夜雨聆风
夜雨聆风🔬 5条核心原则 · 6大必备区域 · 3层边界体系 · 来自2500+真实Agent配置文件的经验
你有没有这种感觉?
给AI Agent写个需求说明,写太长了它就懵了,写太短了它又瞎猜。有人说「我可以写一份堪比RFC的spec,但到最后context太大模型就崩了」。
说真的,这话简直是我的心声。
Addy Osmani(Google Chrome团队工程负责人)最近出了一篇深度长文,把他在Claude Code和Gemini CLI上的实战经验浓缩成了5条原则。我读完之后觉得,这可能是目前我见过最完整的「怎么给AI Agent写spec」的框架了。
今天把这篇完整拆给你看。
核心操作|用一个简洁的高层spec启动项目,然后让AI帮你扩展成详细计划。
很多人上来就想把spec写得巨细无遗,然后一股脑喂给Agent。
错。
更聪明的做法是,你先写一个「产品简报」级别的东西,像用户故事一样说清楚Who、What、Why就行,然后让Agent从这个起点生成一份完整的spec。
为什么这样有效?LLM在「给定明确方向后展开细节」这件事上特别擅长,但如果你不给方向,它就会飘。
实操步骤
开一个新session,直接说「你是AI软件工程师,为X项目起草一份详细规格说明,覆盖目标、功能、约束和分步计划」。
保持你的初始prompt高层化,比如「做一个任务管理web应用,有用户账号、数据库、简洁UI」。Agent会回一个结构化的草稿spec,包含概览、功能列表、技术栈建议、数据模型等等。
GitHub的AI团队推广了一种叫Spec-Driven Development的方法论,核心理念是「spec成为共享的真相来源...是随项目演进的活的、可执行的工件」。
💡 在写任何代码之前,先审查和完善AI的spec。确保它跟你的愿景一致,纠正任何幻觉或偏离目标的细节。
用Plan Mode强制「先规划再执行」
Claude Code有个Plan Mode(Shift+Tab),限制Agent只能做只读操作,它可以分析你的代码库、创建详细计划,但不会写任何代码直到你准备好。
工作流长这样👇
- 1. 进入Plan Mode
- 2. 描述你要构建的东西
- 3. 让Agent边探索代码边起草spec
- 4. 让它问你澄清问题
- 5. 让它审查架构、最佳实践、安全风险、测试策略
- 6. 计划完善到没有误解空间后,退出Plan Mode开始执行
这避免了最常见的坑,还没把spec想清楚就跳进代码生成。
把spec当context用
审核通过后,保存为SPEC.md,在需要时把相关片段喂给Agent。很多用strong model的开发者就是这么干的,spec文件在session之间持久化,随时锚定AI。
这就像团队里的PRD一样,每个人(不管是人还是AI)都可以查阅来保持方向一致。
有工程师说过,「先写好文档,模型可能仅凭这个输入就能构建出匹配的实现。」
spec就是那份文档。
📋 原则二 · 像写PRD一样结构化你的Spec
核心操作|把spec当成结构化文档(PRD),有清晰的章节,而不是一堆散乱的笔记。
GitHub分析了超过2500个agent配置文件,发现了一个清晰的模式,最有效的spec覆盖六个核心区域。
拿这个当完整性checklist👇
1. Commands(命令)
把可执行命令放在前面,不只是工具名,而是带flags的完整命令,npm test、pytest -v、npm run build。Agent会反复引用这些。
2. Testing(测试)
怎么跑测试、用什么框架、测试文件在哪里、覆盖率预期是什么。
3. Project Structure(项目结构)
源代码在哪、测试在哪、文档在哪。要明确,「src/放应用代码,tests/放单元测试,docs/放文档。」
4. Code Style(代码风格)
一个真实代码片段展示你的风格,胜过三段描述。包含命名规范、格式规则和好输出的例子。
5. Git Workflow(Git工作流)
分支命名、commit message格式、PR要求。你写清楚了Agent就能跟着走。
6. Boundaries(边界)
Agent绝对不能碰的东西,密钥、vendor目录、生产配置、特定文件夹。「永远不要提交secrets」是研究中最常见的有用约束。
关于tech stack要具体
说「React 18 with TypeScript, Vite, and Tailwind CSS」而不是「React项目」。含糊的spec产出含糊的代码。
用一致的格式
很多开发者在spec中用Markdown标题甚至XML-like标签来划分章节,因为AI模型处理结构化文本比自由散文好得多。
示例结构👇
# Project Spec: My team's tasks app
## Objective
- Build a web app for small teams to manage tasks...
