 夜雨聆风
夜雨聆风

00
引言
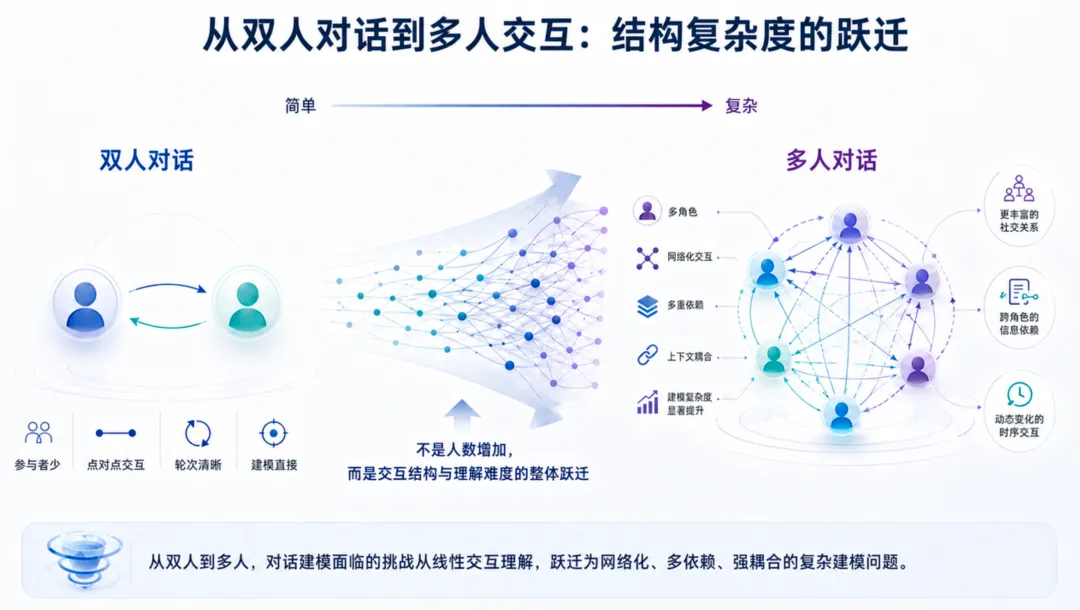
当大模型从单轮问答工具走向长期协作的 Agent 系统,“记住”正在变成一个绕不开的问题。一个真正可用的 Agent Memory,不只是能保存几条用户偏好,而是要在多轮对话、多人关系和持续变化的信息中,判断什么该记住、什么已经过期、什么需要更新,以及什么时候应该承认“没有足够依据”。
为了更准确地评测这种能力,MemoraX AI 联合牛津大学推出 ScriptMem:一个基于真实剧本构建的 Agent Memory 评测基准。ScriptMem 选取 4 部高质量剧本作为语料基础,围绕人物、事件、关系和状态变化构建知识图谱,再从图谱中自动采样跨角色、跨时间、跨事件的记忆链条,生成 457 道记忆评测题。
这套设计的核心,是让记忆评测更接近真实交互中的复杂性。相比单纯依赖 LLM 合成长对话,真实剧本提供了更稳定的人物设定、更清晰的事件因果和更可追踪的时间线;相比单纯把文本拉长,图谱化构建和自动出题让题目难度来自信息之间真实存在的依赖关系。
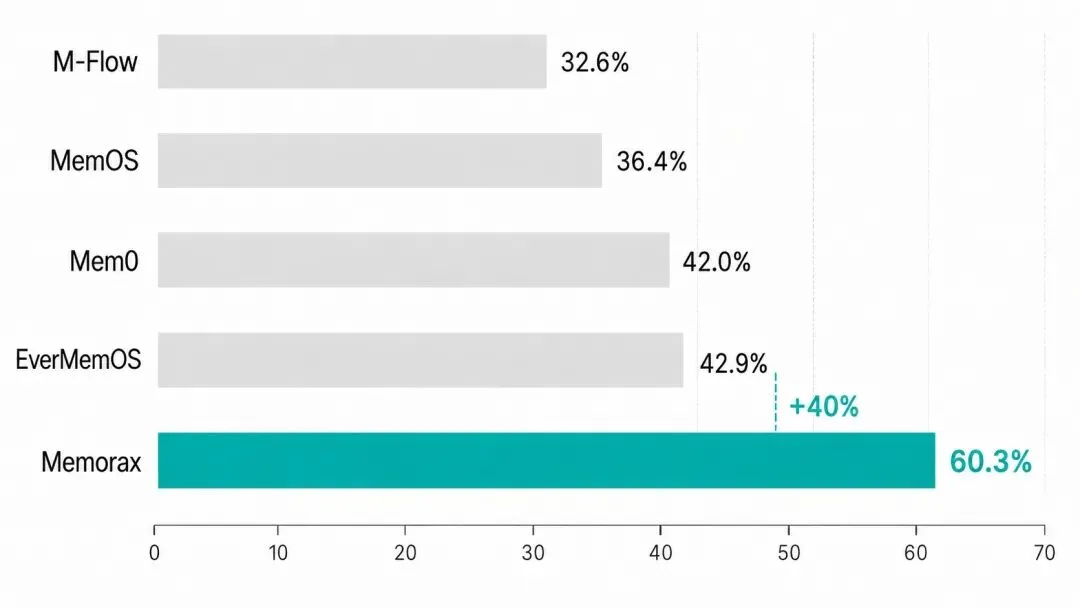
