 夜雨聆风
夜雨聆风
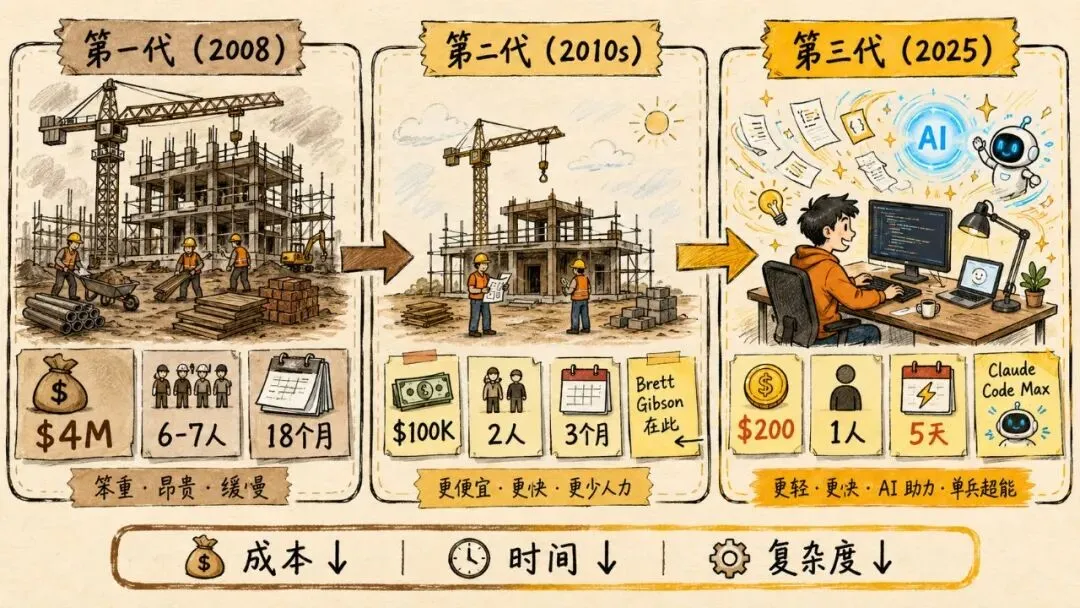
17年前,Gary Tan 用400万美元、6到7个工程师、花了一年半时间,构建了一个博客平台 Posterous,最终被 Twitter 以2000万美元收购。10年前,他和搭档两个人、花10万美元、用3个月把它重写了一遍。而在今年1月,他一个人,花了200美元(一个 Claude Code Max 订阅),只用5天,又重写了一次——这次甚至还多了完整的 RAG 和深度研究能力。
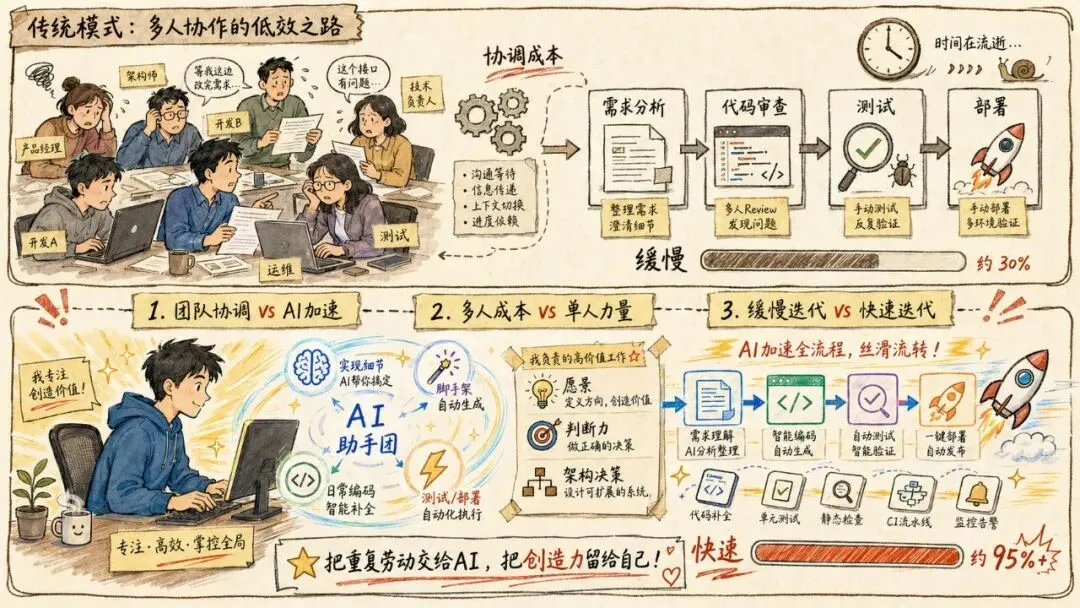
这不是炫耀,而是一个信号:软件工程的成本结构正在被彻底重塑。Gary 把这种打法叫作 Tokenmaxxing。
你能控制你的工具,还是工具控制你?
