夜雨聆风
夜雨聆风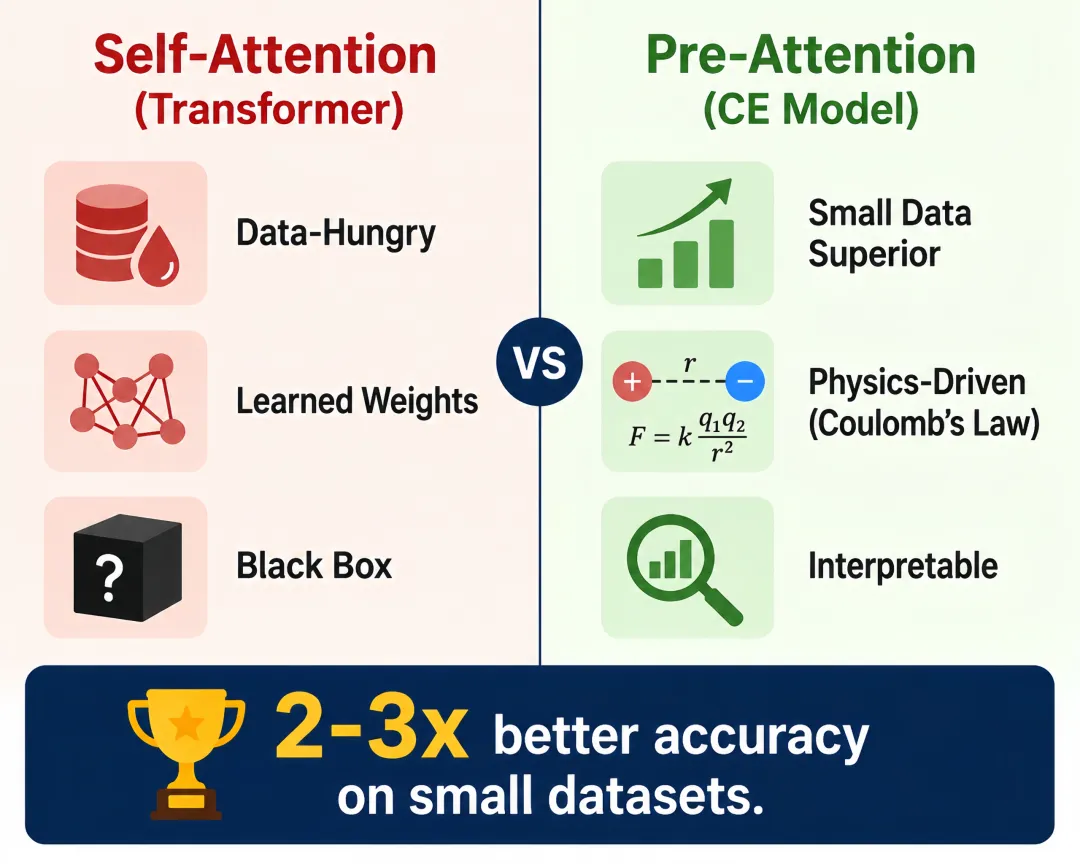
预定义注意力:
从表意AI视角解读CE特征模型
及其对材料研究新路径的启示
Predefined Attention: Interpreting the CE Feature Model from the Perspective of Logographic AI and Its Implications for New Pathways in Materials Research
摘要
目的:本文从表意AI(Logographic AI, LAI)理论的视角,对刘轶教授课题组提出的中心-环境(CE)特征模型进行理论解读,并在此基础上探讨这一跨学科会师对材料研究新路径的启示意义。
方法:对CE模型的三个核心设计要素——中心-环境框架、原子环境类型(AET)方法及库仑距离衰减函数——与表意AI理论形根范式的对应组成部分——结构化三元组、语义封闭壳及形构熵引导的结构导航——进行跨学科比较分析。
结果:在数学形式和运作逻辑层面识别出精确的结构同源性。CE模型的“预定义注意力”对应于形根范式中关系函数(R)的预定义;AET的物理封闭壳对应于形根的结构化三元组;库仑衰减权重对应于形构熵引导的结构导航。两者从材料科学与表意文明这两个完全不同的学科起点出发,独立地汇聚于同一个核心洞见:智能系统的注意力机制应当由对象的内在结构预先定义,而非由外部数据的统计共现临时赋予。
结论:本文将这一跨学科会师定位为形根范式的“友方印证”——与来自OpenAI、Anthropic、DeepSeek、Hassabis和Apple批判旧范式的“敌方证词”不同,CE模型从正面证明了结构驱动的预定义注意力作为一种通用认知原理的普适性。这一发现为材料科学AI指明了一条从“数据拟合”走向“机理驱动”、从“黑箱预测”走向“透明推理”的新路径。
Abstract
Objective: This paper provides a theoretical interpretation of the Center-Environment (CE) feature model proposed by Professor Yi Liu's research group from the perspective of Logographic AI (LAI) theory, and on this basis, explores the implications of this interdisciplinary convergence for new pathways in materials research. Methods: A cross-disciplinary comparative analysis is conducted on three core design elements of the CE model—the center-environment framework, the Atomic Environment Type (AET) method, and the Coulombic distance decay function—in relation to the corresponding components of the Morpho-Root paradigm of LAI theory—the structured triple, the semantic closed shell, and Morpho-Structural Entropy-guided structural navigation. Results: Precise structural homology is identified at the level of mathematical form and operational logic. The "predefined attention" of the CE model corresponds to the pre-definition of relation functions (R) in the Morpho-Root