测试结果显示,ScriptMem 能够有效区分不同记忆框架的表现。在统一使用 GPT-4o-mini 作为底层模型的设置下,不同记忆框架之间呈现出明显差异,其中,MemoraX 取得 60.3% 的正确率,相比第二名 EverMemOS 相对提升 40%。后文将进一步通过题型拆分和归因案例,说明这些差异具体体现在哪里。
现有很多评测基准可以告诉我们模型最终答对还是答错,却很难进一步说明这个结果意味着什么。ScriptMem 想推动的,是 Agent Memory 评测方式的一次转向:从只看最终分数,走向更可靠的语料基础、更真实的记忆难度,以及更清楚的问题定位。Agent 记忆能力评测的价值不只是比较谁分数更高,而是帮助记忆系统改进有更明确的方向。下文将从真实语料、诊断能力、难度设计和测试结果四个角度,展开介绍 ScriptMem 的设计思路与实验发现。
01
真实多人语料:
先让被记忆的世界足够可靠
做 Agent Memory 评测,有一个很容易被忽视的前提:被记忆的世界本身必须可靠。
如果一段评测语料里的人物设定会漂移,事件因果前后不一致,时间线也暗含矛盾,那么模型答错时,我们就很难判断问题到底出在哪里。是记忆系统没有写入?是检索召回不全?还是原始语料本身就无法支撑一个稳定答案?
