**编者按**:这是一个系列文章的第一章。我们将通过阅读 Claude Code 的源码,理解一个工业级 AI 编程助手是如何被设计和实现的。本系列基于一个反编译还原版项目,让我们得以窥见 Anthropic 官方的架构思路。
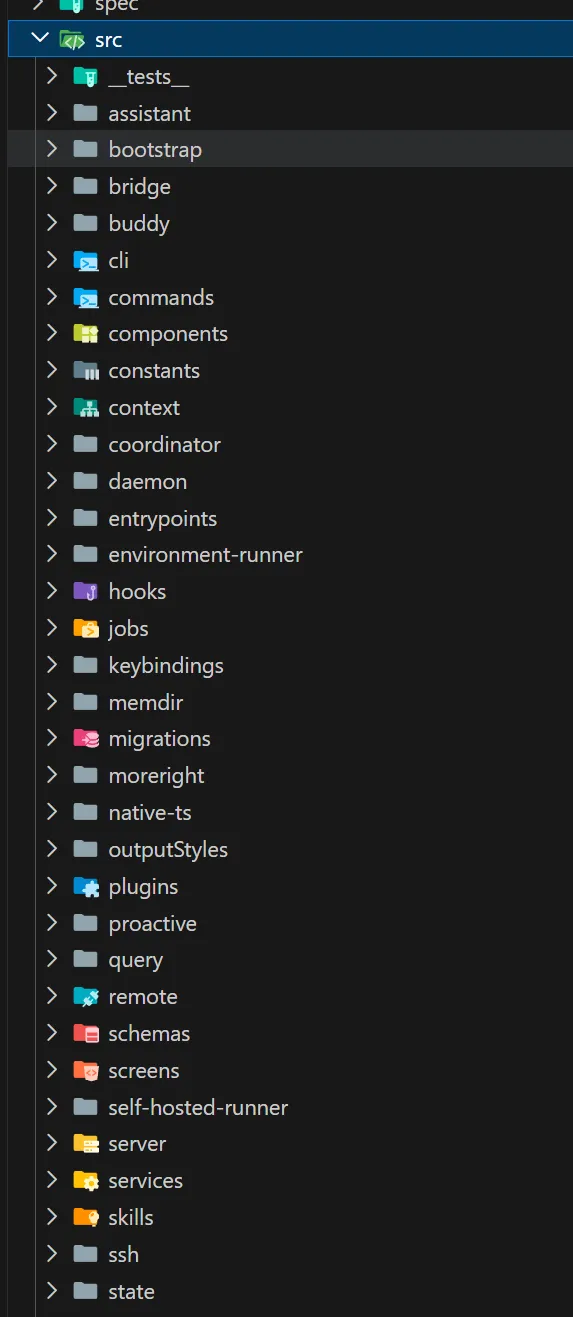
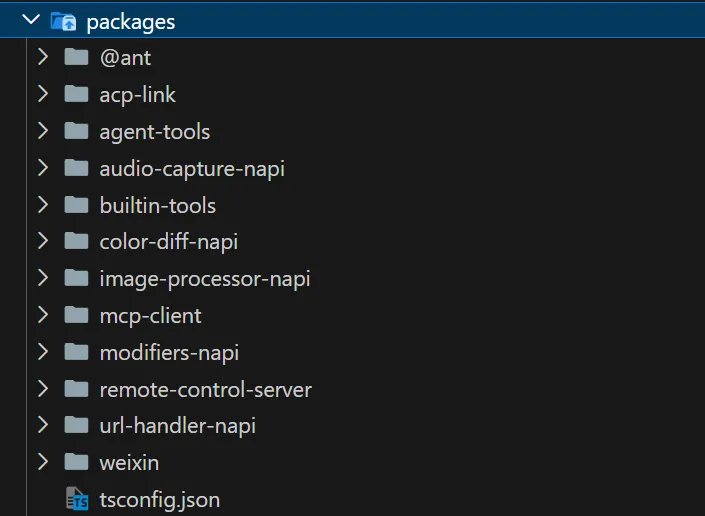
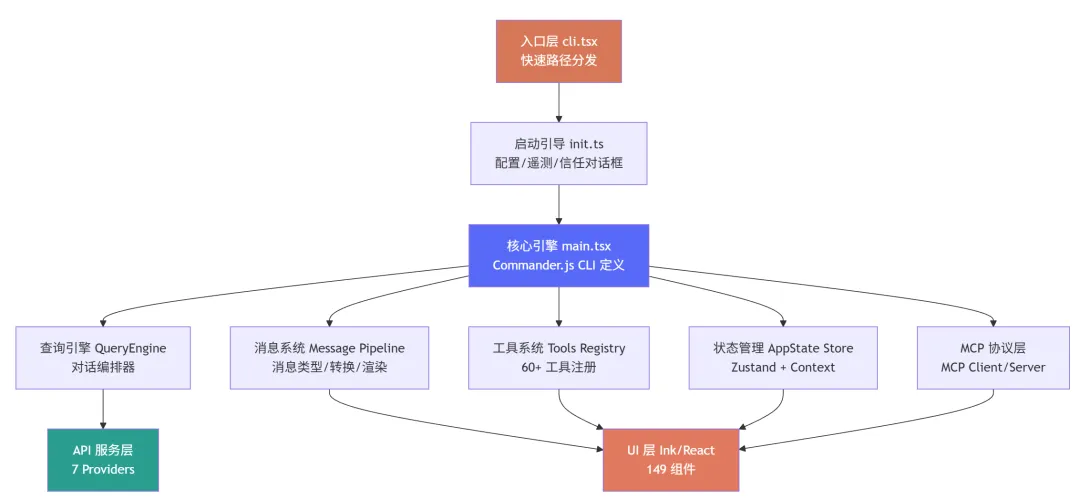
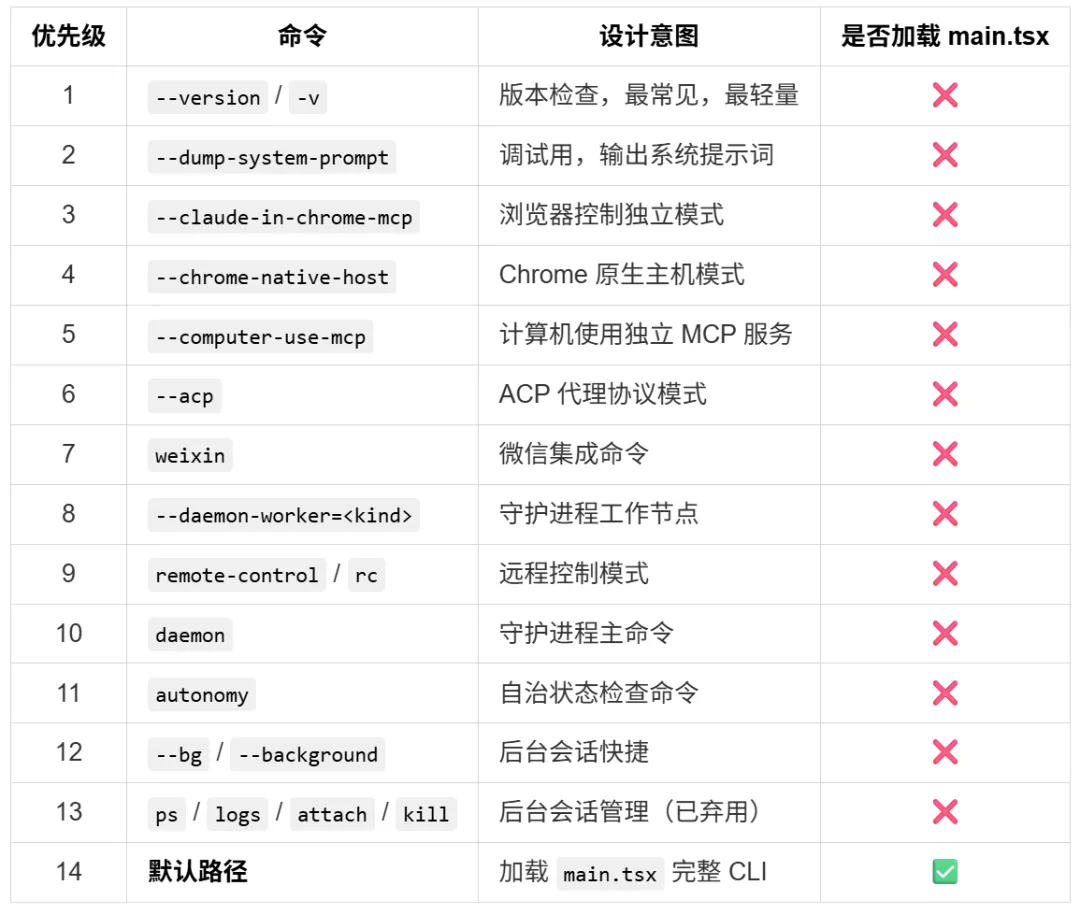
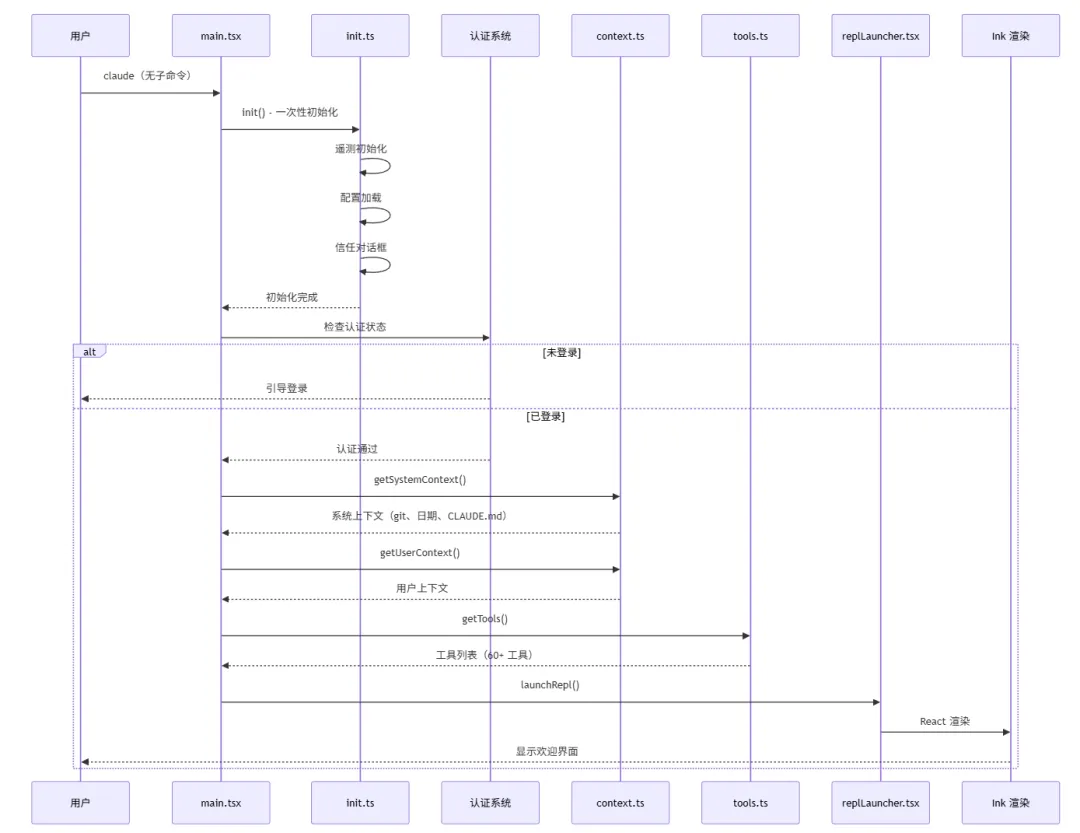
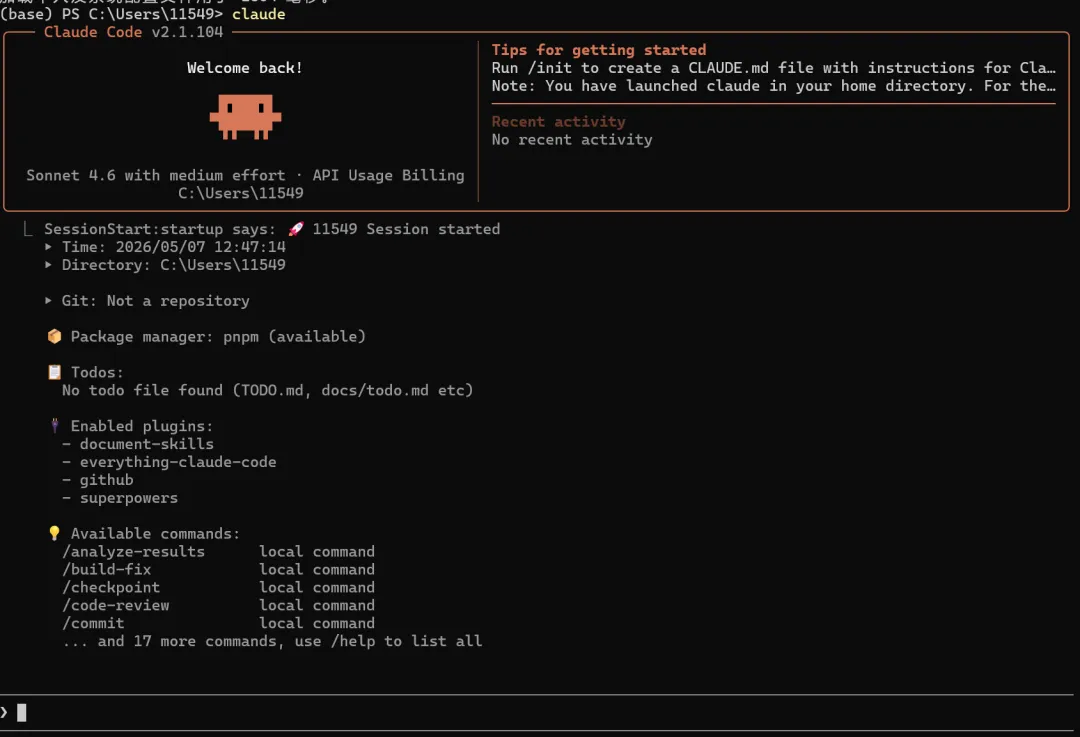
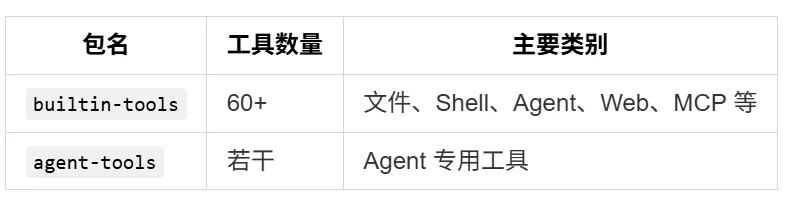
想象这样一个场景:你打开了终端,进入项目目录,输入了 claude,然后按下回车。 不到一秒的时间里,终端屏幕上出现了一个漂亮的欢迎界面,告诉你 Claude Code 已经准备好了。你输入了一句"帮我看看这个项目的架构",几秒钟后,Claude 开始回答你,甚至还附带了几个文件读取的操作。 但你想过没有,这不到一秒的时间里,背后发生了什么? 一个现代的 CLI 工具,尤其是像 Claude Code 这样集成了 AI 能力的复杂工具,它的启动过程绝不仅仅是"读取配置文件然后显示界面"那么简单。它需要在极短的时间内完成: MCP(Model Context Protocol)服务连接 而这些操作,每一个都可能需要加载若干个模块、执行若干行初始化代码。如果全部串行执行,启动时间会轻松突破数秒 —— 对于一个需要频繁启动的 CLI 工具来说,这是不可接受的。 所以 Claude Code 的设计者做了一个关键决策:快速路径系统(Fast-Path System)。 这就是我们第一章要讲述的内容 —— Claude Code 的整体架构。我们会从入口开始,一层层剥开它的外壳,看看这个精密系统是如何被设计出来的。 在这个过程中,你会发现很多可以借鉴到自己项目中的设计思想。无论你是否在写一个 AI 工具,这些架构层面的思考都是通用的。 第一部分:第一印象 —— 项目长什么样 在深入细节之前,我们先来建立对这个项目的整体认知。 1.1 项目的特殊身份 这不是 Anthropic 官方的开源仓库,而是一个反编译还原版项目。 这意味着什么?意味着我们看到的代码,是从编译后的产物中"逆向工程"回来的。项目的目标很明确:恢复核心功能,裁剪次要能力。 这种做法让我们获得了一个独特的视角 —— 看到一个商业产品的架构骨架,而不是被业务逻辑包裹的血肉。很多模块是 stub(空实现)或被 feature flag 关闭的,这反而帮助我们更容易识别哪些是核心路径,哪些是可选功能。 1.2 完整的目录结构 让我们先从最高维度看看这个项目的文件组织。完整的 src/ 目录如下: 光是看这个目录结构,你就能感受到这个项目的规模 —— 数十个顶级目录,每个目录下还有若干层级的子目录。这不是一个周末能写出来的玩具项目,而是一个经过深思熟虑架构的工业级系统。 