## Tech Stack
- React 18+, TypeScript, Vite, Tailwind CSS
- Node.js/Express backend, PostgreSQL, Prisma ORM
## Commands
- Build: `npm run build`
- Test: `npm test`
- Lint: `npm run lint --fix`
## Project Structure
- `src/` – Application source code
- `tests/` – Unit and integration tests
## Boundaries
- ✅ Always: Run tests before commits
- ⚠️ Ask first: Database schema changes
- 🚫 Never: Commit secrets, edit node_modules/Anthropic的工程师推荐把prompts组织成不同的区段(像<background>、<instructions>、<tools>、<output_format>),给模型强信号告诉它哪些信息是什么角色。
记住,「minimal不一定意味着short」,如果细节重要就不要回避,但保持聚焦。
把spec整合到你的工具链
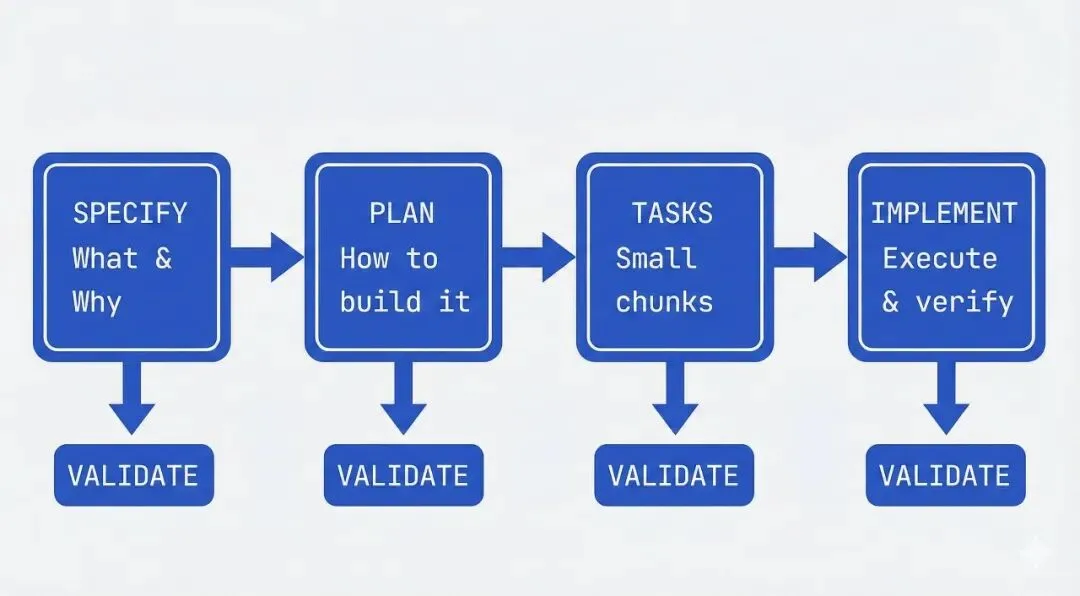
GitHub Spec Kit用一个四阶段门控工作流让spec成为工程流程的中心,
1. Specify(规格化),你描述要构建什么和为什么,AI生成详细规格。关注用户旅程和成功标准,不是技术栈。
2. Plan(计划),现在进入技术层面。你提供desired stack、架构和约束,AI生成技术计划。可以要求多个方案变体来比较。
3. Tasks(任务),AI把spec和plan拆成实际工作项,小块、可审查、每块解决一个具体问题。不是「构建认证」,而是「创建用户注册endpoint,验证email格式」。
4. Implement(实现),Agent逐个(或并行)处理任务。你审查聚焦的变更而不是千行代码dump。
你的角色是在每个阶段验证。spec是否捕获了你想要的?计划是否考虑了约束?有没有AI遗漏的边缘场景?
