 夜雨聆风
夜雨聆风原链接:https://x.com/_avichawla/article/2052326975034048754
Karpathy、Garry Tan 和科技圈最顶尖的构建者们正在不约而同地走向 AI 第二大脑。本文提供了一份完整的 100% 本地化搭建指南。这股浪潮的发展速度远超大多数人的认知——六个月后,这将成为标配。
Karpathy 的 LLM Wiki 将原始资料源编译成一个持久的 Markdown 知识库,带有反向链接和交叉引用。
LLM 负责阅读论文、提取概念、撰写百科全书式的文章,并维护索引。这些知识只需编译一次并保持更新,LLM 在查询时就不需要从头重新推导上下文。
这套方案之所以可行,是因为研究本质上关乎概念及其之间的关系,而这些内容相对稳定。
但当你把这种模式应用到实际工作中时,它就失效了——因为在工作场景中,上下文在跨对话之间不断演变。
一个编译好的 Wiki 可能会有一个关于某项目的页面,但它无法追踪到某个截止日期在一封邮件中被确认、又在另一封邮件中被推迟、而团队仍然按照原定日期在推进的情况。
Wiki 无法有效地追踪事实真相。
我最近写过关于这个话题的文章,Karpathy 也点赞了:
要追踪这类信息,需要一种完全不同的数据结构——不是摘要式的 Wiki,而是一个由类型化实体组成的知识图谱:人员、决策、承诺和截止日期作为独立节点,跨对话关联在一起。
Rowboat(GitHub 仓库[1])正是这样一个开源实现,它基于 Karpathy 使用的同样的 Markdown + Obsidian 基础架构,但将其扩展到了工作场景。
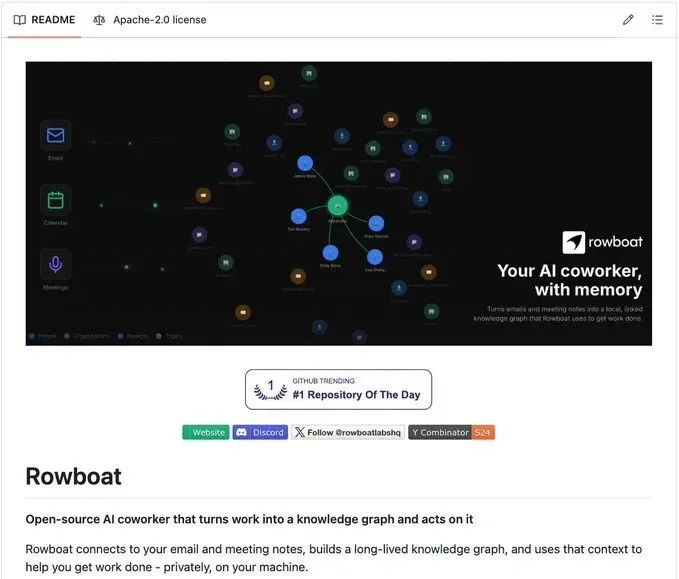
