 夜雨聆风
夜雨聆风
文献来源:Ashyrmamatov et al., "A survey on large language models in biology and chemistry," Experimental & Molecular Medicine, 58, 970–980 (2026).DOI: 10.1038/s12276-025-01583-1
适读人群:生命科学 / 药学 / 化学方向研究生与科研工作者;AI 医药领域从业者;对 AlphaFold 之后科学 AI 走向感兴趣的读者
把分子当作语言来处理
过去五年,大语言模型(Large Language Models, LLMs)从 NLP 领域溢出,席卷了蛋白质设计、基因组学、药物发现、化学合成等几乎所有分子科学分支。相关论文快速涌现,研究者们面临的最大困惑不是 信息太少 ,而是 信息太碎 。
这篇由首尔大学五位作者联合完成、发表于 Nature 旗下期刊《Experimental & Molecular Medicine》的综述,试图做一件更难的事:在统一的分析框架下,同时覆盖生物大分子(蛋白质、核苷酸、单细胞)与小分子化学两个领域,系统比较表征策略、模型架构、训练范式与下游应用。
这种双域并举的视角,使其成为目前为止少数能同时回答"蛋白质语言模型和化学语言模型有何本质共性与差异"的参考文献之一。本文将沿着综述的核心逻辑,逐层深入,带你建立对这一领域的系统认知。
一、核心命题:表征是科学 LLM 的第一性问题
1.1 LLM 为何能迁移到科学领域?
LLM 的核心能力并非"理解"语义,而是对 token 序列的统计结构进行建模。只要某种科学数据能被编码为离散符号的序列,transformer 架构原则上就能学习其内在规律。
这一洞察带来了一个核心问题:如何把复杂、多维的分子信息转化为模型可处理的格式?
综述明确指出,这不是工程细节,而是根本性的设计决策——表征决定了模型能学到什么、能泛化什么、最终能发现什么。
1.2 科学表征的三重挑战
| 语义对齐 | ||
| 信息密度 | ||
| 多模态性 |
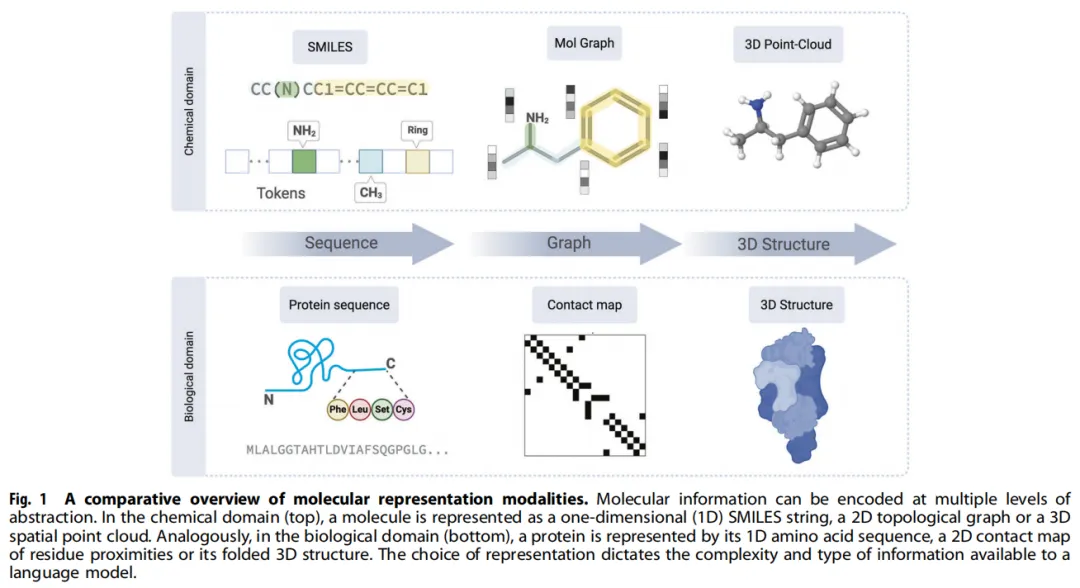
1.3 规模与表征的双重驱动
综述引用 Kaplan 等人的 Scaling Law 研究,强调模型规模和训练数据量是涌现能力的关键驱动力。但对于科学 LLM 而言,规模与表征必须同时到位:一个在糟糕表征上训练的巨型模型,其上限仍然受到表征瓶颈的限制。
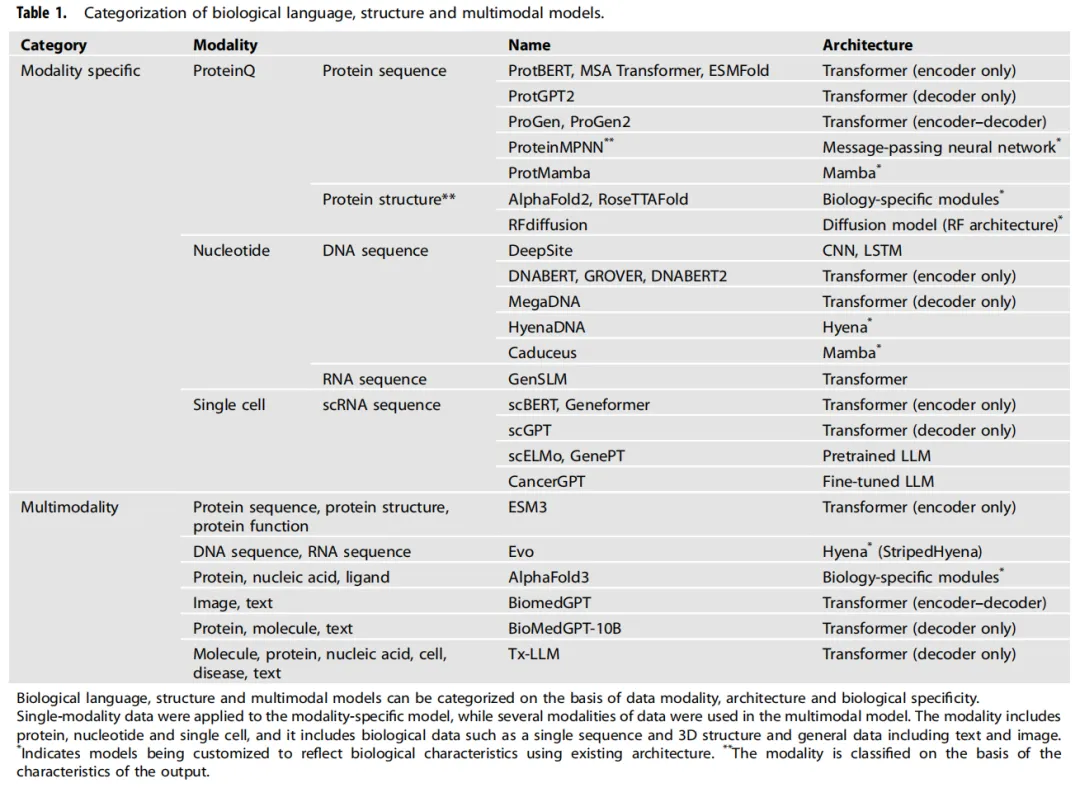
二、生物语言模型(BLMs):三大分子模态的建模进展