1.3 技术栈解读 这个项目的技术栈选择非常有针对性,每个技术都有其存在的理由: Bun 而非 Node.js 项目运行在 Bun 上,而不是传统的 Node.js。这背后的原因很直接:启动速度。 Bun 是一个现代的 JavaScript 运行时,它内置了打包器(bundler)、测试框架、TypeScript 原生支持等。对于 Claude Code 这样需要快速启动的 CLI 工具来说,Bun 的即时启动速度比 Node.js 有明显优势。 此外,Bun 内置的 Bun.build() API 让构建过程变得极其简洁 —— 整个 build.ts 文件只有不到 100 行核心代码,就能完成打包、代码分割、后处理的全流程。 TypeScript Strict 模式 项目强制执行 TypeScript strict 模式,bunx tsc --noEmit 必须零错误。 在一个近万行代码的核心文件(main.tsx)和如此庞大的模块数量下,严格类型检查是保证代码质量的最后一道防线。这不是一个可以"差不多就行"的项目 —— 类型错误在运行时可能导致 AI 行为异常,而这种异常往往难以调试。 React + Ink 这可能是这个项目最有趣的技术选择:用 React 来写终端 UI。 Ink 是一个基于 React 的终端 UI 框架,它让你可以用声明式的方式编写终端界面。这意味着: UI 状态由 React 管理,而不是手动控制 ANSI 转义序列 这种选择的好处是:UI 逻辑和业务逻辑可以使用相同的编程范式,降低认知负担。 Commander.js CLI 子命令的标准解决方案。main.tsx 中注册了数十个子命令(mcp、server、auth、plugin、agents、doctor、update 等),Commander.js 提供了清晰的路由机制。 Zustand 轻量级状态管理库。相比 Redux 需要大量的 boilerplate 代码,Zustand 提供了更简洁的 API,非常适合 CLI 工具这种不需要复杂状态管理的场景。 1.4 完整的 packages/ 工作区 这不仅仅是一个单一仓库项目,而是一个 Monorepo 架构。让我们看看 packages/ 目录的全貌: 15 个工作区包,每个都有明确的职责边界。这种组织方式让代码隔离、独立发布、清晰的职责边界成为可能。我们会在后面的章节中详细解读 Monorepo 的设计哲学。 1.5 架构总览图 这张图展示了数据从入口流向 UI 的完整路径。接下来我们会逐层深入,看看每个部分是如何工作的。 第二部分:入口的精妙设计 —— 快速路径系统 如果说架构是 Claude Code 的骨架,那么入口层的设计就是它的神经系统 —— 决定了信息如何被路由、如何处理、如何以最快的速度响应用户。 2.1 故事开始:当你输入 claude --version 当你在终端输入 claude --version 时,你期望什么?一个版本号,对吧?比如 2.1.0 (Claude Code)。 这个操作看起来极其简单,但如果你加载了整个 CLI 框架(Commander.js、React、Ink、配置系统、认证系统……),仅仅为了输出一行字,可能需要花费数百毫秒到数秒的时间。对于用户来说,这感觉像是"卡顿"。 