"现在用 Claude Code 就像开法拉利,"YC 总裁 Gary Tan 说,"快得令人难以置信,它能想到一些你以为机器永远想不到的东西,并且瞬间就做完了。"
但他紧接着补了一句:这同样是一辆"会在最关键的时刻抛锚在路边"的法拉利。你最好同时也是一名机械师,能在出问题时拿起扳手、掀开引擎盖、自己动手修。
这不只是一个比喻,而是 Gary 给整个行业留下的核心问题:
你会掌控自己的工具,还是让工具反过来掌控你?

13年没碰代码的人,重新写了几十万行
Gary Tan 是 Y Combinator 的总裁。过去13年里,他基本上是个投资人,几乎不再写代码。然而最近几个月,他突然以惊人的速度在 GitHub 上出现:发布了几十万行代码,开源项目从0冲到10万+ Star——而这一切,都是在他依然全职管理 YC 的同时完成的。
互联网上有不少人不相信,甚至冷嘲热讽。不过 Light Cone 的几位主持人却在他身边亲眼见证了这一切。
"我自己也挺震惊的,"Gary 笑着说,"13年没写代码,然后一下子,我现在的产出量大约是当年我状态最好时的 400倍——而那一年我差不多三分之二的时间都在写代码。"
400倍这个数字背后有一段故事,后文会讲到。但他重新拿起代码的契机,其实和"AI"无关——而是和加州的政治、和一个孩子能不能学到代数有关。
起点:一个孩子能不能学代数
在旧金山做了多年政治工作后,Gary 越来越确信一件事:把聪明人聚在一起,本身就是一种巨大的力量——这正是大规模社会运动得以形成的真正基础。
于是他成立了一个 501(c)(4)、后来又设立了 C3 和 PAC,这是政治组织常见的组合。但他很快意识到,仅靠组织还不够——他需要一个发声的平台。
"那就先做个网站吧。" 他说,"我先把我担心的事情写下来。"
他最在意的事情之一是:在旧金山的公立学校,一个7年级或8年级的学生,直到今天依然几乎不可能选修代数。
"全世界的人听到这个可能会觉得很奇怪,"他说,"但我自己就是从东湾的公立学校出来的,如果当年我没机会学代数,我就不可能去斯坦福读工程,不可能写代码,不可能做今天这些事。"
