 夜雨聆风
夜雨聆风现在做AI Agent开发的人越来越多,但绝大多数人都卡在同一个问题上:单一大模型prompt简单好用,稍微落地复杂场景就全面翻车。
上下文窗口不够用、长文档处理幻觉频发、复杂任务出错无法自查、系统没有纠错机制、大规模调用后准确率断崖式下跌……
这也是多智能体(Multi-Agent)架构成为行业主流的核心原因:不再让单个大模型包揽所有工作,而是把复杂目标拆解、分工协作,让专业智能体做专业的事。
但很多开发者陷入了新误区:以为堆更多Agent就能解决所有问题。
真正决定AI系统上限的,从来不是Agent数量,而是智能体的编排逻辑——Agent之间如何通信、共享状态、校验输出、容错纠错、分工协作。
纽约大学团队重磅发布的万级文档基准测试研究,基于5款主流顶级大模型、10000份真实文档,全面测评了行业通用的四大AI智能体编排架构。同时,结合arxiv最新收录的70个真实工业级Agent项目实证研究,我们可以彻底搞懂:不同场景到底该用哪种编排模式,如何平衡准确率、成本、速度和规模化稳定性。

https://arxiv.org/abs/2603.22651
看完这篇,你再也不会盲目搭建Agent架构,从零规避90%的落地坑。
先划核心结论:四种模式,各霸一方
先给大家上最直白的终极总结,方便快速选型:
顺序流水线(Sequential Pipeline):成本&规模化稳定性天花板,海量任务批量处理最优解
并行分发合并(Parallel Fan-Out with Merge):速度天花板,追求低延迟、任务相互独立场景首选
层级督导-工作者(Hierarchical Supervisor-Worker):综合性能王者,绝大多数企业生产环境的最优默认方案
自省纠错循环(Reflexive Self-Correcting Loop):准确率天花板,高风险低频次场景专属,成本极高
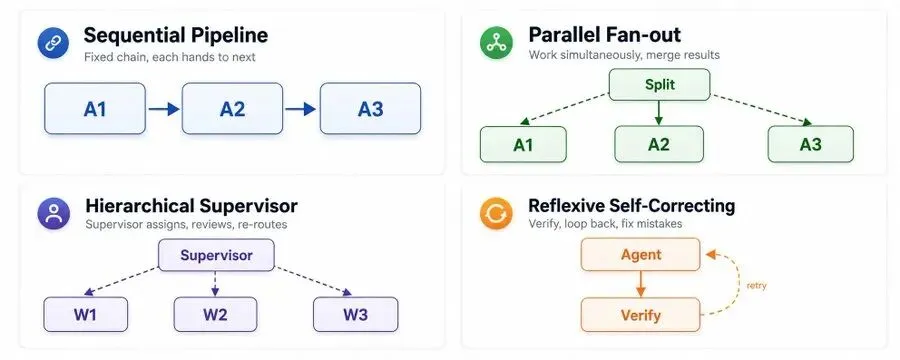
所有模式均基于同一套基础智能体组件(文档解析、字段提取、表格分析、交叉校验、置信度评分、输出格式化),差距不在Agent本身,而在协作方式。
顺序流水线:大规模量产的性价比之王