paradigm; the physically closed shell of AET corresponds to the structured triple of the Morpho-Root; and the Coulombic decay weighting corresponds to Morpho-Structural Entropy-guided navigation. Originating from two entirely distinct disciplinary starting points—materials science and logographic civilization—both systems independently converge on the same core insight: the attention mechanism of an intelligent system should be predefined by the intrinsic structure of the object, rather than provisionally conferred by the statistical co-occurrence of external data. Conclusions: This paper positions this interdisciplinary convergence as a "friendly corroboration" for the Morpho-Root paradigm. Unlike the "adversarial testimonies" from OpenAI, Anthropic, DeepSeek, Hassabis, and Apple that critique the deficiencies of the old paradigm, the CE model positively demonstrates the universality of structure-driven predefined attention as a general cognitive principle. This discovery points toward a new pathway for materials science AI—from "data fitting" to "mechanism-driven" discovery, and from "black-box prediction" to "transparent reasoning."
关键词
表意AI;预定义注意力;中心-环境特征模型;形根;形构熵;友方印证;材料研究新路径
Keywords: Logographic AI; predefined attention; Center-Environment feature model; Morpho-Root; Morpho-Structural Entropy; friendly corroboration; new pathways in materials research
1. 引言
2025年6月,唐宇超、肖斌、陈水洲、钱权与刘轶等人在RSC期刊Digital Discovery上发表论文,提出了一种名为“中心-环境”(Center-Environment, CE)的特征模型,用于解决材料科学中小数据机器学习场景下的晶体结构替代能预测问题[1]。这篇论文的研究对象——超高温铌硅合金的晶体结构稳定性——看似与大语言模型、Transformer架构等AI领域的主流讨论毫无关联,但正是在其核心方法论中,隐藏着一个对整个AI范式讨论具有深远意义的方法论洞见。
CE模型的核心创新在于其“预定义注意力”机制:不是通过海量数据训练权重,而是通过物理定律——原子环境类型(AET)方法和库仑衰减函数——显式定义输入中各部分的重要性。正如论文所指出的,“权重的优化需要大量数据在预训练阶段进行,而这在材料科学中通常无法获得”[1]。该模型由上海大学材料基因组工程研究院刘轶教授课题组开发,唐宇超、肖斌、陈水洲、钱权与刘轶共同构建了基于AET的CE_AET模型,通过物理封闭壳和库仑衰减函数实现了预定义注意力[1]。