这对记忆评测来说不是小问题。因为记忆测评的核心价值,不只是给出打分,而是帮助定位系统到底在哪个环节失效。语料一旦不可靠,后面的评测结果就很难解释,归因也容易失准,系统改进更无从对准问题。
因此,ScriptMem 从一开始就没有把数据基础放在纯 LLM 合成的长对话上,而是选择真实、高质量的剧本作为语料底座。这样做的目的,是尽可能降低语料噪声对评测结论的干扰,当系统答错时,错误更可能反映记忆系统本身的问题。
为什么合成语料撑不起长期记忆评测
过去不少评测基准会使用 LLM 批量生成长对话或虚构场景。这样做的好处很明显:成本低、规模扩展快、题材也容易控制。但在长期记忆评测里,这条路线有一个绕不开的风险:合成文本很难长期维持稳定的事实结构。
在短对话里,模型通常可以保持局部连贯;但当叙事跨越几十轮甚至上百轮后,早期的一点设定偏移、一次人物关系误写、一个时间点没对齐,都可能在后续内容里不断放大。最后得到的文本表面上仍然流畅,但前后细节已经对不上了。这类问题放在普通生成任务中,可能只是语料瑕疵;但放在 Agent Memory 评测里,就会变成更麻烦的问题:模型答错时,我们很难判断它是真的没有记住,还是被语料里前后不一致的细节带偏了。
因此,ScriptMem 选择真实剧本,并不是因为剧本“更像故事”,而是因为剧本里天然存在大量需要长期追踪的信息:人物关系会变化,立场会反转,计划会更新,旧信息也会被新信息覆盖。这种做法可以更精确地暴露记忆系统的真实短板,而不至于让语料本身的噪声污染评测结果。
基于这一思路,ScriptMem 最终选取了4部代表性作品。它们在交互结构上形成互补,共同覆盖了记忆的典型测试类别:
《老友记》(长周期关系演化): 长时间跨度下,人物之间的日常互动与关系在潜移默化中持续演变;
《十二怒汉》(高密度与立场反转): 封闭物理空间和单一时间线内,高密度的信息交锋带来立场的快速变化;
《这个男人来自地球》(深层博弈与信息解构): 纯粹的长对话形式,要求 Agent 在极深的信息层面上进行逻辑和身份推演;
《全民公敌》(多源信息追踪与动态图谱): 引入宏大的公共事件背景,充斥着复杂的多方利益对抗、信息不对称以及动态的社会关系变化。
这4类场景共同构成了 ScriptMem 的语料基础:它们不是简单增加文本长度,而是提供了更接近真实人类交互的记忆复杂度。
剧本有助于暴露记忆系统的真实瓶颈
真实剧本的价值,不只是“内容更可靠”,还在于它能自然制造出合成语料很难稳定复现的复杂结构:
多角色关系网络:人物之间形成多边关系网络,包含合作、对立、信任与冲突的动态变化。记忆系统必须同时追踪多个角色的状态,并理解它们之间的相互影响——任何一个角色状态的误判,都可能导致整个关系网络的理解错误。
跨轮次状态演化:人物的偏好、立场、计划和态度不是一次性给出的静态事实,而是在多轮交互中逐步形成、不断修正的动态过程。记忆系统需要持续追踪这些变化,而不是只记住某一时刻的状态——这正是长期记忆与单次阅读理解的根本区别。