这件事戳到了他。他决定动手。而当他动手时,他发现一切都已经不一样了。
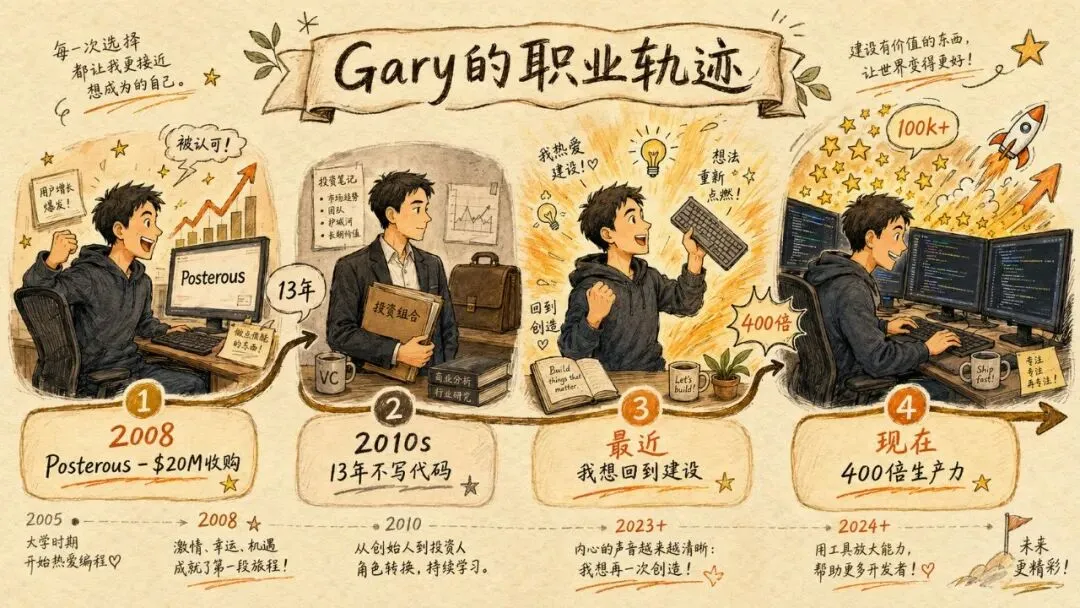
Posterous → PostHaven → Garys.org:三次重写,三个时代
Gary 第一次做这种发布平台是在2008年,那是他第一家 YC 公司 Posterous——"通过邮件写博客",一度冲进互联网 Top 200 网站,被 Twitter 以约 2000 万美元收购。
Twitter 关停 Posterous 后,他和联合创始人 Brett Gibson(如今 Initialized 的负责人)又把它重写了一遍,叫做 PostHaven——因为从 Twitter 手里买回原来那套代码要花几百万美元,他们当时根本掏不出来。
而今年1月,他第三次重写了它,命名为 Gary's List:
200美元、5天,做出来的不只是和前两版功能对等的博客平台,而且多了一整套 RAG 系统和 agentic 检索能力:能爬全网、读他写过的每一条推文、对任何议题做递归式深度调研。
"代数只是其中一件事。"他补充道,"但围绕加州、旧金山、洛杉矶的治理问题,我们关心的议题非常多。"
软件本身就是记者
"很多人没看懂 Gary's List 真正在做什么,"主持人补充道,"传统软件是给人用的:你做一个博客平台,别人来写博客;做个 Substack,别人来发文章。但 Gary's List 本身就在做高质量调查记者的工作,而不是让记者来用它。"
Gary 接过话头:
"差不多花5到10美元 Opus 调用费,就能完成一个真人需要好几天才能做完的工作——翻几十篇文章、读完几本书、做笔记、交叉印证。"
他说,这个思路其实早在 Light Cone 第一期采访 Casetext 创始人 Jake Heller 时就埋下了种子:要思考"一个人在这个上下文里会做什么"。他会去图书馆吗?会查什么书?会在网上搜什么?