这是最简单、最基础的基线架构,也是工业落地最稳的模式。
逻辑非常直白:智能体按照固定链路串行执行,A完成任务后,将全部上下文传递给B,B处理完毕再传递给下一个节点,逐级推进、层层交付。
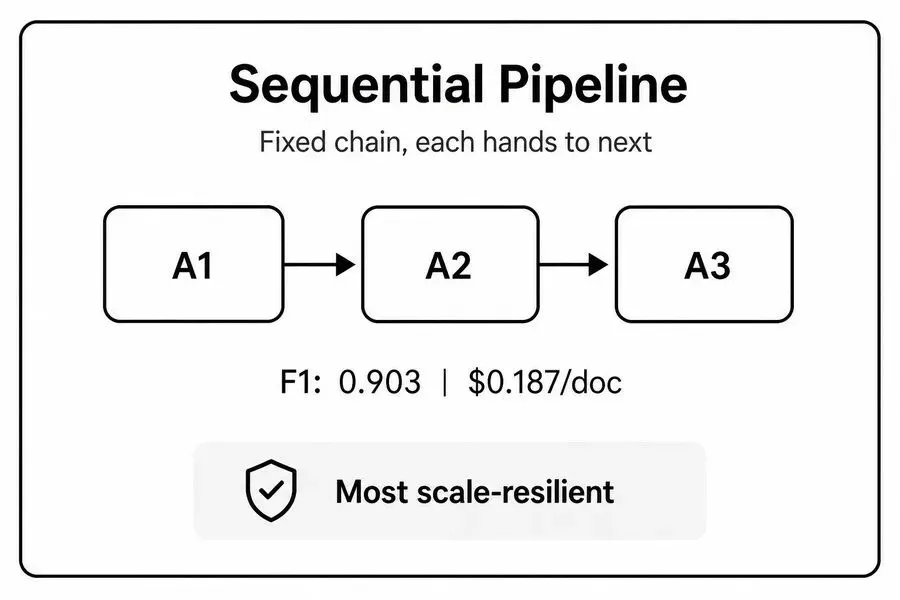
✅ 核心优势:极致稳定、可预测、易规模化
整个执行链路完全确定,延迟线性增长,没有复杂的跨智能体协作逻辑,抗并发能力拉满。
实测数据印证:当任务量级达到每日10万条的超大规模时,四大模式中唯有顺序流水线的准确率衰减最小,是海量批量任务的绝对首选。同时架构简单、开发成本低、运维难度极低。
❌ 致命短板:token浪费、误差逐级传导
链路越长,后续智能体需要处理的上下文体量越大,token消耗持续递增,长尾任务成本偏高。
更关键的是错误传导效应:只要链路第一个节点出现幻觉、提取错误,后续所有智能体都会继承错误结果,没有天然纠错节点,必须手动额外配置校验逻辑。
🎯 适用场景
超大规模批量处理、预算严格受限、任务流程标准化、优先保障吞吐量而非极致准确率的场景。
并行分发合并:低延迟极速方案
专为快而生的架构。
路由节点将多个相互独立的子任务,同时分发至多个垂直领域工作智能体,各分支并行执行、互不干扰,所有任务完成后,由合并智能体统一汇总、校验、整合输出最终结果。
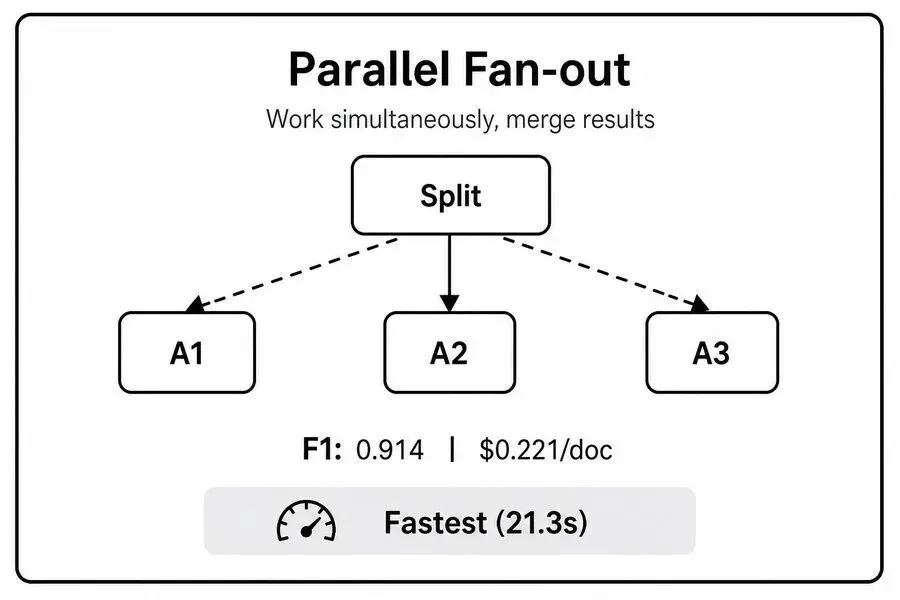
✅ 核心优势:延迟最低、故障隔离性强
整体耗时仅由最慢的单条分支+合并耗时决定,相比串行模式效率大幅提升。且各分支独立运行,单个工作智能体出错、输出异常,不会影响其他分支结果,避免全局崩盘。
❌ 致命短板:成本最高、合并冲突难解决
并行分支需要重复加载相同的上下文信息,多节点重复计算,导致token冗余消耗,是四种模式中token效率最低的架构。
同时存在核心痛点:各独立智能体的输出逻辑、假设、推理链路完全不同,极易出现结果冲突、内容残缺、口径不一的问题,而合并智能体往往缺乏足够上下文精准判别最优结果,导致整合效果不稳定。
🎯 适用场景
实时性要求极高、子任务天然相互独立、无需跨分支共享信息的抽取类、检索类场景。
层级督导-工作者:企业落地最优解