这种门控工作流防止了Simon Willison所说的「纸牌屋代码」,那种在审视下就崩塌的脆弱AI输出。
考虑agents.md做专门化persona
对GitHub Copilot,你可以创建agents.md文件定义专门化的agent persona,比如@docs-agent做技术写作,@test-agent做QA,@security-agent做代码审查。每个文件都是那个persona的行为、命令和边界的聚焦spec。
为Agent Experience(AX)设计
就像我们为DX设计API一样,考虑为「Agent体验」设计spec。要求干净可解析的格式,OpenAPI schemas、llms.txt文件、明确的type定义。AAIF正在标准化MCP(Model Context Protocol)等协议,遵循这些模式的spec更容易被Agent消费和可靠执行。
🧩 原则三 · 拆成模块化的prompts,而不是一个大prompt
核心操作|分而治之。一次给AI一个聚焦的任务,而不是一个包含所有内容的巨型prompt。
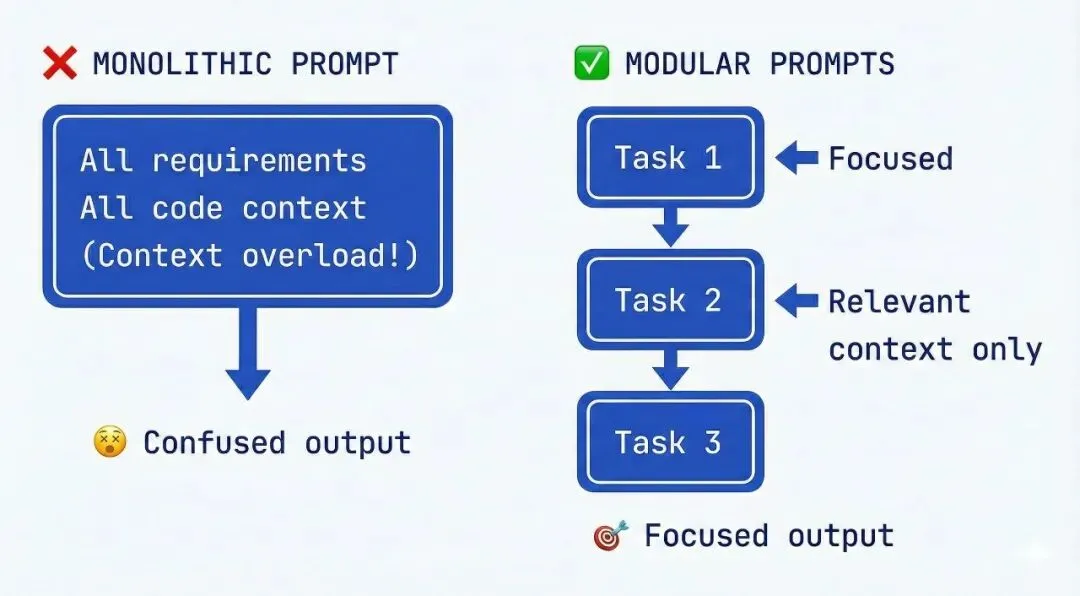
你试过把整个项目(所有需求、所有代码、所有指令)塞进一个prompt吗?
那是灾难的配方。
「指令诅咒」的现实
研究确认了很多开发者的直觉体验,随着你往prompt里堆更多指令或数据,模型对每一条的遵守程度显著下降。
一项研究把这称为「指令诅咒」(Curse of Instructions),显示即使GPT-4和Claude在被要求同时满足很多需求时也会挣扎。实际效果是,如果你给10条详细规则,AI可能遵守前几条然后开始忽略其他的。
更好的策略是迭代聚焦。行业指南建议把复杂需求分解为顺序的、简单的指令。一次聚焦AI在一个子问题上,做完,然后移到下一个。
把spec分成阶段或组件
如果spec文档很长,考虑拆分。比如你可能有「后端API Spec」和「前端UI Spec」。你不需要在AI做后端时总是喂前端spec,反之亦然。
甚至可以创建分离的agents或子进程处理每个部分。比如一个agent做数据库/schema,另一个做API逻辑,另一个做前端。每个只接收spec的相关切片。
💡 不要把认证任务和数据库schema变更混在一个prompt里。每个prompt紧密围绕当前目标。
扩展目录/摘要应对大spec
有个聪明技巧,让Agent构建一个带摘要的扩展目录(Extended TOC)。
其实就是一个「spec摘要」,把每个章节浓缩为几个关键点或关键词,并引用详情位置。比如完整spec有500词的「安全需求」,你可以让Agent总结为「Security: 使用HTTPS,保护API keys,实现输入验证(详见full spec §4.2)」。
通过创建层次化摘要,你得到一个可以留在prompt里的鸟瞰视图,而详细内容只在需要时才提供。这就像一个索引,Agent可以说「啊,有个安全章节我应该看看」,然后你按需提供那个章节。
利用sub-agents或"skills"处理不同spec部分
Anthropic的Claude Code支持定义有自己system prompt和工具的subagents。「每个subagent有特定目的和专业领域,使用自己的context window(与主对话分离),有自定义的system prompt指导行为。」
并行agents提高吞吞
同时运行多个agent实例处理不同任务正在成为「the next big thing」。Simon Willison描述这为「embracing parallel coding agents」,并指出它「surprisingly effective, if mentally exhausting」。