Claude Code 的设计者显然意识到了这一点。他们的解决方案是:快速路径(Fast-Path)。 注意到了吗?--version 的处理在整个函数的最开头,而且它不需要加载任何模块。MACRO.VERSION 是在构建时被注入的常量(类似 C 语言的宏定义),所以在运行时只是一个字符串替换。 这就好比你去银行办事。如果你只是问"你们几点关门",柜员直接告诉你就可以了,不需要叫号、不需要填表、不需要排队。快速路径就是那条"问一句就走"的通道。 2.2 快速路径的优先级链 但 --version 只是冰山一角。让我们看看完整的快速路径列表: 14 条快速路径,只有最后一条才会加载完整的 CLI 框架。 这意味着,对于大多数轻量级操作,Claude Code 都可以在几百毫秒内响应。这种设计思维在 CLI 工具中并不常见 —— 大多数工具会把所有命令都注册到同一个路由系统中,然后统一处理。但 Claude Code 选择了一种更高效的方式:在路由系统之前就完成分发。 2.3 Feature Flag 的门卫作用 在这些快速路径中,你会注意到有些路径前面有条件判断,比如: 这里的 feature() 函数是整个架构中非常关键的一环。它不是普通的运行时布尔值,而是一个构建时可确定的标志。 1. 在 scripts/defines.ts 中定义了 19 个默认启用的特性: 2. 在构建时,这些特性被传递给 Bun.build() 的 features 选项: 3. Bun 编译器会在构建时进行 DCE(Dead Code Elimination,死代码消除)。如果某个 feature 没有启用,整个 if (feature('X')) { ... } 代码块都会被删除。 这就意味着,如果你没有启用 BRIDGE_MODE,那么远程控制相关的代码不仅不会执行,它甚至不会出现在最终的产物中。这就是所谓的构建时优化 —— 不是运行时判断,而是编译时裁剪。 安全性更高:被禁用的功能在产物中不存在,无法被逆向启用 当然,这也带来了一个限制:Feature Flag 只能在构建时确定,不能在运行时动态切换。但对于 Claude Code 这种发布后功能就确定的场景来说,这是一个合理的权衡。 2.4 启动性能分析器 当所有快速路径都走完后(也就是用户输入了 claude 回车,没有任何特殊参数),程序会加载启动性能分析器: 这个 startupProfiler 是什么?它是一个简单的计时系统,在每个关键步骤打上 checkpoint,最后可以输出每个步骤的耗时。 这就像给启动过程装上了"秒表"。如果没有这个工具,你很难知道启动慢了是因为配置加载慢、还是因为 MCP 连接慢、还是因为模块加载慢。有了它,你就可以精确地定位瓶颈。 这种"先测量,再优化"的工程思维,在任何项目中都是适用的。 2.5 快速路径的完整流程图 让我们用一张流程图来总结从入口到 REPL 的完整路径: 这张图揭示了一个重要的设计原则:越常见的操作,路径越短;越复杂的操作,越需要完整的初始化。 *在下一部分中,我们将进入 main.tsx 这个近 7000 行的核心文件,理解它是如何组织整个 CLI 的。* 第三部分:核心引擎 —— main.tsx 的近 7000 行 当所有快速路径都走完后,程序会加载 main.tsx。 