2.1 蛋白质语言模型:从序列到结构再到设计
2.1.1 历史脉络
蛋白质天然具有序列性,因此是最早成功应用 NLP 技术的生物模态。
• ProtBERT / ProtTrans(早期):直接将 BERT 的 MLM 预训练迁移到氨基酸序列,探索单序列与 MSA 两种输入格式。 • MSA Transformer:利用多序列比对(Multiple Sequence Alignment)捕捉跨物种进化信息,将"进化压力"编码进模型权重。 • ESMFold:关键突破。无需 MSA,仅通过语言建模即可达到 AlphaFold2 级别的结构预测精度。证明了语言模型可以隐式编码蛋白质的进化信息与折叠规律。 • ProtMamba:采用 Mamba(基于选择性状态空间的架构)替代 attention,在长序列建模上具有线性时间复杂度优势。
2.1.2 蛋白质结构预测的范式革命
传统结构测定(X 射线晶体学、NMR、冷冻电镜)成本高、周期长,已知序列数(UniProtKB)与已解析结构数(PDB)之间存在数量级差距。
AlphaFold2(AF2) 的核心创新:
• Evoformer 模块:生物特异性 transformer,将 MSA 视为"语言序列"处理,同时捕捉残基间的 pairwise 相互作用。 • 结构模块:端到端实现从一级序列到三维坐标的重建,达到接近实验精度。
AF2 之后的扩展方向:
• ColabFold:利用宏基因组序列数据库扩充 MSA 多样性,通过 Google Colab 降低计算门槛,实现普惠化部署。 • Phyre2.2:整合 AF2 预测结构作为新模板,支持域级优化和批处理预测。 • AlphaFold3:进一步扩展至 RNA、DNA 和配体的多分子复合物结构预测。 • RoseTTAFoldNA / RoseTTAFold All-Atom:将核酸、配体纳入统一结构预测框架。
2.1.3 蛋白质从头设计:生成模型的用武之地
• ProGen / ProGen2:自回归 transformer,通过条件标签控制生成序列的结构与功能属性。 • ProtGPT2:无监督深度语言模型,用于生成具有新颖功能的蛋白质序列。 • RFdiffusion:将图像生成领域的扩散模型适配至蛋白质结构生成,引入 SE(3) 等变性以保证物理一致性,在 scaffolding 任务上表现突出。 • ProteinMPNN:针对已知骨架设计序列的逆折叠模型。 • ESM3:联合嵌入序列、结构与功能,模拟了 5 亿年进化历程的语言模型,代表多模态生物表征的最新前沿。
2.2 核苷酸语言模型:四字母表的挑战
2.2.1 DNA 建模的特殊难点
