 夜雨聆风
夜雨聆风
2026年5月5日,高盛发布了一份重磅研究报告,标题为《Decoding the Agentic Economy:The Coming Inflection in AI Usage and Margins 解码Agent经济:AI使用量与利润率的即将拐点》。
这份报告试图回答一个市场最关心的问题:AI的大规模基础设施投入,究竟什么时候能开始赚钱?
答案可能比大多数人预想的更近。
核心判断:Token经济学正在迎来拐点
过去两年,市场对AI的主流叙事是烧钱。更多的推理负载意味着更多的加速芯片、更大的电力消耗,以及更高的资本支出。
但高盛在这份报告中指出,这个逻辑正在发生根本性变化。
关键在于两条曲线的走势分化。
一方面,主流大模型的Token定价在经历了长期的快速下降后,已经开始趋于稳定,部分场景甚至出现价格上调。
另一方面,基于英伟达、AMD、谷歌TPU和Trainium等芯片平台的底层算力成本,仍在以每年60%-70%的速度持续下降。
当价格企稳而成本继续下降,一个简单但意义重大的经济学结论浮出水面:Token的边际利润率正在改善。
高盛预计,这一正向的毛利率拐点很可能在2026年上半年内出现。
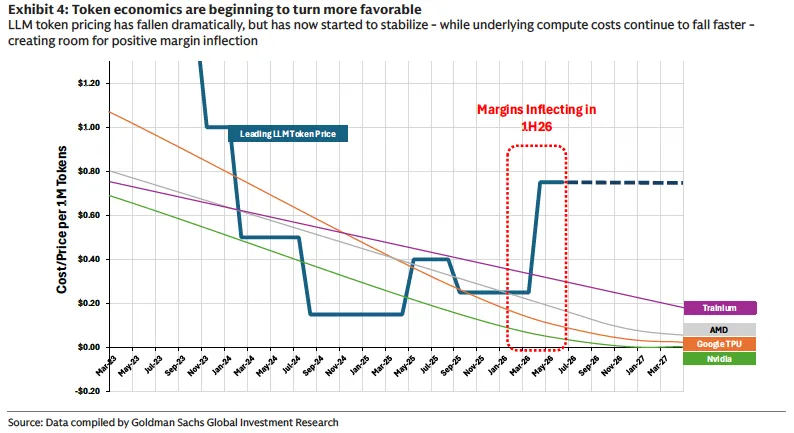
这意味着接下来AI使用量的爆发式增长,不再只是一个收入故事,更是一个利润故事。
超大规模云厂商和模型提供商的经济模型正在从推理亏损走向推理获利,而这将使整个行业的资本支出变得更加可持续。
Agent:不是更好的聊天机器人,而是全新的使用范式
报告的核心研究对象是Agentic AI(智能体AI)。
与传统的聊天机器人不同,Agent不只是回答问题,而是能够自主地规划、执行、监控和迭代完成复杂任务。
高盛将其分为两大类:消费级Agent和企业级Agent,并分别做了深入的量化分析。
消费级Agent:从“问一句答一句”到“永远在线”
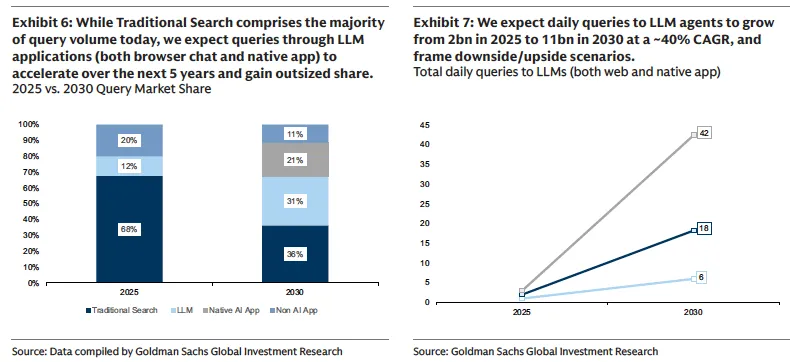
今天大多数消费者使用AI的方式仍然是对话式的,也就是提一个问题,得到一个回答,然后关闭窗口。
高盛的数据显示,2025年平均每次AI查询消耗约1,715个Token,大致相当于3-5分钟的对话。
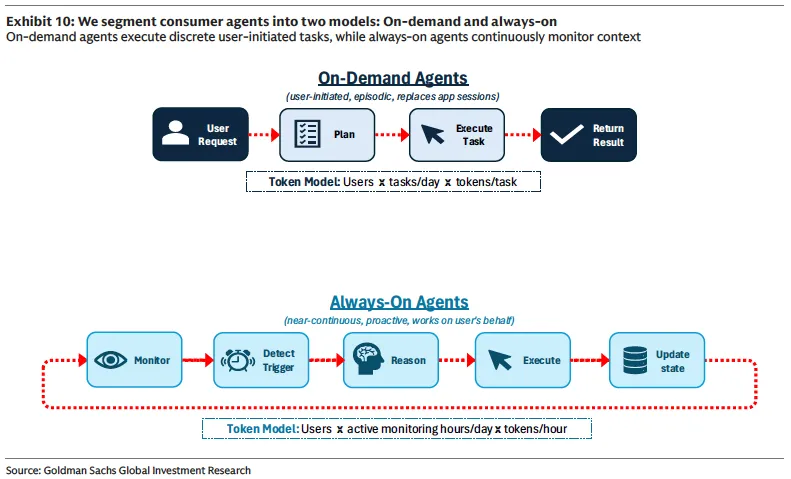
但这种使用模式正在发生根本性转变。高盛将消费级Agent分为两种模型:
按需型Agent(On-Demand):用户主动发起任务,Agent负责规划和执行。例如,用户说“帮我订一张下周去东京的机票”,Agent随即进行航班搜索、价格比较、行程组合、可行性验证等一系列操作。
高盛构建的模拟旅行预订Agent显示,即使是一次简单的旅行规划,也需要经过意图解析、缺失信息补充、多轮搜索筛选、用户反馈整合、预订前验证等十多个步骤,Token消耗量远超一次普通对话。
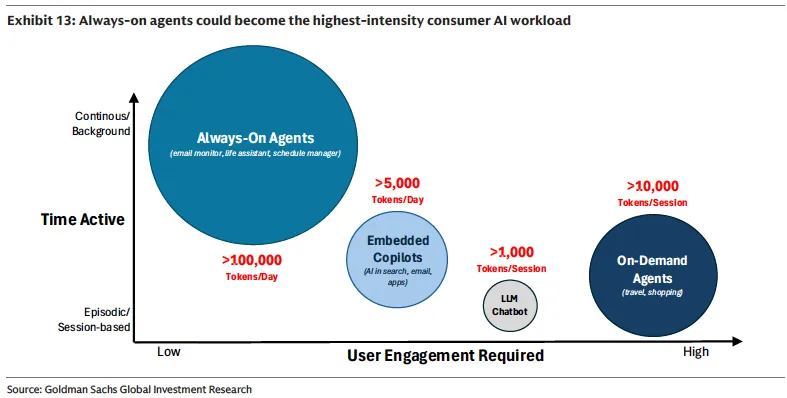
常驻型Agent(Always-On):这是消费级Agent中Token消耗量最大的类别。这类Agent不需要用户主动触发,而是持续在后台运行,比如监控邮箱、管理日程、追踪价格变动、自动整理信息。
高盛构建的邮件监控Agent模拟显示,一个全天运行的邮件助手每天需要消耗超过10万个Token,是传统聊天对话的近百倍。
高盛预计,到2030年,全球每天的AI查询量将从2025年的约50亿次增长到约230亿次,其中高达30%可能由Agent处理。
消费级Agent工作负载将推动全球Token消耗量较当前水平增长约12倍,每月新增约60千万亿个Token。
企业级Agent:更复杂、更精确、更耗Token
如果说消费级Agent的核心驱动力是便利性,那么企业级Agent的核心驱动力则是精确性。
一个消费级Agent给出差不多的答案往往就够了,但企业级Agent需要经过多轮推理、验证、纠错和审计,才能输出可用于真实业务流程的结果。
高盛的方法论颇具说服力。
他们没有停留在抽象的岗位替代率层面,而是针对AI暴露度最高的职业,基于Anthropic的实际使用数据,逐一构建了模拟Agent,将每个工作流程拆解为具体的步骤、模型调用、工具调用、验证循环和重试逻辑,从而估算出最低Token消耗量。
结果揭示了一个重要的不对称性:Token消耗量和实际API成本并不总是成正比。
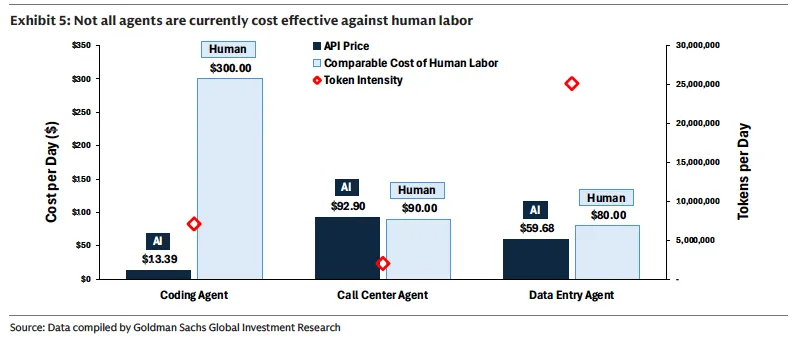
以编程Agent为例,它每天需要消耗约700万个Token,但由于工作流程以文本为主,每天的API成本仅约13美元,这也解释了为什么软件开发是目前Agent采用速度最快的领域。
相比之下,呼叫中心Agent每天只消耗约200万个Token,但如果依赖实时语音处理,每天的API成本可能高达92美元,远超目前外包人工客服的成本(约90美元/天)。
数据录入Agent则处于另一个极端:每天消耗高达2,500万个Token,成本约60美元/天,低于对应的人工成本(约80美元/天),属于Token密集但经济上可行的场景。