这个文件有 5675 行(在某些版本中接近 7000 行),是整个项目中最大的单个文件。它承载着 Commander.js CLI 的完整定义,是连接入口和实际功能的桥梁。 3.1 main.tsx 的角色定位 如果把 cli.tsx 比作公司的前台接待员,那么 main.tsx 就是整个公司的组织架构表。它负责: 1. 注册所有子命令 —— mcp、server、ssh、auth、plugin、agents、auto-mode、doctor、update 等数十个命令 2. 定义主 action 处理器 —— 当用户没有输入任何子命令时,启动完整的交互式 REPL 3. 执行启动前初始化 —— 配置加载、遥测初始化、信任对话框 4. 管理并行预取 —— MDM 配置读取、Keychain 预取、Fast Mode 状态检查 这段代码的注释揭示了一个重要的优化策略:并行预取(Parallel Prefetch)。 3.2 启动时的并行优化 仔细看这段代码,你会发现三个操作在导入阶段就被启动了: 1. profileCheckpoint('main_tsx_entry') —— 标记进入 main.tsx 的时间点 2. startMdmRawRead() —— 启动 MDM(Mobile Device Management)配置读取子进程 3. startKeychainPrefetch() —— 启动 macOS Keychain 的并行读取 因为这些都是 IO 操作,需要访问文件系统或调用系统 API。如果串行执行,它们会花费大约 65-135 毫秒。但如果让它们与后续的模块加载(也是 IO 操作)并行执行,总耗时就不会增加。 这就像你早上起床后,同时启动了咖啡机、烤面包机和热水器。如果你一个一个启动,可能需要 15 分钟;但如果同时启动,可能只需要 5 分钟 —— 最慢的那个决定了总时间。 这种优化的核心思想是:让 IO 操作重叠,而不是串行等待。 3.3 Commander.js 命令注册 在初始化完成后,main.tsx 开始注册所有的子命令。这是 Commander.js 的标准用法: 3.4 主 Action 处理器 当用户输入 claude 而不带任何子命令时,就会触发主 action 处理器。这是整个 CLI 的"默认路径",也是最复杂的代码路径。 1. 初始化系统 —— 调用 init() 完成一次性初始化(遥测、配置、信任对话框) 2. 检查认证状态 —— 如果未登录,引导用户登录 3. 加载上下文 —— 构建系统上下文和用户上下文(git 状态、日期、CLAUDE.md 内容等) 4. 注册工具 —— 从 @claude-code-best/builtin-tools 加载工具列表 5. 启动 REPL —— 调用 launchRepl() 进入交互式界面 3.5 REPL 启动链路 launchRepl() 是整个启动过程的最后一步。它负责: 注入 AppStateProvider(状态提供者) REPL.tsx 是我们最终看到的交互式界面,它包含: *(上图:Claude Code 的 REPL 欢迎界面)* 3.6 为什么一个文件需要 5000+ 行? 