DNA 仅由 A/T/G/C 四种碱基构成,字母表比蛋白质小 5 倍,信息密度更低,且没有天然的"词"边界概念,这使得 tokenization 策略的选择尤为关键。
2.2.2 模型演进
| DeepSite | ||
| DNABERT | ||
| GROVER / DNABERT2 | ||
| Caduceus | ||
| HyenaDNA | ||
| Evo | ||
| MegaDNA |
2.2.3 RNA 语言模型
GenSLM 是代表性 RNA 语言模型,采用密码子级词表(codon-level vocabulary)以避免移码问题,能够预测突变对 RNA 功能的影响效应(如 SARS-CoV-2 进化动态分析)。
2.3 单细胞语言模型:高维表达数据的语言化
2.3.1 核心挑战:非序列数据的序列化
单细胞 RNA 测序(scRNA-seq)数据是高维基因表达向量,天然不具有序列性。主流解决思路是:按表达量对基因排序,将同一细胞内的基因集合视为一个"词序列"。
2.3.2 代表性模型
• scBERT:利用完整基因表达谱(而非传统 marker gene),通过 gene2vec 编码 + BERT 架构,在细胞类型注释任务上超越传统方法。 • Geneformer:按基因计数统计排序,在多项细胞分类任务上展现有效性。 • scGPT:以基因嵌入为输入 token,输出细胞嵌入,联合学习两层次表征;在细胞分类、扰动预测、批次校正、多组学整合四类任务上均达到 SOTA。
2.3.3 通用 LLM 的跨界应用
令人惊讶的是,未经生物特化训练的通用模型同样展现出潜力:
• GPT-4:仅凭文本描述的基因表达水平,即可自动完成细胞类型注释。 • GenePT:调用 ChatGPT 的文本嵌入 API,从 NCBI 生物医学文献构建基因/细胞嵌入,在部分任务上超越专用的 Geneformer。 • scELMo:类似路线,利用语言模型嵌入构建单细胞数据分析工具。 • CancerGPT:GPT-3 在文本语料上微调,用于稀有组织类型的药物协同预测,将文本表征与细胞信息对齐。 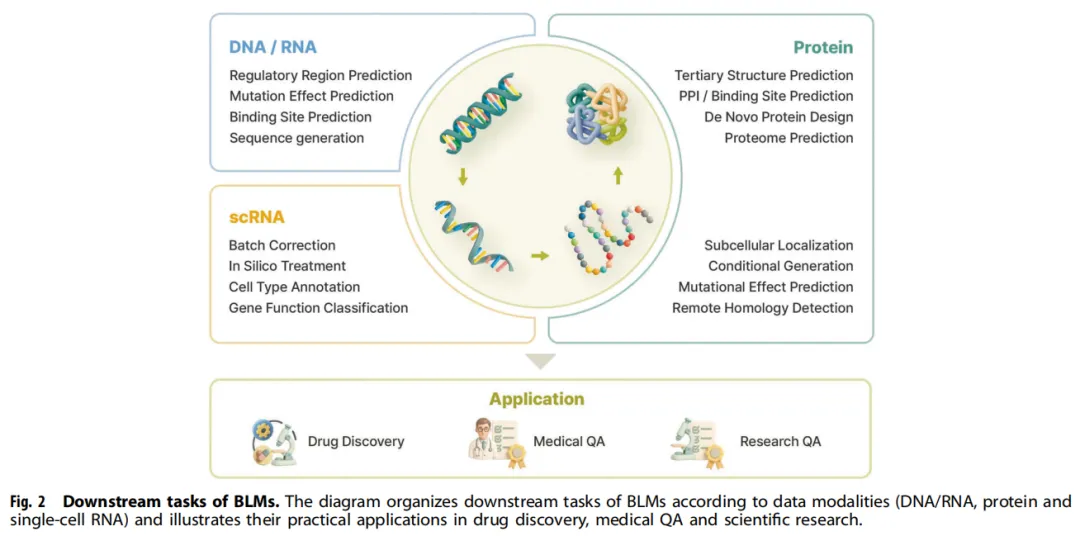
三、化学语言模型(CLMs):从小分子表征到药物设计
3.1 分子表征体系:三条技术路线
3.1.1 字符串表征(SMILES 及其衍生)
SMILES(Simplified Molecular Input Line Entry System)将分子结构编码为线性 ASCII 字符串,是目前最主流的化学语言格式。
核心局限:
• 非唯一性:同一分子存在多种合法 SMILES 表示,增加训练难度。规范化(canonicalization)能减少歧义,但可能导致模型过拟合句法模式而非化学规律。 • 缺乏立体化学信息:手性中心和几何异构体常被省略。 • 无三维信息:对构象敏感的任务(如分子对接)存在天然缺陷。
改进变体:
• DeepSMILES:调整括号和环闭合语法,降低句法错误率。 • SELFIES(Self-Referencing Embedded Strings):100% 化学合法性保证,所有生成的字符串均对应有效分子。 • Atom-in-SMILES:在 token 中嵌入局部拓扑上下文(邻近原子、环成员关系),提升低数据场景的优化性能。
3.1.2 图表征
将分子抽象为原子节点与化学键边的图结构,保留 SMILES 缺失的拓扑约束信息。
代表模型:GROVER(图神经网络 + transformer)、MG-BERT(图注意力机制 + BERT)。
主要挑战:tokenization 与序列模型对齐困难,缺乏标准化的图序列化流程。
3.1.3 三维点云表征
直接编码原子的三维空间坐标,捕捉分子几何特征,对分子性质预测和药物设计至关重要。
• Uni-Mol:专用 3D 感知 transformer,适用于分子预训练和蛋白质-配体复合物结构预测。 • nach0-pc:多任务语言模型,整合分子点云编码器与语言模型,在 3D 分子数据集上联合训练。 • 3D-MolT5:面向三维分子-文本统一建模。
3.2 模型架构分类:按任务选择架构
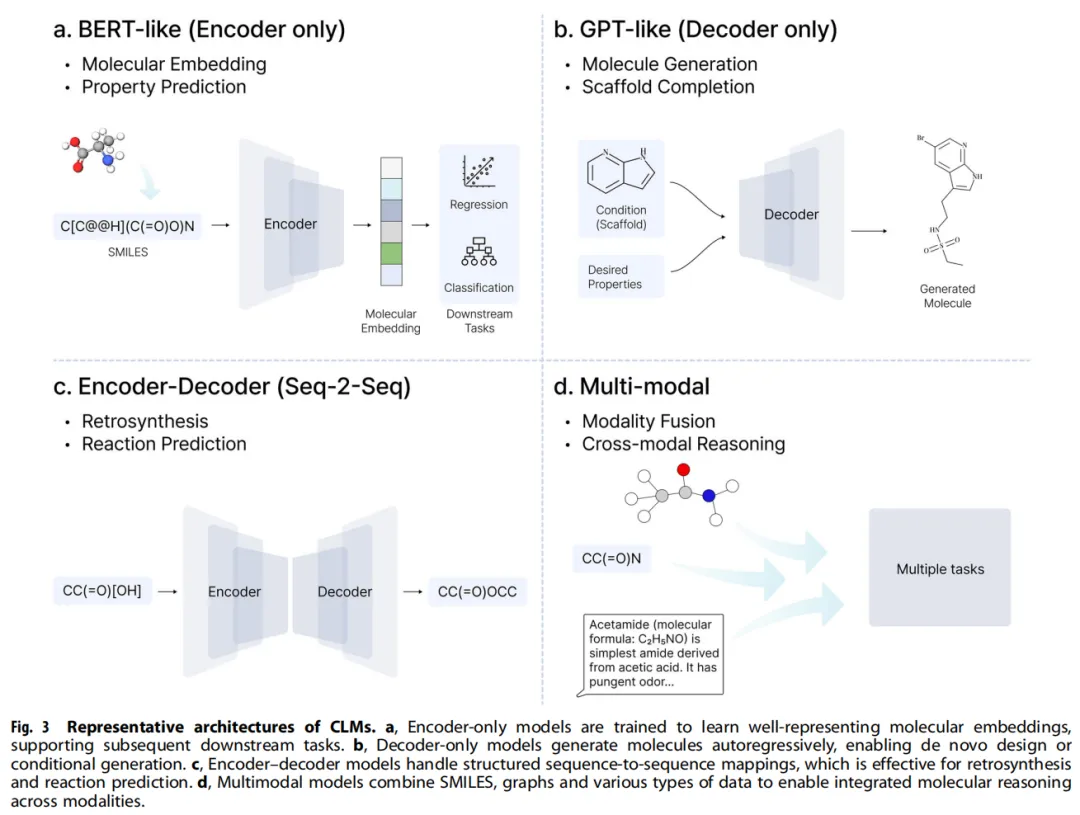 3.2.1 Encoder-only(BERT-like):分子理解与性质预测
3.2.1 Encoder-only(BERT-like):分子理解与性质预测
适合需要提取上下文表征的任务:分子性质预测、活性分类、毒性预测。
| ChemBERTa | ||
| Mol-BERT | ||
| MoLFormer | ||
| SELFormer | ||
| GROVER |
3.2.2 Decoder-only(GPT-like):从头分子生成
适合自回归生成任务:de novo 药物设计、骨架补全、条件分子生成。
| MolGPT | |
| GP-MoLFormer | |
| cMolGPT | |
| Taiga | |
| iupacGPT |
3.2.3 Encoder-Decoder:序列到序列的结构转换
适合序列映射任务:逆合成规划、反应预测、跨域分子翻译。
| Molecular Transformer | ||
| Chemformer | ||
| Text+ChemT5 | ||
| SELFIES-TED | ||
| SCROP | ||