关键是划分任务让agents不会踩到彼此。一个agent写代码,另一个写测试,或者分离的组件并发构建。
| 维度 | 单Agent | 并行/多Agent |
|---|---|---|
| 优势 | 更简单、开销低、易调试 | 更高吞吐、处理复杂依赖、领域专家 |
| 挑战 | 大项目context过载、更慢、单点故障 | 协调开销、潜在冲突、需共享记忆 |
| 适合 | 隔离模块、中小项目、早期原型 | 大代码库、一个写+一个测+一个review |
| 建议 | 用spec摘要、每任务刷新context | 初期限2-3个agent、用MCP共享工具 |
每个prompt聚焦一个任务/章节,
即使不用花哨的多agent设置,你也可以手动强制模块化。比如spec写完后,你的下一步是「Step 1: 实现数据库schema」。只喂Agent数据库章节加全局约束。做完后,「Step 2: 实现认证功能」,喂Auth章节加相关schema。
每个主要任务刷新context,确保模型不携带大量过时或无关信息。
💡 底线:小的、聚焦的context胜过一个巨型prompt。这提升质量并防止AI被「overwhelm」。
🛡️ 原则四 · 内建自检、约束和人类专业知识
核心操作|让spec不仅是todo列表,还是质量控制的指南,不要怕注入你自己的专业知识。
好的spec预见AI可能出错的地方并设置护栏。它也利用你知道的东西(领域知识、边缘场景、坑)让AI不在真空中操作。
把spec想成AI的教练兼裁判,它应该鼓励正确方法并吹哨犯规。

使用三层边界体系,
GitHub对2500+个agent文件的分析发现,最有效的spec使用三层边界系统而不是简单的禁止列表。这给Agent更清晰的指导,
✅ Always do(始终做),
Agent应该不问就执行的动作。
- • 「始终在commit前跑测试」
- • 「始终遵循style guide的命名规范」
- • 「始终把错误log到监控服务」
⚠️ Ask first(先问),
需要人类批准的动作。
- • 「修改数据库schema前先问」
- • 「添加新依赖前先问」
- • 「改CI/CD配置前先问」
🚫 Never do(绝不做),
硬停止。
- • 「绝不提交secrets或API keys」
- • 「绝不编辑node_modules/或vendor/」
- • 「绝不在没有明确批准的情况下删除failing test」
这比扁平的规则列表更有细微差别。Agent可以自信地处理「Always」项,标记「Ask first」项等待review,在「Never」项上硬停止。
鼓励自我验证,
一个强力模式是让Agent根据spec自动验证自己的工作。在prompt层面,你可以指示AI double-check,
「实现后,把结果与spec对比并确认所有需求都已满足。列出任何未被处理的spec项。」
这推动LLM反思自己的输出与spec的关系,捕获遗漏。
LLM-as-a-Judge做主观检查,
对于难以自动测试的标准(代码风格、可读性、架构模式遵守),考虑用「LLM-as-a-Judge」。用第二个agent(或单独prompt)根据spec的质量准则审查第一个agent的输出。
一致性测试,
Simon Willison主张构建conformance suites,语言无关的测试(通常基于YAML),任何实现都必须通过。这像合约一样。在spec的Success章节包含这些(比如「必须通过conformance/api-tests.yaml中的所有用例」)。
把你的领域知识注入spec,
spec应该反映只有有经验的开发者才知道的洞见。比如你知道products和categories是多对多关系,明确说出来(不要假设AI会推断)。如果某个库有已知的坑,提到要避免的陷阱。