你可能会问:为什么 main.tsx 需要这么多行代码?这不是违反了"单一职责原则"吗? 1. Commander.js 的命令定义本身就很长 —— 每个子命令都有名称、描述、参数选项、action 处理器。数十个命令加起来,代码量自然很大。 2. 这个文件是"胶水层" —— 它不负责具体实现,只负责把各个模块连接起来。在大型项目中,胶水层往往比较臃肿,但它的职责是清晰的。 3. 反编译的影响 —— 由于这是反编译版本,可能丢失了原始的模块拆分结构。官方版本可能更模块化。 但重要的是:这个文件的职责边界是清晰的。 它只做"注册命令和分发请求"这一件事,具体的实现都委托给了其他模块。 *在下一部分中,我们将探索 Monorepo 架构的设计哲学,理解 15 个工作区是如何协作的。* 第四部分:Monorepo 架构 —— 15 个工作区的协作 当你第一次看到 packages/ 目录下有 15 个工作区包时,你可能会好奇:为什么不把所有代码都放在 src/ 下面? 4.1 为什么选择 Monorepo Monorepo(单一仓库多包)架构在大型项目中越来越流行。它的核心优势是: 代码隔离 —— 每个包有明确的边界和接口,不能随意互相访问 独立发布 —— 某些包可以单独发布到 npm,供其他项目使用 清晰的职责边界 —— 每个包只做一件事,做好一件事 依赖管理 —— 通过 workspace:* 语法,包之间可以互相引用而无需发布 对于 Claude Code 这种功能复杂、模块众多的项目,Monorepo 是一个非常合理的选择。 4.2 packages/ 全景图 让我们再次看看完整的 packages/ 目录结构,但这次我们会标注每个包的职责和依赖关系: 4.3 工作区解析机制 在 package.json 中,workspaces 配置如下: packages/* —— 匹配所有直接在 packages/ 下的包
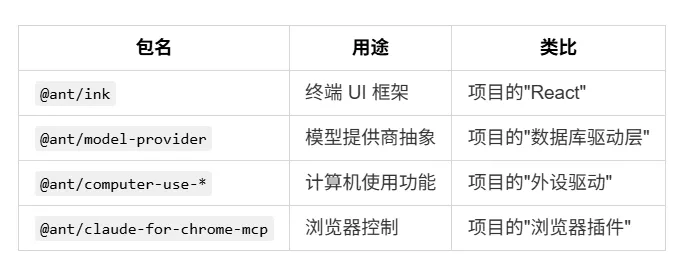
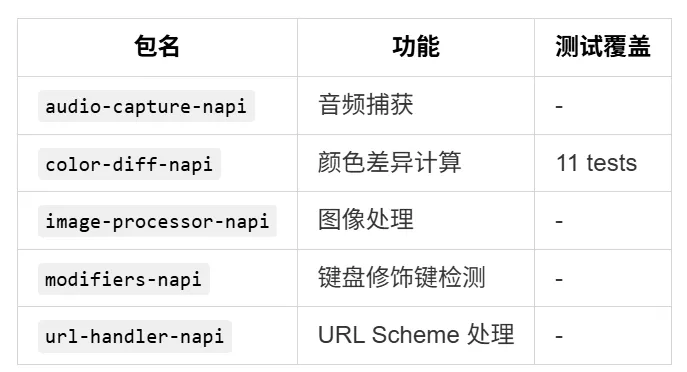
packages/@ant/* —— 匹配 @ant 范围内的所有包
packages/@anthropic-ai/* —— 匹配 @anthropic-ai 范围内的所有包
通过 workspace:* 语法,包之间可以互相引用: 这意味着你不需要发布这些包到 npm,它们可以在本地直接互相引用。 4.4 包的分类 内部框架类(@ant/*) 工具集类(builtin-tools, agent-tools) 服务类(mcp-client, acp-link, remote-control-server) 原生模块类(*-napi) 4.5 Monorepo 的设计哲学 Claude Code 的 Monorepo 架构体现了几个重要的设计原则: 1. 职责单一原则 这种拆分让每个包的代码量都保持在可管理的范围内,也降低了新贡献者的学习曲线。 2. 依赖方向明确 src/ → packages/builtin-tools → packages/@ant/ink src/ 依赖 packages/ 中的包,但 packages/ 中的包不依赖 src/。这种单向依赖让代码更容易被复用。 3. 内部包不发布 @ant/* 范围内的包通常不发布到 npm,它们仅供项目内部使用。这与那些发布到 npm 的包(如 mcp-client)形成了对比。 4. 原生模块隔离 所有需要原生代码的功能都被放在单独的 *-napi 包中。这样做的好处是: 原生代码的构建不会影响其他包