| RetroTRAE |
3.2.4 多模态 LLM:跨模态融合推理
化学信息天然多模态(文本描述、分子图、2D 结构式、3D 坐标、光谱数据),标准 CLM 难以全面捕捉。
• Mol-LLaMA:将图表征引入语言模型,提升官能团识别和逆合成推理。 • GIT-Mol:独立编码图、图像和文本,通过共享表征层融合,对比学习对齐,多任务预测头。 • PRESTO / ChemVLM:视觉-语言模型,联合编码分子结构式图像与文本,支持合成规划和反应条件推断。 • nach0:SMILES、图像与文本的统一表征空间,多模态推理。
3.3 预训练与微调策略
3.3.1 自监督学习(SSL)
• MLM(Masked Language Modeling):随机遮盖 15% 的 token,训练模型从上下文恢复。强迫模型学习化学句法和分子结构的深层表征,是 encoder 类模型的主流预训练目标。 • 去噪目标(Denoising Objectives):训练模型从噪声/损坏版本重建原始输入。BART 系模型(BARTSmiles、SELFIES-TED)的核心预训练策略。
3.3.2 多任务学习
同时训练多个相关任务,共享权重,迫使模型学习跨任务通用表征:
• Text+ChemT5:化学与自然语言跨域权重共享。 • nach0-pc:在 3D 分子数据上的多任务语言模型。 • 优势:缓解单任务数据稀疏问题,提升低资源场景泛化能力。
3.3.3 检索增强生成(RAG)
在推理时动态检索外部知识库,提升模型在特定任务上的表现:
• 在分子设计、逆合成、反应预测等任务上报告了高达 17.4% 的性能提升。 • 通过引入最新领域数据,有效缓解"幻觉"问题。 • ATLANTIC:构建异构文档图,使用冻结 GNN 进行上下文编码,改进检索质量同时保持计算效率。
3.3.4 监督微调与参数高效方法
全参数微调在低资源场景下易过拟合,参数高效方法(PEFT)成为主流:
| LoRA | |
| Adapter Tuning | |
| Prefix Tuning | |
| Prompt Tuning |
四、生物医学应用:从预测到设计再到自动化
4.1 蛋白质结构与功能预测
AlphaFold 系列引发的结构预测革命已广为人知,但综述更关注后 AlphaFold 时代的演进方向:
• 多分子复合物预测:AF3、RoseTTAFoldNA 将 RNA、DNA、配体纳入统一预测框架。 • 全原子结构预测:RoseTTAFold All-Atom 挑战精确重建所有原子三维坐标的计算难题。 • 功能整合建模:ESM3 同时嵌入序列、结构与功能,标志着从单模态向多模态表征的转变。 • DNA 结合蛋白预测:ESM-DBP 等专用模型采用序列-结构混合策略。