它的工作方式是:从 Gmail、Granola 和 Fireflies 中摄取对话内容,然后不是为每个主题写一个摘要页面,而是将每个决策、承诺和截止日期提取为独立的 Markdown 文件,并带有指向相关人员和项目的反向链接。
这在结构上与 Wiki 有着本质区别:
一个关于"项目 X"的 Wiki 页面只给你一个讨论摘要。 而知识图谱则能告诉你每一个做出的决策、谁做的、承诺了什么、承诺的时间是什么,以及之后是否有任何变动。
接下来,让我们从零开始搭建 Rowboat,看看知识图谱在磁盘上的实际结构,以及图谱上线后能做什么。
搭建
Rowboat 是一个本地桌面应用(支持 Mac、Windows、Linux),完全运行在你自己的机器上,并允许你从 Ollama、LM Studio 或任何托管 API 接入自己的模型。
它将所有数据以纯 Markdown 文件的形式存储在 ~/.rowboat/ 目录下,兼容 Obsidian vault 格式。如果你已经在使用 Obsidian 记笔记,可以直接指向同一个 vault,在浏览自己文件的同时查看 Rowboat 的知识图谱。
如果你不使用 Obsidian,这些 Markdown 文件在任何编辑器中都可以正常阅读。
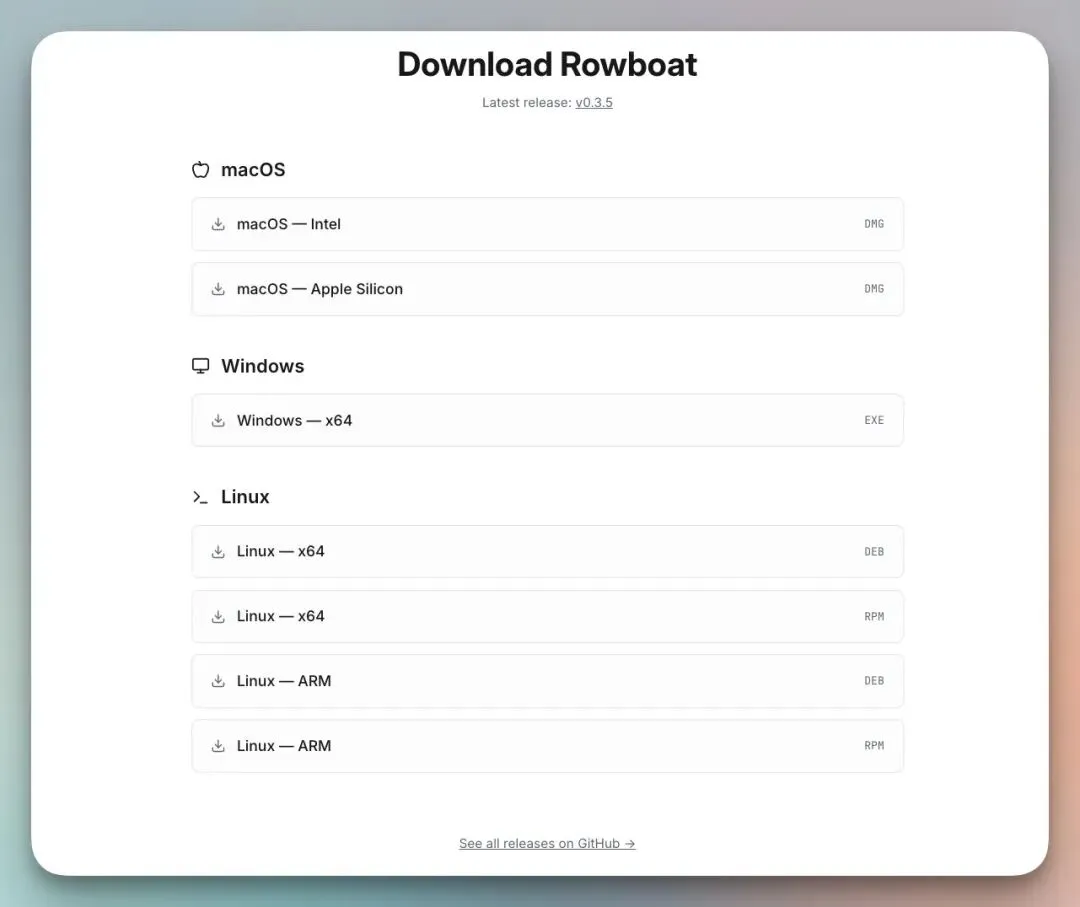
首先,从这里下载应用:rowboatlabs.com/downloads[2]
然后,打开 ~/.rowboat/config/models.json,将其指向你正在运行的模型服务。
对于托管服务商,可以这样配置:
{
"provider": {
"flavor": "openai",
"apiKey": "sk-..."
},