如果某个平台的原生代码不可用,只影响对应的包,不影响整个项目
更容易测试和调试原生模块
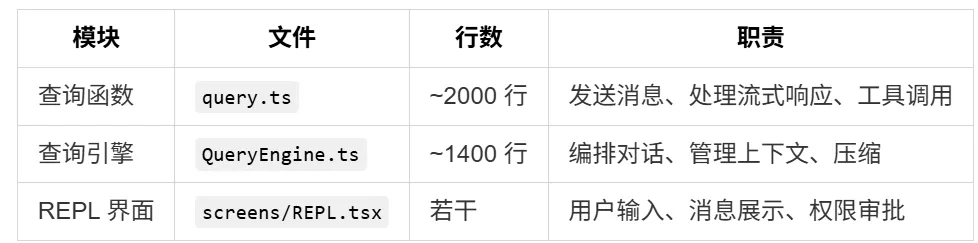
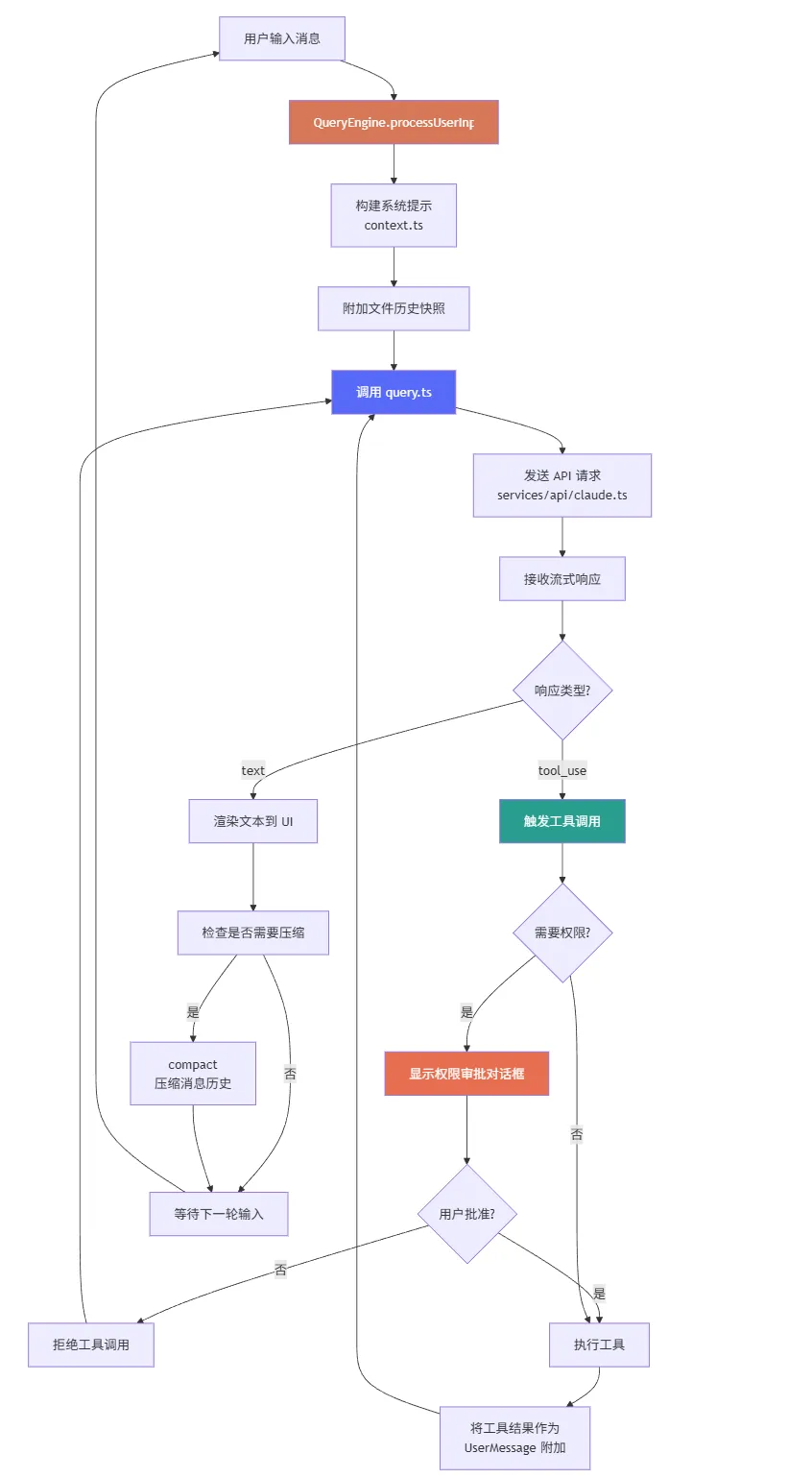
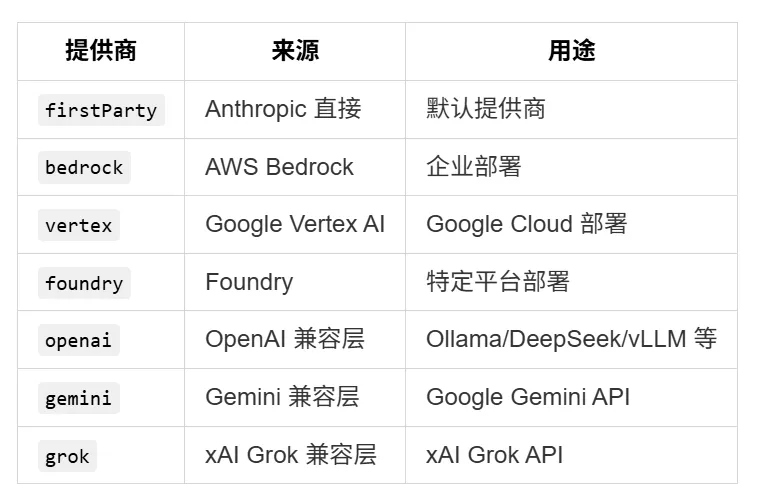
*在下一部分中,我们将深入 Claude Code 的核心循环 —— 理解它如何与 AI 进行对话。* 第五部分:核心循环 —— Claude Code 如何"思考" 前面我们看了入口、引擎和架构组织。现在,让我们来到整个系统最核心的部分:Claude Code 如何与 AI 进行对话? 这三个模块的关系,可以用一句话概括:query 是送信人,QueryEngine 是指挥官,REPL 是前台。 5.1 query.ts —— 送信人 + 翻译 query.ts 是整个系统中最接近 API 的模块。它的职责很明确: 处理 BetaRawMessageStreamEvent 事件流 Anthropic 的 API 使用 Server-Sent Events (SSE) 返回响应。这意味着响应不是一次性返回的,而是像水流一样一点一点到达。query.ts 需要: 这种流式处理的设计,让用户能够在 Claude 还在"思考"时就看到部分输出,极大地提升了交互体验。 5.2 QueryEngine.ts —— 对话的指挥官 如果说 query.ts 是送信人,那么 QueryEngine.ts 就是指挥官。它负责更高层次的编排: QueryEngine 的核心职责是管理"一轮对话"的完整生命周期。 API 返回 tool_use → 执行工具 → 将结果作为用户消息发回 API 再次返回 tool_use → 再次执行 → 再次发回 这个循环在 QueryEngine 中被管理,而 query.ts 只负责单次 API 调用。 5.3 核心循环的完整流程 让我们用一张流程图来展示从用户输入到 AI 响应的完整路径: 这张图揭示了 Claude Code 核心循环的几个关键特征: 1. 循环直到完成 只要 API 返回 tool_use,循环就会继续。这意味着 Claude 可以连续调用多个工具,直到它认为自己有足够的信息来回答用户的问题。 2. 权限审批是循环的一部分 当工具调用需要权限时,循环会暂停,等待用户批准或拒绝。这个设计让用户能够在关键时刻介入。 3. 压缩是自动的 当消息历史接近上下文窗口限制时,系统会自动触发压缩(compaction)。压缩会将消息历史缩减到可管理的大小,同时保留关键信息。 5.4 API 层的七种实现 Claude Code 支持 7 种不同的 API 提供商: 提供商选择优先级:modelType 参数 > 环境变量 > 默认 firstParty 第三方 API 格式 → 流适配器 → Anthropic 内部格式 → 下游代码 这意味着下游代码完全不需要关心使用的是哪个提供商,它只需要处理统一的内部格式。