跨角色信息依赖:很多问题的答案无法从单一角色的发言中直接获得,必须结合多个角色在不同时间点的表达才能推断出来。这要求记忆系统不只是存储信息,还要能在检索时识别跨角色的隐性依赖,并完成多跳整合。
也就是说,剧本带来的难度不是“文本很长”,而是“信息之间真的有关联”。这类关联无法靠局部语义匹配轻松绕过,也更接近真实 Agent 在长期协作中会遇到的记忆挑战。
在题目设计上,ScriptMem 采用选择题、排序题等客观形式。干扰选项并非随意构造,而是来自剧本中的真实信息,只是不满足当前问题的关键约束。这让错误更接近真实的记忆失败模式:系统不是完全不知道,而是记住了一部分、混淆了另一部分、在关键约束上判断失误——长期记忆系统最危险的失败,往往正是这种“看起来相关,但其实用错了”的错误。
02
可诊断:
Benchmark 不该只是一张分数表
很多 Agent Memory 评测都有一个共同问题:它们只看最后答案,却很少告诉我们答案为什么错。
但记忆系统不是一步完成的。一次回答背后,通常要经过信息识别、记忆写入、记忆更新、候选召回、上下文整合和最终推理。任何一个环节出错,最后都可能表现为同一个结果:答案不对。
问题在于,同样是答错,背后的原因可能完全不同。
有可能是原文里的关键信息一开始就没被识别出来;也可能是信息识别出来了,但没有正确写入记忆;还有可能是记忆已经存在,只是在检索时没有被召回;也可能是相关信息都找到了,但模型在整合时混淆了人物关系;甚至还有一种情况:文本里根本没有足够依据,系统本该拒答,却顺着上下文编出了一个看似合理的答案。
这些错误在总分里没有区别,都会被记成“答错”。但对系统开发者来说,它们指向的是完全不同的修复方向。写入错了,要改信息抽取和更新;检索漏了,要改召回和排序;推理混了,要改多跳整合;边界错了,要改拒答机制。
如果测评基准只给一个分数,我们看到的只是系统表现不好,却看不到问题到底卡在哪一步。ScriptMem 想解决的,正是这个问题:让每一次错误都能被追溯到具体环节。
沿着记忆流程回放信息流
要让测评基准具备诊断能力,关键是把最终错误拆回记忆系统的中间过程。ScriptMem 在评测时,会借助记忆系统在运行过程中已有的中间信息,包括输入处理、记忆写入与更新、候选记忆召回,以及最终推理结果。当一道题答错时,自动归因模块会对照这些日志与标准答案,沿着系统运行链路回放一次信息流,逐阶段判断当前信息是否足够支撑正确答案。
它追踪的不是“最后答错了”,而是更具体的问题:系统到底是没记住,没取到,还是没用对。
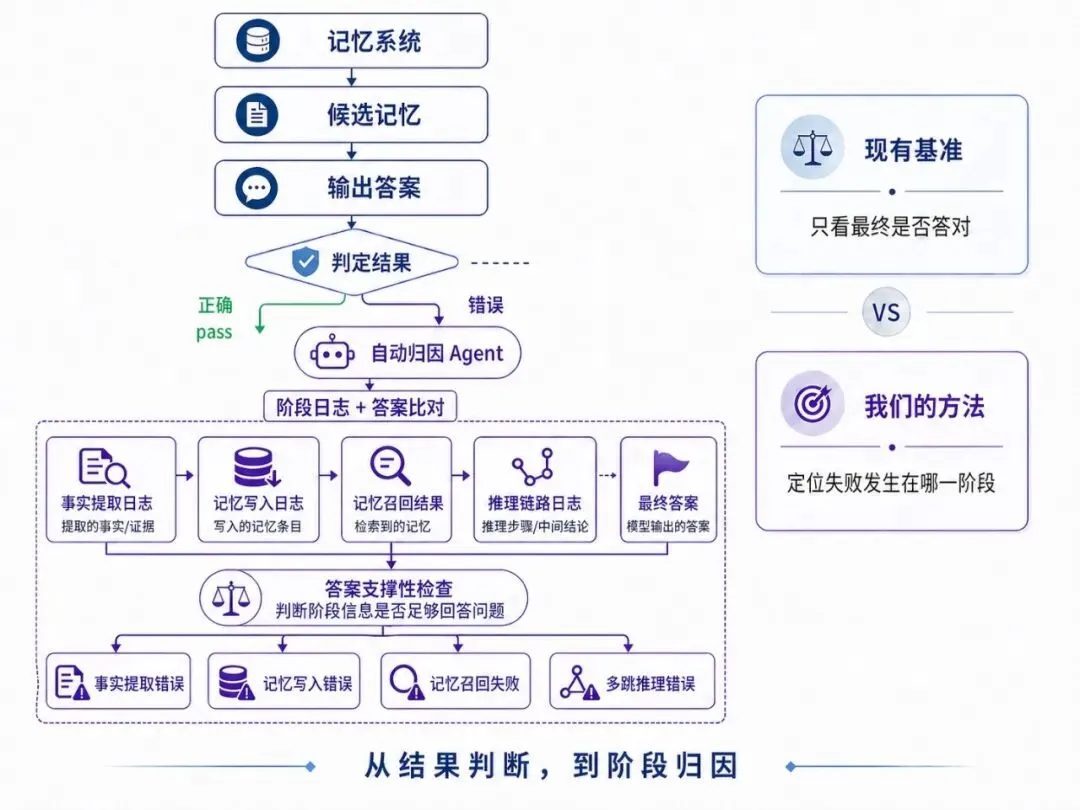
错误类型 | 主要含义 |
事实提取失败 | 原文中的关键事实没有被正确识别或抽取 |
记忆写入失败 | 提取的事实没有被正确写入或更新到记忆中 |
记忆召回失败 | 关键记忆已写入但在检索阶段未被有效召回 |
多跳推理失败 | 多个分散事实没有被组合成正确判断 |
