 夜雨聆风
夜雨聆风OpenAI这条语音线,突然又往前冲了一截。
这次重点在API。
三个名字一起出现:
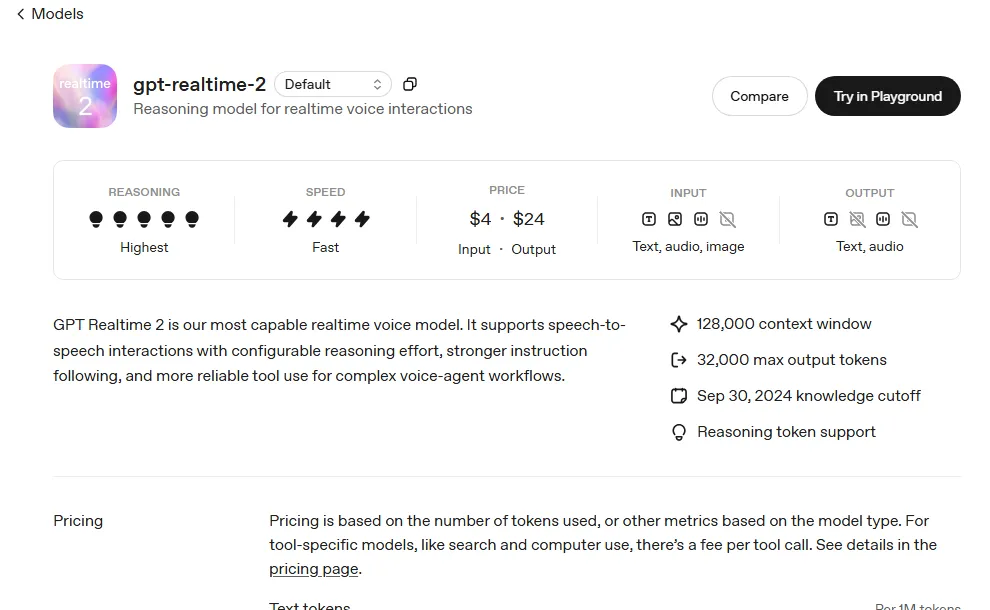
GPT-Realtime-2。
GPT-Realtime-Translate。
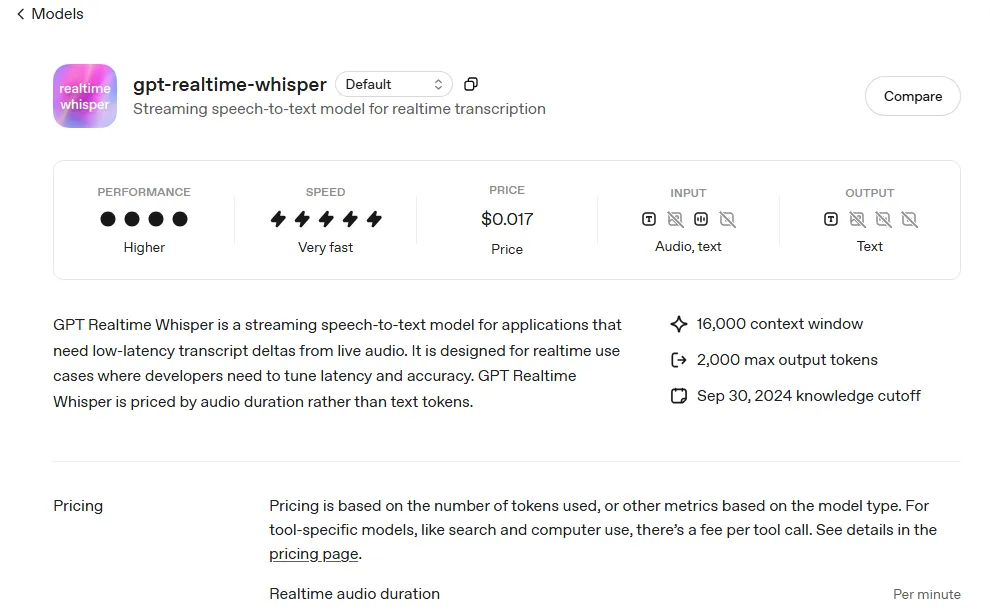
GPT-Realtime-Whisper。
一个管实时对话。
一个管实时同传。
一个管流式转录。
拼在一起,就是语音Agent的完整底座。
以前很多AI产品还卡在聊天框里。
你输入一句,模型回复一句。
再复制、再粘贴、再点按钮。
但真实世界的需求,经常发生在电话里。
客户不会先帮你整理prompt。
会议不会等模型想完再继续。
跨语言沟通也没有那么多耐心。
语音Agent要解决的,就是这件事:
人在说话时,系统已经开始工作。
Realtime-2:电话线上的Agent
GPT-Realtime-2最关键。
OpenAI把它写成“面向实时语音交互的推理模型”。
它支持语音到语音、工具调用,支持更强的指令跟随。
还把价格、上下文、输入输出形态都摆在开发者文档里。
这说明它已经走过展示demo阶段。
它在等开发者接业务。
想象一个客服场景:
用户打电话进来:“我想改地址,顺便查一下订单到哪了。”
老式语音机器人会把你带进菜单:按1;按2;继续等待。
Realtime-2这类模型的目标更直接:
1.听懂这句话
2.查订单
3.改地址
4.确认结果
5.必要时再转人工
这才是语音Agent真正有商业价值的地方。
它要把“听懂”变成“办完”。
Translate:同传变成一层基础能力
第二个模型是GPT-Realtime-Translate。
它的定位很清楚:
实时语音到语音翻译。
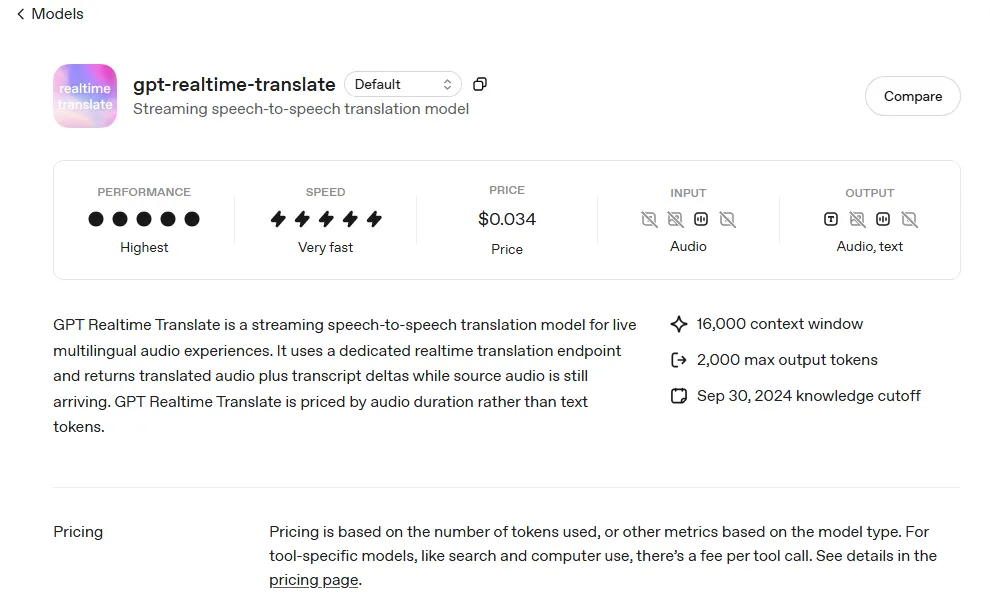
这里最值得注意的,是“流式”两个字。
翻译如果慢半拍,体验就掉一大截。
电话、会议、远程教育、跨境客服,都吃低延迟。
以前跨语言沟通常常是四步:
1.先说 2.转录 3.翻译 4.再播报
中间每多一步,就多一次停顿。
实时同传模型的价值,就是把这些停顿压下去。
对用户来说,是沟通变顺。
对企业来说,是成本重算。
客服团队可以跨语言。
会议系统可以自带翻译层。
教育产品可以直接服务更多地区。
出海业务也能把语言门槛往下压。
Whisper:耳朵开始实时工作
第三个模型是GPT-Realtime-Whisper。
Whisper本来就是OpenAI语音转文字的招牌。
这次加上Realtime,意义变了。
转录不再只是“录完以后整理文稿”。
它开始变成实时输入层。
这对Agent很重要。
没有稳定转录,后面的推理、总结、工具调用都会歪。
会议纪要要实时生成。
医生问诊要实时记录。
客服电话要实时总结。
直播字幕要实时出现。
车载语音要随时接住用户一句话。
这些场景都离不开一只稳定的“耳朵”。
Whisper负责把声音变成模型能处理的结构化输入。
Realtime-2负责理解和行动。
Translate负责跨语言。
三者合起来,才像一套能跑业务的语音系统。
为什么这次值得写
语音一直是AI最诱人的入口。
因为它自然、它够快,同时很多人懒得打字。
也因为很多场景根本不适合打字。
开车、走路、开会、打客服电话、带孩子、处理现场问题。
这些时候,语音比键盘输入更像默认入口。
