 夜雨聆风
夜雨聆风前言
上一篇我们聊了纯JS方案,216万点12秒算完,说实话已经超出预期了。但问题来了——有显卡的电脑能不能用GPU加速?
答案是:能,而且快到离谱。
今天这篇,就来讲讲WebGPU模式的表现。先预告一下结果——独显RTX 2060跑216万点,1.79秒。核显跑463万点,39秒。对比上一篇的JS方案,这简直是质的飞跃。
一、WebGPU是什么?
先解释一下WebGPU。它是浏览器访问GPU的新接口,比WebGL更直接,能让GPU真正干"计算"的活,而不是只渲染画面。
核心优势:Compute Shader。每个地形点分配一个GPU线程,216万个点同时找最近的电线,而不是排队一个个算。
硬件要求:很多人以为必须有独显,其实核显也能用。实测表明,i9-13900H的核显跑WebGPU完全没问题,性能介于独显GPU和纯JS之间。
浏览器兼容性:
二、测试环境:这次有独显了
上一篇用的是两台电脑对比CPU差异,这次重点看GPU差异。
| RTX 2060独显 | |||
| 核显 |
重点看配置1的独显表现,同时也会展示配置2核显的数据。
数据集还是两档:
三、震撼对比:GPU直接碾压
先看50-51数据集(216万地形点):
| GPU独显 | 1.79秒 | |
| GPU核显 | 9.64秒 | |
结论:独显GPU比C#桌面软件快9倍,比JS快19倍。核显GPU比JS略快,但差距不大。
再看11-12数据集(463万地形点):
| GPU独显 | 6.57秒 | |
| GPU核显 | 39秒 | |
结论:独显GPU比C#桌面软件快11倍,比JS快22倍。
下面是GPU模式计算后的效果:
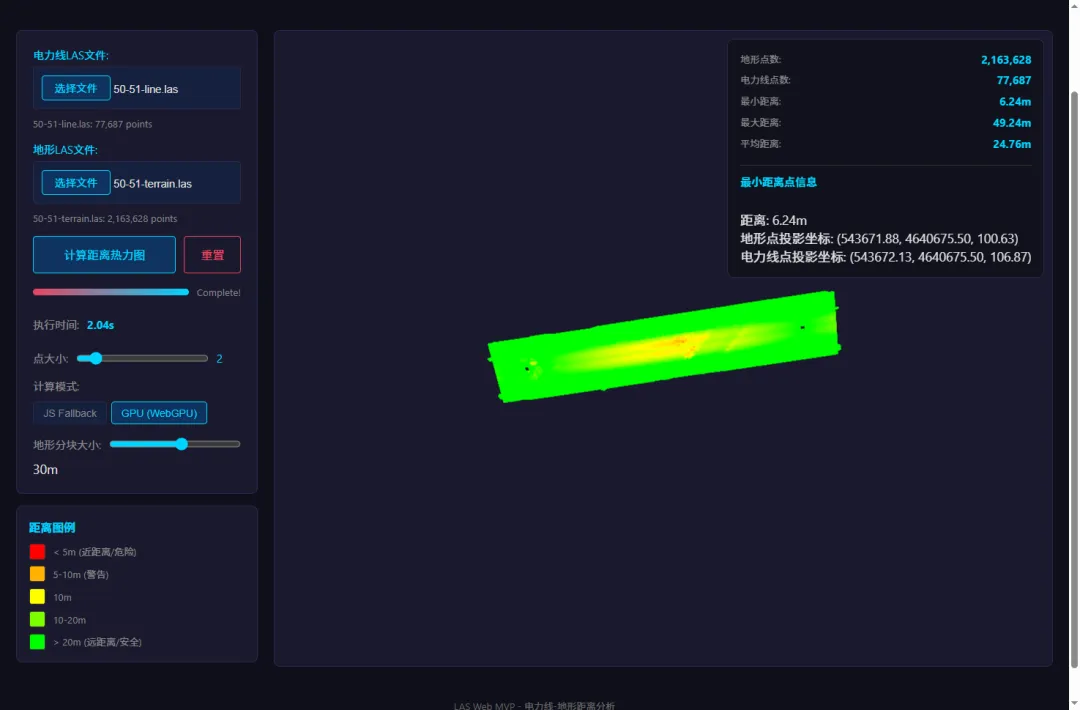
50-51 GPU计算后:
11-12 GPU计算后:
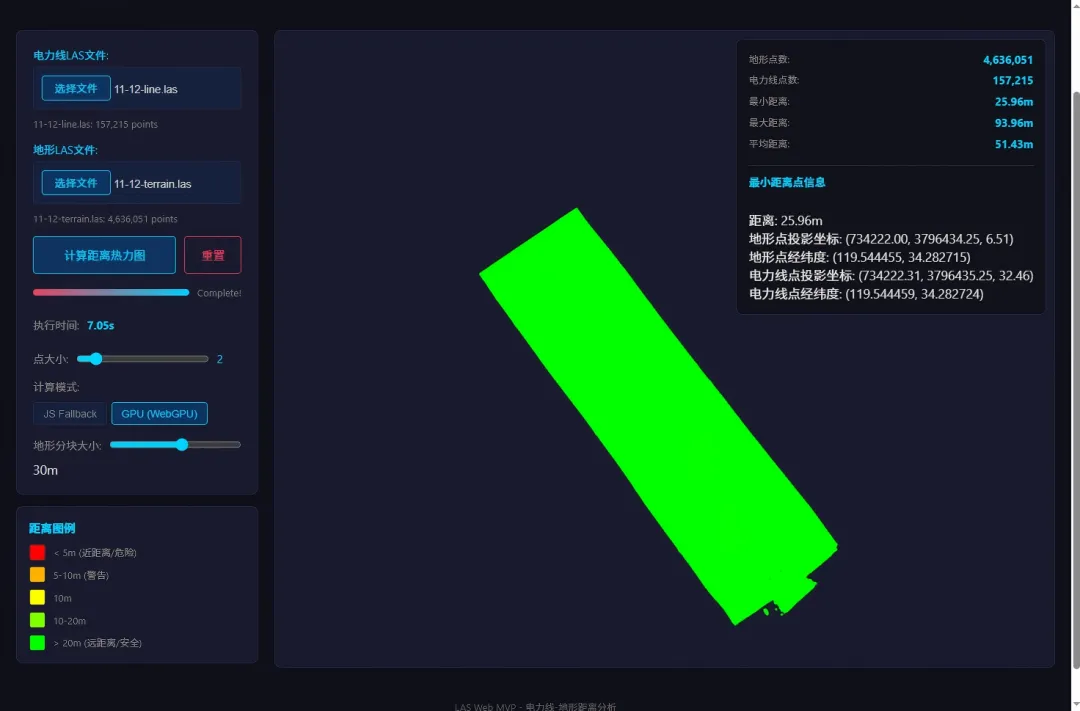
热力图颜色一目了然,红色区域就是危险点——树离电线太近了。
四、精度验证:算得快,也算得准
快归快,精度能不能保证?直接对比三种方案的最小距离:
| 6.241m | |||
| 25.964m |
三种方案结果几乎完全一致,差异在小数点后三位以内,完全在浮点精度范围内。
这说明GPU模式不是"快而粗糙",而是"快且精确"。算法逻辑一样,只是计算方式从CPU换到了GPU。
五、GPU是怎么做到的?
5.1 并行计算:大家同时干活
想象一下,你要在216万个地形点里,每个点找出最近的电线点。JS方案是派12个Worker轮流干,每个Worker处理一小块。GPU方案不一样——每个地形点派一个"小工人",216万个工人同时开工。
当然,GPU不能真的开216万个线程,它把工人分成小组,每组256人,叫一个"workgroup"。50-51数据集分了8452个小组,11-12分了18110个小组,全部同时启动,瞬间算完。
5.2 数据搬运:电线点搬到GPU"仓库"
GPU有自己的"仓库"(显存),计算前要把数据搬进去:
电线点坐标(77,687个点,约93KB) 地形点坐标(216万个点,约26MB) 八叉树结构(约692KB)
搬进去之后,GPU就可以直接访问,不用每次都问CPU要数据。
5.3 结果回收:一次性拉回来
算完之后,GPU把216万个距离值塞进输出缓冲区,一次性复制回CPU内存。整个过程就结束了。
下面是完整的流程图:

六、看看日志:GPU到底干了什么
直接看浏览器日志,GPU计算过程一目了然:
50-51数据集日志(简化版):
GPU: 2163628 terrain points, 77687 powerline points, chunkSize=30mGPU: Buffers uploaded: {nodes: 692800, points: 932244, terrain: 25963536}GPU: Dispatching 8452 workgroups for 2163628 pointsGPU: Compute completed, reading buffer...GPU: Read 2163628 distance valuesGPU: Min=6.24m, Max=49.24mGPU Total compute time: 1.79s11-12数据集日志(简化版):
GPU: 4636051 terrain points, 157215 powerline points, chunkSize=30mGPU: Buffers uploaded: {nodes: 692800, points: 1886580, terrain: 55632612}GPU: Dispatching 18110 workgroups for 4636051 pointsGPU: Compute completed, reading buffer...GPU: Read 4636051 distance valuesGPU: Min=25.96m, Max=93.96mGPU Total compute time: 6.57s关键数字解读:
- workgroups数量
:正好是地形点数/256,向上取整 - Buffer大小
:terrain buffer约26MB/56MB,决定了GPU显存占用 - Min/Max
:最小距离和最大距离,用于热力图颜色映射
七、适用规模:多大数据量合适?
这是个实际问题。不同方案能处理的数据规模不一样:
| <200万点 | ||
| 400万+点 | ||
| 上限未知 |
实际建议:
八、独显 vs 核显 vs JS:到底选哪个?
总结一张表:
| GPU独显 | ||
| GPU核显 | ||
| JS Fallback | ||
| JS Fallback |
最佳实践:代码自动检测WebGPU支持,能用GPU就用GPU,不支持就fallback到JS。
坦诚说几个限制:
当前实现是brute-force:暴力遍历所有电线点找最近的。完整八叉树遍历shader已经写好,但还没集成。集成后预计更快,<0.5秒应该能搞定。
显存限制:GPU显存决定了能处理的最大数据量。RTX 2060是6GB显存,理论上能处理千万级点云,但还没实测验证。
浏览器兼容:Safari暂不支持WebGPU,Firefox需要手动开flag。Chrome/Edge 113+没问题。
核显性能中规中矩:实测核显比JS快了很多,比独显慢一些,性能较之JS提升多。
写在最后
做完WebGPU方案后,说实话有点震撼——浏览器里的GPU计算,居然比C#桌面软件还快。这让"纯前端"的意义完全不同了。
上一篇说"纯前端不是万能的,但在很多场景下已经足够好了"。现在可以改一下——纯前端加上GPU,在很多场景下已经比桌面软件更好了。
当然,GPU方案还有优化空间。八叉树shader集成后,预计能到<0.5秒,那才是真正的"秒杀"。后续有机会再更新。
有问题欢迎留言讨论,下一篇准备聊聊DBSCAN聚类分析——怎么在点云里自动找出危险点簇。敬请期待...