把你的mentorship倒进spec。spec可以包含像「如果用library X,注意version Y的内存泄漏问题(使用workaround Z)」这样的建议。
这就是把一个平庸的AI输出变成真正健壮的解决方案的东西,因为你把AI从常见陷阱中引开了。
简单任务保持简约,
你的专业知识之一是知道什么时候保持简单。对相对简单、隔离的任务,过度承载的spec实际上可能造成更多困惑。
经验法则,调整spec详细度以匹配任务复杂度。不要对难问题under-spec(Agent会挣扎或跑偏),但也不要对trivial问题over-spec。
你始终是loop中的exec,
spec赋能Agent,但你仍然是最终质量过滤器。Simon Willison幽默地把跟AI Agent工作比作「一种非常奇怪的管理形式」,甚至「从coding agent那里获得好结果,感觉不舒服地接近管理一个人类实习生」。
你需要提供清晰指令(spec)、确保他们有必要的context、给可操作的反馈。
🔄 原则五 · 测试、迭代、演进spec(并用对工具)
核心操作|把spec写作和agent构建视为迭代循环,早测试、收集反馈、精炼spec、利用工具自动化检查。
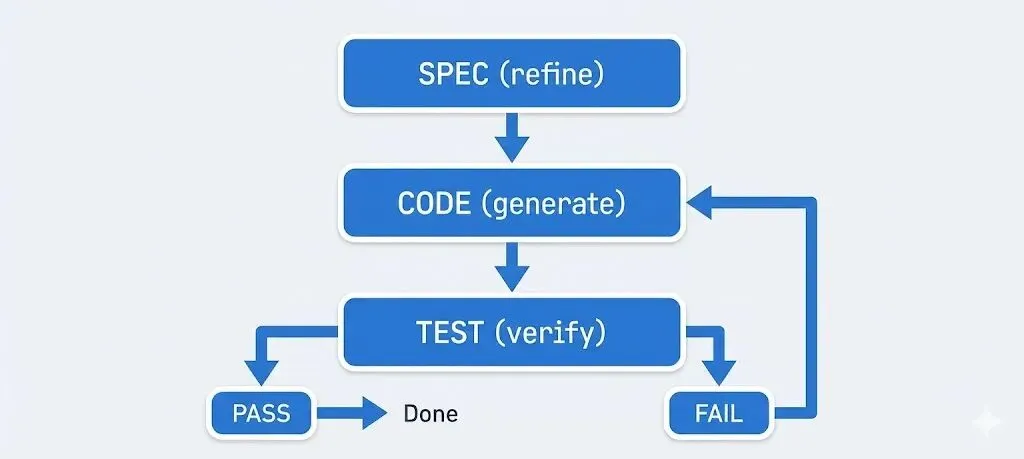
初始spec不是终点,是循环的开始。最好的结果来自持续验证Agent的工作与spec的对应,并据此调整。
持续测试,
不要等到最后才看Agent是否满足了spec。每个主要里程碑甚至每个函数后,跑测试或至少做快速手动检查。如果有东西失败了,在继续之前更新spec或prompt。
自动测试在这里闪闪发光,如果你提供了测试,让Agent跑。结果(失败)可以反馈到下一个prompt,告诉Agent「你的输出在X、Y、Z上没满足spec,修复它」。
这种agentic loop(code → test → fix → repeat)极其强大,是Claude Code和Copilot Labs处理大型任务的演进方向。
始终定义「完成」的标准是什么(通过测试或标准)并检查它。
迭代spec本身,
如果你发现spec不完整或不清晰,更新spec文档。然后显式re-sync Agent,「我已如下更新了spec...根据更新后的spec,调整计划或重构代码。」
这样spec保持single source of truth。这就像我们在正常开发中处理需求变更一样,只是这次你也是你AI Agent的产品经理。
利用context管理和记忆工具,
有一个不断增长的工具生态帮助管理AI Agent的context和知识,
- • RAG(检索增强生成),Agent可以从知识库(向量数据库)即时拉取相关数据块。如果spec很大,可以嵌入章节让Agent按需检索最相关的部分。
- • MCP(Model Context Protocol),自动化根据当前任务给模型喂正确context。
- • Context7等工具,根据你的工作内容自动抓取相关的context片段。
并行化要小心,
如果你运行多个agent实例并行处理不同任务,确保任务真正独立或清晰分离以避免冲突。不要让两个agents同时写同一个文件。
开始时最多2-3个agents来保持可管理性。
版本控制和spec锁定,
用Git跟踪Agent做了什么。好的版本控制习惯在AI辅助工作中更加重要。把spec文件本身commit到repo。Agent甚至可以用git diff或blame来理解变更。
通过把spec放在repo里,你允许你和AI跟踪演进。
成本和速度考虑,
用大模型和长context可能又慢又贵。实际建议,
- • 用更便宜/快速的模型做初始草稿或重复工作