这意味着Agent的采用不会均匀地发生在所有岗位上。
高盛认为,采用速度将取决于四个变量:Token消耗量、API成本、多模态需求和实施复杂度。
文本密集型且工具生态成熟的工作流程将率先规模化;语音密集型或深度集成的后台流程可能需要更长时间。
从历史中寻找采用曲线的线索
为了预测Agent的采用节奏,高盛做了一件有趣的事。
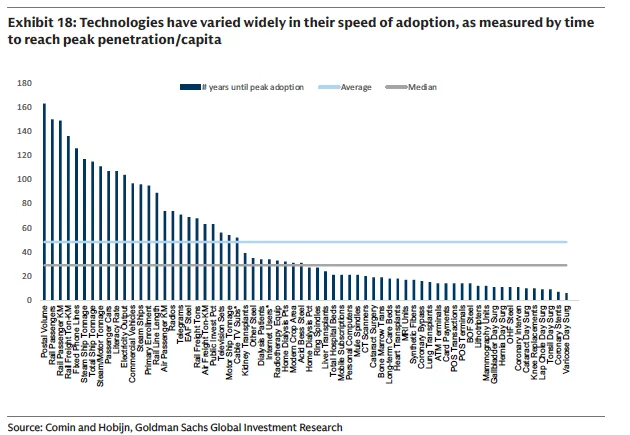
他们借鉴了经济学家Comin和Hobijn的历史技术扩散数据库,涵盖161个国家、101种技术、跨度200年的数据,从中提取企业级技术的采用规律。
历史告诉我们几件事。
第一,不同技术从发明到渗透率达峰的时间差异巨大,铁路和固定电话花了100多年,ATM和微创手术技术只用了不到20年,中位数为29年。
第二,采用曲线的形态不尽相同。有的呈J型(互联网在1990年代的爆发),有的呈S型(电报、居家透析),有的则近似线性(邮政、电力)。
第三,新技术的峰值往往高于旧技术,因为它们往往是在扩大总盘子,而非简单替代。
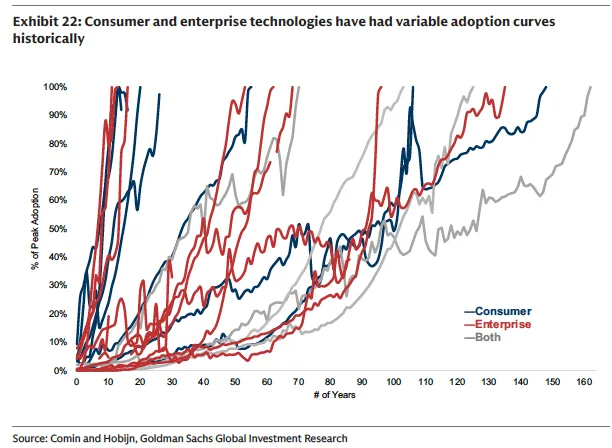
高盛据此做出两个基线假设:企业级Agent的采用将呈S型曲线,从目前的试验期到2030年前后进入加速扩散阶段;达到峰值渗透率的时间约为15年,快于历史中位数。
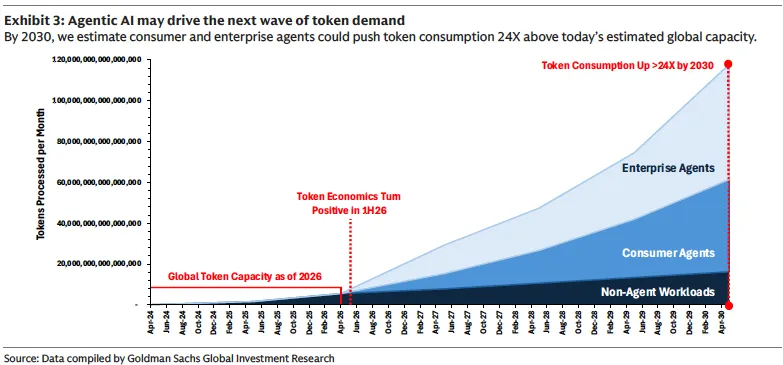
在峰值状态下(约2040年),全球知识工作者中约37%的工作流程将由Agent处理,届时全球Token消耗量将达到当前水平的55倍。
到2030年,消费级和企业级Agent合计将推动全球Token消耗量达到当前的24倍以上,即每月约120千万亿个Token。
一个自我强化的飞轮
高盛在报告中描绘了一个颇具说服力的正反馈循环。
算力成本下降,使得更复杂的Agent在经济上变得可行;更复杂的Agent消耗更多Token(更长的上下文、更多的循环、更多的验证、更持续的监控);更高的使用率改善了AI基础设施的经济性;更好的经济性又为模型质量和分发能力的持续投入提供了空间。
这个飞轮的意义在于,它与此前市场的主流担忧形成了鲜明对比。
此前的叙事是AI使用量越大,亏损越多,而现在的逻辑是AI使用量越大,单位利润越高。
当然,高盛也提醒,这一正向拐点并非对所有AI工作负载都成立。竞争可能迫使某些标准化聊天产品的Token价格继续下降,快于成本的降幅。