"model": "gpt-4o"
}
Anthropic、Google 和 OpenRouter 使用相同的结构,只需替换上面的 flavor 属性即可。如果你希望推理完全在本地运行,Ollama 也可以:
{
"provider": {
"flavor": "ollama",
"baseURL": "http://localhost:11434"
},
"model": "llama3.2"
}
此外,你也可以直接在 UI 中使用各服务商的 API Key 来设置首选的 LLM 提供商。前往 设置 → 模型:
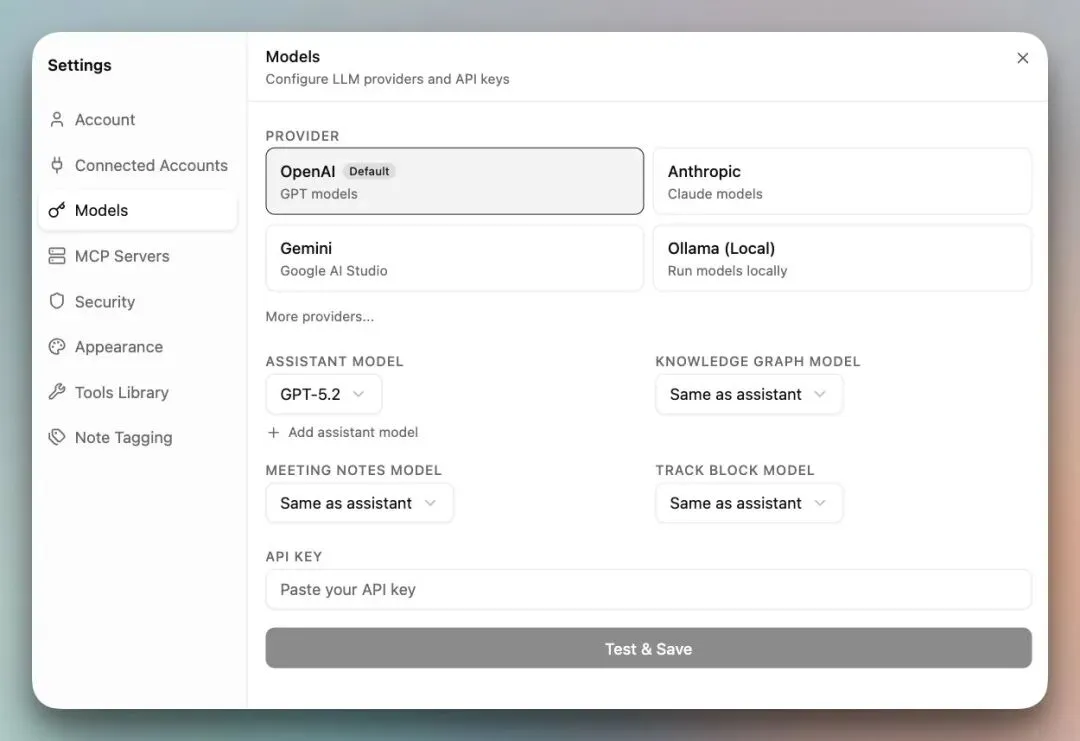
模型连接成功后,Rowboat 会用系统提示词将其包装,使 LLM 能够感知你的知识图谱结构。
模型会了解 knowledge/ 目录的存在,理解实体类型(People、Projects、Organizations、Topics),能够遍历笔记之间的反向链接,并在回复前读取 Today.md 以获取当前上下文。
这本质上是一个工作导向的系统提示词层,叠加在你选择的任何模型之上,使 LLM 作为一个有上下文感知能力的助手运行,而不是一个空白的聊天会话。
接下来,你需要创建自己的 Google Cloud 项目并配置 OAuth 凭据,以便直接从本地机器调用 Gmail、Calendar 和 Drive。
完整的操作指南在 Rowboat GitHub 仓库[3] 中的 google-setup MD 文件里。核心流程如下:
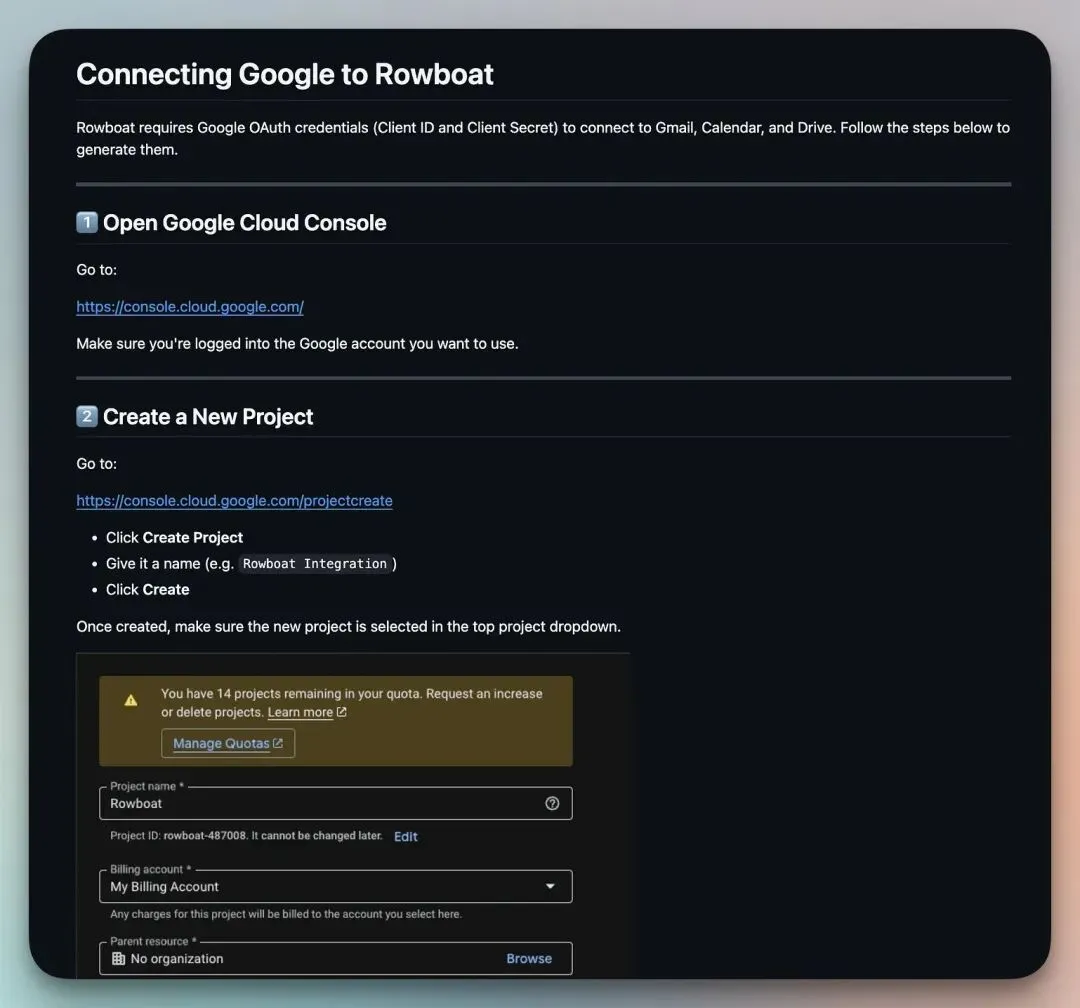
