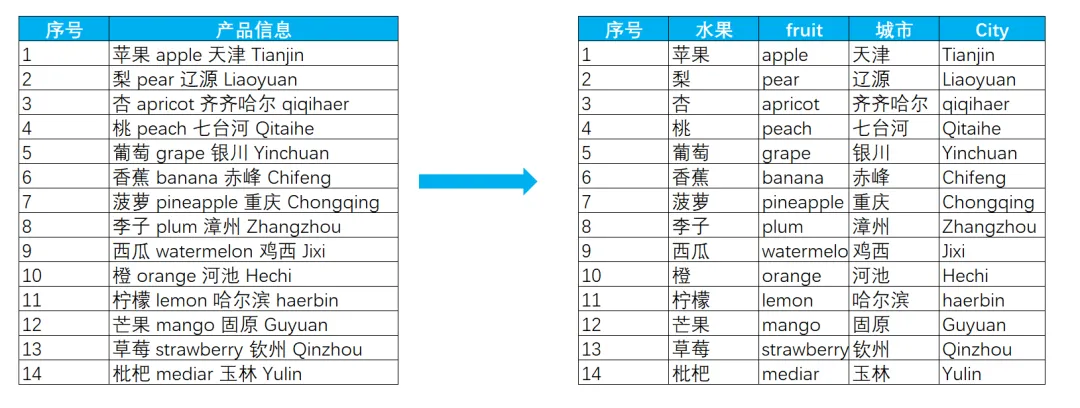
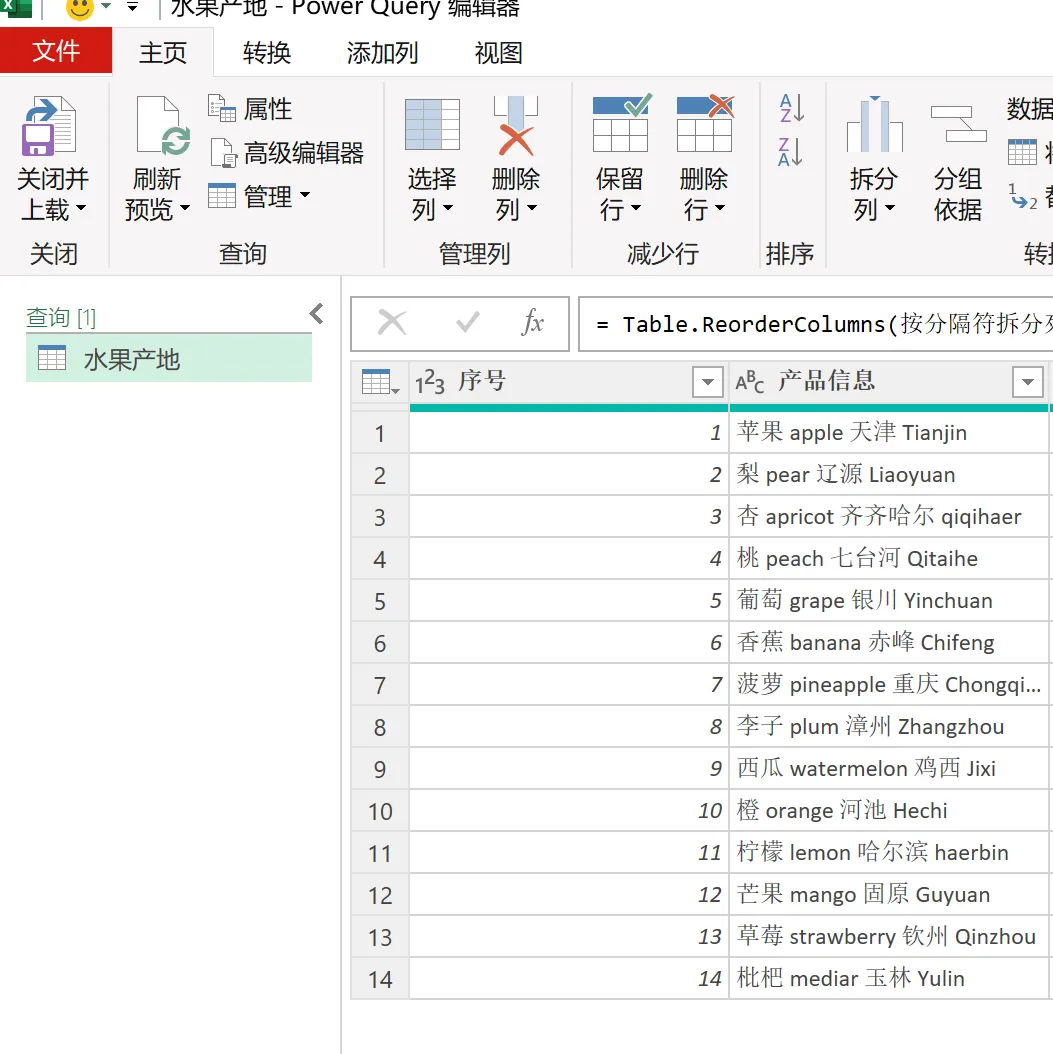
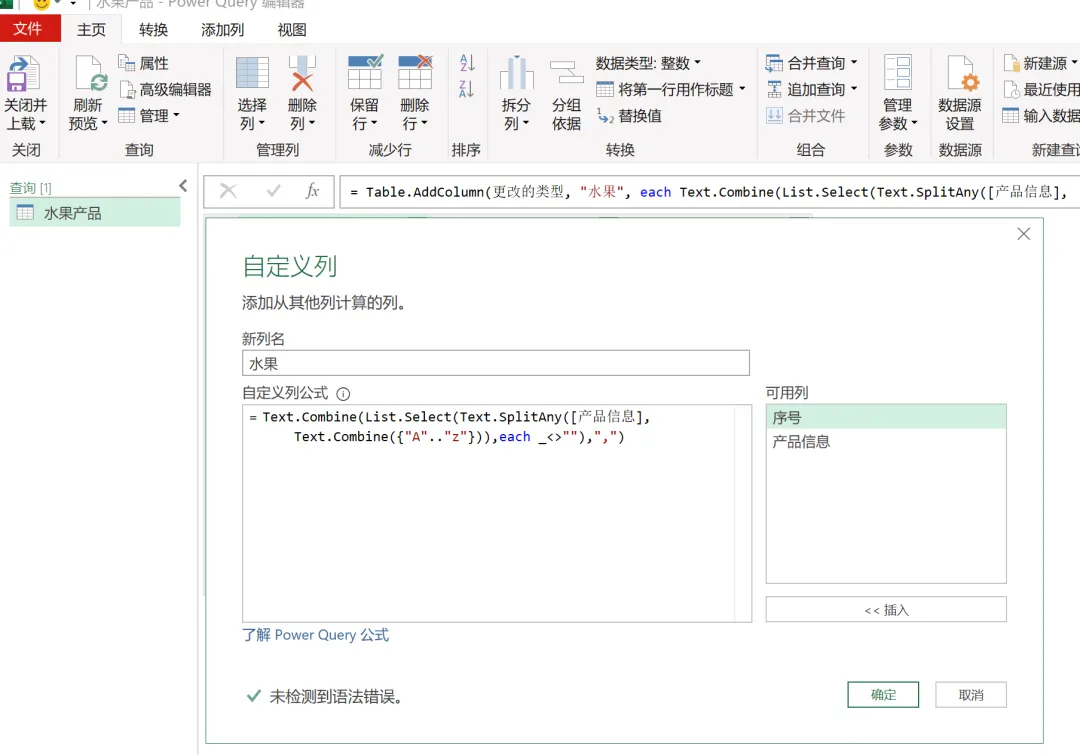
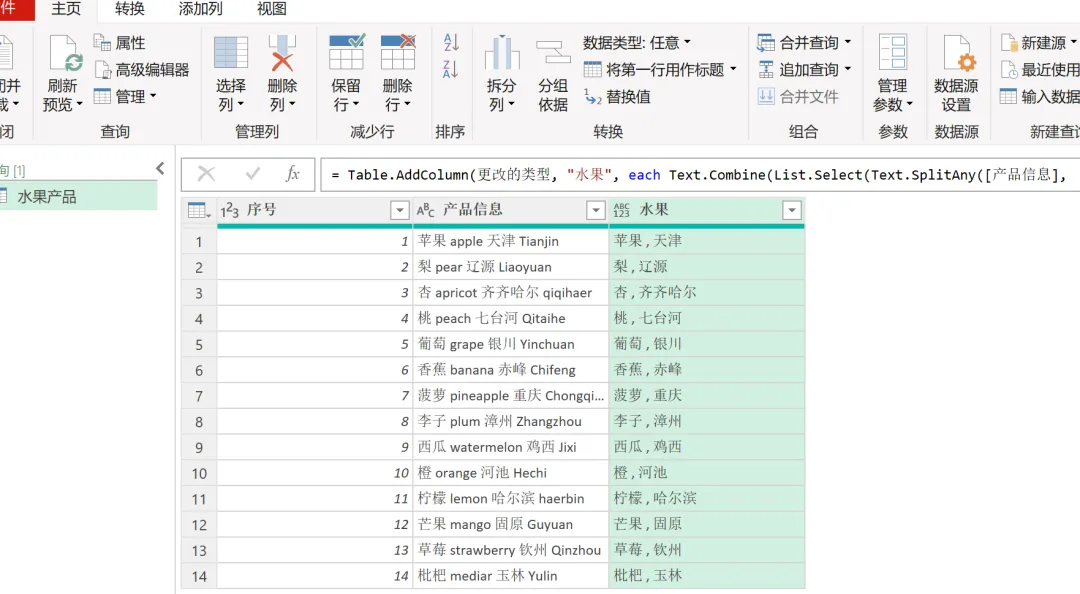
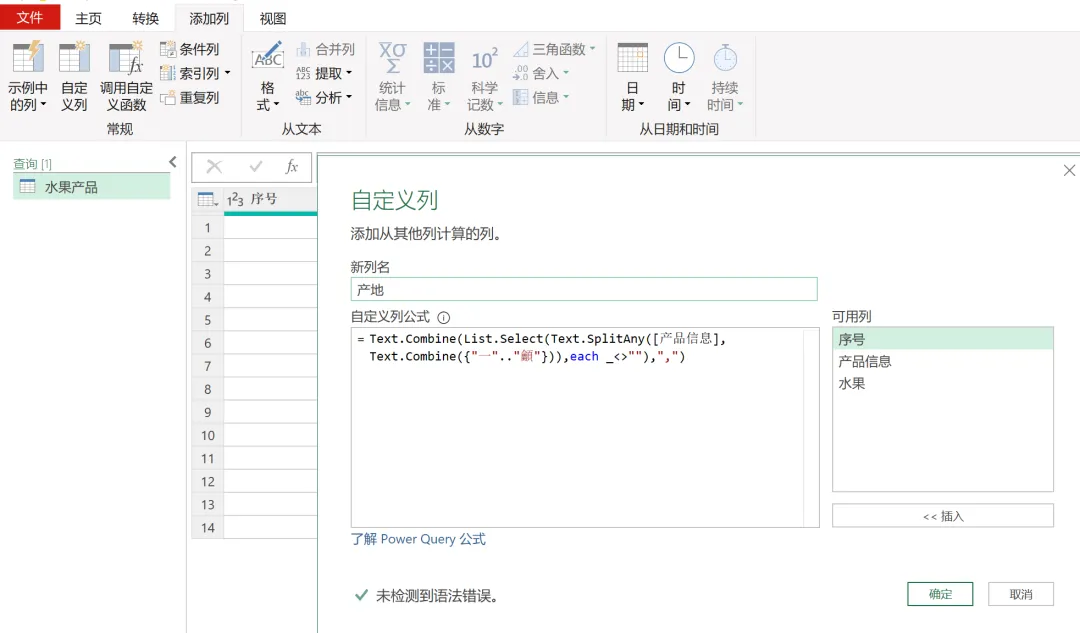
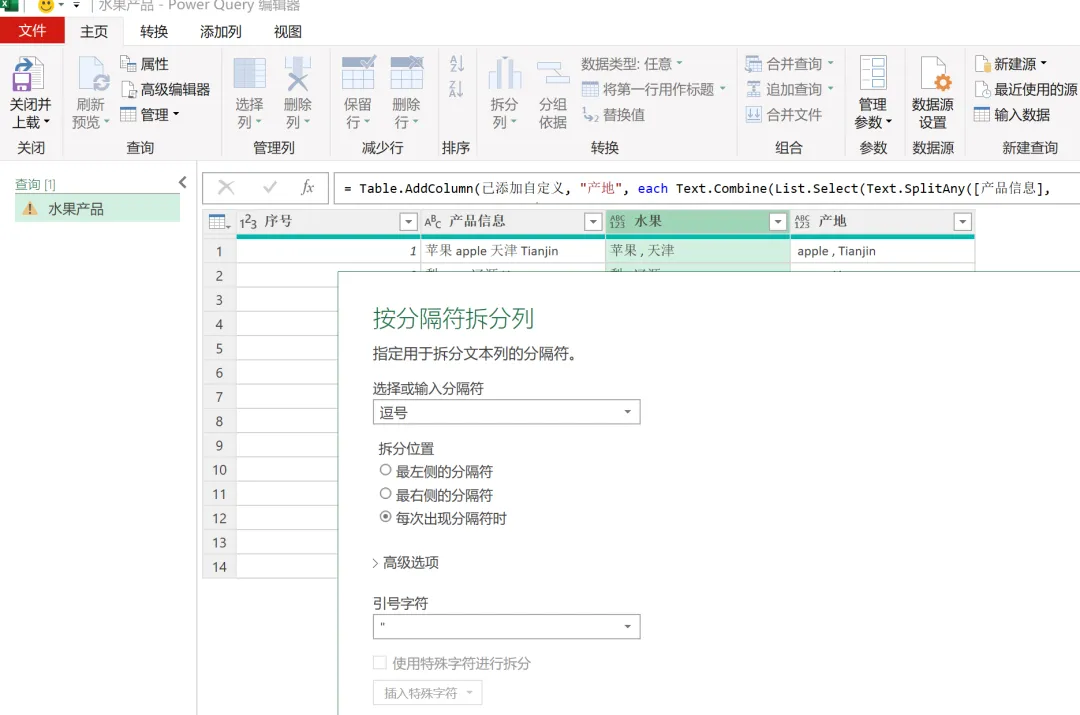
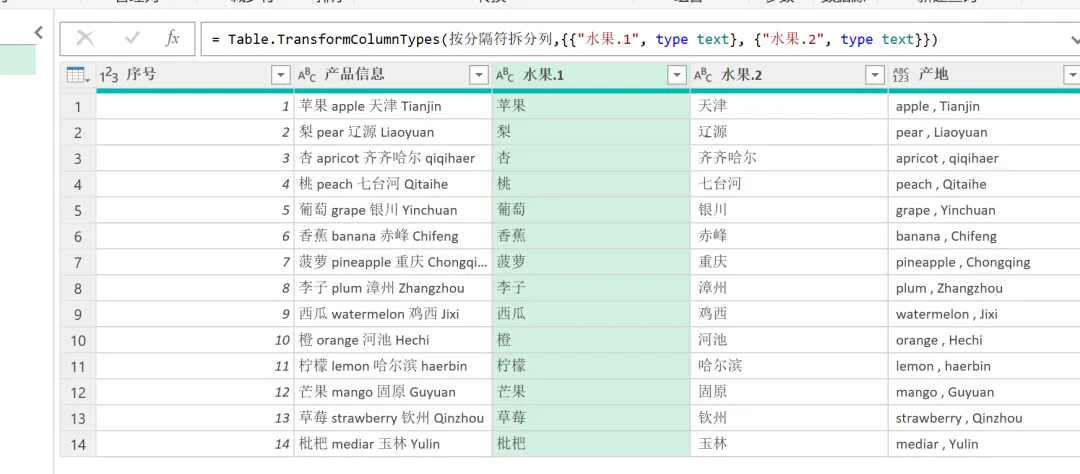
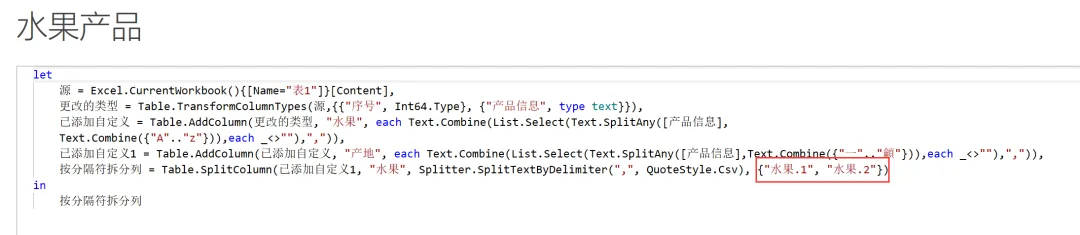