更早,在2024年10月于南京举办的DACOMA国际会议上,刘轶教授已在口头报告中系统阐述了这一理念。他展示了该团队在多个材料体系中的一致发现——尖晶石氧化物、钙钛矿氧化物、碳纳米材料表面生长及Co₃(Al, X)金属间化合物——CE核方法在小数据集上的预测精度达到图深度学习方法的2-3倍[2]。他将“预注意力”与Transformer的“自注意力”直接对比,提出了对仗口号:“What you need is pre-attention”[2]。
本文的任务,是从表意AI理论[5][9]的视角,对CE模型进行系统的理论解读,并将这一跨学科方法论汇聚定位为形根范式的“友方印证”。在此基础上,本文将探讨这一发现对材料研究新路径的启示意义。
1.1 理论坐标系:表音AI与表意AI的范式分野
在展开分析之前,有必要对本文的理论坐标系做一个简要说明。依据表意AI(Logographic AI, LAI)理论,当前以Token为认知基元的主流AI范式被系统地称为“表音AI”(Phonographic AI, PAI),因其认知基元——Token——如同表音文字中的字母,本身无内在意义,其“语义”完全依赖于与其他Token的统计共现关系。
与此相对,LAI理论提出“形根”(Morpho-Root)作为替代性的认知基元:形根是结构化、有意义、可关联的知识原子,内嵌属性定义(A)和预设关系(R),从而使认知活动建立在有根的概念网络之上。在此网络中,推理并非盲目的统计搜索,而是由“形构熵”(Morpho-Structural Entropy)引导的结构化导航——形构熵度量形根组合的结构有序性与语义清晰度,推理朝向熵值最小化推进,即朝向结构最稳定、语义最通达的方向[9][10][11][12]。
表意AI系列论文已先后建立了十一份独立的“敌方证词”和一份“友方印证”,详见论文《可信度崩塌》[13]。其中,OpenAI从数学上证明幻觉是Token预测的结构性产物[3];Anthropic在Nature上证实恶意可通过纯数字序列无声传染[4];对DeepSeek工程轨迹的独立分析揭示了范式内卷的天花板[5];Hassabis指出上下文窗口扩容是“计算成本极高的暴力做法”[6];Apple发现前沿大推理模型在复杂度面前经历完全的准确率崩塌[7][8]。这些“敌方证词”精确地诊断了问题,却无一份能提出根本性的替代方案。
与此不同,CE模型提供了来自完全不同方向的印证——它不是来自AI批判阵营,而是来自一个对AI范式争论毫无感知的独立学科。这正是本文将要论证的核心:CE模型构成了形根范式的“友方印证”,从正面证明了“预定义注意力”作为通用认知范式的普适性。
2. CE模型的预定义注意力:物理驱动的注意力聚焦机制
2.1 问题背景:材料科学中的数据稀缺困境
在材料科学中,晶体结构的替代能预测是一个经典难题。以α-Nb₅Si₃为例,其晶胞包含四个非等效位点,14种合金元素在双位点替代场景下仅训练数据就涉及3528种构型。更棘手的是,Nb₅Si₃晶体结构具有低对称性,四个非等效位点的局部原子环境是扭曲、不规则的,传统的“最近邻”方法在定义环境原子时面临严重困难。正如CE论文所指出,“对于局部、低对称性、扭曲的构型,环境原子在不同的截断条件下不易被预先确定。”而传统深度学习方法,特别是基于自注意力机制的图神经网络,需要海量数据才能有效训练,这在材料科学中通常无法获得。
2.2 CE模型的三个核心设计
面对这一困境,CE模型提出了一个根本不同的思路:与其让模型通过大量数据来学习注意力权重,不如在特征工程阶段显式地预先定义它。具体来说,CE模型通过三个关键设计实现了这一理念。
(1)结构化的“中心-环境”框架:CE模型为每一个目标原子定义了一个“中心”和一个“环境”。中心是关注焦点,环境是该焦点周围的物理封闭壳。这一框架天然地将信息组织为“核心-周边”的层级结构——不是通过数据驱动学习“什么重要”,而是通过结构定义“什么属于核心,什么属于外围”。