在 console.cloud.google.com 创建一个项目 启用 Gmail、Calendar 和 Drive API 设置 OAuth 同意屏幕(测试模式即可) 将你的邮箱添加为测试用户 创建一个 OAuth Client ID(类型:Web 应用) 将重定向 URI 设置为 http://localhost:8080/oauth/callback 按提示将 Client ID 和 Secret 粘贴到 Rowboat 中
连接成功后,首次同步自动启动,图谱开始构建。
如果你使用 Fireflies 或 Granola,可以在这里添加 API Key:
// ~/.rowboat/config/fireflies.json # Fireflies 会议转录
{
"apiKey": "<your-fireflies-api-key>"
}
// ~/.rowboat/config/granola.json # Granola 会议笔记
{
"apiKey": "<your-granola-api-key>"
}
会议转录内容会自动拉取到 Meetings/ 文件夹中,其中的决策和待办事项会被提取到知识图谱中。
此外,你还可以根据工作流需要添加其他集成:
~/.rowboat/config/deepgram.json # 语音输入和笔记
~/.rowboat/config/elevenlabs.json # 语音输出
~/.rowboat/config/exa-search.json # 通过 Exa 进行网络研究
~/.rowboat/config/composio.json # 外部工具
~/.rowboat/config/mcp.json # 其他 MCP 工具
首次同步完成后,图谱就可以查询了。