投资启示与重点标的
基于上述分析框架,高盛在三条主线上给出了投资建议。
在半导体领域,首选博通(Broadcom)、英伟达(Nvidia)和AMD。
逻辑是,Token成本的持续下降将使更多Token密集型场景在经济上可行,从而扩大可寻址的算力市场。
更重要的是,下游客户(云厂商和模型厂商)利润率的改善,将为持续的资本支出创造更多空间。
在互联网与云计算领域,首选谷歌母公司Alphabet、亚马逊和Meta。
这三家公司分别在云计算、电商和数字广告领域拥有强大的分发能力,同时也是AI算力的最大买家和部署者。
高盛特别指出,亚马逊AWS的营收增速已重新加速至同比28%,谷歌云增速达到63%,Alphabet的营收积压订单接近4,600亿美元。
在软件与IT服务领域,首选微软、Cloudflare和埃森哲。
微软的Copilot反馈持续改善,E7升级周期有望进一步加速Microsoft 365的增长。Cloudflare凭借其网络架构和隔离技术的优势,有望在AI推理工作负载中获取超额份额。埃森哲则将受益于企业从AI试点向规模化Agent部署转型过程中对集成、工作流再设计和变革管理的巨大需求。
几个值得关注的信号
报告中还有几个细节值得投资者关注。
一是BaseTen在高盛私有公司会议上提到,推理算力的供需失衡比大多数行业参与者感知的要严重得多。
一些公司的工程推理成本已经从初始预算超支了数个量级,目前约占人员成本的10%,但按照当前轨迹,可能在几个季度内与人员成本持平。
二是软件公司的定价模式正在发生根本性变化。
越来越多的公司开始按工作单元而非席位定价。调查数据显示,企业愿意为通用智能Agent支付每年2,400美元,作为参考,微软365中间档E5的年费约为680美元,而编程工具的ARPU已经增长了25倍。
三是关于采用节奏的一个反直觉发现。
那些被认为最容易被AI替代的岗位,未必是最先被Agent渗透的岗位。真正决定采用速度的,不是能不能做,而是做起来划不划算。
结语
高盛这份报告最核心的投资逻辑可以浓缩为一句话:Agent经济不是简单地将今天的聊天机器人使用量外推到未来,而是一个使用量与利润率同步改善的新阶段。
当Token消耗量以24倍的速度增长,而单位Token的利润率同时在扩张时,这对于整个AI价值链的含义是深远的。
当然,所有预测都基于一系列假设,现实中的路径必然曲折。
但至少有一点是清楚的:AI从概念验证到规模化盈利的距离,正在以比市场预期更快的速度缩短。
