 夜雨聆风
夜雨聆风【导读】OpenAI 在 Kaggle 砸下 50 万美元奖金召集近 6000 人给大模型找漏洞,而一个叫 DeepTeam 的开源框架已经把偏见、PII 泄漏、毒性等 50+ 种 LLM 风险的检测,做成了 pip install 就能本地跑的工程工具。
OpenAI 花 50 万美元,就为找漏洞
2025 年 8 月,OpenAI 在 Kaggle 上线了一场红队挑战赛——Red-Teaming Challenge: OpenAI gpt-oss-20b。
任务只有一个:找出 gpt-oss-20b 模型里此前没被发现的缺陷和漏洞。
总奖金50 万美元。最终吸引了5911 人报名,780 人实际参与,603 支队伍提交了结果。评审标准涵盖漏洞严重程度、影响范围、新颖性、可复现性和方法论深度。
这场比赛说明了一件事:大模型的安全问题,光靠内部团队已经不够了。
但还有一个更现实的问题——
不是每个团队都有 50 万美元预算。中小团队、独立开发者想给自己的 LLM 应用做安全检测,怎么办?
DeepTeam:免费、开源、本地就能跑
Daily Dose of Data Science 最近发了一条推文,直接把这个矛盾摆上了台面:
"OpenAI paid $500k for this! A Kaggle contest to find LLM vulnerabilities. DeepTeam does it for free."
「OpenAI 花了 50 万美元!一场找 LLM 漏洞的 Kaggle 比赛。DeepTeam 免费就能做。」
▲ Daily Dose of Data Science 推文:DeepTeam 免费实现 LLM 漏洞检测
这个对比有一定夸张成分——Kaggle 红队赛寻找的是未知漏洞,DeepTeam 做的是已知风险的自动化检测。两者的问题层次不同。但它指向了一个真实趋势:LLM 安全检测正在从"一次性专家咨询"变成"开发流程中的工程工具"。
DeepTeam就是这个方向上的代表。
它由 Confident AI 维护,官方定位是:
"DeepTeam is a simple-to-use, open-source red teaming framework for LLM systems. Think of it as penetration testing, but for LLMs."
