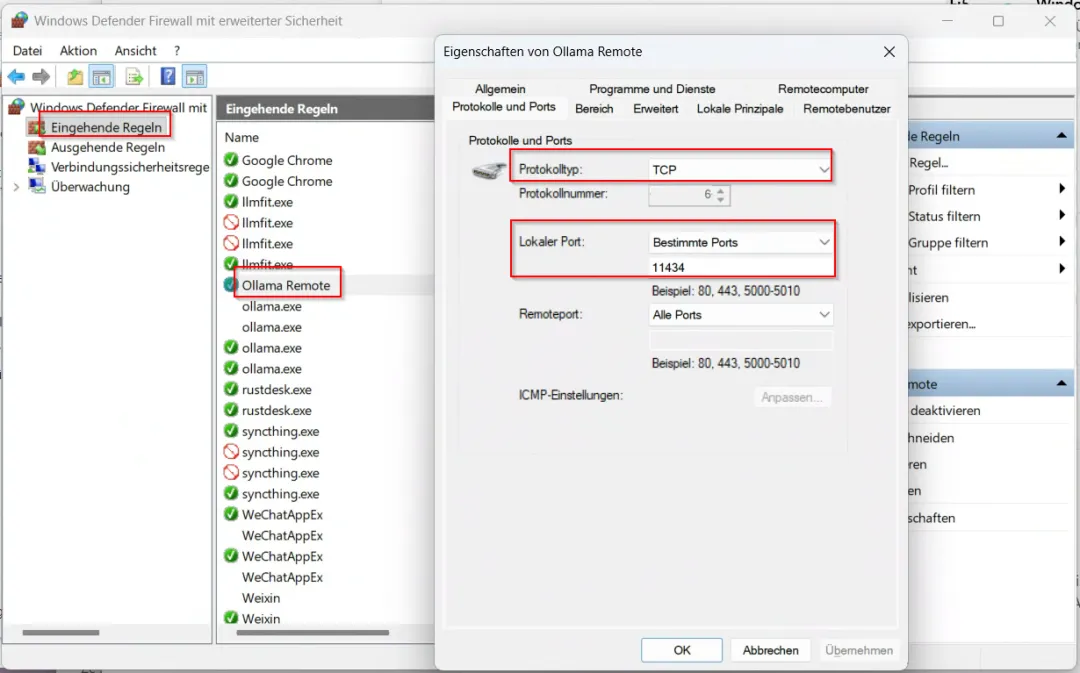
7. 设置家庭网络上的客户端电脑
7.1 极简测试
在客户端电脑上最简单的验证就是在浏览器当中打入 URLhttp://[MY-MSI-STATIC-IP]:11434
结果应该是: "Ollama is running"。
7.2 Chrome 浏览器 Page Assist 插件
Page Assist 设置:
在 Ollama Settings 设置中
Ollama URL:
http://[MY-MSI-STATIC-IP]:11434存储(Save) 高级 Ollama URL 设置(Advance Ollama URL Configuration):