拒答边界失败 | 面对超出记忆范围的问题时,系统没有正确拒答,反而产生脑补 |
03
难度:不是把文本拉长,
而是把记忆链条做深
很多长文本评测在设计难度时,默认采用一个很直接的办法:把文本变长。文本越长,信息越多,模型处理起来就越难。
这个思路在普通长文本问答里有一定道理,但放到 Agent Memory 上,就不够了。
因为长期记忆真正难的,不只是“在更长的文本里找到一句话”,而是要判断不同信息之间的关系:谁在什么时候说过什么,后来有没有改口;一个事件是否改变了后续计划;两个人的关系有没有变化;某个答案是否需要结合多个角色在不同时间点的表达才能推出。
单纯拉长文本,更多是在增加定位和检索难度。它考验的是能不能在更大的范围里找到相关信息;但 Agent Memory 更需要考验的是,系统能不能把跨时间、跨角色、跨事件的信息正确连起来。
所以,ScriptMem 在设计难度时,没有把重点放在“文本有多长”,而是放在“信息之间有多深的依赖”。
用知识图谱把隐藏的依赖关系找出来
要让题目真正考到这些复杂依赖,首先要解决一个问题:剧本中的人物关系、状态变化和因果线索,通常不是直接显式给出的,而是隐含在一轮轮对白和剧情里。
如果直接从剧本里随机抽句出题,大多数问题很容易退化成局部事实检索:谁说了某句话、某个事件发生在哪里、某个人做了什么。这样的题当然也有价值,但还不足以考察长期记忆系统最容易出错的地方。
ScriptMem 的做法是,先围绕剧本构建知识图谱,把人物、事件、关系和状态变化抽取出来,再根据图谱中的连接关系设计问题。
这样做的意义在于:原本散落在几十轮对话里的信息依赖,会被显式组织起来。哪些人物关系发生过变化,哪些事件影响了后续行动,哪些状态被新信息覆盖,都可以被定位出来。出题时也就不再依赖随机抽取,而是可以有意识地选择那些需要跨轮次、跨角色、跨时间整合的信息链条。
ScriptMem 为每部剧本构建的图谱包含数百个实体节点和上千条关系边,覆盖身份、事件、关系与状态变化等多层结构,让原本散落在数十轮对话中的隐性依赖被完整组织起来。借助这些图谱,ScriptMem 可以从剧本中系统性地采样复杂记忆链条,而不是只围绕局部事实出题。

基于知识图谱,ScriptMem 识别出五类典型链条。它们对应的不是文本长度,而是记忆系统在真实交互中经常会处理不好的信息关系。
人物链条:某个角色的偏好、习惯或身份,是否在不同场景中保持一致?后来有没有发生变化?这类问题要求系统跨轮次聚合同一人物的多次表达,而不是只记住某一次发言。
事件链条:某个事件发生后,是否改变了后续的计划、关系或行动?这类问题要求系统记住事件本身,也要理解它对后续剧情的影响。
时间链条:某个状态是在什么时候形成的,后来是否被更新或替代?这直接考察系统对信息时效性的判断能力。
关系链条:两个人之间的关系,是否在多次交互中发生了变化?这要求系统追踪关系的动态演化,而不是只记录某一时刻的关系状态。
因果链条:后文某个行为,是否需要结合前文某个铺垫才能正确理解?这要求系统在检索时识别跨轮次的隐性因果依赖。