4.2 蛋白质从头设计
这是目前最令生物学家兴奋的方向之一:不再只是预测已有蛋白质的结构,而是从零设计具有特定功能的新蛋白质。
RFdiffusion 等扩散模型通过 SE(3) 等变性将几何约束纳入生成过程,在 scaffolding、binder 设计等任务上取得重大突破。ProteinMPNN 和 Foldseek 的组合进一步加速了设计-验证迭代循环。
4.3 基因组分析
transformer 类模型在以下任务上已展示出超越传统方法的能力:
• 调控区域预测(启动子、增强子识别) • 转录因子结合位点预测 • 突变效应推断(SNP 功能影响) • 长程基因组相互作用建模
4.4 分子性质预测与药物发现
CLM 正系统性地渗透进药物发现流程:
• 早期筛选:从 SMILES 直接预测溶解度(ESOL、FreeSolv)、生物利用度、血脑屏障通透性(BBBP)、毒性(Tox21、SIDER)。 • De novo 分子设计:自回归与扩散模型生成具有优化活性、选择性或合成可及性的新化合物。 • 反应预测与逆合成规划:在 USPTO 等反应数据库上训练的 seq2seq 模型,为目标药物分子建议合成路线。 • 毒理学评估:学习与不良效应相关的结构模式,支持临床前风险评估。
4.5 多模态基础模型:走向统一的生物医学平台
• BiomedGPT:对齐自然语言与生物医学视觉表征,支持诊断、摘要、临床决策等跨模态任务。 • Tx-LLM:在 RNA、DNA、蛋白质序列及 SMILES 上大规模预训练,在端到端药物发现任务上展现正向迁移。 • BioMedGPT-10B:专注蛋白质-分子问答,整合细胞序列、蛋白质和分子结构信息。
4.6 智能体系统:迈向自主科学发现
这是综述最具前瞻性的部分。LLM 与外部工具的结合催生了"科学智能体":
代表性系统:
• Coscientist:整合网络搜索、文献检索、逆合成工具和实验室协议,实现多步骤化学研究自主规划。 • ChemCrow:将 18 种化学工具(RDKit、SafetyCheck、文献搜索等)接入 LLM,完成复杂合成任务。 • ChatMOF:专注金属-有机框架(MOF)材料的性质预测与生成。 • Chemputer / Organa:LLM 指导下的实验室自动化平台,实现合成规划到机器人执行的全链路自动化。
核心范式 ReAct(Reason + Act):交替进行 LLM 推理与外部工具调用,形成闭环的多步骤工作流。
⚠️ 当前局限:这些系统仍严重依赖确定性工具链和人类监督,在开放式科学推理方面仍有很大差距。
五、数据集与基准:模型能力的边界在哪里?