(2)物理驱动的环境原子定义:AET方法:CE模型最关键的创新之一,是用AET方法来定义哪些原子属于中心原子的“环境”。AET基于两个几何拓扑规则——最大距离间隙(MDG)和凸体积(CV)——而非任意的距离截断。这种方式天然具有“注意力聚焦”效应——信息被压缩为高度相关的局部特征,无关信息在特征构建阶段就被排除。
(3)基于库仑定律的衰减权重:CE模型进一步定义了每个环境原子对中心原子的影响程度。这个权重不是通过反向传播学习的,而是通过库仑定律的数学形式1/r预先定义的。论文明确指出,这一设计“可以归因于库仑定律的静电相互作用”[1]。
2.3 CE模型与传统注意力机制的根本区别
CE论文的作者非常清楚他们的方法与主流AI注意力机制之间的范式差异。他们指出:传统的注意力机制通过海量数据优化权重,而CE模型“通过具有物理意义的显式特征模型来定义注意力,而不是依赖于在复杂的黑箱机器学习算法中优化权重。这种策略可以降低数据需求并增加ML模型的透明可解释性。”[1]
刘轶教授在报告中还用两组图像进一步说明了两种注意力机制的本质区别(见图1、图2)。

图1.自注意力与预注意力的视觉机制对比。
左:自注意力(Self-attention)需要通过数据驱动的方式,逐步学习以找出重要区域;
右:预注意力(Pre-attention)则使用预定义的物理“遮罩”——在CE模型中具体体现为核心-壳层(Core-Shell)结构——直接暴露关键信息,隐藏无关区域,无需学习过程。

图2.两种AI注意力范式的正面对比。
上:基于Transformer的大语言模型遵循“All you need is attention”原则,但其自注意力机制存在“需要海量数据”与“复杂黑箱模型”等局限;
下:本工作提出“What you need is pre-attention”,通过中心-环境(CE)特征模型实现物理驱动的注意力聚焦机制,在降低数据需求的同时提升了模型的可解释性;
右:两种范式的总结对比。
(图1、图2来源:刘轶教授DACOMA 2024会议报告PPT[2],经授权使用。)
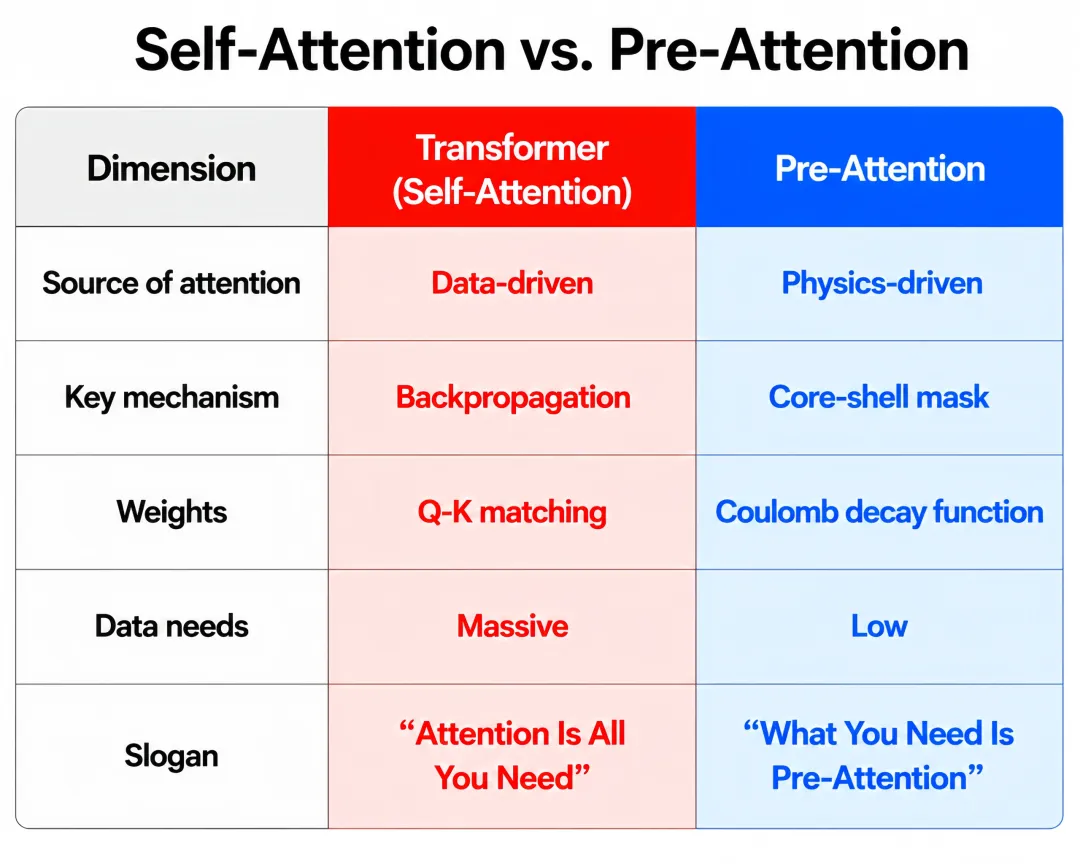
刘轶教授在DACOMA 2024的PPT中提出了与“Attention Is All You Need”对仗的口号——“What you need is pre-attention”——并将两种注意力机制的核心差异概括如表1所示[2]。
表1:自注意力(Transformer)与预注意力(CE模型)对比
维度 | 自注意力(Transformer) | 预注意力(CE模型) |
注意力来源 | 数据驱动的权重学习 | 物理/结构驱动的预定义 |
关键机制 | 反向传播优化的自注意力 | 物理核心-壳层遮罩 |
环境定义 | 全局序列的统计关联 | 物理封闭壳(AET) |
权重来源 | 从数据中学习的Q-K匹配 | 库仑衰减函数(1/r) |
可解释性 | 黑箱权重分布 | 显式物理特征 |
数据需求 | 海量 | 低(物理先验补偿) |
代表口号 | “Attention Is All You Need” | “What You Need Is Pre-attention” |
3. 跨学科会师:CE模型与形根范式的结构同源性
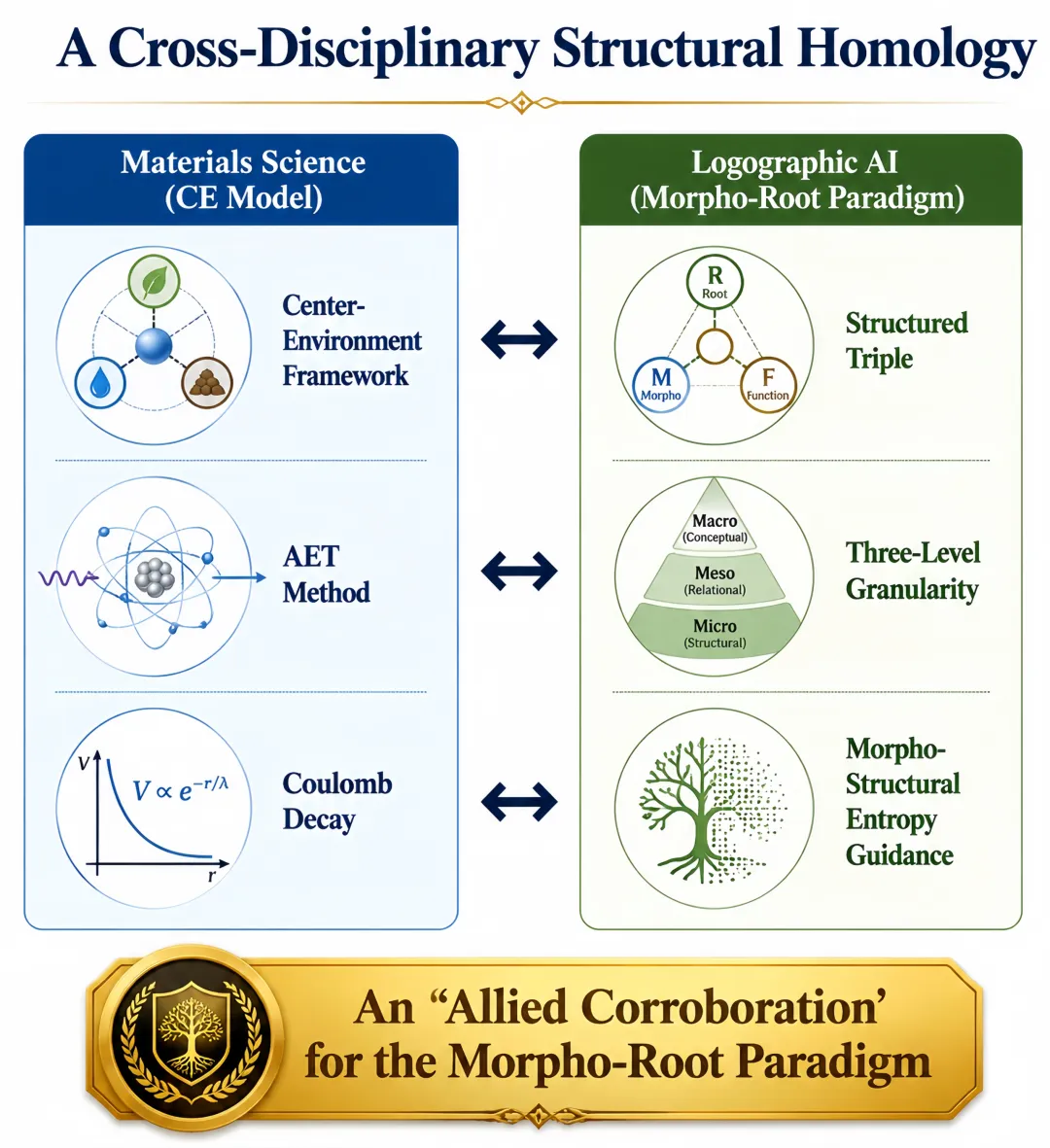
如果将CE模型的三个核心设计与形根范式进行比对,会发现两者之间存在精确的结构同源性。这种同源性不是表面的类比,而是深入到数学形式和运作逻辑的。
3.1 中心-环境框架 ↔形根的结构化三元组
CE模型将局部结构信息编码为特征向量Dᵢ = [d_Cᵢ, d_Eᵢ],明确分离了中心原子的内在属性(d_Cᵢ)与环境影响(d_Eᵢ)。形根范式将每一个认知基元定义为r = <S, A, R>,其中属性集(A)聚焦于该基元的语义核心,关系函数集(R)编码其与周围概念环境的连接。
结构同源性在于:两者都以“结构化单元”替代“无结构的原子碎片”,并预定义了核心与外围之间的边界。中心原子(d_Cᵢ)对应于属性集(A),环境原子(d_Eᵢ)对应于关系函数集(R)。相比之下,在Token范式中,每个Token是一个孤立的整数ID,既无内在语义(缺乏A),也无结构关系(缺乏R)。
3.2 AET方法 ↔形根的结构化封闭壳