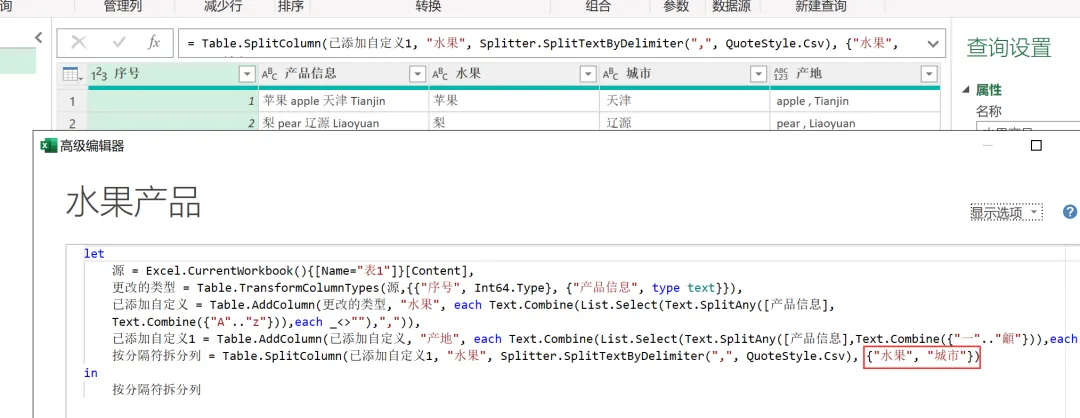
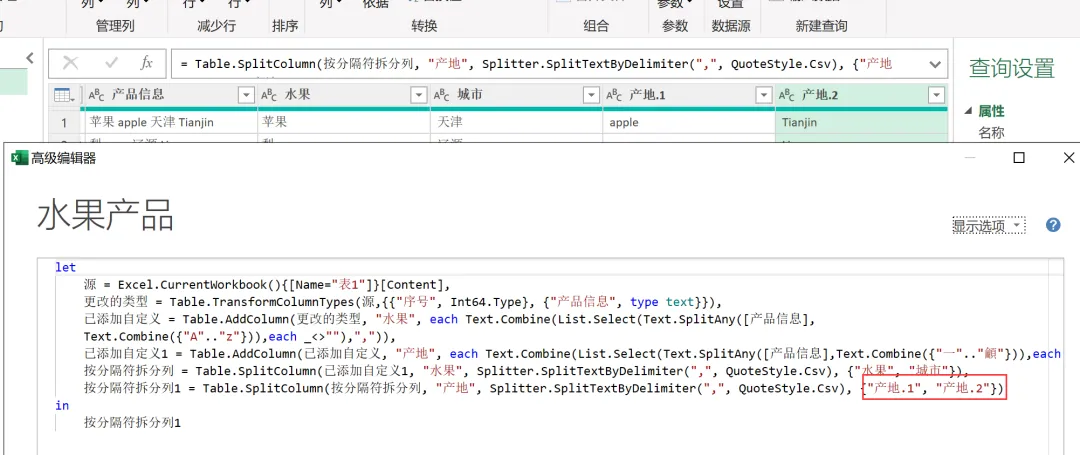
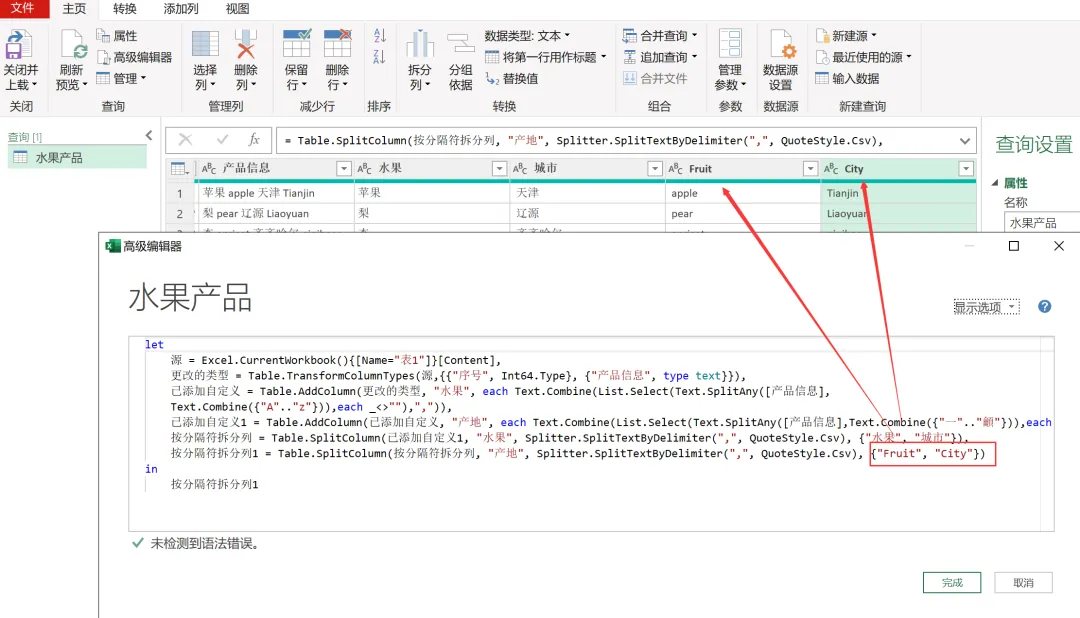
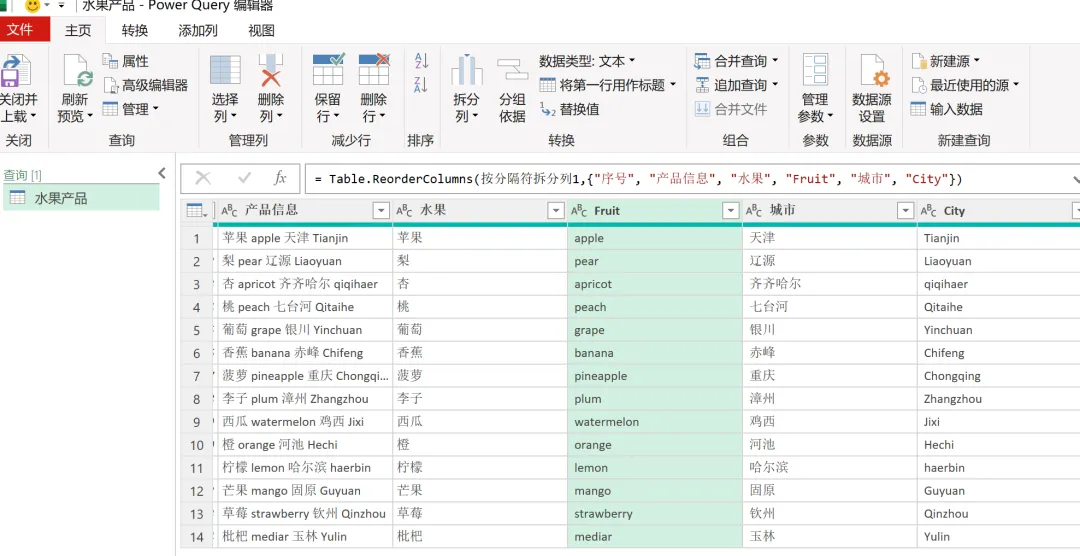
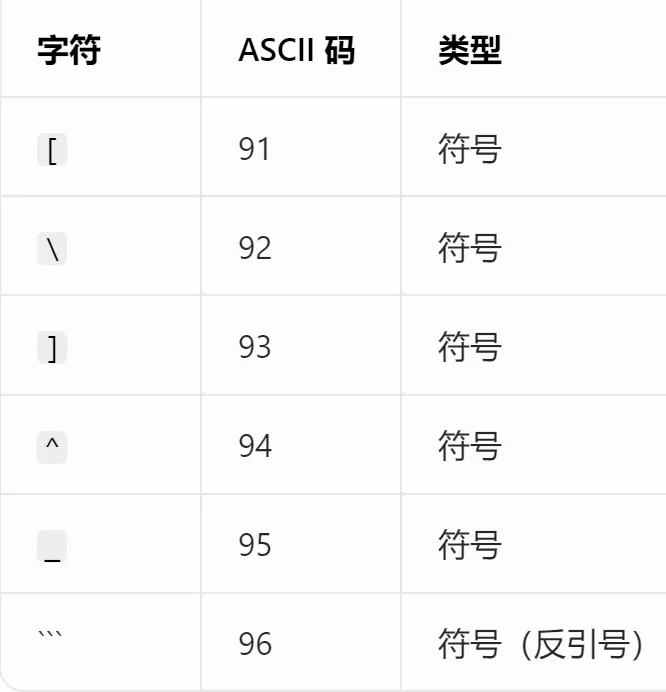
EXCEL|Power Query的高级应用5-拆分数据案例说明:左图是文字与字母混搭的内容,如何准确地按照实际中英文品名,中英文产地进行快速拆分,达到右图的效果。