"现在好就好在,你不必只让一个 LLM 自己去想,"Gary 说,"Perplexity 有 API,xAI 的 Grok 有 API,每个都能做深度研究。你把所有这些上下文一把抓回来,喂给你的核心 prompt——这就是我所说的 boil the ocean(一网打尽)。"
Tokenmaxxing:把所有能查的都查一遍
Boil the Ocean 是 Gary 在自己博客里写过的一篇文章。它的核心很简单:
既然机器不嫌累,那就别再用"人类才需要的偷懒标准"去做事。
如果换作一个真人,要花一个月才能调研完一件事——那现在你就让 agent 去把这一个月的活全干了。多花点钱,也许你正在 token max,但你就该 token max。
他举了一个具体的例子:
• 写一篇报道,传统做法是找一个来源就开始写。 • Tokenmax 的做法是:抓 20 个来源,让模型交叉比对,识别出"13 个来源支持这个观点,7 个反对",把全部上下文塞进核心 prompt。 • 然后由模型基于完整图景做判断,而不是像普通人那样点开一个链接读个标题就下结论。
Gary 强调,这不只是写文章。它会渗透到知识工作的每一个角落。
"但这并不意味着不需要人了。"他特别澄清,"人提供的是 agency——是'我在乎这件事'的那个原始驱动力。我之所以想做 Gary's List,是因为我真的为那些学不到代数的12、13岁孩子感到痛苦。"
GStack:从"我懒得重复打字"开始
让 Gary 在工程上完成跨越的,不只是 boil the ocean 这个哲学,还有他无意间打磨出来的一套工具集——GStack。
"我根本没打算做 GStack,"他说,"我只是发现自己反复在 Claude Code 里打同样的话,烦了,就把它们写到 Apple Notes 里。"
最早只是非常朴素的几条规则,比如:
• plan-review:让 Claude 在写代码前先输出一份计划。 • 要求它画 ASCII 图:数据流、状态机、依赖图、处理流水线、决策树。
"我发现 Claude 有时候会犯糊涂,写出 bug 或漏掉东西。但当我让它先画一张 ASCII 图,把所有数据流、输入输出、用户路径、错误信息都画出来——它一旦把上下文都加载进去,就能把整件事做得更完整、更彻底。"
接着他撞上了所有"vibe coder"都会撞上的那堵墙:能跑通 80% 的场景,但只要真用户一上手就处处崩。
"那是我意识到——我可以让它把测试覆盖率推到 100%。后来我发现 100% 太多了,80% 到 90% 就够。"
这套早期 prompt 后来演变成了 plan-review skill。他把更狠的版本叫做 mega plan,最终改名为 CEO plan。这个 prompt 用了一种叫 metaprompting 的手法,模仿 Airbnb CEO Brian Chesky 提出的"10星体验"思考法:
大家都知道酒店有三星、四星、五星。但 Brian 会问:六星是什么?七星是什么?八星呢?……一直问下去。
"这是我最喜欢的产品和设计练习之一,"Gary 说,"以前你只能在脑子里偶尔玩一玩,现在你每一次写代码都可以这么思考。"
CEO 这个 skill 里还有两条非常关键的指令:
1. 找到这个想法的"柏拉图理想形态"是什么样的。 2. What is the 10x check?——做什么改动,能用 2 倍努力换来 10 倍价值?
"就这两句话,几乎是魔法。"Gary 说。"我是个 ADHD 的 CEO,最爱的就是'纯粹的潜能',这个 skill 让我每次都能进入那种状态。"
一个人的工厂:13个 PR / 48小时
GStack 后来又长出了一整套角色分工:CEO、设计师、开发者体验工程师、plan-review、/codex ……Gary 把它们全部嵌进 Conductor,作为他每天写代码的真实工作流。
"过去 48 小时我提了 13 个 PR,"他展示自己的界面,"任何新想法过来,我就排队进去。"
他的标准流程:
1. Office Hours / CEO Review:先把想法过一遍 YC 式的灵魂拷问。 2. Designer Review(如果涉及 UI)。 3. Developer Experience Review(GStack/GBrain 几乎所有功能都涉及)。 4. plan-review。 5. /codex:把当前 plan 或已实现代码丢给 OpenAI Codex,让它用命令行跑一轮"找问题、找 bug",再把结果反馈给 Claude Code。
之所以引入 Codex,是因为他在一次 YC 校友活动上听到许多人说他们更喜欢 Codex。
