 夜雨聆风
夜雨聆风💡 痛点导语
你是不是也有这种时刻——老板问"上个月华东区新客复购率同比去年增长了多少",你知道答案就在数据库里,但就是写不出那条SQL?3张表JOIN、窗口函数算同比、再套个子查询……光想想就头大。等找分析师排期出结果,三天过去了,决策早就晚了。更扎心的是,斯坦福最新研究显示:即使是GPT-4,复杂SQL生成准确率也不到42%。所以纯靠AI写SQL?不靠谱。但完全不用AI?更傻。正确姿势是:AI生成框架,你补业务逻辑,5分钟搞定以前2小时的活。今天这篇保姆级教程,手把手教你用AI做数据钻取分析,零基础也能深挖数据!
🛠️ 第一步:喂表结构——AI不认识你的表,写的SQL全是瞎编
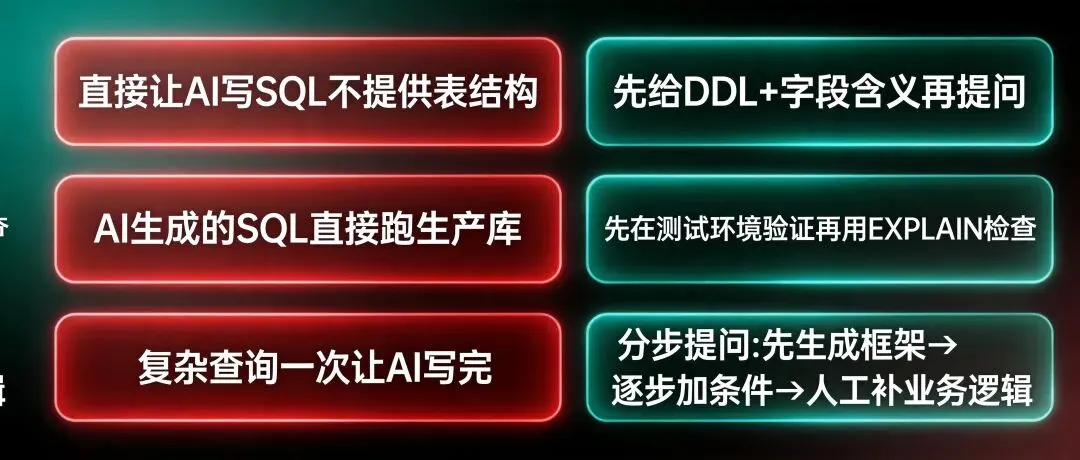
这是90%的人会跳过的一步,也是出错的根源。你直接跟ChatGPT说"帮我查销售额Top5客户",它不知道你有哪些表、字段叫什么,就开始编字段名了。
正确做法是:先把DDL(建表语句)喂给AI。比如:
```
我的数据库有以下3张表:
-- 客户表
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(100),
region VARCHAR(50),
register_date DATE
);
-- 订单表
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
product_id INT,
amount DECIMAL(10,2),
order_date DATE,
is_test TINYINT DEFAULT 0 -- 0=正常订单 1=测试订单
);
-- 产品表
CREATE TABLE products (
product_id INT PRIMARY KEY,
name VARCHAR(100),
category VARCHAR(50)
);
```
重点提醒:DDL里一定要标注业务关键字段。比如上面的`is_test`标记了"测试订单",这样AI就不会把测试数据算进去了。这叫"元数据增强",是让AI写对SQL的最关键一步。
避坑指南:不要只给表名不给字段含义。AI看到`amount`不知道是含税还是不含税,看到`status`不知道每个值代表什么。每个容易混淆的字段,加一行注释就行,成本极低,收益极大。

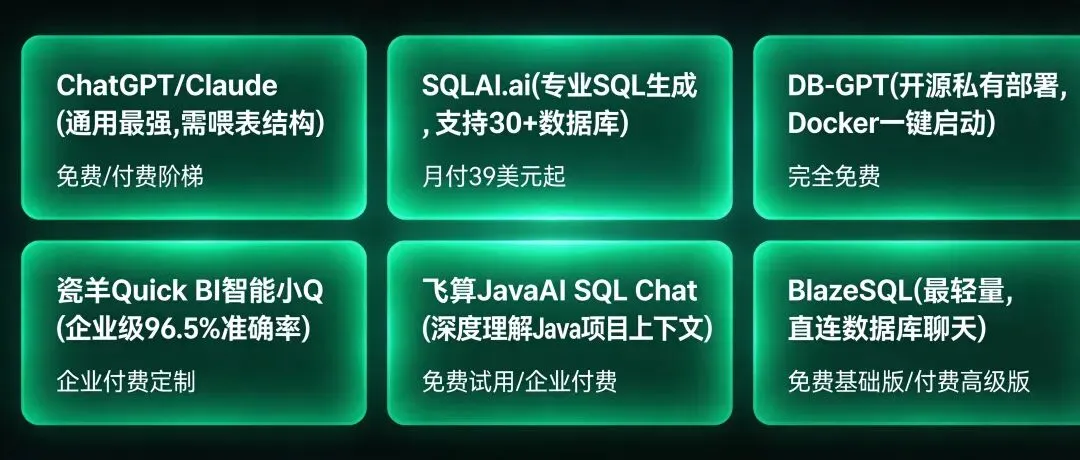
🛠️ 第二步:选对工具——6款AI写SQL工具,场景不同选法不同
不是所有AI写SQL的场景都该用ChatGPT。根据你的需求和技术背景,直接对照这张表选:
| 工具 | 一句话定位 | 适合谁 | 价格 |
|------|-----------|--------|------|
| ChatGPT/Claude | 通用最强,需手动喂表结构 | 偶尔查数据、懂一点SQL | 20刀/月 |
| SQLAI.ai | 专业SQL工具,支持30+数据库 | 经常写SQL的开发/分析师 | 免费起步 |
| DB-GPT | 开源私有部署,Docker一键启动 | 有数据安全要求的企业 | 免费 |