激活定制根 URL (Enable Custom Origin URL) 定制根 URL (Custom Origin URL): http://127.0.0.1:11434激活自动 Ollama CORS 修正(Enable Automatic Ollama CORS Fix) 存储(Save) 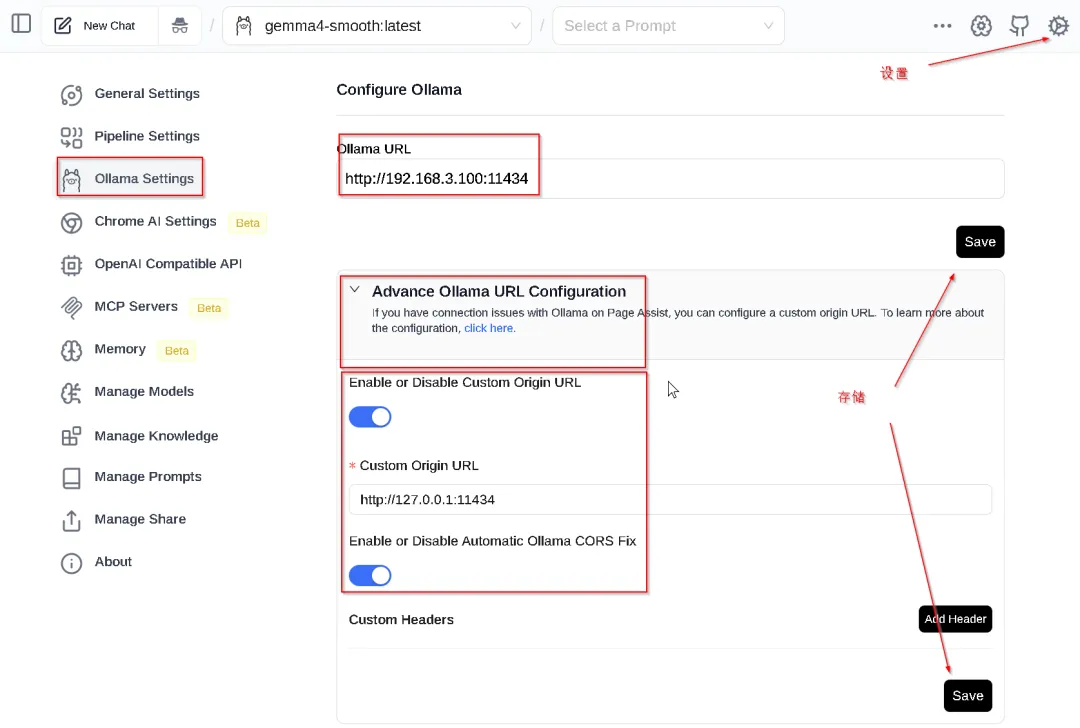
在 OpenAI 兼容 API (OpenAI compatible API) 设置中,添加服务提供者:
提供者名(provider name):
OpenAI基础 URL(base URL):
http://[MY-MSI-STATIC-IP]:11434/v1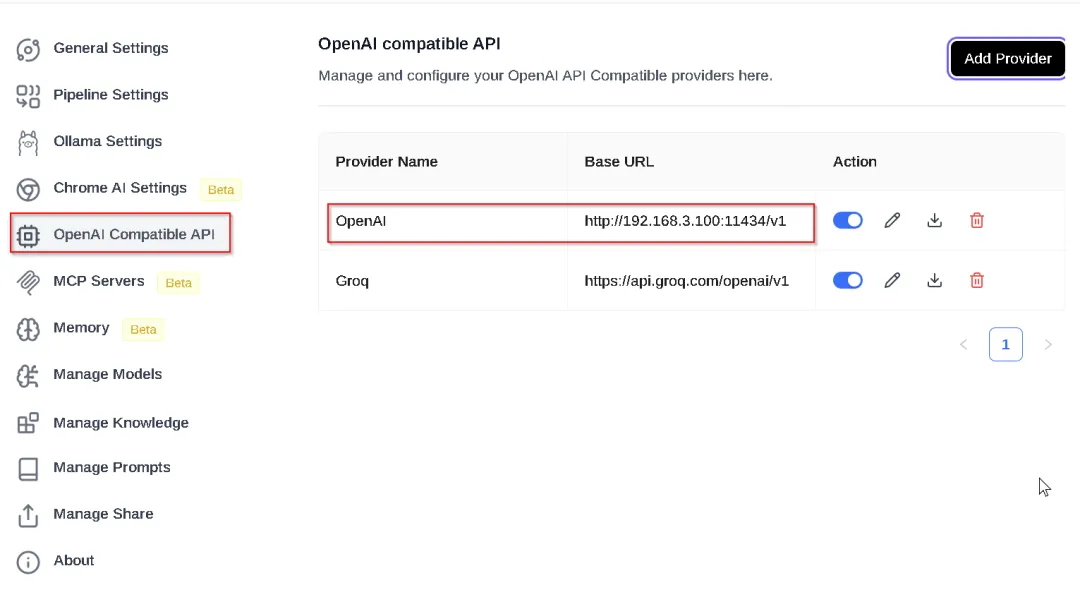