这个难点在于,左图每个单元格的内容没有一点分隔符,所以没办法直接使用分列进行拆分。今天的内容主要用到Text.Combine,List.Select,Text.SplitAny这3个函数之间的嵌套。1)左表导入到查询编辑器里,并命名为【水果产地】,如下图所示。2)添加自定义列,命名为【水果】,如下图所示操作。这里需要特别注意一点:公式中的"each _"在each后面_前面是一定要有空格的,否则就会报错,大家编写的时候需要特别注意。3)结果如下图所示。上面一步,相当于把文字给单独拎出来了。4)再添加一个自定义列,命名为【产地】,操作如下图所示。这一步相当于把字母都单独拎出来了。5)选择【水果】列,按照分隔符","进行拆分,操作和结果如下图所示:6)我们来修改下公式,把名称分别改为"水果"和"城市",如下图所示。7)同样的对表格【产地】一列按照","进行拆分,然后我们也来修改下公式。操作如下图所示:接下来,咱们来解析函数。老规矩,按照抽丝剥茧的方式,由里往外讲。{"A".."z"}:这个咱们之前讲过,生成A至z的字符list列表。Text.Combine({"A".."z"}):将上述list列表合并成一个字符串"ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz"。这里解释下,为啥在全部的大小写字母外,还掺杂着[]^_`。是因为Power Query 的start..end 序列生成,是基于字符的Unicode/ASCII 编码值连续生成的,而不是按 “字母类型” 过滤的。