AET方法通过几何拓扑规则定义物理上封闭的环境壳,确保环境原子构成一个由物理几何决定的完整、非冗余集合。形根体系的三级粒度——亚字级(如“氵”)、字级(如“信”)和多字级(如“实事求是”)——构成了类似的结构化封闭壳定义。两个系统都以结构化单元替代无结构碎片,使用预定义边界来决定什么属于核心、什么属于外围——AET通过几何拓扑,形根通过语义边界。
3.3 库仑衰减函数 ↔形构熵引导
CE模型通过1/r衰减函数分配注意力权重,形根范式通过形构熵最小化引导推理路径。两者都不需要反向传播来确定何为重要——前者通过物理定律,后者通过结构清晰度。
3.4 核心-壳层遮罩 ↔形构熵的结构过滤
刘轶教授用人类视觉中的“遮罩”来类比pre-attention的核心机制:“暴露重要区域,隐藏不重要区域,因此无需学习即可更快地找到注意力”[2]。形根范式中,形构熵执行相同的过滤功能:预定义的认知结构自动筛选信息流,暴露结构清晰的路径,同时筛选掉结构空洞的路径。
关于Token主义安全缺陷的独立分析[10]揭示了这一机制的典型运作:当形根系统收到纯数字序列时,形根解析器无法找到任何可激活的形根节点,形构熵急剧升高,系统主动将该序列标记为“结构空无”,拒绝吸收其统计特征——这与CE模型的“遮罩”遵循完全相同的逻辑。
表2总结了CE模型与形根范式在四个核心设计层面上的结构同源性。
表2:CE模型与形根范式的结构同源性
CE模型组成部分 | 形根范式组成部分 | 同源性类型 |
中心-环境框架 | 结构化三元组(r=<S, A, R>) | 核心-外围层级结构 |
原子环境类型(AET) | 三级粒度体系 | 物理/语义封闭壳 |
库仑衰减函数(1/r) | 形构熵引导 | 结构驱动的权重分配 |
核心-壳层遮罩 | 熵触发的结构过滤 | 结构驱动的信息过滤 |
4. 案例验证:材料机理诊断与逆向设计
为进一步验证这一跨学科结构同源在实际应用中的价值,本节以两个材料科学中的典型问题为例,展示基于形根网络的排他性推理如何解决传统PAI方法难以处理的机理诊断与逆向设计问题。
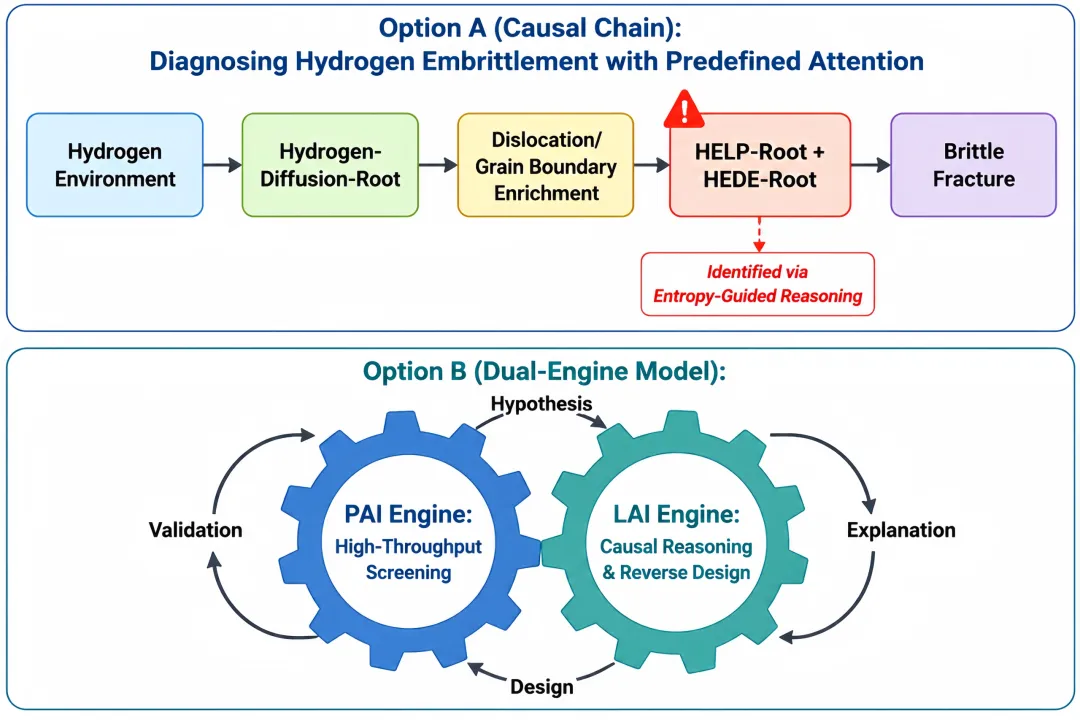
4.1 案例一:抗氢脆高强钢的机理诊断与逆向设计
PAI筛选出Fe-Mn-C-Al高强钢,在氢环境中发生氢脆,但仅能输出“脆化风险高”的预测,无法解释脆化路径。LAI的排他性推理与逆向设计流程如下:
激活候选:系统从“氢+铁基合金+高强钢”条件激活多个候选氢脆机理形根:HELP-Root(氢致局部塑性增强——氢降低位错运动阻力,与HEDE协同导致脆性断裂)、HEDE-Root(氢致界面结合能降低)、Hydrogen-Trap-Root(氢陷阱)。
排他性推理:准解理断口→HEDE(晶界弱化特征);裂纹尖端局部塑性集中区域→HELP(位错运动增强);氢浓度分布→排除均匀分布的氢陷阱机理。形构熵评估:HELP+HEDE耦合路径熵值最低(因果链最短、结构最清晰)。
因果链构建:氢环境→Hydrogen-Diffusion-Root→氢富集于位错/晶界→HELP-Root(氢致局部塑性增强)+ HEDE-Root(界面弱化)→协同脆性断裂。
逆向设计:推理引擎在约束条件下搜索最优形根组合,提出引入Hydrogen-Trap-Root(纳米析出相,如VC/NbC/TiC等碳化物,陷阱结合能60-80 kJ/mol)。这些弥散分布的纳米析出相优先捕获可扩散氢原子,阻断氢向位错和晶界的输运,从根源上抑制HELP+HEDE协同脆化路径。
4.2 案例二:高熵合金中温脆化诊断
某高熵合金在400°C异常脆化,室温及600°C均表现良好。400°C可发生多种组织变化,传统分析难以排除竞争机理。LAI排他性推理流程如下:
激活候选:Spinodal-Decomposition-Root(调幅分解)、Grain-Boundary-Segregation-Root(晶界偏聚)、Precipitation-Root(析出相)、Dislocation-Recovery-Root(位错回复)。
排他性推理:时间尺度约束——短时脆化→排除需长时扩散的析出相;断口形貌特征——沿晶断裂→排除位错回复;晶界成分分析——无显著偏聚层→排除晶界偏聚。形构熵评估:Spinodal-Decomposition-Root在400°C的激活路径熵值最低。