最贴近现实团队协作逻辑、综合性价比最高的均衡型架构,也是实测中最适合绝大多数生产环境的方案。
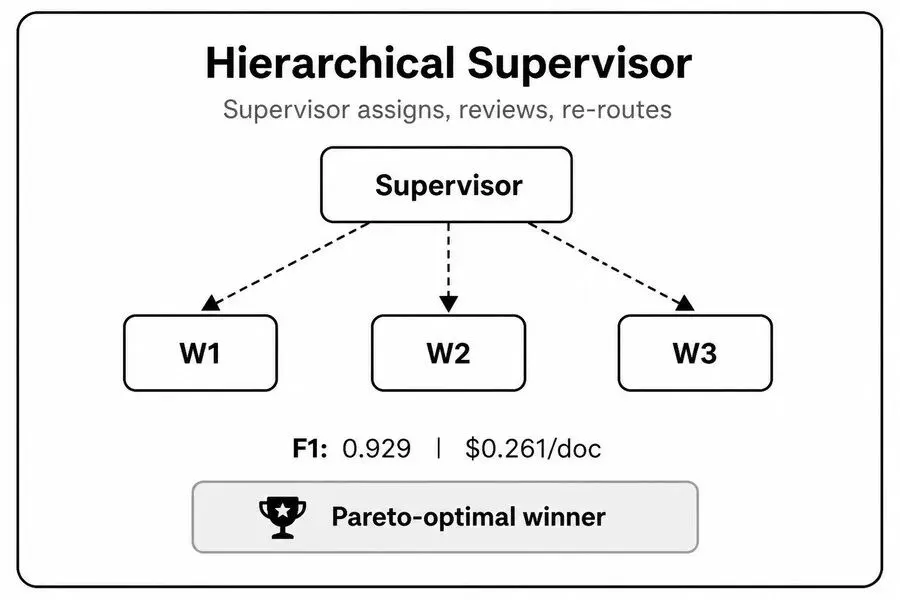
架构分为两层:督导智能体(Supervisor)负责全局规划、任务拆分、智能体调度;多个工作智能体(Worker)负责执行具体细分任务,输出结果并附带置信度评分。
督导智能体拥有核心决策权:低分结果驳回重算、疑难任务升级至更强模型、重复校验优化结果,灵活调度资源。
✅ 核心优势:精准控本、兼顾准确率与灵活性
实测数据堪称惊艳:F1分值达到极致准确率模式的98.5%,但成本仅为自省纠错模式的60.7%。
同时完美解决token浪费问题:工作智能体仅接收自身任务所需的局部上下文,无需加载全量信息,精准控制算力消耗。
支持模型分级路由:简单任务调用低成本轻量模型,复杂疑难任务调度GPT-4o、Claude 3.5 Sonnet等高端模型,完美适配企业控本+提质的核心需求。
❌ 致命短板:调度复杂度提升
督导层的决策逻辑会带来轻微延迟,系统依赖智能体间的消息传递机制。如果路由规则设计不合理,容易出现任务错配、输出格式不统一、调度失效等问题,对架构设计能力有一定要求。
🎯 适用场景
绝大多数企业通用生产负载、中大规模落地场景,需要兼顾准确率、成本、延迟和稳定性的核心业务。
自省纠错循环:高准确率极致方案
行业准确率天花板架构,核心是内置闭环自检机制。
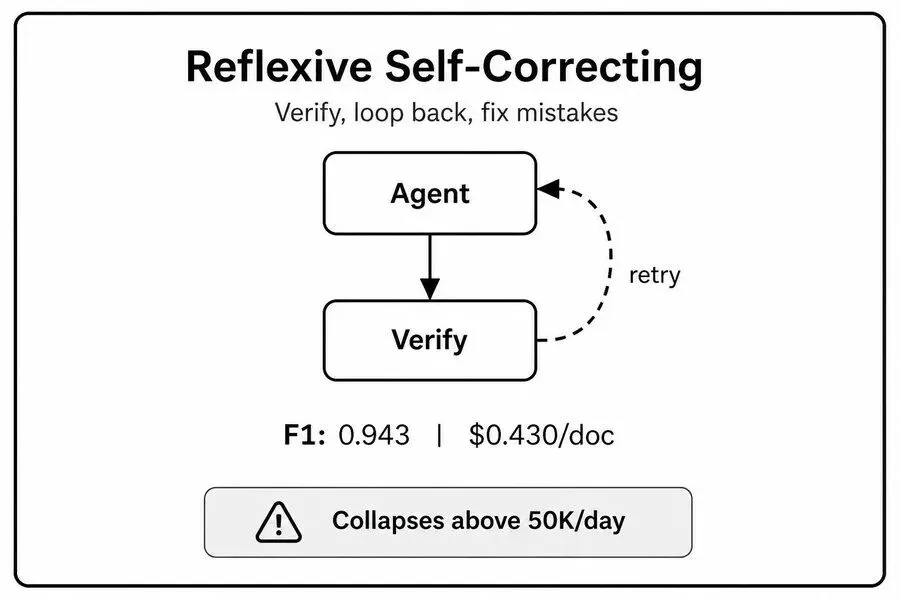
工作智能体输出初始结果后,专属校验智能体独立复盘、找茬、给出结构化修改意见,反馈给原智能体迭代优化,循环往复,直到结果达标或达到迭代上限(常规为3轮迭代)。
✅ 核心优势:准确率拉满、自带纠错能力
依托Claude 3.5 Sonnet实测,该模式F1分值可达0.943,位居四大模式首位。通过多轮自检迭代,大幅规避大模型幻觉、细节遗漏、逻辑漏洞问题,从机制上提升输出质量。
❌ 致命短板:贵、无法规模化
极致准确率的代价是极致的高成本:算力消耗是顺序流水线基线的2.3倍。
更致命的是规模化缺陷:当日任务量突破2.5万条后,纠错循环会引发队列拥堵、超时中断、迭代截断等问题,准确率持续下滑,甚至低于简单的串行流水线模式。同时容易出现过度迭代问题,对模糊文本反复修改、过度解读,反而降低结果稳定性。