- 小写字母 a-z:ASCII 码 97-122所以
{"A".."z"} 会把从 65 到 122 之间的所有字符都包含进来,自然就带上了中间的符号。 - Text.SplitAny([产品信息],Text.Combine({"A".."z"})):判断[产品信息]列字段中的所有英文字符串,以英文字符作为分隔符拆分成list列表。
- 当
Text.SplitAny 遇到 ** 连续的分隔符(多个字母)** 时,会在每一个分隔符的位置都产生一次拆分,从而在中间生成多个空字符串。 - 以
apple 为例,它是由 a/p/p/l/e 这 5 个字母组成的,按字母拆分后,会变成:{"", "", "", "", "", ""} - 当遇到不连续的分隔符时,只有当分隔符出现在文本的开头或结尾时,才会产生空字符串。
- 以输入"
A产品123B456号C"为例,拆分的结果是{"", "产品123", "456号", ""}。
本案例中,将"苹果apple天津Tianjin"字符串,按照所有的英文字母进行拆分:=Text.SplitAny("苹果apple天津Tianjin",Text.Combine({"A".."z"})),拆分后返回的结果为{"苹果","","","","","天津","","","","","",""}。List.Select(Text.SplitAny([产品信息],Text.Combine({"A".."z"})),each _<>""):在list列表中选择非空的list。=Text.Combine(List.Select(Text.SplitAny([产品信息],Text.Combine({"A".."z"})),each _<>""),","):以","为分隔符合并list中的所有字符串。今天讲到的3个函数都比较陌生,初看是有点懵圈的,觉得这根本不是人能看懂的呀。这个时候先别急,拉下来看函数拆解。一步步看,看完了也就看懂了。另外,在操作的时候,建议大家公式直接手敲上去,不要复制粘贴,敲个两遍,差不多就能记住七七八八了。千万别偷懒。
 夜雨聆风
夜雨聆风