这五类链条共同指向同一个设计目标:题目的难点必须来自记忆链条本身的复杂性,而不是来自文本长度或语义模糊。
六类题型,覆盖记忆系统的关键失效场景
链条决定了问题从哪里来,题型则决定了具体考什么。
基于这些链条,ScriptMem 构造了六类记忆评测题,分别对应:用户画像聚合、事件追踪、时序演化追踪、社会关系与交互、精细化数据记忆、经验教训归纳。
这些题型有一个共同的特点:答案通常不能靠命中某一句相关文本直接得到。模型即便找到了某一句相关片段,也可能因为漏掉后续状态变化、混淆相似角色、没有处理新旧信息覆盖,或者没有完成多跳整合而答错。
这也是 Agent Memory 和普通长文本问答之间的重要区别:普通问答更关心模型能不能在上下文里找到答案;长期记忆更关心系统能不能持续管理信息状态,知道哪些信息还有效,哪些已经变化,哪些需要结合起来看。
04
测试结果:
难度可区分,失败可追踪
一个评测基准是否有价值,不能只看题目够不够难,更要看它能不能把结果讲清楚。它要能回答这两个问题:整体上,哪些能力拉开了系统差距;具体到每一次答错,问题又卡在了记忆的哪一步。
整体结果:ScriptMem 对记忆框架形成了有效区分
在统一使用 GPT-4o-mini 作为底层模型的设置下,ScriptMem 对 4 个现有记忆系统和 MemoraX 进行了测试。结果显示,4 个现有记忆系统在 ScriptMem 上的整体正确率均低于 43%。在跨对话状态追踪、角色区分、信息更新等任务上,仍然有明显短板。
在同样设置下,MemoraX 的整体正确率达到 60.3%,相对第二名 EverMemOS 增益超过40%。
分题型来看:不同系统的短板并不相同
只看整体正确率,只能看到系统之间有差距;拆到具体题型后,差距背后的原因会更清楚。
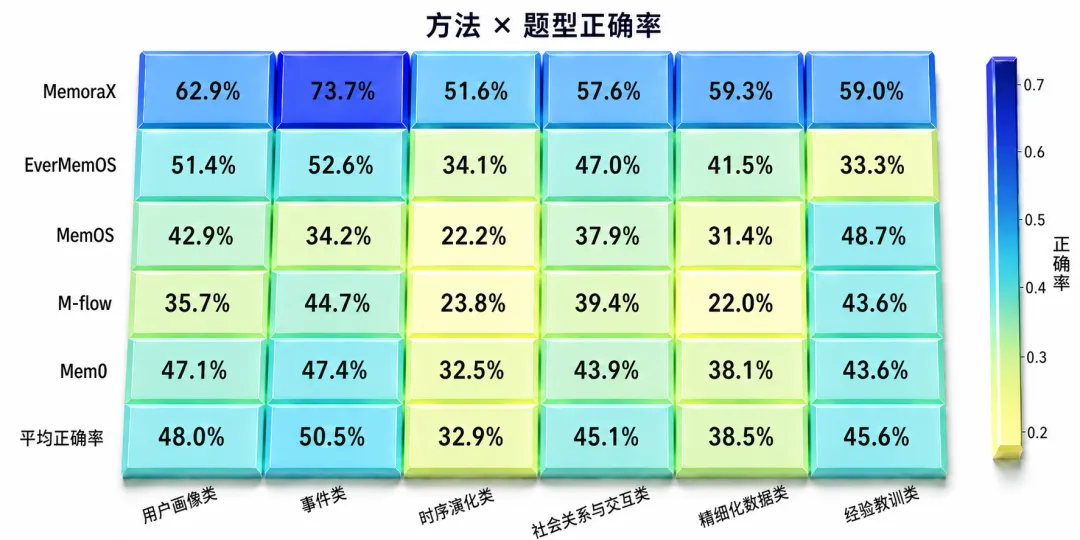
实验进一步统计了 MemoraX和EverMemOS、MemOS、M-flow、Mem0 在六类题型上的表现。
从六类题型来看,不同系统的表现并不完全同步:有的系统在事件追踪类任务上表现相对更好,但在经验归纳或精细化数据记忆上明显下降;有的系统能够处理部分概括性信息,却在时序演化类任务中更容易失分。也就是说,记忆系统的短板往往不是均匀分布的,而是会集中暴露在某些具体能力上。
归因机制:错误可以被拆回具体环节
分题型结果能说明系统在哪类任务上更容易出错,但对 Agent Memory 来说,这还不够。一次具体的错误,可能发生在不同环节。ScriptMem 的归因机制,会回看系统在评测过程中的中间记录,包括事实提取、记忆写入、候选召回和最终回答,再判断错误是从哪一步开始发生的。

以《十二怒汉》中的两个问题为例。