| 瓴羊Quick BI智能小Q | 企业级96.5%准确率,多轮追问 | 中大型企业、阿里云用户 | 按量计费 |
| 飞算JavaAI SQL Chat | 深度理解Java项目上下文 | Java开发者、IDE内使用 | 商业版 |
| BlazeSQL | 最轻量,直连数据库聊天 | 快速查询、不想折腾 | 免费/付费 |
选型决策:
- 偶尔查一次数据 → ChatGPT(把DDL贴进对话框就行)
- 每天都要写SQL → SQLAI.ai(支持Schema导入,准确率更高)
- 公司不让数据出内网 → DB-GPT(本地Docker部署,数据不出服务器)
- 企业级多源分析 → 瓴羊Quick BI(支持中文追问、自动归因,准确率最高)
重点提醒:免费工具先用起来,别一上来就买付费版。先验证AI生成的SQL是否靠谱,再决定是否升级。
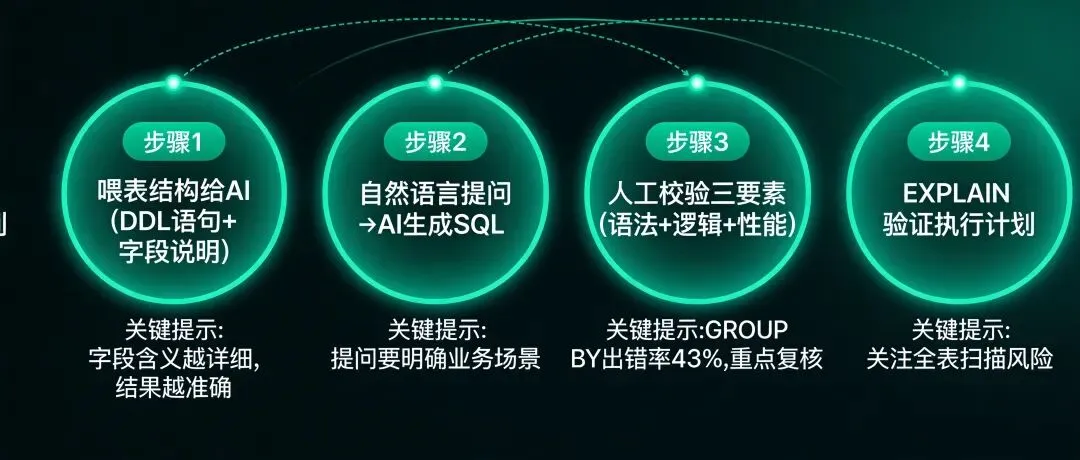
🛠️ 第三步:自然语言提问→AI生成SQL→人工三要素校验
以电商场景为例,你想做数据钻取分析,先从一个核心问题开始:
你的提问:
> 查询2026年Q1各区域销售额Top5客户,排除测试订单,输出客户名、区域、总金额,按金额降序
AI生成的SQL:
```sql
SELECT c.name, c.region, SUM(o.amount) AS total_amount
FROM customers c
INNER JOIN orders o ON c.customer_id = o.customer_id
WHERE o.order_date BETWEEN '2026-01-01' AND '2026-03-31'
AND o.is_test = 0
GROUP BY c.customer_id, c.name, c.region
ORDER BY total_amount DESC
LIMIT 5;
```
重点来了——人工三要素校验:
1. 语法校验:跑一下看有没有报错。SQLAI.ai内置Validator可以自动检测语法问题。
2. 逻辑校验:GROUP BY出错率高达43%,这是人工复核的第一重点。检查GROUP BY字段是否和SELECT非聚合字段一致,JOIN条件是否正确,WHERE过滤是否遗漏。
3. 性能校验:在前面加`EXPLAIN`跑一遍,看有没有全表扫描。如果百万行数据做Seq Scan,加索引或改写SQL。
避坑指南:AI最容易犯的3个错——虚构不存在的字段(以为有`revenue`字段其实是`amount`)、错误处理NULL值(忘了IS NULL判断)、混淆多对多关系(JOIN产生笛卡尔积)。这3个必须手动检查。
🛠️ 第四步:钻取深挖——从"看到了什么"到"为什么这样"
数据钻取才是AI写SQL真正发光的地方。你不需要会写复杂的子查询和窗口函数,只要会追问就行:
第1层:看趋势 → "查询近6个月月度销售额趋势"
第2层:找异常 → "3月销售额为什么环比下降15%?按产品线拆解"
第3层:挖根因 → "电子产品线3月下降最严重,按渠道拆解看哪个渠道出了问题"