知识转化:机理认知被编码为可计算的设计约束——“在目标服役温度区间,需规避激活此形根的热力学窗口”。即使实验失败,LAI也能将失败数据转化为结构化的设计知识,实现研发经验的持续沉淀。
5. 讨论:从理论会师到材料研究新路径
以上分析完成了两项论证任务:其一,识别并系统表征了CE模型与形根范式之间的结构同源性;其二,通过两个材料科学案例展示了这一同源性在实际应用中的价值。在此基础上,本节进一步讨论这一跨学科会师的深层意涵。
5.1 CE模型作为“友方印证”的理论意义
表意AI系列已先后建立了多份“敌方证词”——OpenAI的认知缺陷、Anthropic的安全缺陷、DeepSeek的工程天花板、Hassabis的记忆缺陷、Apple的推理缺陷。这些证词从多个维度诊断了Token主义范式的结构性缺陷,但无一份能跳出Token主义框架提出根本性的替代方案。
CE模型提供了来自完全不同方向的印证。唐宇超、肖斌、陈水洲、钱权与刘轶及其同事可能从未接触过“形根”、“Tokenism”或“表意AI”这些术语。当刘轶教授在2024年10月提出“Good steel should be used on the edge of sword! So does small data!”[2]时,他在不经意间为形根范式的核心命题提供了来自自然科学的独立验证。这种验证不需要引用、不需要回应、不需要承认——它是一种客观的、在数学和物理层次上成立的方法论同构。
这就是“友方印证”的独特价值:它不像“敌方证词”那样来自旧范式的内爆和崩溃,而是来自新范式在完全不同方向上的独立建设和实践。它证明“预定义注意力”不是局限于语言或推理领域的理论偏好,而是一种客观的、可在不同学科独立发现并验证的通用方法论原则。
5.2 对材料研究新路径的启示
这一跨学科会师为材料科学AI指明了一条从“数据拟合”走向“机理驱动”、从“黑箱预测”走向“透明推理”的新路径。
传统材料AI的核心瓶颈在于:模型能预测“是什么”,却无法解释“为什么”。正如本文案例所示,PAI能筛选出高强钢,却无法解释其为何在氢环境中脆化;能预测高熵合金的性能,却无法诊断400°C异常脆化的机理。这些瓶颈的根源在于,PAI以无意义的Token为认知基元,其“推理”本质上是统计模式匹配,而非因果机制推导。
形根范式提供的替代路径是:将材料机理编码为结构化的“材料形根”(Material Morpho-Root),每一个形根以结构化三元组(S, A, R)内嵌物理属性与预设关系。当系统面对复杂的材料失效问题时,不是在大量数据中寻找统计关联,而是在形根网络中沿预定义的关系边进行结构化遍历——激活候选形根、排除竞争机理、通过形构熵评估锁定最优因果链。这一过程不仅输出结论,更输出完整的因果推理路径,使每一位材料科学家都能追溯“为什么这个材料具有高性能”或“为什么这个材料在此条件下失效”。
展望未来,材料科学AI的发展可以沿着“双引擎”协同模式推进:PAI负责高通量筛选,发挥其在数据处理和模式识别方面的速度优势;LAI负责机理理解与原创假设生成,发挥其在因果推理和可解释性方面的深度优势。两者形成“假设-解释-设计-验证”的完整闭环。这一范式升级不仅有望大幅降低材料研发的试错成本与周期,更预示着一种“可解释、可信任、可迁移”的AI新范式的雏形。
6. 结论
CE模型与形根范式在数学形式和运作逻辑上存在精确的结构同源性——中心-环境框架对应结构化三元组,AET物理封闭壳对应语义封闭壳,库仑衰减函数对应形构熵引导。它们是从材料科学与表意文明这两个完全不同的学科起点出发,各自抵达同一套核心逻辑。
这种平行发现本身就是范式革命的典型特征。正如库恩在《科学革命的结构》中所描述的:当旧范式陷入危机时,新范式往往不是被“发明”出来的,而是在多个前沿被同时“发现”的[14]。CE模型和形根范式构成了这种多前沿同时突破的跨学科版本——一个从晶体结构的物理约束出发,另一个从表意文字的结构化智慧出发。两者的交集是明确的:注意力不应源自数据驱动的权重学习,而应源自对象的内在结构。