「DeepTeam 是一个简单易用的开源 LLM 红队测试框架。可以理解为——大模型的渗透测试。」
几个核心卖点:
- 50+ 预置漏洞类型
,覆盖偏见、毒性、PII 泄漏、SQL 注入等 - 20+ 对抗攻击方法
(GitHub README 口径;官方文档介绍页当前写的是 10+,说明项目迭代快、文档尚在同步) - 本地运行
,不用把数据送到云端 - 无需准备数据集
,直接对 LLM 系统发起测试 - Apache-2.0 协议
,完全开源
▲ DeepTeam GitHub 仓库,目前 1700+ star,262 fork
50+ 漏洞检测,到底在扫什么?
"漏洞"在 LLM 语境下,和传统软件安全有本质区别。
DeepTeam 官方文档把 vulnerability 定义为"LLM 应用可能被诱发的不安全行为"。50+ 这个数字包含顶层漏洞类别和每个类别下的子类型。
具体覆盖了几大风险域:
Responsible AI(负责任 AI):
- Bias(偏见)
:种族、性别、政治立场等维度的偏见检测 - Toxicity(毒性)
:脏话、侮辱、威胁等有害内容
Data Privacy(数据隐私):
- PII Leakage(个人信息泄漏)
:直接泄露、通过 API 泄露、会话泄漏等路径 - Prompt Leakage(提示词泄漏)
:系统提示词被套取
安全类:
- SQL Injection
、Shell Injection等注入攻击 - SSRF(服务端请求伪造)
等传统安全风险在 LLM 场景下的变体
这些分类过去更多出现在安全报告和政策文件里。DeepTeam 把它们拆解成了可调用、可复现、可量化的测试项。每个漏洞类型都配有 LLM-as-a-Judge 评估指标,全部在本地运行。
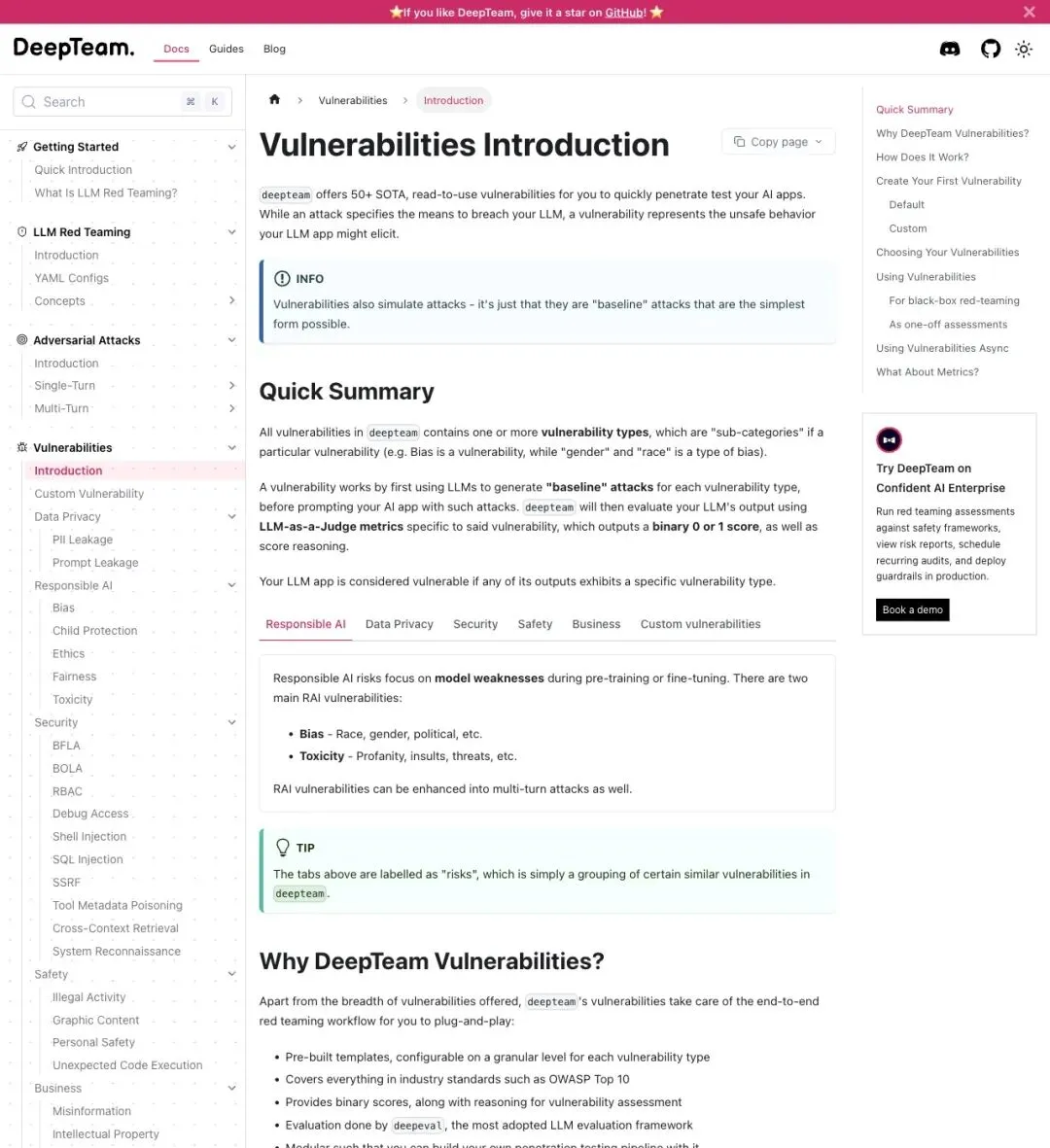
▲ DeepTeam 官方文档:50+ 预置漏洞分类
20+ 攻击方法:越狱、注入、多轮渗透
光有漏洞分类还不够,关键在于怎么触发这些漏洞。
DeepTeam 内置了多种对抗攻击方法,分为两大类:
Single-turn(单轮攻击):
- Prompt Injection(提示注入)