5.1 化学领域核心数据集
| ZINC-22 | ||
| PubChem | ||
| ChEMBL | ||
| USPTO | ||
| QM9 / QMugs | ||
| MoleculeNet |
5.2 生物医学领域核心数据集
| PubMed / PubMed Central | |
| MIMIC-III / eICU | |
| MedQA / PubMedQA / BioASQ | |
| Therapeutics Data Commons | |
| DisGeNET / DrugBank / STRING | |
| Human Cell Atlas |
5.3 当前基准的局限
综述指出,尽管数据积累迅速,跨化学与生物域的系统性对比研究仍然匮乏,标准化基准体系尚不完善,这严重制约了领域间的知识迁移与模型能力评估。
六、提示工程与大型通用 LLM 的科学应用
除了专用科学 LLM,ChatGPT 等通用大模型也在化学与生物领域展现出令人意外的能力:
6.1 提示工程策略
• 零样本提示:无需示例,直接描述任务。在简单分子转换、基本性质预测上有一定效果。 • 少样本提示(Few-shot):提供若干示例对,引导模型推理模式。 • 思维链提示(CoT):引导模型逐步推理,在复杂化学任务(逆合成规划、反应分类)上效果改善显著。
研究表明,在逆合成规划和反应分类任务上,精心设计的提示可以驱动 LLM 达到令人惊讶的表现水平。但提示敏感性、领域知识有限和输出不一致性仍是主要瓶颈。
6.2 领域特化微调
通过在化学文献和领域数据集上继续预训练,ChatGPT 类模型可以内化领域语言与逻辑:
• 在化学性质回归、反应预测、文献知识提取上表现提升。 • 在无机化学、热电材料等细分领域,即便在小规模数据集上微调也有效。 • 关键挑战:结果对数据质量和任务设计高度敏感。
七、关键挑战与未来展望
7.1 当前核心挑战
| 表征 | |
| 数据 | |
| 模型 | |
| 评估 | |
| 伦理与安全 |
7.2 未来发展方向
综述总结了以下前沿趋势:
1. 向先验知识对齐:在训练过程中更有效地融合化学/生物物理约束与先验知识,而非仅依赖数据驱动。 2. 统一多模态基础模型:整合表观遗传标记、空间转录组学、蛋白质表达数据和扰动信号,构建更全面的细胞表征。 3. 可解释性提升:发展可解释的 attention 机制和特征归因方法,为实验验证提供可信指导。 4. 标准化评估体系:建立跨化学与生物域的统一基准框架,推动严格的模型对比。 5. 智能体科学系统:更成熟的"AI 科学家"系统,具备假设生成、实验设计、结果解读的闭环能力。 6. 设计-构建-测试-学习(DBTL)循环加速:LLM 作为整个生物医学发现管线的协作平台。
小结:一张关于科学 AI 的全景地图
这篇综述最大的价值在于提供了一个统一的分析框架:
分子信息 → 表征设计 → 模型架构 → 训练策略 → 下游任务无论是蛋白质语言模型还是化学语言模型,无论是结构预测还是分子生成,都可以沿着这条主线进行定位和比较。
核心判断:
• 表征是科学 LLM 的第一性问题,决定了模型的能力天花板。 • 规模(模型参数 + 数据量)和架构(如何处理长序列、多模态)同等重要。 • 专用科学 LLM 与通用 LLM 的能力边界正在快速变化,混合策略(通用模型 + 领域微调 + 工具调用)代表当下最优实践。 • 智能体系统是下一个爆发点,但距离真正的"自主科学发现"仍有相当距离。
对于正在这个领域工作或希望进入的研究者而言,这篇综述是建立系统认知的绝佳起点。