"我研究后发现,Claude Code 是 ADHD CEO 的最佳搭档,但偶尔它会一本正经地胡说八道。Claude 模型很强,但说实话,它不是最聪明的。当你遇到的问题特别离谱,你就需要那种'IQ 200 但几乎不会说话的 CTO'——Codex 就是这个角色。你随时把它请进来当顾问。"
后来他还反过来加了 /claude:当你以 Codex 为主时,可以让 Claude 临时进来当 CEO。
而最后一道关——手工 QA——他原本是用 Chrome MCP 解决的,但每次跳转两到三秒,慢得让人崩溃。他索性让 Claude Code 直接包了一层微软的 Playwright,叫做 Browse:一个常驻的 70 命令 CLI。
"我新的 QA skill 就一句话:'看看你在这条分支上做了什么。如果有 UI 或数据变更,就用浏览器去测一下。'"
第一次跑通的那一刻,他形容自己的心情:
"Mini AGI 已经来了。"
Thin Harness, Fat Skills:把魔力放进 Markdown
Gary 在 X 上发过一篇文章叫 Thin Harness, Fat Skills,在网上引起争论。这个名字其实出自他在 YC 的合伙人 Pete Koomen。
他们之前内部一直在做自己的 agent 框架(也就是 harness),后来发现:天天用 Claude Code,那何必再去重写 harness?真正应该投入心力的,是去想该写哪些 markdown。
"你应该把自己想象成一个婚礼策划——如果你要写一份'怎么办一场婚礼'的清单,让下一个人照着做,你会用纯英文写下哪些步骤?这些就是 markdown 应该做的事。"
而真正确定性的、需要精确执行的部分(比如打 20 个酒店电话),就交给代码(比如 Twilio API)。
"今天 agentic 工程里大部分的痛苦,"Gary 说,"都是因为人们试图用代码去做该用 markdown 做的事,结果失败了——因为代码太脆弱,它不理解特殊情况,它不知道你是谁、你想要什么。"
而 LLM 有 latent space,知道你是谁、你的动机是什么,能处理通用情况。
"这个时代做工程师,魔法就在于:判断哪些该放进 LLM 的世界,哪些该放进代码的世界。"
他被人嘲讽"满嘴 markdown"已经不是一两次。他的回应是:
"Markdown 就是代码——它只是以另一种方式被'编译'。"
容易坏也没关系:再叫一个 agent 去修就行
主持人也分享了一段他自己使用 OpenCode 的经历:它有时候会"把自己搞砸",干出一些莫名其妙的事。
"但你只要让 Claude Code 在旁边跑着,"Gary 说,"它就会顺手把它修了。"
这就是这一代工程师必须完成的"心智切换":
东西容易坏、需要修没关系——只要你能再叫一个 agent 一直在那儿守着修就行。
主持人把这句话扩展成了一段对历史的回望:
• Stack Overflow 时代:你卡住了,去搜,复制代码回来。 • ChatGPT 时代:你能交互了,但还是在复制粘贴。 • Claude Code 时代:你不再需要复制粘贴,它直接执行。
"我现在大约 50–60% 时间在 Claude Code 里写代码,"Gary 说,"剩下 40–50% 时间在 OpenClaw 里。"
GBrain:让 Markdown 变成你的二号大脑
Gary 最近主要在做的项目是 GBrain。它的灵感来自 Karpathy 那篇关于 "LLM Wikis" 的文章。
"我有一个全是 markdown 的 repo,所有上下文都可以塞进去。但我意识到,OpenClaw 默认用的是 grep,grep 不够好,会把太多无关的内容塞进上下文。"
于是他打开 Conductor,点了 quick start——GStack 已经预装在 Conductor 里——然后说:
"去看看 ~/garys-list,看看我那边是怎么做 chunking、embedding、hybrid RRF retrieval 的,把这套抽出来;我要用 Postgres + pgvector 给 OpenClaw 做完整 RAG。"
就这样,一件事接一件,整个项目就被推动了起来。
"这就是为什么我说我们正在进入开源的黄金时代。"他说,"你已经有了一套被实战检验过的实现,新项目里只需要让 agent 去模仿、去抽象。"
关于 "400x" 这件事
Gary 在网上贴了一张图,说自己的产出"是 2013 年的 100 倍",结果被群嘲:"代码行数根本不能衡量生产力。"
他承认:是,也不是。
"代码行数确实不能完全衡量生产力——但它也确实能衡量。你可以用一些公开的脚本,把 git repo 里的代码归一化成'逻辑代码行数'。我跑了之后,结果反而更高了——是 400x。"
他补充了关键的细节:
• 他不是自己手敲,而是同时指挥 15 个 agent。 • 归一化之后,Claude Code 的代码量略微下降。 • 但出乎意料的是,他 2013 年自己写的代码量被砍掉了 70%。