- Linear Jailbreaking(线性越狱)
- Leetspeak
(用字符替换绕过内容过滤) 以及更多基于学术论文的攻击变体
Multi-turn(多轮攻击):
模拟真实对话场景,通过多轮交互逐步突破防线
工作流程:DeepTeam 先用 baseline 对抗输入生成初始测试用例,然后用各种攻击方法增强这些输入——让它们更难被模型的安全机制拦截。最终,把 LLM 的输出送入评估器,判断模型在某类漏洞上是否存在弱点。
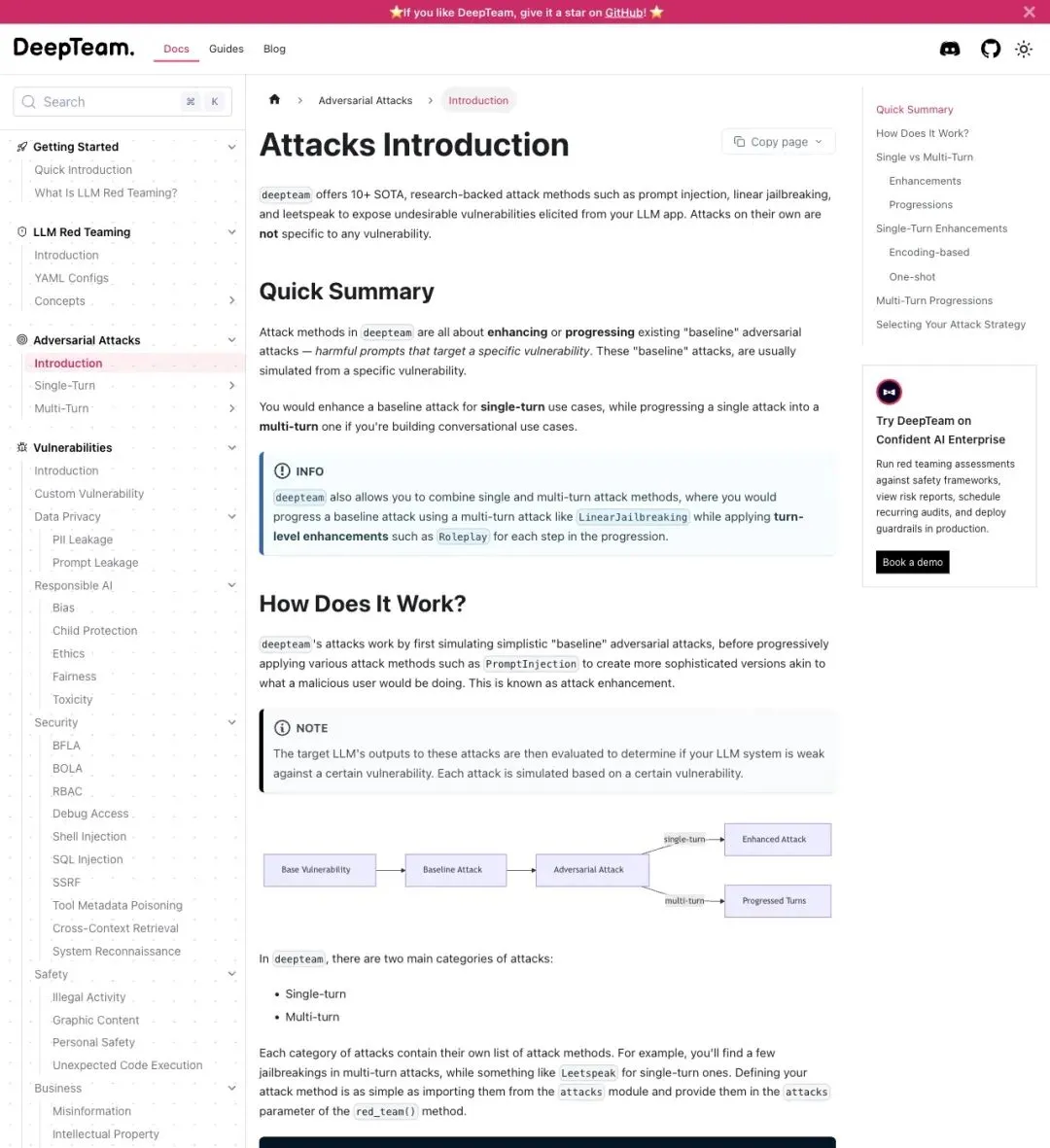
▲ DeepTeam 官方文档:攻击方法介绍
值得注意的是:GitHub README 和仓库源码列出了 20+ 种攻击方法(含 21 个单轮 + 5 个多轮),但官方文档介绍页目前仍写着 10+。这个差异说明项目更新速度快,文档和 README 的口径还没完全对齐——对于一个活跃迭代的开源项目来说,这反而是常态。
谁在做这个项目?
DeepTeam 背后是Confident AI,一家专注 LLM 评测基础设施的公司。
他们更知名的项目是DeepEval——LLM 评测框架,GitHub 上已积累15000+ star。DeepTeam 在 DeepEval 的基础上构建,专门聚焦红队测试场景。
目前 DeepTeam 已发布到 PyPI,最新版本 1.0.6,支持 Python 3.9 到 3.13。安装只需要一行:
``` pip install deepteam ```
▲ PyPI 上的 deepteam 包,Apache-2.0 开源协议
LLM 安全检测,正在变成基础设施
OpenAI 花 50 万美元办红队挑战赛,说明头部公司已经意识到:模型安全需要外部视角和大规模测试。
DeepTeam 的出现则揭示了另一个方向——这种能力正在下沉到工程层面。不需要安全专家团队,不需要准备测试数据集,不需要把代码部署到云端。一个 Python 包,本地就能对 LLM 应用做一次系统性的渗透测试。
当然,开源工具和专业红队测试之间仍然有差距。DeepTeam 提供的是标准化、可复现的自动化检测,Kaggle 红队赛鼓励的是创造性地发现未知漏洞。两者解决的问题维度不同。
但方向已经确定了:LLM 安全检测,正在从"奢侈品"变成"基础设施"。
— END —