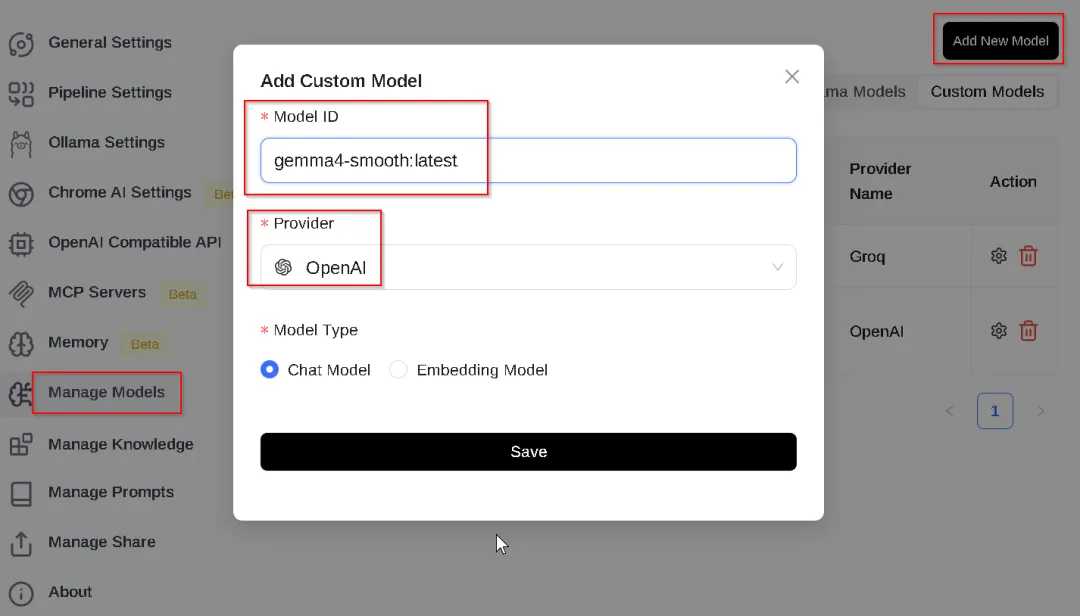
在模型管理 (Manage Models)中,自定义模型(custom models), 添加模型(add model)
提供者(provider):
OpenAI从发现的·列表中选择 模型 ID (Model ID): 譬如
gemma4-smooth:latest模型类型(Model Type):聊天模型(Chat Model)
然后就可以和服务端 MSI Prestige 15 A10SC 聊天啦。
7.3 Obsidian Copilot 插件
Copilot 设置:
在模型设置(Model)中,添加模型 "gemma4-smooth"
基础 URL(base URL):