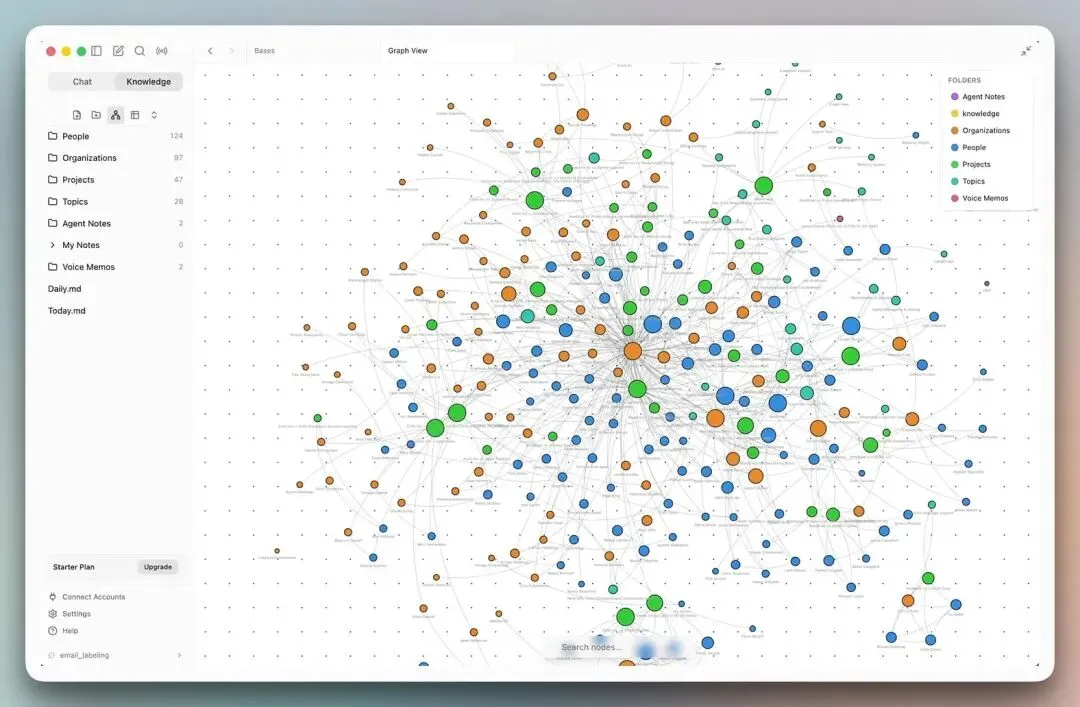
磁盘上的 vault 结构
首次同步后,你的 ~/.rowboat/ 目录就正式上线了。
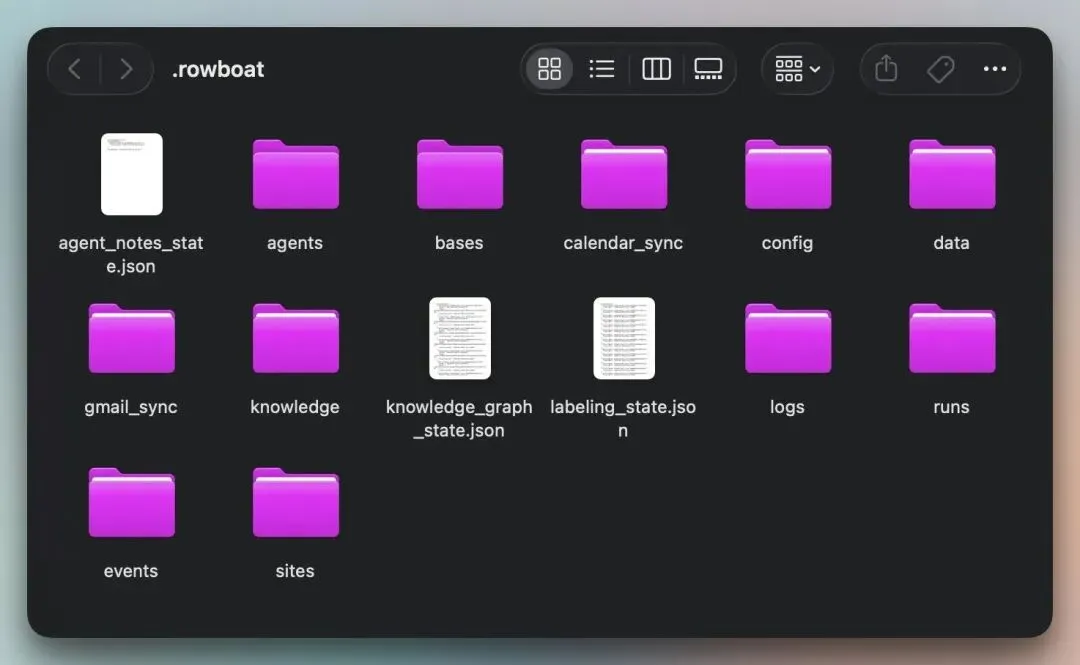
config/ 文件夹包含你所有的 API Key 和模型配置 gmail_sync/ 和 calendar_sync/ 文件夹存储同步数据,在处理成图谱之前的原始数据 events/ 文件夹包含后台 Agent 的活动记录,分为 done/ 和 pending/ 子文件夹 sites/ 文件夹中的内容可通过 http://localhost:3210/sites/ / 访问,并可作为实时 iframe 嵌入到任何笔记中 logs/ 和 runs/ 文件夹包含操作历史和 Agent 运行记录
结构中更有趣的部分在 knowledge/ 目录下。
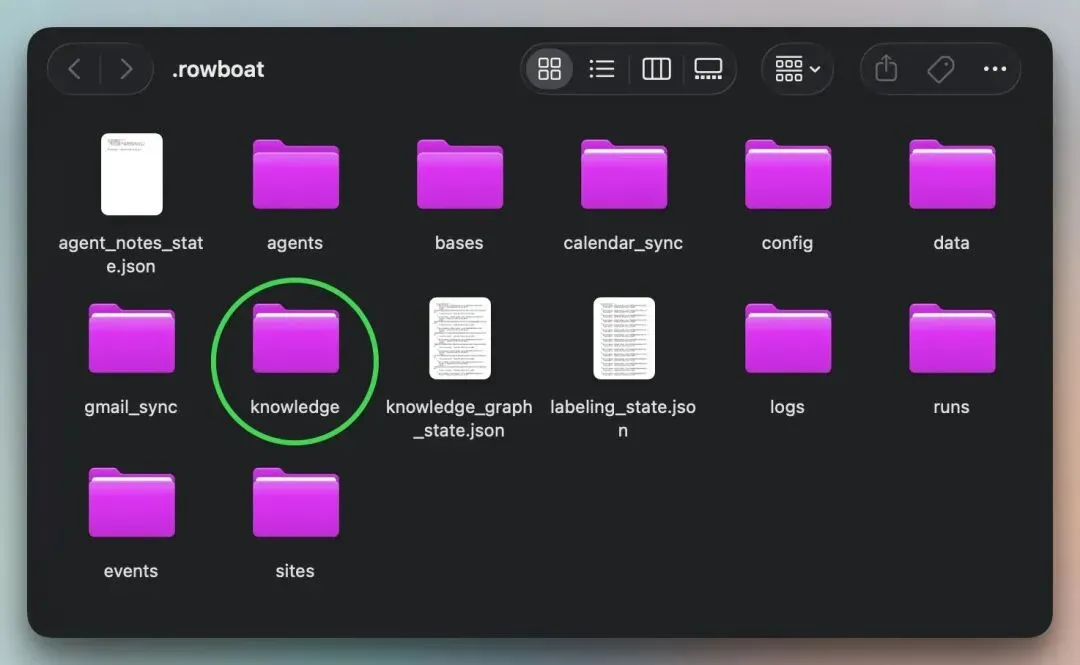
以下是它的内容:
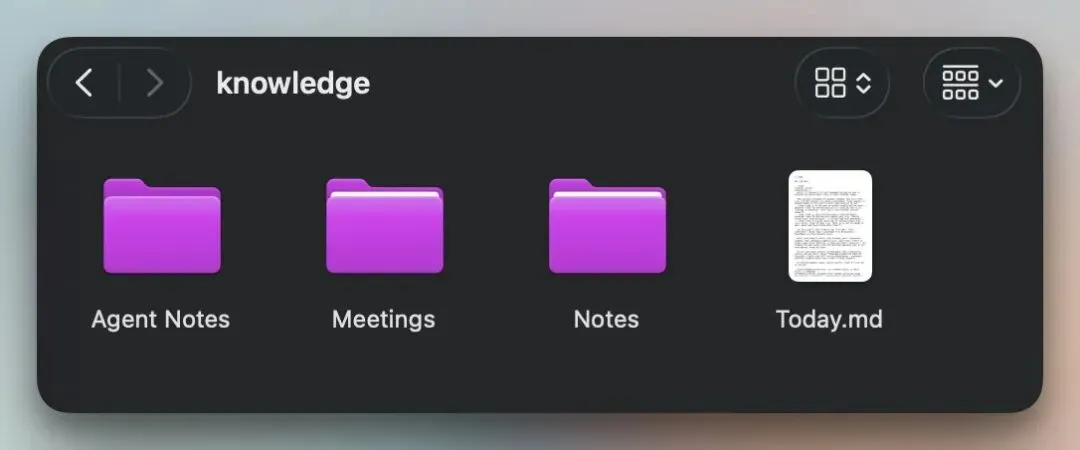
Agent Notes/ 是 Rowboat 的记忆层,根据你的行为和写作模式随时间生成 Meetings/ 包含来自 Fireflies 或 Granola 的已处理转录内容,其中提取了决策和待办事项 Notes/ 用于存放你自己的 Markdown 文件 Today.md 是 Rowboat 在回答任何问题之前首先读取的文件。它将最近的邮件、会议笔记和草稿汇总为一个统一的查询入口
除此之外,还有 People/、Organizations/、Projects/ 和 Topics/ 文件夹。