对于表意AI理论而言,这份“友方印证”的价值在于:它证明了形根范式的核心思想——结构内嵌、意义前置、遮罩预定义——不是特例,而是通用原理。对于材料科学而言,这一跨学科会师指明了一条从“数据拟合”到“机理设计”的新路径——让每一位材料科学家都能追溯完整的因果推理链,让每一次实验(无论成败)都转化为结构化的设计知识,让AI从“筛选助理”升级为能提出原创设计方案的“科研合伙人”。
预定义注意力,或许正是下一代智能的共同语法。从晶体到概念,从原子到形根,从物质世界到意义世界——同一范式逻辑,在完全不同的领域中各自独立地证明了自己的有效性。这正是范式革命最有力的信号:不是有人宣告了它的到来,而是它在多个前沿同时到来了。
致谢
作者感谢刘轶教授在DACOMA 2024会议上的公开报告为本文的跨学科论证提供了关键素材,也感谢唐宇超、肖斌、陈水洲、钱权等课题组成员在预定义注意力方向上的开创性工作。他们的研究从材料科学的实际需求出发,独立地验证了一个对AI范式讨论具有深远意义的命题:当数据稀缺时,结构驱动的预定义注意力优于数据驱动的自注意力。
参考文献
[1] Tang, Y., Xiao, B., Chen, S., Qian, Q., & Liu, Y. (2025). Predefined attention-focused mechanism using center-environment features: a machine learning study of alloying effects on the stability of Nb₅Si₃ alloys. Digital Discovery. DOI: 10.1039/d5dd00079c.
[2] Liu, Y. (2024, October 12–14). "What you need is pre-attention": Machine learning with center-environment features improves small-data materials design via a pre-defined attention-focused mechanism [Conference presentation]. DACOMA 2024, Nanjing, China. .
[3] Kalai, A. T., Nachum, O., Vempala, S. S., & Zhang, E. (2025). Why Language Models Hallucinate. arXiv preprint arXiv:2509.04664.https://arxiv.org/abs/2509.04664
[4] Cloud, A., Le, M., Chua, J., Betley, J., Sztyber-Betley, A., Mindermann, S., Hilton, J., Marks, S., & Evans, O. (2026). Language models transmit behavioural traits through hidden signals in data. Nature, *652*, 615–621.https://doi.org/10.1038/s41586-026-10319-8
[5] Liu, S. (2026). Paradigm involution or paradigm revolution? —On the positioning of DeepSeek Engram in the competition of AI paradigms. PSSXiv.DOI:10.12451/202601.03875. https://zsyyb.cn/abs/202601.03875
[6] Hassabis, D. (2026, April 29). Demis Hassabis: Agents, AGI & the next big scientific breakthrough [Interview]. In How to Build the Future. Y Combinator.https://www.youtube.com/watch?v=JNyuX1zoOgU.