http://[MY-MSI-STATIC-IP]:11434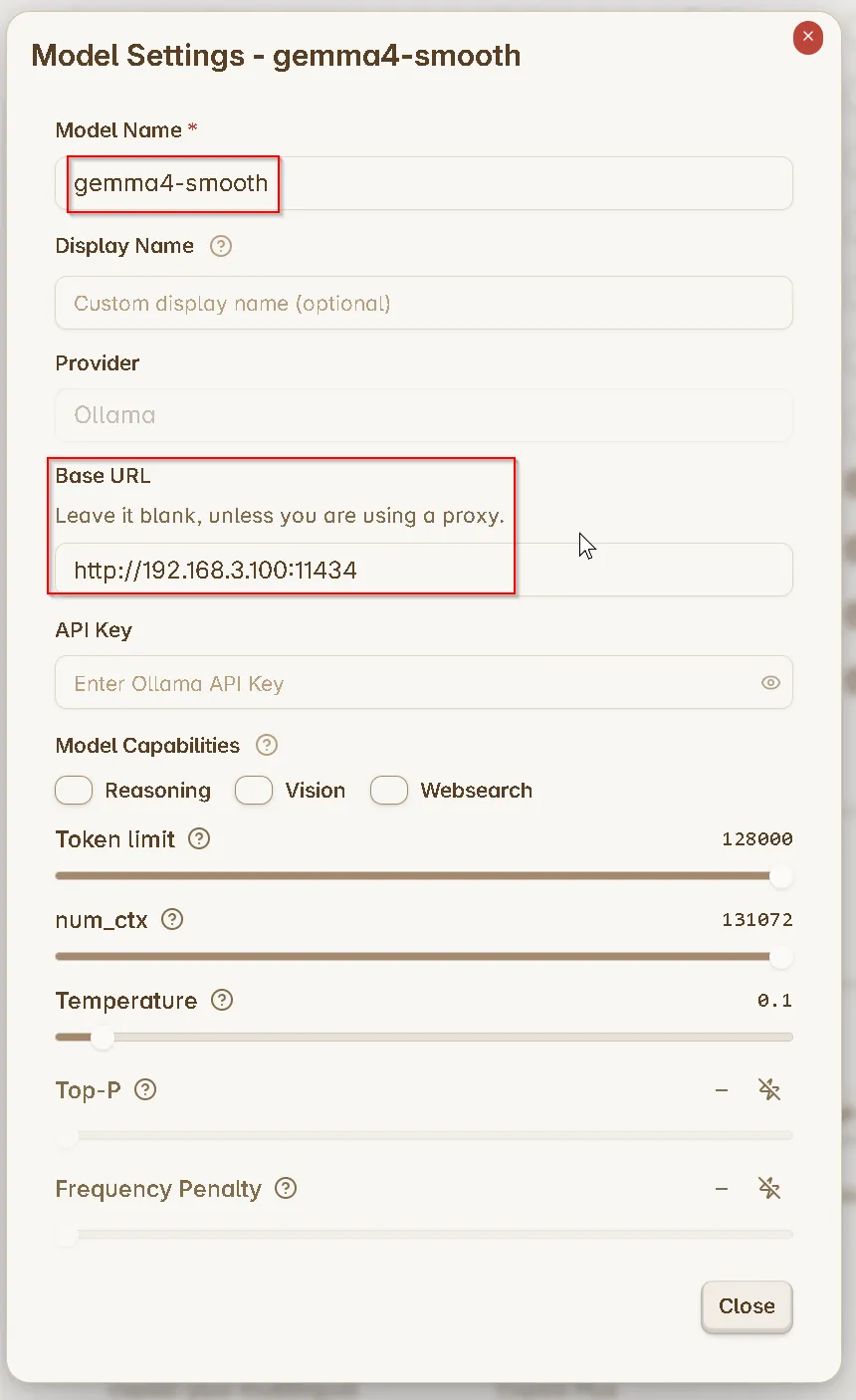
在基本设置(Basic)中选择缺省聊天模型(Default Chat Model)"gemma4-smooth"。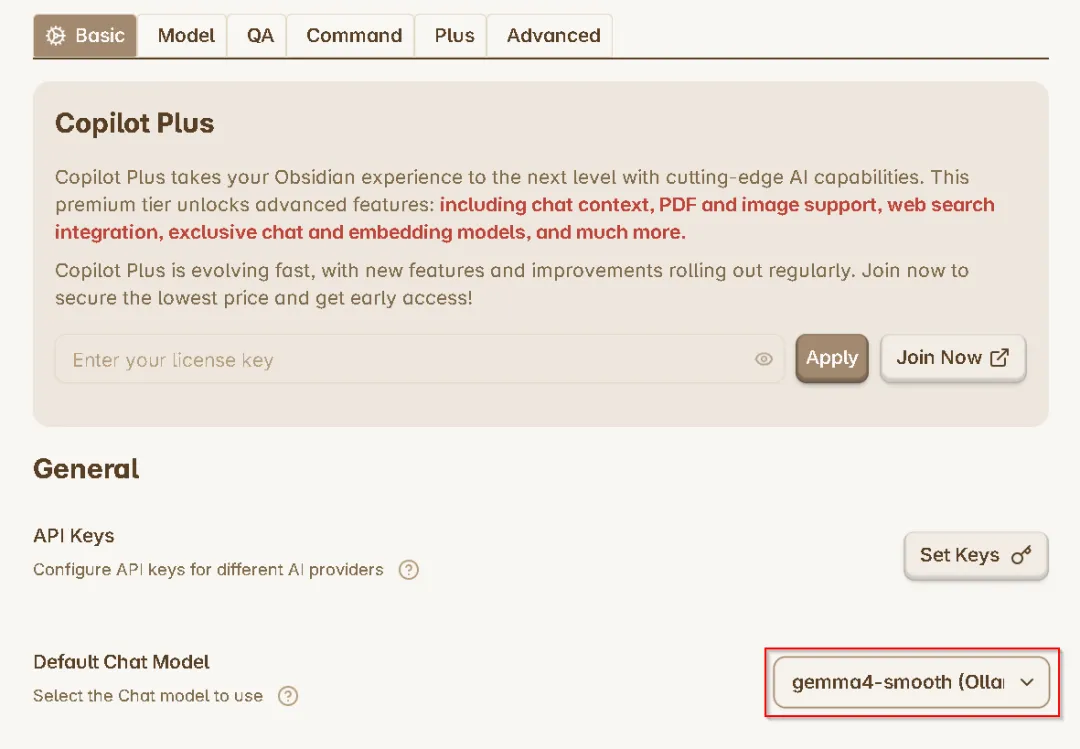
如此,Obsidian 中的 Copilot 就可以工作起来了。
8. 总结
在一台初级游戏笔记本电脑上,挑选了两个大语言模型本地运行,本文详细描述了选型,安装和调试的整个过程,运行的大语言模型在家庭局域网上提供人工智能大语言模型的服务,最后接进了客户端电脑的 Obsidian,让它实际工作起来。这个尝试说明游戏笔记本电脑是完全能够跑上个为整个家庭服务的本地大语言模型的。