但语音Agent过去很难做。
要在多人、多语言、噪音环境里保持稳定,只会“能说话”的模型不够。
真正能落地的语音Agent,拼的是整套链路。
OpenAI这次把实时对话、实时同传、实时转录分成三个清晰模型,开发者就更容易按场景拼装。
接下来谁会先被改造
最先动的,大概率是客服。
因为电话量大,流程清楚,ROI好算。
再往后,是会议和销售。
会议要纪要、翻译、待办。
销售要跟进、记录、CRM更新。
教育和医疗也会被影响,但门槛更高。
教育要看互动质量,医疗要看合规和责任边界。
车载和硬件入口也值得盯。
一旦语音Agent能稳定调工具,耳机、汽车、中控屏都会有新故事。
用户甚至不需要意识到自己在“使用AI”。
他说一句话。
系统就开始跑流程。
这才是语音入口最可怕的地方。
最后说句实话
OpenAI这次更新没有头条那种火药味。
但它很贴近普通人未来每天接触AI的方式。
ChatGPT让大家习惯了打字问AI。
Realtime API要推动的是下一步:
开口之后,系统能不能立刻接住。
如果这条路跑通,很多产品的入口都会换。
入口从聊天框,变成直接说话。
然后,AI把事办了。
参考资料:
• OpenAI官方发布:Advancing voice intelligence with new models in the API[1] • OpenAI Developers模型页:GPT Realtime 2[2] • OpenAI Developers模型页:GPT Realtime Translate[3] • OpenAI Developers模型页:GPT Realtime Whisper[4] • Reuters转引报道:OpenAI unveils three audio models for realtime voice tasks[5]
引用链接
[1] Advancing voice intelligence with new models in the API: https://openai.com/index/advancing-voice-intelligence-with-new-models-in-the-api/[2] GPT Realtime 2: https://developers.openai.com/api/docs/models/gpt-realtime-2[3] GPT Realtime Translate: https://developers.openai.com/api/docs/models/gpt-realtime-translate[4] GPT Realtime Whisper: https://developers.openai.com/api/docs/models/gpt-realtime-whisper[5] OpenAI unveils three audio models for realtime voice tasks: https://www.investing.com/news/stock-market-news/openai-unveils-three-audio-models-for-realtime-voice-tasks-4669326
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,我们,下次再见。