🎯 适用场景
低频次、高风险、零容错的核心场景,成本不敏感、优先保障结果绝对准确的业务(如金融合规审核、法律文档校验、医疗文本分析)。
万字实测数据复盘:没有万能架构,只有最优匹配
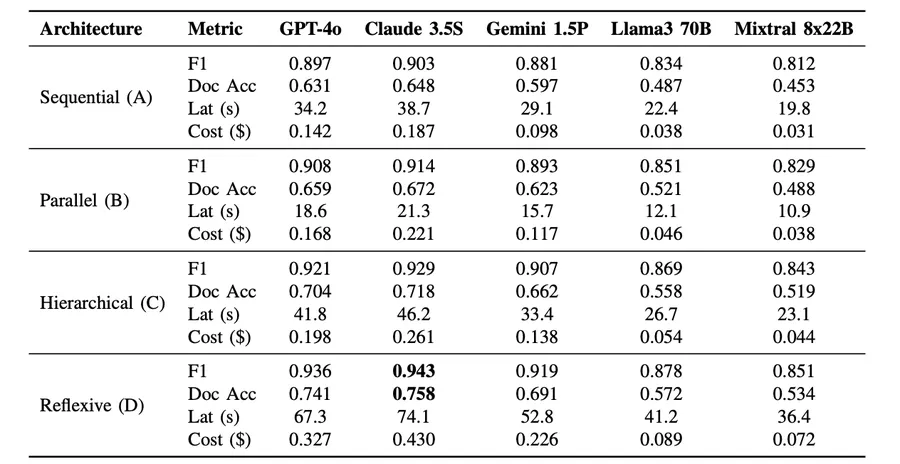
本次研究基于5款主流大模型(GPT-4o、Claude 3.5 Sonnet、Gemini 1.5 Pro、Llama 3 70B、Mixtral 8x22B)、10000份真实SEC财报文档实测,数据真实可落地:
自省纠错循环:准确率第一,成本最高,仅适配小体量高价值场景
层级督导:全能均衡王,高准确率、低成本、可落地,企业首选默认架构
并行分发:速度第一,牺牲成本换延迟,实时场景专属
顺序流水线:规模化稳定性第一,超海量批量任务最优解
70个工业级项目实证:比模型更强的,是架构设计
结合arxiv最新实证研究(分析70个公开工业级Agent项目),有一个颠覆很多人的核心结论:
更强的大模型,不会自动带来更安全、更稳定的AI系统。
Demo场景的惊艳效果,完全不能等同于生产环境的稳定性。很多花哨的高阶架构,落地后会出现成本失控、延迟飙升、准确率衰减、系统不稳定等一系列问题。
研究总结出一条生产落地黄金法则:永远优先选择最简单、能满足业务需求的架构。
不要为了炫技过度设计:基础场景用串行架构,需要智能调度再加层级督导,只有极高风险场景,才叠加自省纠错机制。
真正成熟的AI Agent工程化,不是堆砌技术、堆叠模型,而是基于业务的规模、成本、精度、延迟、容错需求,做精准的架构匹配。
最后:落地选型极简口诀
求量大、求省钱、求稳定 → 顺序流水线
求极速、低延迟、实时响应 → 并行分发合并
求极致精准、零容错、不计成本 → 自省纠错循环
企业通用落地、兼顾所有指标 → 层级督导-工作者
AI Agent的下半场,早已不是模型能力的比拼,而是工程架构与落地思维的比拼。选对编排模式,比调优十次prompt更有用。
需要原文论文的可以自行查阅:https://arxiv.org/abs/2604.18071