案例一(事实提取 / 记忆写入错误)来自《十二怒汉》Q42,问连续读出多少次“Guilty”后才出现“Not guilty”,标准答案是 7 次(E),系统答 6 次(B)。回放运行日志可以看到,系统检索到的核心记忆已经是“FOREMAN declared guilty six times”——也就是说,记忆系统在事实提取与记忆写入时就把 7 次记成了 6 次。后续的检索和回答只是忠实地调用了这条错误记忆。归因结论是:计数事实写错。
案例二(记忆检索错误)来自同一作品的 Q64,问 Juror #3 最终对男孩有罪的立场,标准答案是“勉强同意 not guilty”(A),系统答“继续相信男孩有罪”(D)。归因结果显示,正确的终态记忆其实存在于库中(session_6 D6:304–305 明确记录了 “All right!” 和 “Not guilty”),但它没有被排到检索前列;占据前列的反而是中途状态和其他角色的状态变化(“#7 changes his vote…” “#5 changes his vote…”)。因此错误的真正根因在检索排序失败导致终态记忆未被召回。
这两个案例表面上都是答错,但排查方向完全不同:前者要检查事实抽取、计数记录和写入校验,后者要检查检索排序,以及新旧状态信息在召回时的优先级。
这也是 ScriptMem 相比普通分数型 Benchmark 更进一步的地方:它不只是告诉我们系统错了,还能帮助判断错误从哪里开始发生。对记忆系统来说,知道“错了”只是第一步,知道该查写入、查检索,还是查最终推理,才真正有助于后续改进。
05
结语
记忆评测基准不该只是刷分题库,也应该帮助开发者看清 Agent Memory 系统到底错在哪里。ScriptMem 现已开源,包含完整的评测数据集和评测流程代码,欢迎研究者和开发者使用与贡献:
🔗 GitHub:https://github.com/memorax-ai/ScriptMem.git
ScriptMem 的三个设计原则——真实语料保障评测信度、归因机制定位失败环节、链条深度驱动题目难度——共同指向一个目标:
让 Agent Memory 的评测建立在更可靠的语料基础、更可定位的失败诊断,以及更真实的记忆难度之上,让后续系统改进有更清楚的依据。
从单轮问答到长期 Agent,记忆能力正在成为系统可靠性的核心变量。真正重要的问题不是模型在某个榜单上多拿了几分,而是通过评测能不能清楚地知道:它记住了什么,漏掉了什么,把什么记错了,以及为什么。只有当评测基准能够回答这些问题,Agent Memory 的改进才有更清楚的方向。
欢迎扫码入群交流:

关于我们
强化学习实验室,专注于智能体决策与自主学习的前沿研究,探索算法、理论与应用的创新路径。致力于搭建学术交流平台,分享最新研究成果、实验心得与领域前沿动态。
知乎:@强化学习实验室
小红书:@强化学习实验室
MemoraX AI 是一家聚焦大模型个性化记忆赛道的前沿AI科技公司。致力于突破当前大模型长期记忆缺失的行业核心痛点,打造下一代智能Agent的核心记忆基础设施,是大模型个性化记忆赛道的引领者。
公众号:@忆纪元MemoraX AI
小红书:@MemoraX AI