这种设计非常优雅 —— 适配器负责格式转换,核心代码负责业务逻辑。 5.5 压缩(Compaction)机制 当对话很长时,消息历史可能会超过 API 的上下文窗口限制(例如 200K tokens)。这时就需要压缩。 1. 压缩边界消息 在压缩时,系统会插入一个 SystemCompactBoundaryMessage,告诉 Claude 对话已经被压缩了。这类似于给 Claude 一个"记忆断点"。 2. 保留关键信息 保留最近的几条消息(因为它们最相关)
将旧消息总结为简短的摘要
保留工具调用的结果(因为它们包含了实际操作的信息)
3. 自动压缩 vs 手动压缩 压缩可以是自动触发的(当接近上下文窗口限制时),也可以是手动触发的(用户通过命令主动压缩)。 *在下一部分中,我们将了解状态管理系统 —— 理解数据如何在 Claude Code 中流动。* 第六部分:状态管理 —— 数据如何流动 在一个交互式 CLI 工具中,状态管理是至关重要的。你需要跟踪: Claude Code 使用了 Zustand + React Context 的组合来管理这些状态。 6.1 状态管理的层次 1. AppState.tsx —— 类型定义 2. store.ts —— Zustand Store Zustand 的选择很明智 —— 它比 Redux 轻量,比手写 reducer 方便。对于 CLI 工具这种不需要复杂状态管理的场景,Zustand 是一个很好的平衡点。 3. selectors.ts —— 状态选择器 选择器的作用是从全局状态中提取组件需要的数据。这样做的好处是: 4. bootstrap/state.ts —— 会话级全局状态 这个文件与 Zustand Store 不同。它存储的是会话级的全局状态,例如: 这些状态在整个应用生命周期内都存在,而且不通过 Zustand 管理,而是作为模块级单例。 6.2 数据流示意图 1. bootstrap/state.ts → store.ts —— 会话级单例为 Zustand Store 提供初始值 2. store.ts → AppState.tsx —— Zustand Store 被包装为 React Context Provider 3. AppState.tsx → Selectors —— 组件通过选择器从 Context 中提取数据 4. Selectors → React 组件 —— 选择器返回的数据被组件消费 5. React 组件 → 用户交互 —— 用户通过 UI 与系统交互 6. 用户交互 → store.ts —— 交互触发状态更新,形成闭环 6.3 状态更新的模式 在 Claude Code 中,状态更新主要有两种模式: 模式 1:直接更新 Zustand Store 模式 2:通过 action 更新 第七部分:构建系统 —— 从源码到产物 当你写完代码后,如何将它变成一个可以分发的 CLI 工具?Claude Code 的构建系统给出了答案。 7.1 build.ts 的三步流程 简单粗暴 —— 删除 dist/ 目录,确保构建产物是全新的。 这是核心步骤。Bun.build() 的参数揭示了构建的关键配置: ·entrypoints —— 入口文件是 cli.tsx