第4层:定策略 → "线上渠道3月新客数下降30%,找出新客注册到首单转化的漏斗断点"
每一层你只需要用自然语言描述需求,AI就能生成对应的SQL。关键是层层追问,像剥洋葱一样从外到内。
AI钻取指令词模板:
> [指标]出现了[异常],请帮我按[维度1][维度2][维度3]逐层下钻分析,找出最大贡献因子
重点提醒:每层钻取的结果都要做合理性校验。比如"3月新客下降30%"这个数字,拿注册系统的数据交叉验证一下,别AI把某个条件写反了你还当真。

📝 可直接复制的AI指令词
【指令词1】喂表结构+生成SQL
适用场景:从0开始让AI写查询
> 你是一个精通SQL的数据分析师。以下是我的数据库表结构:
> [粘贴DDL语句]
>
> 请帮我生成一条SQL查询:[用自然语言描述需求]
>
> 要求:
> 1. 字段名严格使用DDL中的定义,不要编造字段
> 2. 注意处理NULL值和测试数据
> 3. 输出SQL后用通俗语言解释查询逻辑
> 4. 标注可能的性能风险点
【指令词2】SQL解释与优化
适用场景:拿到AI生成的SQL,检查是否正确
> 请帮我分析以下SQL查询:
> [粘贴SQL语句]
>
> 要求:
> 1. 用通俗语言逐步解释每段在做什么
> 2. 检查是否有逻辑错误(特别是GROUP BY、JOIN条件、NULL处理)
> 3. 评估在100万行数据量下的性能表现
> 4. 如有优化空间,给出改进后的SQL并说明理由
【指令词3】数据钻取分析
适用场景:发现数据异常后层层下钻
> 我发现[指标名]在[时间段]出现了[异常描述]。请帮我设计一个逐层钻取的SQL查询方案:
>
> 第1层:按[维度1]拆解,找出异常最严重的子分类
> 第2层:对异常子分类按[维度2]进一步下钻
> 第3层:定位到具体[维度3],找出根因
>
> 数据库表结构:[粘贴DDL]
> 每层输出一条SQL和对应的解释。
【指令词4】SQL性能调优
适用场景:查询太慢,需要优化
> 以下SQL在[数据库类型]上执行缓慢,请帮我优化:
> [粘贴SQL + EXPLAIN ANALYZE输出]
>
> 要求:
> 1. 分析执行计划中的性能瓶颈
> 2. 建议需要添加的索引(含索引名和字段)
> 3. 如可改写SQL提升性能,给出改写版本
> 4. 估算优化后的性能提升幅度
💬 实操小贴士
每次只让AI写一个查询,别一口气塞3个需求。复杂分析拆成多步,每步校验再往下走
AI生成的SQL先在测试环境跑一遍,确认结果合理再上生产。永远不要把AI生成的SQL直接跑在生产库
建立你的"表结构速查卡"——把常用表的DDL和字段注释存成笔记,每次提问直接粘贴,省去重复描述
学会读EXPLAIN输出,这是你判断AI写的SQL能不能上线的唯一标准。看不懂就贴给AI让它解释
记录AI每次犯的错——虚构字段、漏掉条件、JOIN方向反了——下次提问时主动提醒"注意不要XXX"
🌟 关注星网AI
学会了吗?赶紧试试吧!AI写SQL的正确打开方式不是"让它替你写",而是"你出业务逻辑,AI出代码框架,你做最后校验"。关注星网AI,每天分享AI实用技巧和提效干货。下期教你用AI搭建自动化数据Pipeline,从取数到报表全自动,别错过哦~