它们一开始都是空的,随着信息积累逐步填充。Rowboat Agent 只有当来自邮件、会议和决策的证据足够充分时,才会创建实体文件。
这是一个深思熟虑的设计决策——过早地从噪声数据(垃圾邮件发送者、营销邮件)中创建实体会污染图谱。
Rowboat 不会在每次查询时加载整个 vault。它先读取 Today.md,然后只拉取与你请求相关的实体文件。因此,即使图谱增长到数百条笔记,查询成本也保持平稳。
查询图谱
同步完成后,你可以尝试这个实用的首次查询:
帮我准备下午两点和 Sarah Chen 的会议
以下是查询结果:
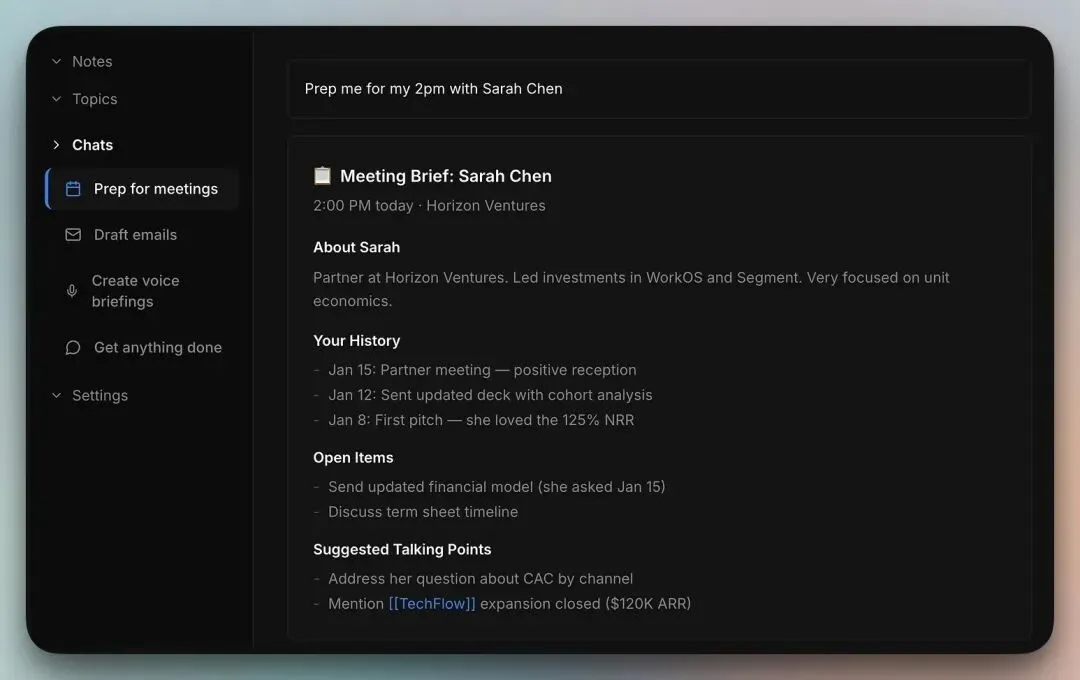
在底层,Rowboat Agent 遍历了 Sarah 的实体节点及其反向链接。
她的职位和公司信息来自邮件签名和会议参与者列表 你们的互动历史从日历事件和邮件线程中重建 未完成事项从过往会议转录中提取 谈话要点来自图谱中的相关实体
摘要中的任何 [[entity]] 引用都是一个实时反向链接,你可以点击进入:
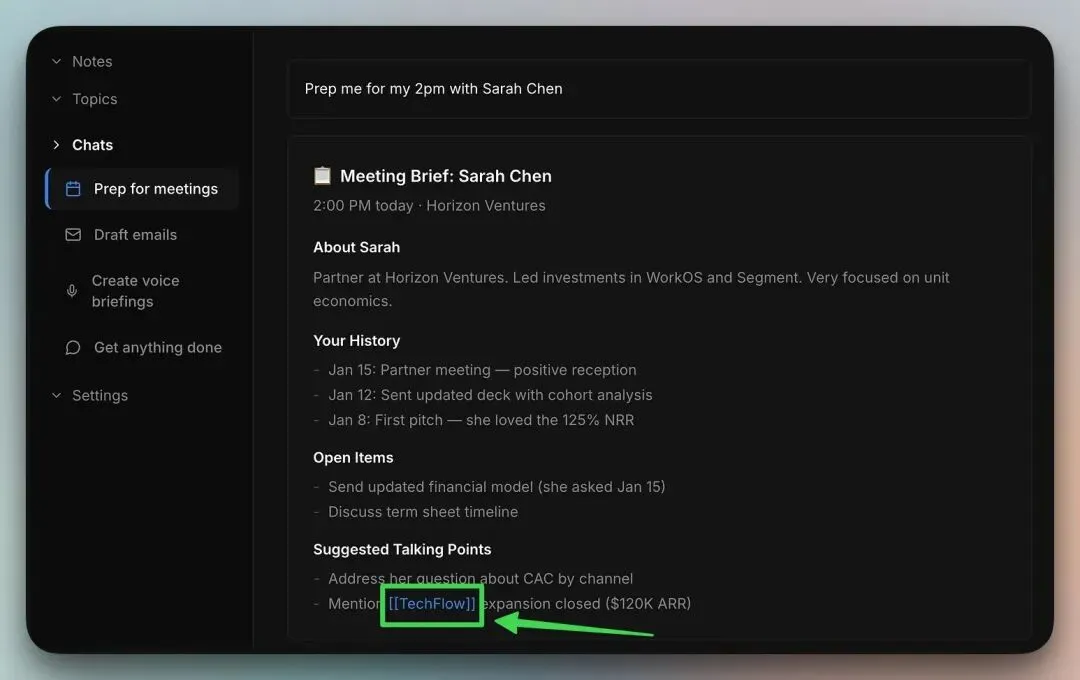
这将展示完整的实体节点,只需一步跳转即可获取任何账户、人员或项目的额外上下文。
再试一个查询:
创建我今天的语音摘要
以下是查询结果:
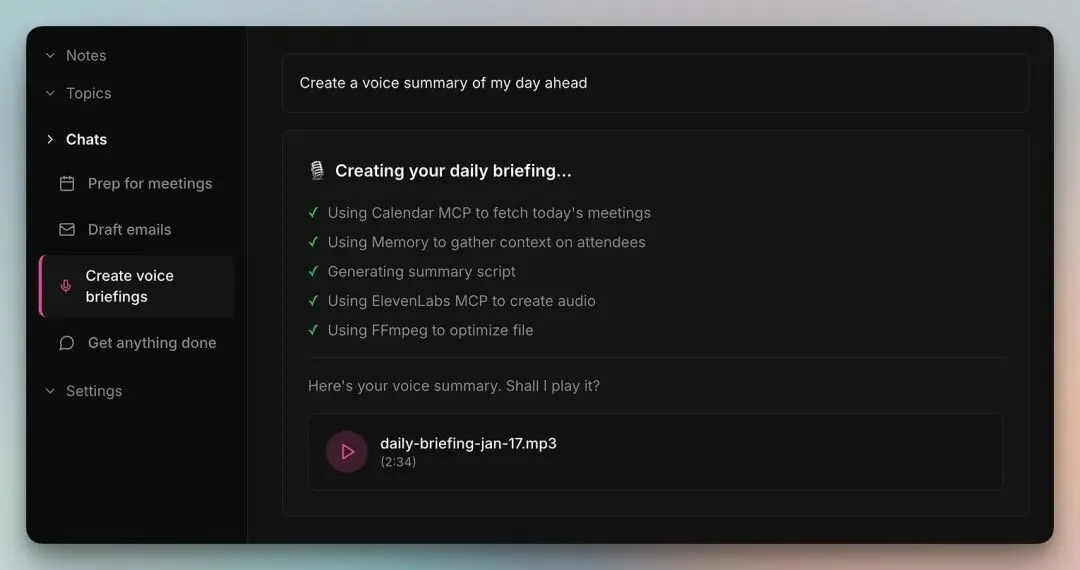
在这种情况下,Agent 从日历中拉取了今天的会议,从图谱中收集了参会者的上下文,基于你的优先事项生成了脚本,并以 MP3 格式返回音频。
这需要上面提到的 ElevenLabs 或 Deepgram 集成来处理音频部分。
对于持续追踪,在任何笔记中标记 @rowboat 就会将其变成一个实时笔记。Rowboat 会在新相关信息从连接的数据源进入时自动保持更新。