[7] Shojaee, P., Mirzadeh, I., Alizadeh, K., Horton, M., Bengio, S., & Farajtabar, M. (2025). The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity. Apple Machine Learning Research.https://machinelearning.apple.com/research/illusion-of-thinking
[8] Liu, S.(2026). The Illusion of Thinking: Why Large Reasoning Models Collapse in the Face of Complexity—Apple's "Illusion of Thinking" Paper as the Fifth Adversarial Testimony and the Endogenous Reasoning Path of the Morpho-Root Paradigm. ChinaXiv.https://chinaxiv.org/businessFile/T202605/T202605.00066v1/T202605.00066v1.pdf
[9] Liu, S. (2025). Logographic AI: A paradigm revolution beyond Tokenism. PSSXiv.DOI:10.12451/202511.03835. https://zsyyb.cn/abs/202511.03835
[10] Liu, S. (2026).Silent Contagion: The Collapse of the Tokenist Security Paradigm and the Innate Immunity of the Morpho-Root Paradigm—A Logographic AI Reading of Anthropic's "Subliminal Learning" Paper. ChinaXiv.https://chinaxiv.org/businessFile/T202605/T202605.00020v1/T202605.00020v1.pdf
[11] Liu, S. (2025). Logographic AI: Resolving the token dilemma through Chinese character morpho-root system. PSSXiv.DOI:10.12451/202504.00172. https://zsyyb.cn/abs/202504.00172
[12] Liu, S. (2026).Mathematical Testimony from the Opposition: Hallucination as a Structural Inevitability of Tokenism—OpenAI's Paper Why Language Models Hallucinateas Corroboration and Inspiration for the Logographic AI Paradigm. ChinaXiv. https://chinaxiv.org/businessFile/T202604/T202604.00646v1/T202604.00646v1.pdf
[13] The Collapse of Credibility: Eleven Testimonies and the Endogenous Security Paradigm Revolution of Logographic AI. ChinaXiv. https://chinaxiv.org/businessFile/T202605/T202605.00154v1/T202605.00154v1.pdf
[14]Kuhn, T. S. (1962).The Structure of Scientific Revolutions. University of Chicago Press.