- • 把最capable(最贵)的模型保留给最终输出或复杂推理
- • 控制context大小,如果5k token够用就不要喂20k
监控和log一切,
在复杂agent工作流中,logging agent的行为和输出是essential。检查logs看Agent是否偏离或遇到错误。审查这些logs可以高亮spec或instructions可能被误解的地方。
⚠️ 避开常见陷阱
GitHub对2500+个agent文件的研究揭示了一个stark的分界,「大多数agent文件失败是因为太模糊。」
以下是要避免的错误,
模糊的prompts,「Build me something cool」给Agent没有锚点。「你是一个为React组件写测试的测试工程师,遵循这些示例,永远不修改源代码」才有效。
过长context不做摘要,往prompt里dump 50页文档然后期望模型搞定,很少有用。用层次化摘要或RAG只表面化相关内容。Context长度不能替代context质量。
跳过人类review,Simon Willison有个个人规则「我不会commit我无法向别人解释的代码」。仅因为Agent产出了通过测试的东西不意味着它正确、安全或可维护。
把vibe coding和生产工程混淆,用AI快速原型验证想法很棒。但把那个代码直接推到生产而不经过严格spec、测试和review,是在找麻烦。
忽略「致命三属性」,Simon Willison警告三个让AI agents危险的属性,速度(比你能review的快)、非确定性(同输入不同输出)、成本(鼓励偷工减料)。你的spec和review流程必须应对这三个。
遗漏六大核心区域,如果你的spec没覆盖commands、testing、project structure、code style、git workflow和boundaries,你可能遗漏了Agent需要的东西。
🛠️ 实战教程 · 手把手教你从零写一份Agent Spec
光讲原则不够,我给你一个完整的实操流程,跟着走一遍你就会了。
场景假设,你要用AI Agent帮你构建一个「团队任务管理Web应用」。
Step 1,写初始简报(3分钟搞定)
打开一个新的AI对话(Claude Code / Copilot / Cursor都行),直接说👇
你是一个资深全栈工程师。
我需要构建一个团队任务管理Web应用,核心功能包含,
- 用户注册登录
- 创建/分配/跟踪任务
- 团队面板展示进度
- 简洁美观的UI
请为这个项目起草一份详细的技术规格说明(Spec),
覆盖目标、功能清单、技术约束、数据模型和分步计划。关键点,你只需要说清楚Who/What/Why,不需要写实现细节。
Agent会回你一份结构化的草稿,通常包含目标概述、功能列表、建议tech stack、数据模型等。
Step 2,审查并完善Spec(10分钟)
拿到草稿后,逐条过一遍,重点审查,
- • ❌ Agent是否加了你不需要的功能?(删掉)
- • ❌ 是否有幻觉内容?(比如推荐了不存在的库版本)
- • ✅ 是否覆盖了你知道的边缘场景?(补充进去)
然后把你的领域知识注入,比如,
补充约束,
- 数据库用PostgreSQL(团队已有运维经验)
- 认证用JWT + refresh token,不要session
- products和categories是多对多关系,需要中间表
- 前端必须用React 18 + TypeScript + Tailwind CSS
- 禁止使用any类型Step 3,创建正式Spec文件
审核完成后,让Agent生成一份标准格式的SPEC.md,
# Project Spec,TeamTask App
## Objective
为5-20人小团队提供轻量级任务管理...