例如,如果你正在跨多个对话追踪一笔交易、一个项目或一个客户,这个笔记会自动保持最新,无需手动维护。
最后,你还可以启动按计划独立运行的 Agent。你可以控制运行什么、何时运行,以及什么内容被写回 vault。
知识图谱随时间的演变
正如预期,知识图谱随着每封邮件和每次会议变得更加密集。新信号会附加到已有的实体节点上,而不是创建孤立的文件。
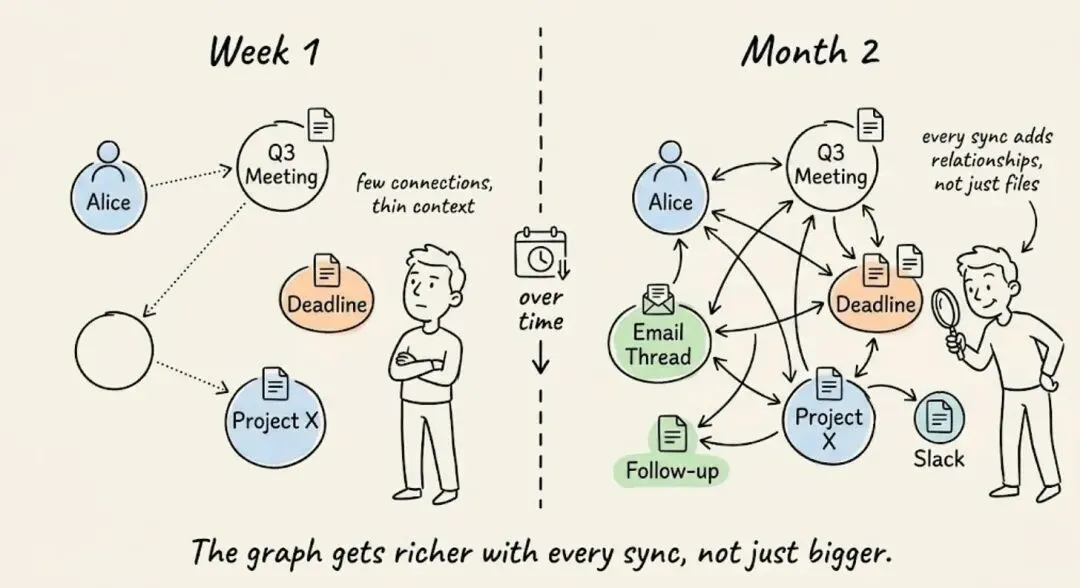
想象一下,Sarah 在三周前参加了一个 B 轮融资介绍会。从第一天起,这个链接就已经存在了。
现在当她发来投资条款书的反馈时,这次更新会作为她活动日志中的一条新记录附加到同一个节点上。
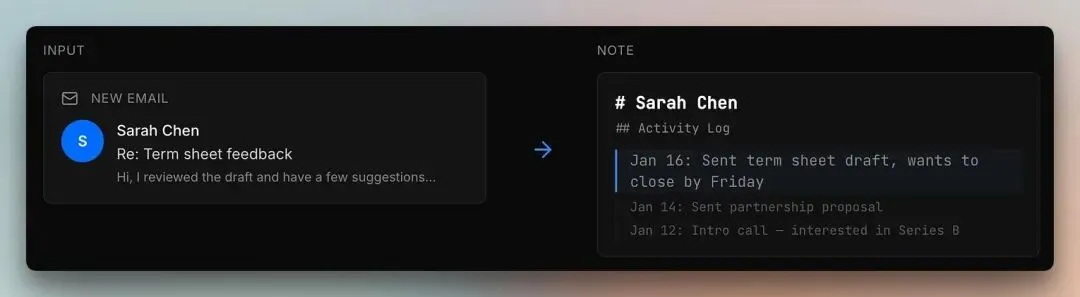
图谱不会创建第二个"Sarah Chen"文件,而是扩展已有的那个。
到了第二个月,当你查询"Sarah 这个季度承诺了什么"时,Agent 会遍历每次互动中的关联上下文,而不是分散在各个收件箱中的独立邮件线程。
如果你在第一周为一个交易设置了实时笔记,它会始终保持最新,因为 Agent 会自动持续地将新的相关上下文拉入其中。
所以你只需设置一次,图谱就会自动维护。
这就是与 Karpathy 的 Wiki 模式在结构上的核心差异。Wiki 将概念编译成页面。知识图谱跨对话追踪状态,而这种状态会随着新互动链接回已有实体而不断累积。
Rowboat 将 Karpathy 模式所描述的复合型知识库,应用到了那些日常实际变化着的上下文中。
它将所有内容以纯 Markdown 格式存储在 ~/.rowboat/ 中,没有任何东西被锁定在专有格式里。