·splitting: true —— 启用代码分割,产物包含 cli.js + 多个 chunk files
·define —— 注入宏定义(MACRO.VERSION 等)和 React 生产模式
·features —— 19 个默认 feature + 环境变量中指定的额外 feature
构建产物默认用 Bun 运行,但为了兼容 Node.js,需要进行后处理: 1. 替换 `import.meta.require` —— Bun 独有的 API,Node.js 不支持。替换为 Node.js 兼容版本。 2. 替换 `globalThis.Bun` 解构 —— 第三方依赖可能直接解构 globalThis.Bun,在 Node.js 下会崩溃。替换为安全版本。 7.2 产物的结构 产物可以直接用 Bun 或 Node.js 运行: 7.3 Dev 模式 vs Build 模式 总结与预告 本章回顾 在这一章中,我们从零开始拆解了 Claude Code 的整体架构: 1. 入口的快速路径设计 14 条快速路径,只有最后一条才会加载完整的 CLI 框架。这种"能不加载就不加载"的设计,让 Claude Code 在大多数情况下都能在几百毫秒内启动。 2. Monorepo 的职责划分 15 个工作区包,每个都有明确的职责边界。内部框架、工具集、服务、原生模块,分类清晰。 3. 核心循环的协作 query → QueryEngine → REPL 的三层协作模式。query 负责 API 调用,QueryEngine 负责对话编排,REPL 负责用户交互。 4. 多提供商支持 七种 API 提供商通过流适配器模式统一为内部格式。这种设计让下游代码完全不需要关心使用的是哪个提供商。 5. 状态管理 Zustand + Context Provider 的组合,加上模块级单例管理会话级状态。 6. 构建系统 三步流程:清理 → Bun.build → 后处理。产物兼容 Bun 和 Node.js 运行。 这些设计你可以借鉴什么? 1. 快速路径系统 —— 对于 CLI 工具,将最常见的操作放在最前面,避免不必要的模块加载 2. Feature Flag 构建时优化 —— 使用构建时 DCE 消除死代码,而不是运行时判断 3. 并行预取 —— 让 IO 操作与模块加载重叠,而不是串行等待 4. 流适配器模式 —— 将第三方 API 格式统一为内部格式,下游代码只处理统一格式 5. Monorepo 职责分离 —— 每个包只做一件事,做好一件事 下一章预告 在理解了整体架构之后,下一章我们将深入 **查询引擎 QueryEngine** —— 理解 Claude Code 如何编排与 AI 的对话、如何管理上下文窗口、如何在长对话中进行压缩(compaction)、以及文件历史快照是如何工作的。
如果你曾经为"如何管理长对话的上下文"而苦恼过,这一章会给你带来答案。
*本系列的下一章将继续深入 Claude Code 的核心模块。敬请期待。*
 夜雨聆风
夜雨聆风