"为什么?因为人写代码会下意识地'灌水',而 Claude 除非你叫它去灌,它不会主动为代码行数优化。"
更有意思的是历史数据。如果你翻 1990–2000 年代的软件工程文献,会发现:
一个专业工程师,平均每天写的、能进生产环境的代码大概只有 30–50 行。
"所以 400x 就是这么来的。我应该早点这么解释,而不是去网上嘴硬。"他自嘲。
个人 AI 革命,正在到来
Gary 谈到了 Claude Code 与 OpenCode/Hermes 之间体感差异巨大的现状。但他非常笃定地预言:
"明年这个时候,地球上每一个人都会拥有自己的个人 AI。"
而我们正面临一个分叉:
╭─────────────────────────────╮ ╭─────────────────────────────╮│ Personal AI │ │ Corporate AI ││ ───────────────────────── │ vs. │ ───────────────────────── ││ • 自己的数据 │ ◀───▶ │ • 像 Facebook 信息流 ││ • 自己的集成 │ │ • 算法是谁写的? ││ • 自己的 prompts │ │ • 服务谁的商业模式? ││ • 看得见、可控、可改 │ │ • 你不知道 │╰─────────────────────────────╯ ╰─────────────────────────────╯"个人电脑革命是我们这代人收到的最大一份礼物,"Gary 说,"我们正在经历一模一样的转折——personal AI 革命。"
但要享受这份红利,你必须愿意自己写 prompt。否则,你就会永远停留在某个产品经理或开发者画下的"API 围栏"之内——而那个人不是你,不会懂你真正在乎的是什么。
"你会掌控自己的工具,还是工具反过来掌控你?"
Token 是新的旧金山房租
主持人接着提出了一个普通用户都会有的真实困惑:要享受这一切,你必须用最新最贵的模型,必须烧掉大量 token。普通人订阅个 Claude Pro、用免费模型,是体验不到这种感觉的。
Gary 给了一个特别 YC 式的类比:
"这就像旧金山的房租。"
很多 YC 创始人一开始都说:"旧金山房租太贵了,我不想搬过去。" 而 YC 的回答永远是:
"不搬过去更贵。"
"早期一个月好几千美元的公寓,你会觉得'这太离谱了'。但答案是:你应该付,甚至应该多付一点,住到 Dogpatch 那种能创造 serendipity 的街区。"
Token 也是一样。
"当你真的在用模型、在烧 token 的时候,你就该使劲儿往上推。 办公桌、沙发那些东西,你可以省;但 token 不一样,那是完全另一回事。"
YC 一直有一句箴言:好的创业点子,藏在'活在未来,把缺失的那部分补出来'里。
"今天 Tokenmaxxing 就是这个箴言最深刻的一种形式。" Gary 说,"你只需要让自己接受——'我可以一天烧掉500美元 token'——前提是你在做对你真正有价值的事。"
从机器那里"借时间"
主持人最后问了 Gary 一个问题:你有没有可能恰恰是因为同时在管 YC,时间极度稀缺,才被逼着把这一切自动化到极致?
Gary 笑了。
"我很羡慕那些 'time billionaire',"他说,"我看着我的孩子,他们就是 time billionaire,他们可以做任何事、学任何东西。"
他自己呢?
"我感觉自己脑子里像揣着百亿条人生,要在这具身体里全部活一遍。我必须让每一刻都算数。"
而现在,有了 Tokenmaxxing:
"我可以买下数百万年的机器意识,让我自己也成为 time billionaire——那不是我自己的时间,那是机器的时间,在替我,在替我所在乎的人,去做我所在乎的事。"
他还提到一段关键的"觉醒时刻"——和 Boris Churnney 同台录 Light Cone:
"Boris 说他的团队'一行代码都不写'。我突然意识到,'诶,我也可以这样啊。' 屏幕另一端的你和我,并没有什么不同。我们站在同一个起点。我能打开一个 prompt,你也能。我们用的是同一种 prompt,同一台 MacBook Pro。没有任何东西挡在你、我、或者任何人,与那数百万年可调用的 token 之间——你可以拿这些 token,去为人类做点什么。"
主持人忍不住接了一句:
"你可以通过向机器借时间,拥有无限的时间。"
Gary 平静地回答:
"What a time to be alive."
本文整理自 The Light Cone 播客特别节目:"Tokenmaxxing: How Top Builders Use AI To Do The Work Of 400 Engineers",主角为 Y Combinator 总裁 Gary Tan。