## Tech Stack
- Frontend,React 18, TypeScript, Vite, Tailwind CSS
- Backend,Node.js 20, Express, Prisma ORM
- Database,PostgreSQL 15
- Auth,JWT + bcrypt
## Commands
- Dev,`npm run dev`
- Build,`npm run build`
- Test,`npm test -- --coverage`
- Lint,`npm run lint --fix`
- DB migrate,`npx prisma migrate dev`
## Project Structure
- `src/client/` - React前端
- `src/server/` - Express后端
- `src/shared/` - 共享类型定义
- `tests/` - 单元测试和集成测试
- `prisma/` - 数据库Schema和迁移
## Code Style
- 使用ESLint + Prettier
- 函数式组件 + hooks
- 变量命名,camelCase
- 类型命名,PascalCase
- 禁止any,必须显式类型
## Git Workflow
- 分支,feature/xxx, fix/xxx, refactor/xxx
- Commit,conventional commits格式
- PR必须通过CI才能merge
## Boundaries
- ✅ Always,跑完测试再commit
- ✅ Always,新endpoint必须有对应测试
- ⚠️ Ask first,修改数据库schema
- ⚠️ Ask first,添加新npm依赖
- 🚫 Never,提交.env文件
- 🚫 Never,编辑node_modules/
- 🚫 Never,在代码中硬编码密钥保存为repo根目录的SPEC.md,后续每次开新session都先喂这个文件。
Step 4,分阶段执行(核心技巧)
不要把整个Spec一股脑甩给Agent说「开始干吧」。
正确做法,
第一轮prompt,
「根据SPEC.md的Database章节,实现Prisma schema,
包含User、Team、Task三个model和它们的关系。
完成后跑 npx prisma migrate dev 验证。」
第二轮prompt,
「根据SPEC.md的Auth章节,实现JWT认证模块,
包含register、login、refresh三个endpoint。
必须通过tests/auth.test.ts中的所有用例。」
第三轮prompt,
「根据SPEC.md的Frontend章节,实现任务面板UI,
使用React + Tailwind,从/api/tasks获取数据。
确保响应式布局,移动端可用。」每轮只喂Spec的相关切片 + 全局约束。做完一块验证一块。
Step 5,自检回路(让Agent自己QA)
每个阶段完成后,加一句,
请把你的实现与SPEC.md对照,逐项确认是否满足所有需求。
列出任何未被处理的spec项,以及你做了但spec未提及的额外决策。这会触发Agent的「反思」能力,帮你抓漏。
Step 6,迭代更新Spec
开发过程中你会发现新需求或spec不清楚的地方。直接更新SPEC.md,然后告诉Agent,
我更新了SPEC.md的Boundaries章节,新增了「Ask first,修改API响应格式」。
请根据更新后的spec检查当前实现是否有冲突。Spec是活文档,跟代码一起迭代。
完整工作流一图流
[写简报] → [AI生成草稿Spec] → [人工审查+注入专业知识]
↓
[保存SPEC.md] → [分阶段喂给Agent] → [每阶段自检]
↓
[发现问题] → [更新Spec] → [Re-sync Agent] → [继续]💡 整个流程的核心就一句话,你是PM,Agent是执行者,Spec是你们之间的合约。
实测效果对比
我自己在Copilot CLI上试过这套方法,对比如下,
| 无Spec(直接聊) | 有Spec(结构化) | |
|---|---|---|
| 第一次输出质量 | 50-60分 | 80-90分 |
| 需要人工修正次数 | 5-8次 | 1-2次 |
| 代码风格一致性 | 随机 | 高度一致 |
| 边缘场景覆盖 | 经常漏 | 基本覆盖 |
| 跨session连续性 | 每次重新解释 | 喂Spec即可恢复 |
差距是肉眼可见的。
🎯 我的判断
这篇文章的价值在哪?
坦率的讲,市面上讲「怎么跟AI协作」的文章很多,但大部分停留在「prompt engineering」层面。Addy这篇把它升级到了工程管理层面。
他的核心洞见是这样的👇
💡 给AI Agent写spec,压根不是在写「技术文档」,而是在「管理一个能力很强但容易走神的实习生」。你需要提供明确方向、划定边界、持续检查、不断修正。
你想想看,这跟带一个刚毕业的工程师有什么区别?
区别在于这个「实习生」,
- • 不会累
- • 同时可以开好几个副本
- • 会以惊人的速度产出(但同样惊人的速度犯错)
- • 不会因为你否定它的方案而不高兴
所以,好的spec就是你的管理工具。
回到实操这块,如果你只记住一件事,就是这个,
先Plan、再Spec、最后Execute。
不要跳步。
以上,既然看到这里了,说明你对AI Agent的工程化实践真的很上心。这条路是对的。AI不会替代你,但会让你管理「一支不知疲倦的数字工程团队」。而管理的核心,就是一份好的Spec。