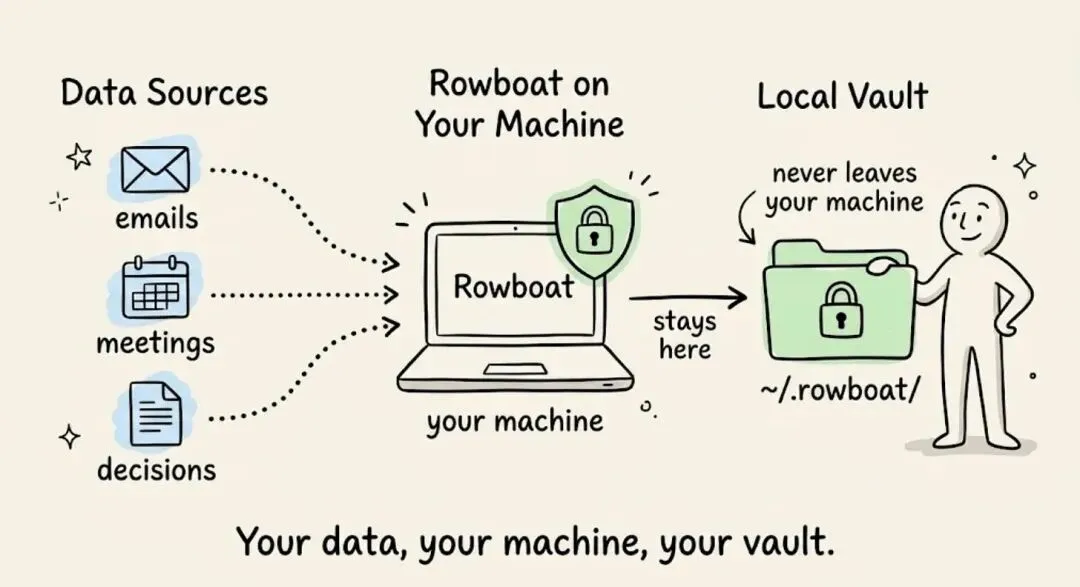
模型调用发送到你在 models.json 中指定的任何位置。
使用 Ollama 时,整个推理管线都在你的硬件上运行。 使用托管 API Key 时,你的提示词直接发送到该提供商,遵循你自己账户的服务条款。
Rowboat 不会代理或拦截模型调用。
Gmail、Calendar 和 Drive 的 OAuth 凭据存储在 ~/.rowboat/config/ 中,直接从你的机器调用 Google API。每个集成都遵循相同的架构——在本地调用,输出写入本地 vault。
仓库采用 Apache-2.0 许可证。
GitHub 仓库在这里(13k+ stars):github.com/rowboatlabs/rowboat[4](别忘了点个 star 🌟)
以上就是全部内容!
如果你喜欢这篇教程:
关注我 → @\_avichawla[5]
每天我都会分享关于 DS、ML、LLM 和 RAG 的教程与见解。
GitHub 仓库: https://github.com/rowboatlabs/rowboat
[2]rowboatlabs.com/downloads: https://rowboatlabs.com/downloads
[3]Rowboat GitHub 仓库: https://github.com/rowboatlabs/rowboat
[4]github.com/rowboatlabs/rowboat: https://github.com/rowboatlabs/rowboat
[5]@_avichawla: https://x.com/@_avichawla
